LLM 논문에 관한 블로그입니다.
-

* Mechanistic Understanding and Mitigation of Language Confusion in English-Centric Large Language Models (Findings of EMNLP 2025)
1. 문제 정의: Language Confusion 핵심 현상 유형 예시 (논문 Fig.1): 2. 핵심 개념: Confusion Point (CP) 정의 –> 매우 중요한 insight: 실험 결과 Table 2 (page 4) –> language confusion은 “local failure”임을 보여줌 3. Mechanistic Insight (핵심 기여) 3.1 Layer-wise 분석 (TunedLens 사용) 관찰 (page 5, Fig.2) 결론 language confusion =“latent → surface language…
-

*** Spherical Steering: Geometry-Aware Activation Rotation for Language Models (ArXiv 2026)
1. 문제 설정 (핵심 motivation) 기존 activation steering: 문제점: 논문 핵심 주장: “LLM의 semantic signal은 magnitude가 아니라 direction에 있다” → 따라서 steering도 벡터 이동이 아니라 방향 회전으로 해야 한다 2. 핵심 아이디어: Spherical Steering (1) Representation을 hypersphere로 해석 ⇒ Sd−1S^{d-1} (unit hypersphere 위의 점) (2) Truthfulness axis 정의 contrastive 데이터로부터: Δ=m+−m−\Delta = m^+ – m^-…
-

*** Angular Steering: Behavior Control via Rotation in Activation Space (NeurIPS 2025)
논문 개요 Angular Steering: Behavior Control via Rotation in Activation Space (NeurIPS 2025) 핵심 문제 기존 방법: 문제: 핵심 아이디어 (한 줄) Activation steering = “벡터 이동”이 아니라 “각도 회전”이다 1. Angular Steering 핵심 개념 ✔️ 기본 설정 –> 이 두 개로 2D subspace P 구성 ✔️ 핵심 연산: Rotation 논문은 steering을 다음처럼 정의: hsteered=RθP(h)h_{\text{steered}}…
-

* Prompt Compression for Large Language Models: A Survey (NAACL 2025)
1. 핵심 문제의식 (Why Prompt Compression?) LLM 사용 시 가장 큰 병목 중 하나는 긴 prompt입니다. 따라서 목표는: “성능 유지하면서 prompt 길이 최소화” 2. 전체 프레임워크 논문은 prompt compression을 크게 두 가지로 분류합니다: (1) Hard Prompt Compression (2) Soft Prompt Compression 정리: 구분 방식 특징 Hard token filtering / paraphrasing 해석 가능 Soft embedding /…
-

*** Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory (EACL 2026)
1. 문제 정의 (Motivation) 기존 LLM의 핵심 한계: 논문 핵심 주장: “LLM도 inference 과정에서 지속적으로 학습해야 한다” 즉, 2. 핵심 아이디어: Dynamic Cheatsheet (DC) 직관 LLM에게 “치트시트(cheatsheet)”를 만들어주자: 전체 구조 (핵심 loop) 논문 수식으로 표현: (1) 생성 단계 y~i=Gen(xi,Mi)\tilde{y}_i = Gen(x_i, M_i) (2) 메모리 업데이트 Mi+1=Cur(Mi,xi,y~i)M_{i+1} = Cur(M_i, x_i, \tilde{y}_i) 핵심 특징: 3. DC의 두…
-

* Tree-Structured Parzen Estimator: Understanding Its Algorithm Components and Their Roles for Better Empirical Performance (ArXiv 2023)
1. 문제 설정: Black-box Optimization TPE는 Bayesian Optimization (BO) 계열 알고리즘으로, 다음 문제를 해결합니다: x∗=argminx∈𝒳f(x)x^* = \arg\min_{x \in \mathcal{X}} f(x) 2. 핵심 아이디어: 기존 BO와의 차이 일반 BO (e.g., GP-based) TPE의 핵심 차별점 역방향 모델링: p(x|y) 를 직접 모델링p(x|y) \text{ 를 직접 모델링} 즉, p(x|y)={p(x|𝒟(l))(y≤yγ)p(x|𝒟(g))(y>yγ)p(x|y) = \begin{cases} p(x | \mathcal{D}^{(l)}) & (y \le y_\gamma) \\ p(x | \mathcal{D}^{(g)})…
-
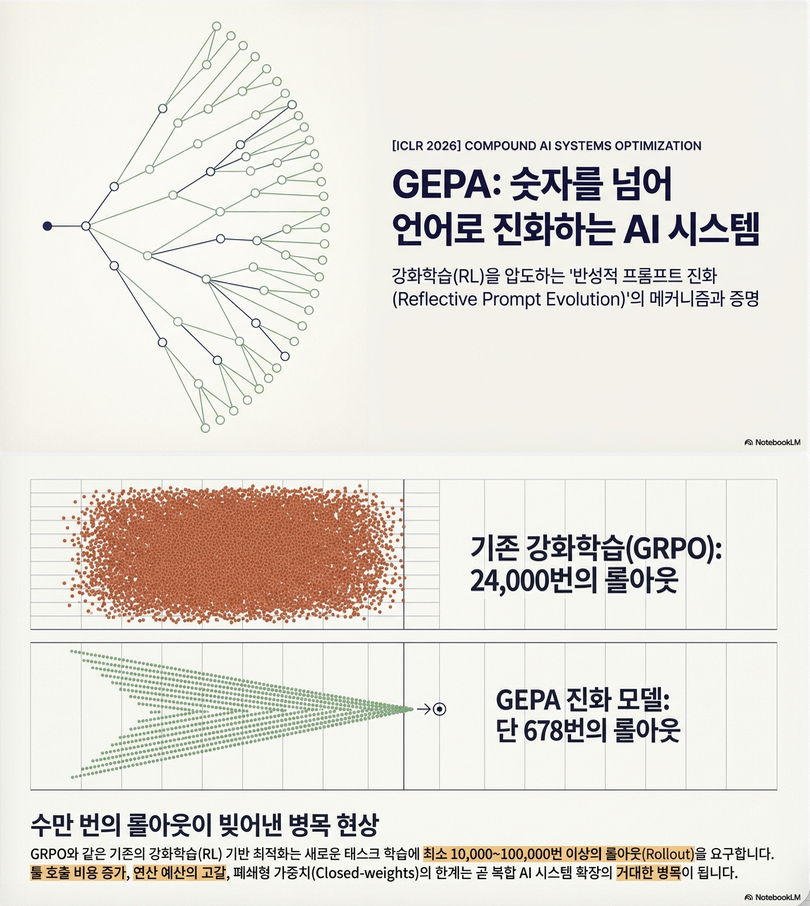
* GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning (ICLR 2026)
1. 핵심 아이디어 (Executive Summary) 이 논문은 다음 질문에서 출발합니다: “LLM을 downstream task에 맞게 최적화할 때, RL(예: GRPO)이 정말 최선인가?” 결론: 이를 위해 제안한 방법이: GEPA (Genetic-Pareto Prompt Optimization) 2. 문제 설정 (Problem Formulation) 논문은 LLM 시스템을 다음과 같이 정의합니다: maxΠ,Θ𝔼(x,m)∼Tμ(Φ(x;Π,Θ),m)\max_{\Pi, \Theta} \mathbb{E}_{(x,m)\sim T} \mu(\Phi(x; \Pi, \Theta), m) 핵심 제약: 3. GEPA 방법론 3.1 전체…
-

* Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs (EMNLP 2024)
핵심 질문 여러 단계로 구성된 LM pipeline에서 instruction + few-shot demo를 어떻게 jointly 최적화할 것인가? 1. 문제 설정 (Problem Formulation) LM Program 정의 목표 전체 프로그램 성능을 최대화: Φ∗=argmaxV→S𝔼(x,x′)∼Dμ(ΦV→S(x),x′)\Phi^* = \arg\max_{V \to S} \mathbb{E}_{(x,x’) \sim D} \mu(\Phi_{V \to S}(x), x’) 중요한 점: 즉, credit assignment problem + combinatorial search 2. 핵심 문제 (Challenges) 논문에서 명확히…
-
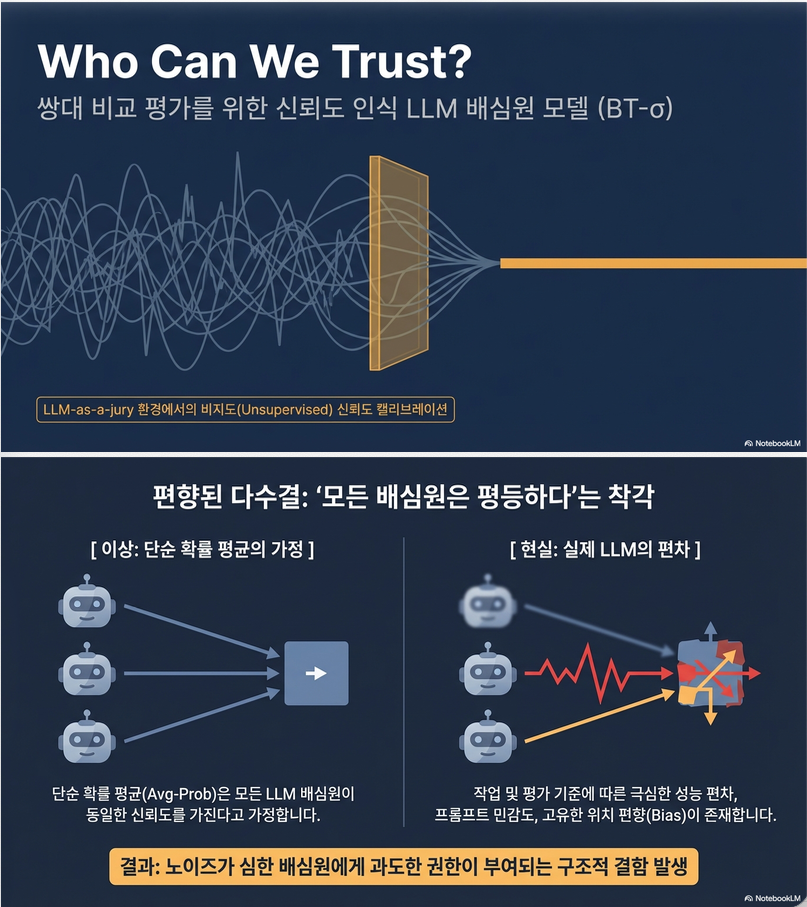
Who can we trust? LLM-as-a-jury for Comparative Assessment (ArXiv 2026)
논문 핵심 요약 Who can we trust? LLM-as-a-jury for Comparative Assessment ✔ 문제: 여러 LLM judge를 평균내면 성능이 최적이 아님 ✔ 원인: 각 LLM의 신뢰도 / 일관성 / bias가 다름 ✔ 해결: BT-σ (Bradley–Terry + judge reliability) (1) 문제 설정: LLM-as-a-judge → LLM-as-a-jury 기존 방식 하지만: 문제점 예: –> 이로 인해 확률 기반 ranking이 깨짐 …
-

* ReAct: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS (ICLR 2023)
1. 핵심 아이디어 (Core Insight) ReAct = Reasoning + Acting의 통합 프레임워크 LLM이 **추론(Thought)**과 **행동(Action)**을 번갈아 수행하도록 만들어 외부 환경과 상호작용하며 문제를 해결하는 방식 핵심 개념: 논문 정의: 2. 방법론 (Methodology) 2.1 ReAct Trajectory 구조 각 step은 다음 3가지로 구성: 예시 (논문 Figure 1): 핵심 특징: 구성 요소 역할 Thought reasoning / 계획 / 상태…
-

A Survey of Context Engineering for Large Language Models (ArXiv 2025)
다음 논문은 최근 LLM 연구에서 매우 중요한 흐름인 **“Context Engineering”**을 체계적으로 정리한 대규모 survey입니다. 1. 핵심 개념 (Paper Summary) 이 논문의 핵심 메시지는 다음 한 줄로 요약됩니다: LLM 성능은 “모델 파라미터”보다 “컨텍스트 설계”에 의해 결정된다. 기존: 제안: 2. Context Engineering의 정의 (수식 기반) 논문은 CE를 명확하게 최적화 문제로 formalization 합니다. (1) 기본 LLM 모델 Pθ(Y|C)=∏t=1TPθ(yt|y<t,C)P_\theta(Y|C)…
-

A-MEM: Agentic Memory for LLM Agents (ArXiv 2025)
1. 문제 정의 (Why?) LLM agent는 tool 사용 + reasoning은 강하지만: 기존 memory 시스템의 한계 핵심 문제: “LLM agent가 경험을 통해 지식 구조 자체를 진화시키지 못한다” 2. 핵심 아이디어: Agentic Memory 기존 vs A-MEM 구분 기존 Memory A-MEM 구조 static dynamic link 생성 predefined LLM이 생성 업데이트 없음 memory evolution 역할 storage self-organizing knowledge system…
-

*** Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models (ICLR 2026)
1. 문제 설정: “Context engineering”의 한계 기존 패러다임 LLM 성능 향상 방식: 즉, 최근 트렌드는 “모델을 바꾸지 말고, 입력(context)을 바꿔라” 그러나 기존 방법의 핵심 문제 (1) Brevity Bias (2) Context Collapse 실제 사례: 핵심 insight: “LLM은 summary보다 rich context에서 더 잘 동작한다” 2. 핵심 아이디어: Context = “Evolving Playbook” ACE의 핵심 주장: Context는 “짧은 요약”이…
-

* Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation (COLM 2025)
다음 논문은 LLM-as-a-judge 평가에서 “피드백 프로토콜(pairwise vs pointwise)” 자체가 편향을 만든다는 점을 체계적으로 분석한 연구입니다. 논문 개요 Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation 핵심 질문 LLM 평가에서 –> 어떤 방식이 더 신뢰할 수 있는 평가를 만드는가? 1. 문제 설정: Feedback Protocol이 만드는 Bias 논문은 평가 방식 자체가 bias를 유도한다고 주장합니다.…
-

** A Survey on LLM-as-a-Judge (arXiv 2024)
1. 개요 (Paper Summary) 이 논문은 **LLM-as-a-Judge (LLM을 평가자로 사용하는 패러다임)**에 대한 첫 체계적 survey입니다. 핵심 문제의식 핵심 질문 논문은 다음 4가지 질문으로 전체 구조를 정리함: 특히 **“reliability (신뢰성)”**을 중심 축으로 모든 내용을 통합함 2. LLM-as-a-Judge 정의 (Formalization) 논문은 LLM-as-a-Judge를 다음처럼 수식화함: 기본 정의 E←PLLM(x⊕︎C)E \leftarrow P_{\text{LLM}}(x \oplus C) 즉, evaluation = conditional generation 문제…
-
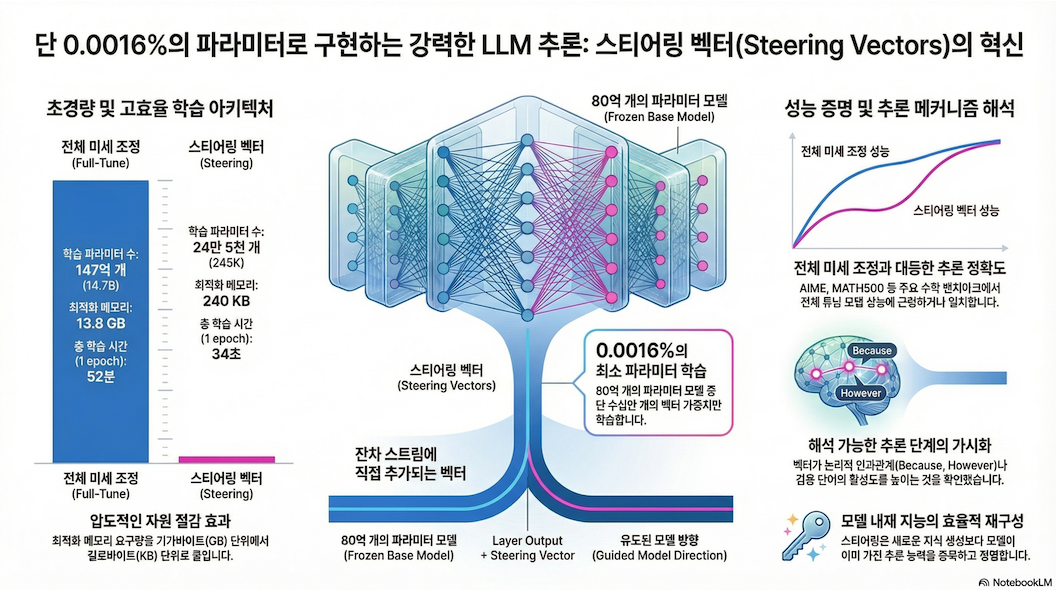
* Steering LLM Reasoning Through Bias-Only Adaptation (ArXiv 2025)
1. 핵심 아이디어 (TL;DR) 이 논문의 핵심은 매우 명확합니다: “LLM의 reasoning 능력은 매우 적은 파라미터 (layer별 vector)만 학습해도 충분히 끌어낼 수 있다.” 즉, reasoning은 “새로 학습되는 능력”이 아니라 이미 존재하는 능력을 특정 방향으로 “증폭(amplify)”하는 것이라는 강한 근거 제공 2. 방법론 (Methodology) 2.1 Steering Vector 정의 각 transformer layer ℓ에 대해: 다음과 같이 단순히 더함: hℓ,t←hℓ,t+sℓh_{\ell,t}…
-
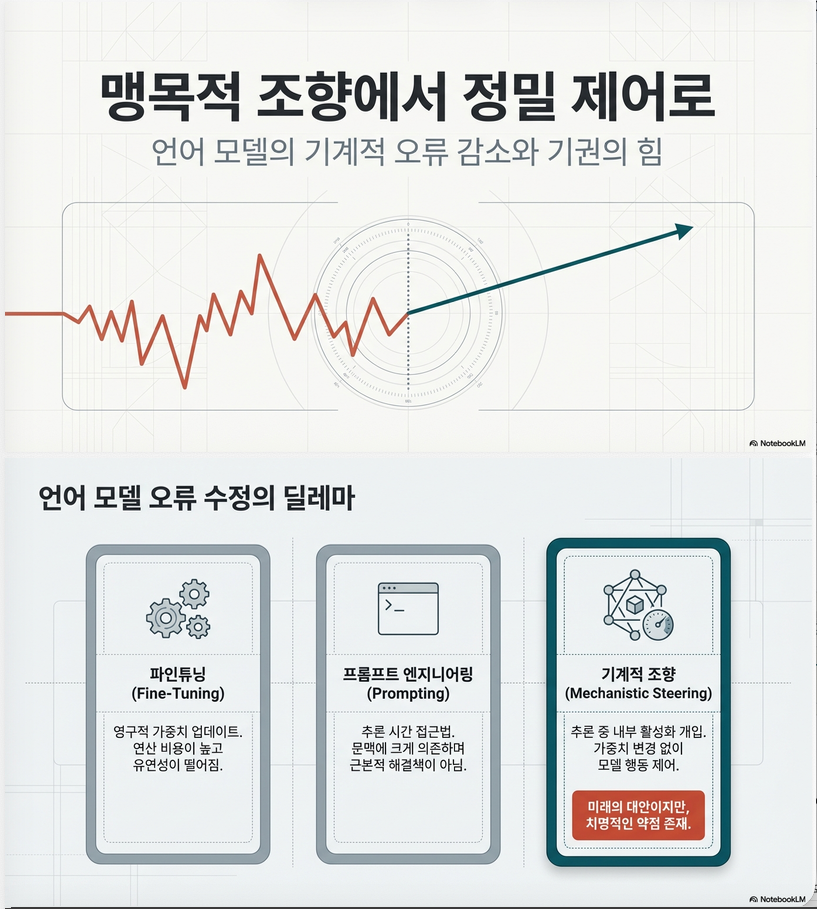
** To Steer or Not to Steer? Mechanistic Error Reduction with Abstention for LMs (ICLR 2026)
1. 핵심 문제의식 (Why this paper matters) 기존 steering 연구들의 공통 한계: 기존 방식 즉, “steering 방향”보다 더 중요한 문제 = steering 강도 결정 2. 핵심 아이디어: MERA 논문은 다음 질문을 해결합니다: 언제 steering을 해야 하고, 얼마나 해야 하는가? 이를 위해 제안된 프레임워크: MERA (Mechanistic Error Reduction with Abstention) 핵심 구성: 3. 기존 Steering vs…
-

** Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms (COLM 2024)
다음 논문은 **mechanistic interpretability (특히 circuits 분석)**에서 매우 중요한 문제를 짚는 연구입니다: “Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms” (COLM 2024) 1. 핵심 문제의식 (Why this paper matters) 기존 circuit 연구의 암묵적 가정: “찾은 circuit이 ground-truth circuit과 **overlap이 크면 → 잘 찾은 것” 하지만 이 논문은 이를 정면으로 반박합니다: 핵심…
-

* A survey and benchmark of high-dimensional Bayesian optimization of discrete sequences (NeurIPS 2024)
이 논문은 고차원 이산 시퀀스(예: 분자, 단백질) 최적화를 위한 Bayesian Optimization (BO) 방법들을 체계적으로 정리 + 벤치마크한 NeurIPS 2024 논문입니다. 1. 핵심 요약 (Executive Summary) 2. 문제 정의 Bayesian Optimization 기본 구조 BO는 다음 두 요소로 구성됨: sequential optimization: surrogate 업데이트 → acquisition 최적화 → 새로운 point 평가 논문에서도 이를 명확히 설명: “BO는 surrogate model과…
-

* Self-Critique and Refinement for Faithful Natural Language Explanations (EMNLP 2025)
다음 논문은 LLM이 생성하는 자연어 설명(NLE)의 “faithfulness(충실성)”을 어떻게 개선할 것인가를 다룬 매우 중요한 연구입니다. 핵심은 모델이 스스로 자신의 설명을 비판하고 수정할 수 있는가입니다. 1. 문제 정의 (Why this paper?) 핵심 문제: NLE의 “비충실성 (Unfaithfulness)” 예: 즉, plausible explanation ≠ faithful explanation 2. 핵심 아이디어: SR-NLE Self-Critique + Refinement 논문에서 제안한 프레임워크: SR-NLE (Self-critique and Refinement…
-

* Towards Faithful Natural Language Explanations: A Study Using Activation Patching in LLMs (EMNLP 2025)
다음 논문은 LLM의 Natural Language Explanation (NLE)의 “faithfulness(충실성)”을 내부 causal 관점에서 측정하는 매우 중요한 메커니즘 기반 연구입니다 1. 핵심 문제 정의 문제 LLM은 CoT 등으로 **그럴듯한 설명(plausible explanation)**을 잘 생성하지만, 이 설명이 실제 내부 reasoning을 반영하는지 (faithful) 는 별개 즉, Faithfulness 정의 논문은 다음 정의를 채택: “Explanation이 모델의 실제 reasoning process를 얼마나 정확히 반영하는가” 즉,…
-

*** The Probabilities Also Matter: A More Faithful Metric for Faithfulness of Free-Text Explanations in LLMs (ACL 2024)
1. 문제 정의 (핵심 동기) LLM이 생성하는 explanation (CoT, NLE 등)는 그럴듯하지만 실제 reasoning을 반영하지 않을 수 있음. 즉, plausibility ≠ faithfulness 논문은 다음 질문을 다룸: “설명이 모델의 실제 결정 과정과 얼마나 일치하는가?” 2. 기존 접근의 한계: Counterfactual Test (CT) CT 방식 (기존 SOTA) CT의 두 가지 치명적 문제 (1) “언급 여부만” 평가 → trivial…
-

** Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits (ArXiv 2025)
이 논문은 “LLM이 자신의 답이 틀렸다는 것을 스스로 예측할 수 있는가?”라는 질문을 다룹니다. 핵심 아이디어는 텍스트나 외부 judge 모델이 아니라 LLM 내부 activation(숨겨진 상태와 attention)에서 직접 오류 신호를 읽어내는 것입니다. 아래에서 연구 문제 → 핵심 아이디어 → 방법론(Gnosis) → 실험 결과 → 연구적 의미 순서로 정리합니다. 1. 연구 문제 (Problem) LLM의 대표적인 문제: 하지만 LLM은…
-

Learning to Reason in 13 Parameters (ArXiv 2026)
1. 연구 배경 및 문제의식 최근 LLM에서 reasoning 능력 향상은 주로 다음 방식으로 이루어집니다. 하지만 기존 접근의 문제는 다음입니다. 방법 학습 파라미터 규모 Full Finetuning 수십억 LoRA 수백만 LoRA rank=1 약 3M 즉 parameter-efficient tuning이라 해도 여전히 수백만 파라미터가 필요합니다. 논문의 핵심 질문: Reasoning을 학습하는 데 정말 수백만 파라미터가 필요한가? 이 논문은 놀라운 결과를 보여줍니다.…