[태그:] LLM-as-a-judge
-
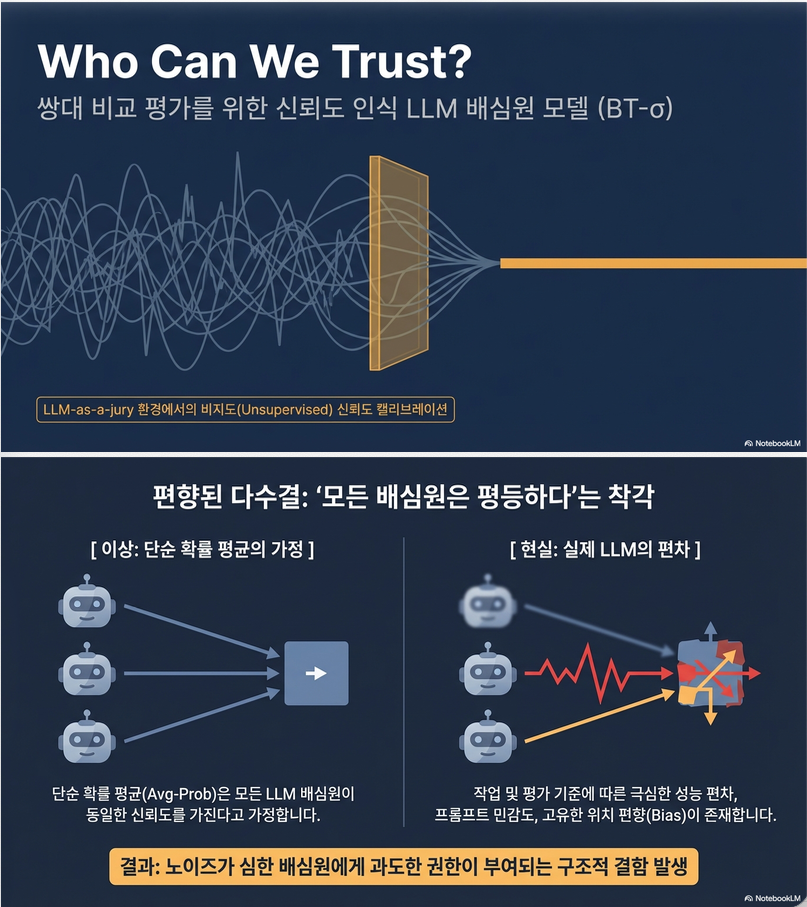
Who can we trust? LLM-as-a-jury for Comparative Assessment (ArXiv 2026)
논문 핵심 요약 Who can we trust? LLM-as-a-jury for Comparative Assessment ✔ 문제: 여러 LLM judge를 평균내면 성능이 최적이 아님 ✔ 원인: 각 LLM의 신뢰도 / 일관성 / bias가 다름 ✔ 해결: BT-σ (Bradley–Terry + judge reliability) (1) 문제 설정: LLM-as-a-judge → LLM-as-a-jury 기존 방식 하지만: 문제점 예: –> 이로 인해 확률 기반 ranking이 깨짐 …
-

* Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation (COLM 2025)
다음 논문은 LLM-as-a-judge 평가에서 “피드백 프로토콜(pairwise vs pointwise)” 자체가 편향을 만든다는 점을 체계적으로 분석한 연구입니다. 논문 개요 Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation 핵심 질문 LLM 평가에서 –> 어떤 방식이 더 신뢰할 수 있는 평가를 만드는가? 1. 문제 설정: Feedback Protocol이 만드는 Bias 논문은 평가 방식 자체가 bias를 유도한다고 주장합니다.…
-

** A Survey on LLM-as-a-Judge (arXiv 2024)
1. 개요 (Paper Summary) 이 논문은 **LLM-as-a-Judge (LLM을 평가자로 사용하는 패러다임)**에 대한 첫 체계적 survey입니다. 핵심 문제의식 핵심 질문 논문은 다음 4가지 질문으로 전체 구조를 정리함: 특히 **“reliability (신뢰성)”**을 중심 축으로 모든 내용을 통합함 2. LLM-as-a-Judge 정의 (Formalization) 논문은 LLM-as-a-Judge를 다음처럼 수식화함: 기본 정의 E←PLLM(x⊕︎C)E \leftarrow P_{\text{LLM}}(x \oplus C) 즉, evaluation = conditional generation 문제…