

1. 핵심 아이디어 (Core Insight)
ReAct = Reasoning + Acting의 통합 프레임워크
LLM이 **추론(Thought)**과 **행동(Action)**을 번갈아 수행하도록 만들어
외부 환경과 상호작용하며 문제를 해결하는 방식
- 기존:
- CoT → reasoning만 (내부 지식 기반)
- Act-only → 행동만 (외부 탐색 기반)
- ReAct:
- Reason ↔ Act를 interleaving
핵심 개념:
- reason to act: 어떤 행동을 해야 할지 결정
- act to reason: 외부 정보를 얻어 reasoning 업데이트
논문 정의:
- action space 확장:
- A: 환경 행동
- L: language (thought)
2. 방법론 (Methodology)
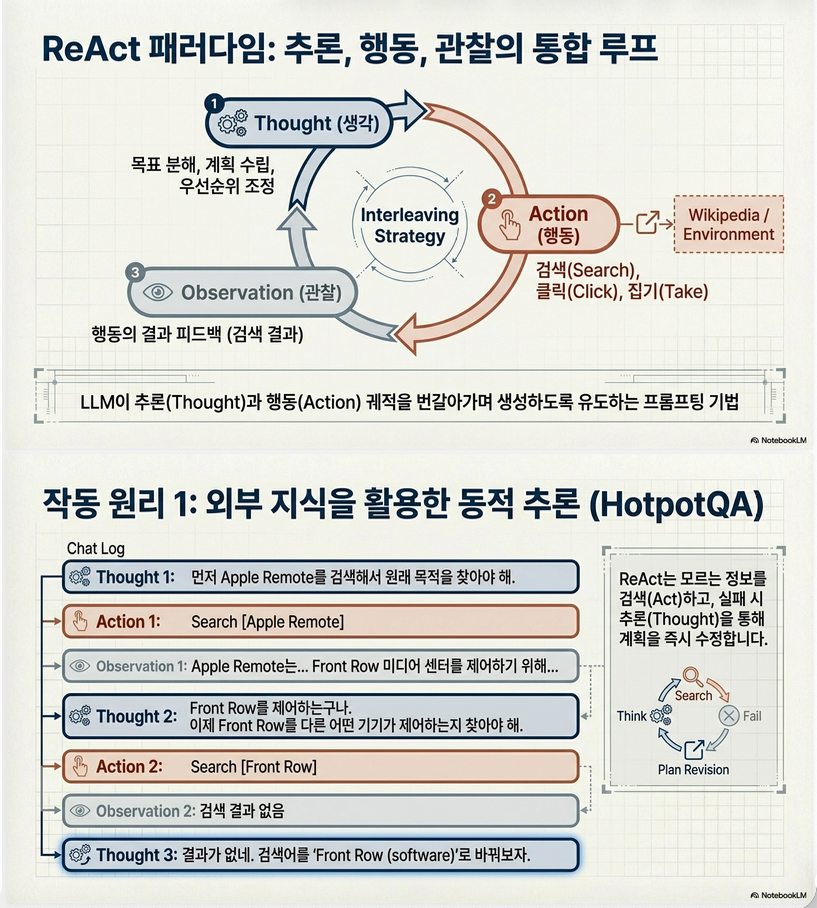
2.1 ReAct Trajectory 구조
각 step은 다음 3가지로 구성:
Thought → Action → Observation예시 (논문 Figure 1):
Thought: 먼저 Apple Remote 검색해야겠다
Action: Search[Apple Remote]
Observation: ...핵심 특징:
| 구성 요소 | 역할 |
|---|---|
| Thought | reasoning / 계획 / 상태 추적 |
| Action | 외부 환경 interaction |
| Observation | 환경 feedback |
2.2 Prompting 방식
- Few-shot trajectory를 prompt에 넣음
- 사람이 직접 작성한 reasoning + action 시퀀스
특징:
- no training 필요 (pure prompting)
- 하지만 이후 fine-tuning 가능
2.3 Thought의 기능 (중요)
논문에서 정의한 thought의 역할:
- 문제 분해 (decomposition)
- 정보 추출 (from observation)
- commonsense reasoning
- search reformulation
- plan tracking
즉, 단순 CoT보다 훨씬 action-aware reasoning
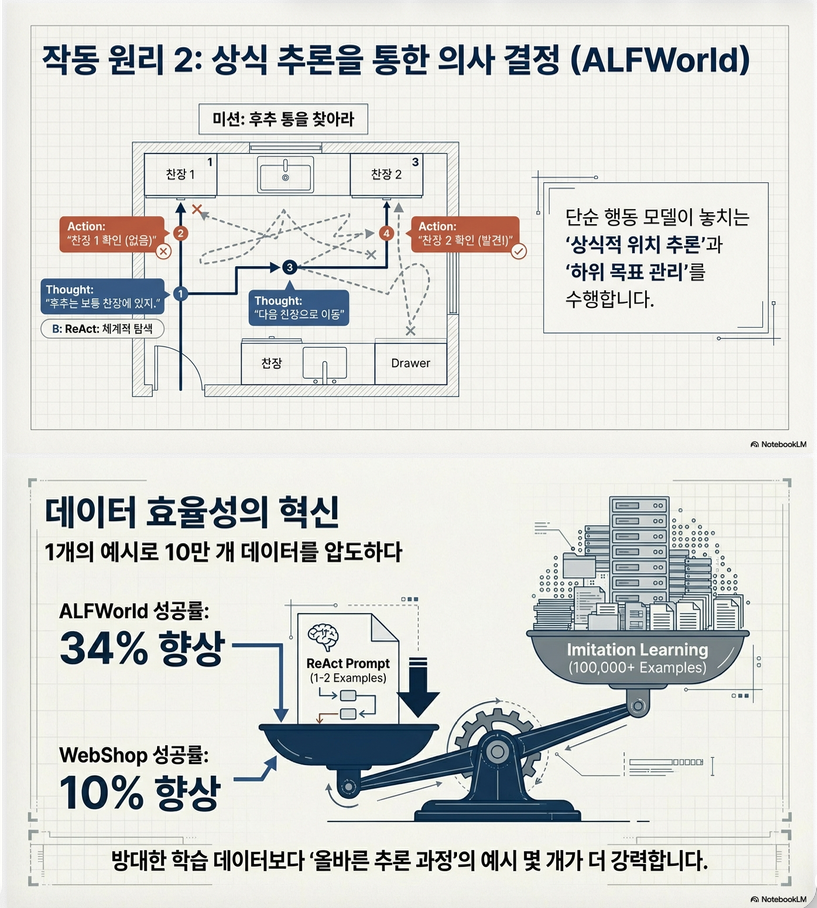
2.4 Dense vs Sparse Reasoning
| Task 유형 | Reasoning 전략 |
|---|---|
| QA (HotpotQA) | dense (매 step마다) |
| ALFWorld | sparse (필요할 때만) |
중요한 insight:
- reasoning은 항상 필요한 게 아니라 adaptive하게 사용됨
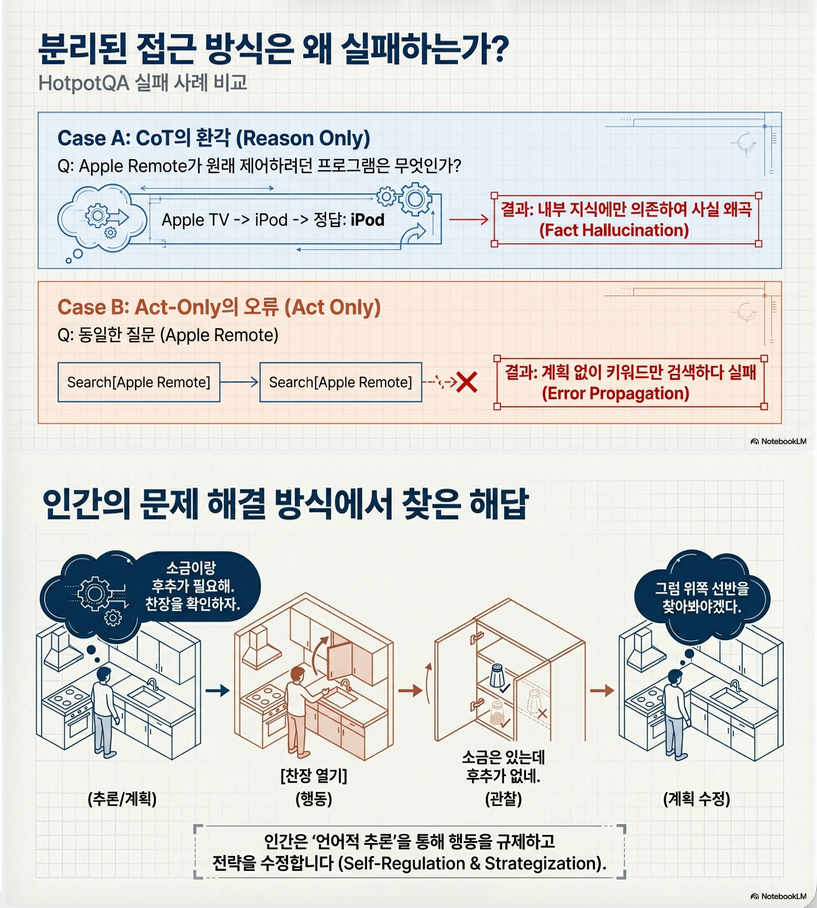
3. 기존 방법과 비교
3.1 4가지 패러다임 비교
| 방법 | 특징 | 문제 |
|---|---|---|
| Standard | 바로 답 | reasoning 없음 |
| CoT | reasoning만 | hallucination |
| Act-only | 행동만 | 계획 없음 |
| ReAct | reasoning + action | ✔ 균형 |
Figure 1 비교에서 확인 가능

3.2 핵심 차별점
(1) CoT의 한계 해결
- CoT:
- internal reasoning만 → hallucination
- ReAct:
- external retrieval → grounding
결과:
- hallucination 감소
(2) Act-only의 한계 해결
- Act-only:
- blind search
- ReAct:
- reasoning-guided search
결과:
- search efficiency 증가
4. 실험 결과 (핵심)
4.1 Knowledge Task (HotpotQA, FEVER)
| 방법 | HotpotQA | FEVER |
|---|---|---|
| CoT | 29.4 | 56.3 |
| Act | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
–> FEVER에서 특히 강함 (retrieval 중요 task)
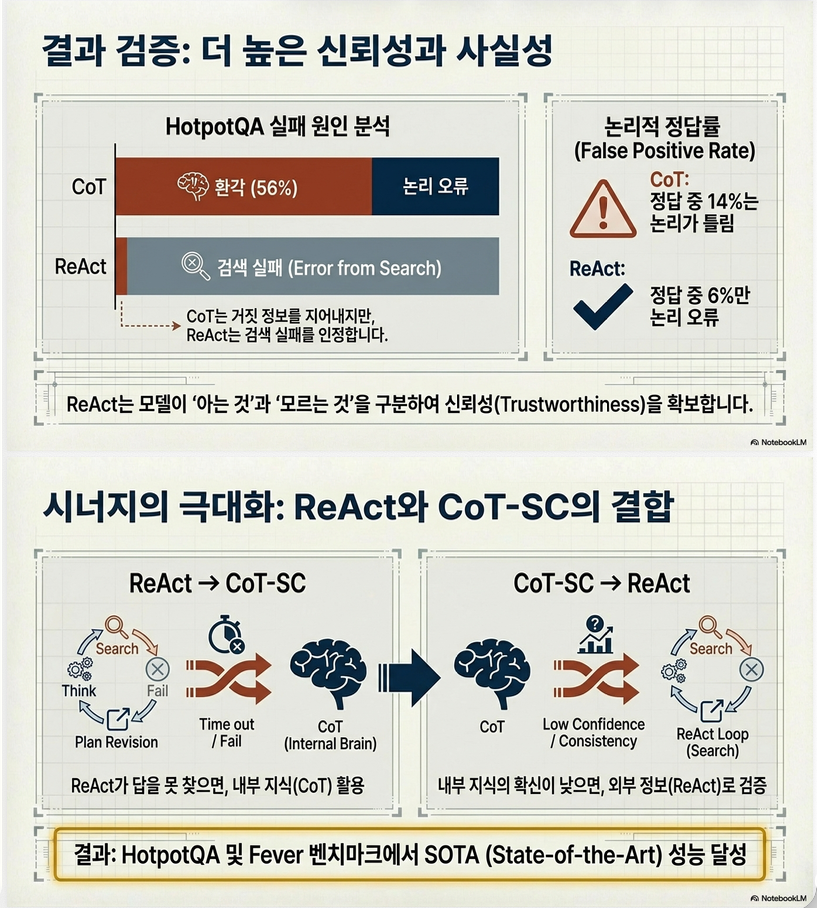
4.2 결합 전략 (매우 중요)
ReAct + CoT-SC
- 최고 성능
전략:
- ReAct 실패 → CoT fallback
- CoT 불확실 → ReAct fallback
–> 내부 지식 + 외부 지식 결합
4.3 Decision Making Task
ALFWorld
- ReAct: 71%
- Act-only: 45%
- RL baseline: 37%
–> +34% improvement
WebShop
- ReAct: 40% success
- IL/RL: ~29%
–> 실제 환경에서도 효과
5. 분석 (논문에서 매우 중요한 부분)
5.1 CoT vs ReAct failure 분석
| 유형 | ReAct | CoT |
|---|---|---|
| hallucination | 0% | 56% |
| reasoning error | 47% | 16% |
trade-off:
- ReAct:
- ✔ grounded
- X reasoning flexibility ↓
- CoT:
- ✔ flexible reasoning
- X hallucination
5.2 핵심 Insight
“Reasoning without grounding → hallucination
Acting without reasoning → inefficiency”
–> ReAct = 둘의 균형
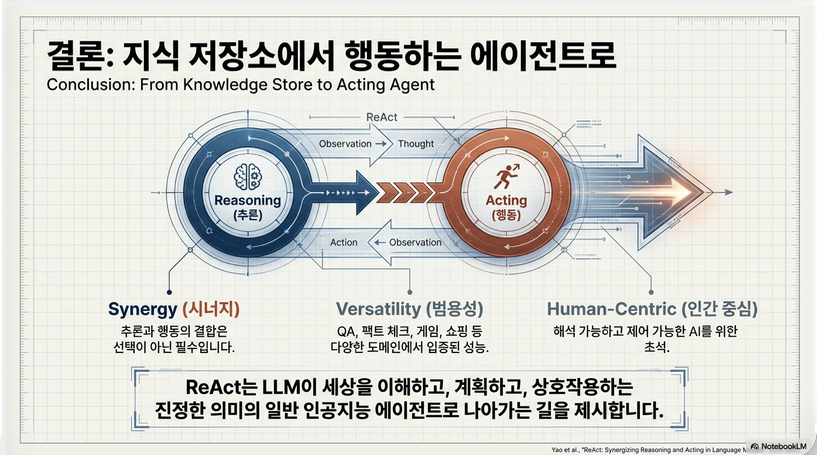
6. 중요한 연구적 의미
6.1 LLM을 “Agent”로 확장
ReAct는 단순 LLM → interactive agent로 전환
–> policy learning 관점
6.2 Cognitive perspective
논문에서 강조:
- 인간:
- thinking + acting 반복
- ReAct:
- 이를 LLM에 구현
6.3 이후 연구 영향 (매우 중요)
ReAct는 다음 분야의 기반:
- Tool use (Toolformer, function calling)
- Agent framework (AutoGPT, LangChain agents)
- RAG + reasoning 통합
- Planning LLM
7. 한계 (논문 기준)
- Prompt engineering 의존
- reasoning + action 동시에 학습 어려움
- long trajectory → context 길이 문제
- search quality에 의존
ReAct 방법론 (Methodology)
1. 문제 설정 (Formalization)
ReAct는 LLM을 environment-interacting agent로 모델링합니다.
상태 정의
- o_t: observation (환경으로부터)
- a_t: action 또는 thought
정책
–> 핵심:
- LLM이 policy model 역할
2. Action Space 확장 (핵심 아이디어)
기존:
A
ReAct:
- A: 환경 action (search, click, move 등)
- L: language action (thought)
3. Trajectory 구조
ReAct는 interleaved trajectory를 생성:
Thought_t → Action_t → Observation_tStep dynamics
- Thought 생성:
- Action 생성:
- Observation:
- Context 업데이트:
4. Thought의 역할 (핵심 설계 요소)
Thought는 environment를 바꾸지 않는 action:
기능 분해
논문에서 명시된 thought 유형:
- Decomposition
- “먼저 X를 찾고 Y를 확인해야 한다”
- Information extraction
- observation에서 정보 추출
- Commonsense reasoning
- Search planning
- 어떤 query를 사용할지 결정
- Progress tracking
- Exception handling
핵심:
Thought = planning + working memory + reasoning
5. Prompting 기반 학습 (핵심 구현)
ReAct는 학습 없이 prompt로 작동
입력 구조
[Example trajectories]
Question: ...
Thought: ...
Action: ...
Observation: ...
...출력
- 다음 token prediction으로:
- Thought 또는 Action 생성
6. Trajectory 생성 방식
(A) Dense reasoning (QA)
Thought → Action → Obs → Thought → Action → ...- 매 step마다 thought
사용:
- HotpotQA
- FEVER
(B) Sparse reasoning (Decision making)
Action → Action → Thought → Action → ...- 필요할 때만 thought
사용:
- ALFWorld
- WebShop
7. Action Space 설계 (Task별)
(1) QA (Wikipedia API)
Action set:
search[entity]
lookup[string]
finish[answer](2) Decision Making
예:
- go to location
- pick object
- buy product
자연어 → structured action
8. In-context Learning 방식
Few-shot trajectories
- HotpotQA: 6 examples
- FEVER: 3 examples
특징:
- human-written trajectory
- reasoning + action 포함
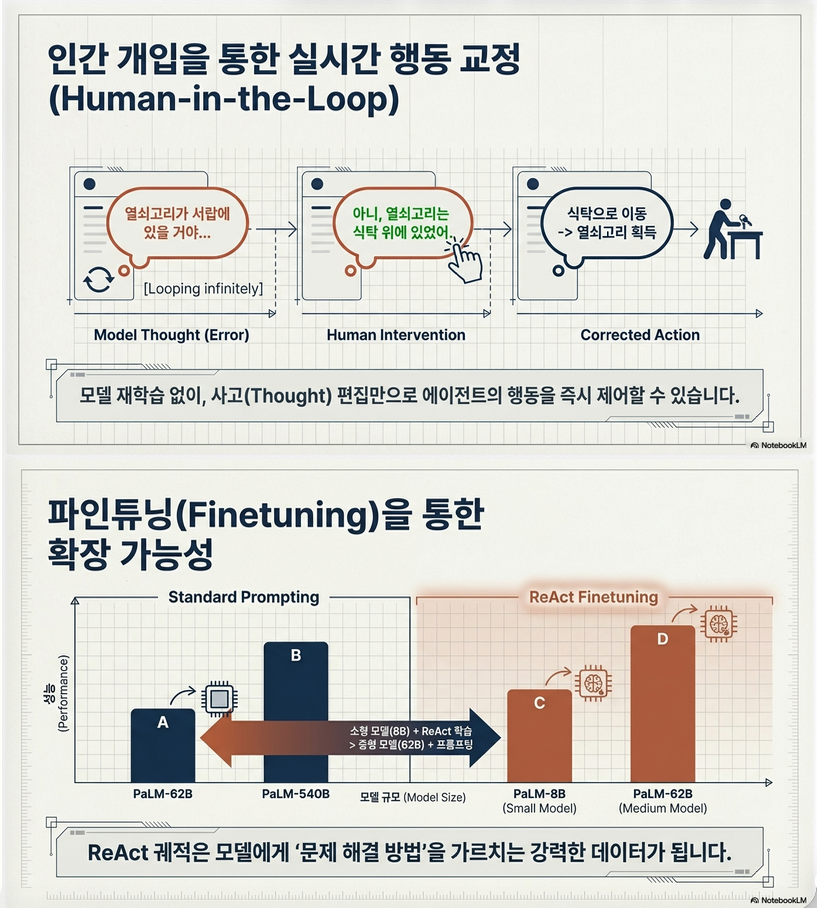
9. Hybrid 전략 (중요)
ReAct 단독이 아니라:
(1) ReAct → CoT fallback
조건:
- step 제한 초과
(2) CoT → ReAct fallback
조건:
- self-consistency 불확실
10. Fine-tuning 확장
데이터 생성
- ReAct로 trajectory 생성
- correct answer만 필터링
학습 목표
–> trajectory 전체를 supervision으로 사용
11. 알고리즘 (Pseudo-code)
context = [input_question]
for t in range(T):
# 1. Thought 생성
thought = LLM.generate("Thought:", context)
context.append(thought)
# 2. Action 생성
action = LLM.generate("Action:", context)
context.append(action)
# 3. Environment interaction
observation = Env(action)
context.append(observation)
# 4. 종료 조건
if action.startswith("finish"):
break12. 핵심 메커니즘 요약
(1) Reason → Act
- 어떤 action을 할지 결정
(2) Act → Reason
- observation 기반 reasoning 업데이트
13. 방법론의 본질 (핵심 요약)
ReAct는 다음 3가지의 결합:
1. Chain-of-Thought
- reasoning capability
2. Tool-use / API interaction
- external grounding
3. Sequential decision process
- agent policy
14. 연구적 핵심 포인트 (중요)
(A) Language = Action
–> reasoning을 action space에 포함
(B) Implicit planning → Explicit planning
- CoT: implicit
- ReAct: explicit (thought)
답글 남기기