[카테고리:] Attention head
-

* A Mathematical Framework for Transformer Circuits (Transformer Circuits 2021)
이 논문은 오늘날 Mechanistic Interpretability 분야의 출발점 중 하나로 평가받습니다. 특히 이후의 등의 연구들이 사실상 이 논문의 수학적 프레임워크 위에서 발전되었습니다. 1. 논문의 핵심 질문 Transformer 내부를 회로(circuit)처럼 해석할 수 있는가? 기존 Transformer 수식: Q=XWQQ=XW_Q K=XWKK=XW_K V=XWVV=XW_V A=softmax(QKT)A=\text{softmax}(QK^T) Y=AVWOY=AVW_O 은 학습과 구현에는 편하지만, “이 head가 실제로 무엇을 하는가?” 를 이해하기 어렵습니다. 저자들은 Transformer를 “token…
-

*** Steering at the Source: Style Modulation Heads for Robust Persona Control (ArXiv 2026)
1. 핵심 문제의식 (Problem Setting) 기존 Activation Steering의 한계 중요한 관찰 2. 핵심 아이디어 (Core Insight) 문제의 원인 기존 방식: 문제: 제안: “Where to steer” 기존 연구: 이 논문: “어디에 steering 해야 하는가?” 3. 핵심 발견: Style Modulation Heads 발견 내용 → 이를 Style Modulation Heads (SMH)라고 정의 특징 속성 설명 sparsity 매우 적은 head만…
-

** Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits (ArXiv 2025)
이 논문은 “LLM이 자신의 답이 틀렸다는 것을 스스로 예측할 수 있는가?”라는 질문을 다룹니다. 핵심 아이디어는 텍스트나 외부 judge 모델이 아니라 LLM 내부 activation(숨겨진 상태와 attention)에서 직접 오류 신호를 읽어내는 것입니다. 아래에서 연구 문제 → 핵심 아이디어 → 방법론(Gnosis) → 실험 결과 → 연구적 의미 순서로 정리합니다. 1. 연구 문제 (Problem) LLM의 대표적인 문제: 하지만 LLM은…
-

* Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering (ArXiv 2024)
논문 “Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering” (Pochinkov et al., 2024) 은 Transformer 기반 모델의 주의(attention) 뉴런 해석과 절제(ablation) 방법을 체계적으로 비교하고, 새로운 방식인 **Peak Ablation (정점 중심 절제)**을 제안한 연구입니다. 아래에 핵심 내용을 구조적으로 정리했습니다. 1. 연구 배경 및 문제의식 기존 절제 방식: 2. 제안 개념: Peak Ablation…
-

*** Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps (EMNLP 2024)
다음 논문은 “Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps” (EMNLP 2024) 입니다 . 이 논문은 **LLM의 contextual hallucination(문맥 기반 환각)**을 attention map만을 사용해 탐지하고, decoding 단계에서 이를 완화하는 방법을 제안합니다. 1. 문제 정의: Contextual Hallucination 논문은 환각을 두 종류로 구분합니다: 이 논문은 **후자(context-grounded setting)**에 집중합니다. 대표 예:…
-
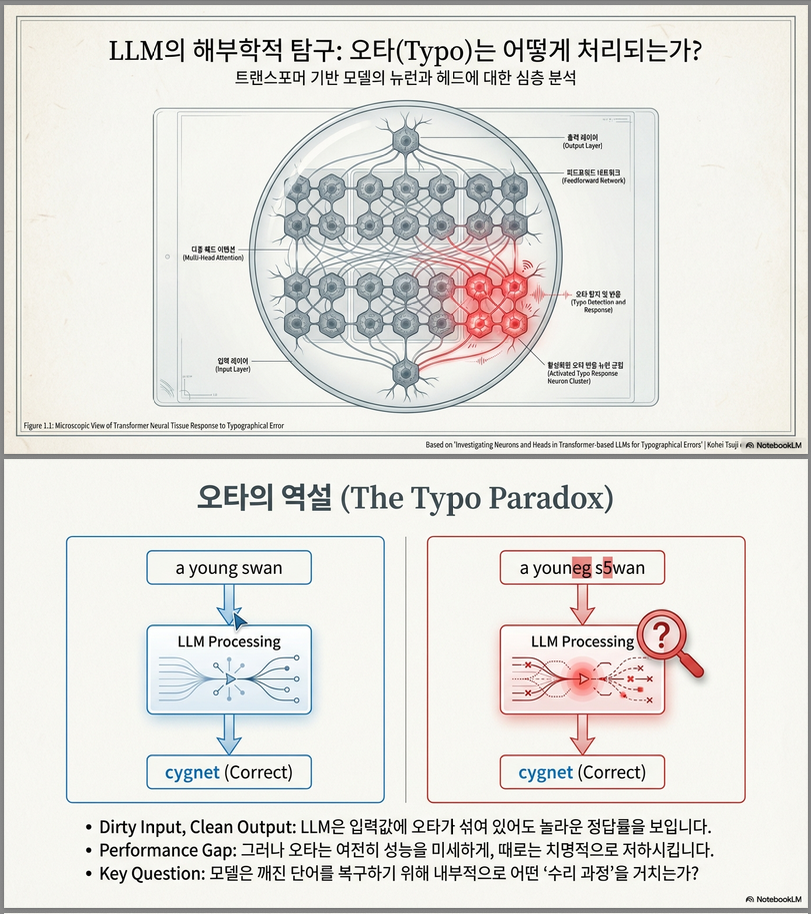
*** Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors (EMNLP 2025)
다음은 **EMNLP 2025 논문 “Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors”**에 대한 핵심 정리입니다. 연구 동기 LLM 입력에는 종종 **오타(typo)**가 포함되며, 모델은 때때로 이를 내부적으로 보정해 올바른 의미를 복원합니다. 그러나 경우에 따라 오타는 모델의 성능 저하를 유발합니다. 이 연구는: 어떤 뉴런(neurons)과 어떤 어텐션 헤드(attention heads)가 오타를 감지·보정하는지 밝혀내는 것이 목표입니다. 주요 연구…
-

** Retrieval Head Mechanistically Explains Long-Context Factuality (ICLR 2024)
아래는 「Retrieval Head Mechanistically Explains Long-Context Factuality」(ICLR 2024) 논문의 핵심을 문제의식 → 방법론 → 주요 발견 → 실험적 근거 → 시사점 순서로 정리한 설명입니다. 1. 문제의식 장문 컨텍스트(수만~십만 토큰)에서 LLM이 어떻게 필요한 정보를 정확히 찾아(faithful retrieval) 출력하는지 내부 메커니즘은 불분명했다. 특히 Needle-in-a-Haystack 유형에서 사실성이 유지되는 이유를 어떤 내부 구성요소가 담당하는가가 핵심 질문이다. 2. 핵심 가설…
-

*** Improving Contextual Faithfulness of Large Language Models via Retrieval Heads-Induced Optimization (ACL 2025)
논문 “Improving Contextual Faithfulness of Large Language Models via Retrieval Heads-Induced Optimization” (ACL 2025 Long Paper) 은 RAG 기반 LLM의 신뢰도 문제, 특히 문맥적 정합성(contextual faithfulness) 을 향상시키는 새로운 방법을 제안한 연구입니다 . 1. 연구 배경 2. 주요 아이디어: RHIO 프레임워크 RHIO = Retrieval Heads-Induced Optimization “retrieval head를 마스킹하여 비충실(unfaithful)한 샘플을 인위적으로 만들고, 이를 이용해…
-

*** Interpret and Improve In-Context Learning via the Lens of Input-Label Mappings (ACL 2025)
논문 **“Interpret and Improve In-Context Learning via the Lens of Input-Label Mappings” (ACL 2025)**는 대형 언어 모델(LLM)의 In-Context Learning (ICL) 능력을 **입력-레이블 매핑(input-label mappings)**의 관점에서 분석하고, 해당 메커니즘을 해석하며, 향상시키는 방법을 제안합니다. 1. 연구 질문 LLM의 ICL 성능을 분석하기 위해 다음 세 가지 질문을 다룹니다: 2. 주요 기여 (1) 입력-레이블 매핑의 발견 (2) PC Patching 기법 (3) 매핑…
-
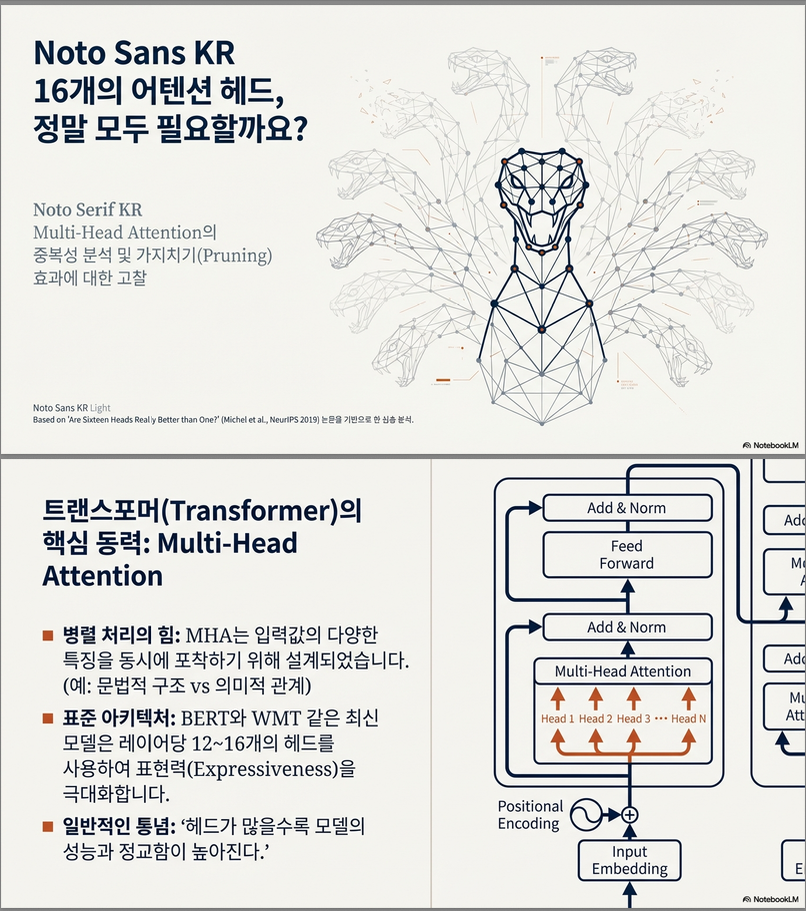
* Are Sixteen Heads Really Better than One? (NeurIPS 2019)
이 논문은 **Transformer의 multi-head attention(MHA)가 정말로 많은 head를 필요로 하는가?**라는 매우 직관적인 질문을 실증적으로 파고든 고전적인 분석 논문입니다. 아래에서 문제의식 → 방법론 → 실험 결과 → 핵심 해석 → 이후 연구에 미친 영향 순서로 정리해 드릴게요. (논문: Are Sixteen Heads Really Better than One?, NeurIPS 2019) 1. 문제의식 (Motivation) Transformer에서 multi-head attention은 다음과 같은 이유로…