
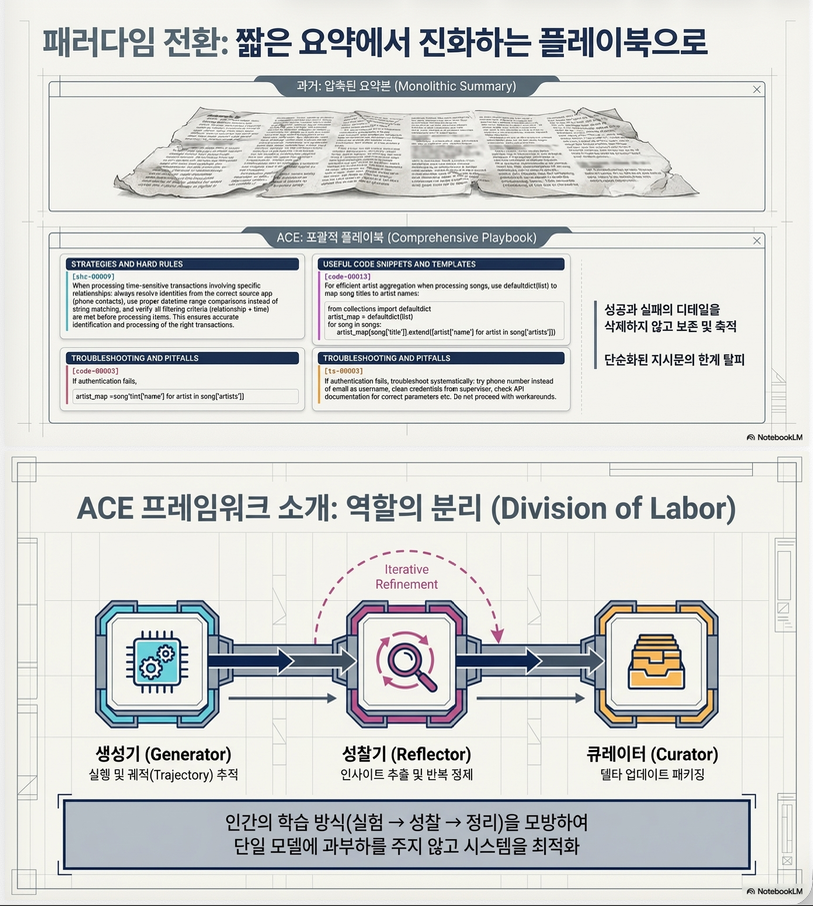


1. 문제 설정: “Context engineering”의 한계
기존 패러다임
LLM 성능 향상 방식:
- weight update (fine-tuning): 비용 큼
- context adaptation (prompt / memory / retrieval): 실용적
즉, 최근 트렌드는
“모델을 바꾸지 말고, 입력(context)을 바꿔라”
그러나 기존 방법의 핵심 문제
(1) Brevity Bias
- 반복 최적화 → 점점 짧고 generic한 prompt로 수렴
- domain-specific 전략/heuristic이 사라짐 → agent / reasoning task에서 치명적
(2) Context Collapse
- context를 매번 통째로 rewrite 하면 발생
- 정보가 점점 압축됨 → 성능 급락
실제 사례:
- 18,282 tokens → 122 tokens
- accuracy: 66.7% → 57.1%
핵심 insight:
“LLM은 summary보다 rich context에서 더 잘 동작한다”
2. 핵심 아이디어: Context = “Evolving Playbook”
ACE의 핵심 주장:
Context는 “짧은 요약”이 아니라,
지속적으로 성장하는 playbook이어야 한다
기존 vs ACE
| 방식 | 특징 | 문제 |
|---|---|---|
| GEPA / prompt optimization | concise instruction | 정보 손실 |
| Dynamic Cheatsheet | memory 축적 | collapse 발생 |
| ACE | structured evolving context | ✔ 해결 |
3. ACE 프레임워크
전체 구조 (3-agent system)
- Generator: 문제 해결 (trajectory 생성)
- Reflector: 성공/실패 분석 → insight 추출
- Curator: context 업데이트
–> 인간 학습 과정과 동일:
trial → reflection → consolidation
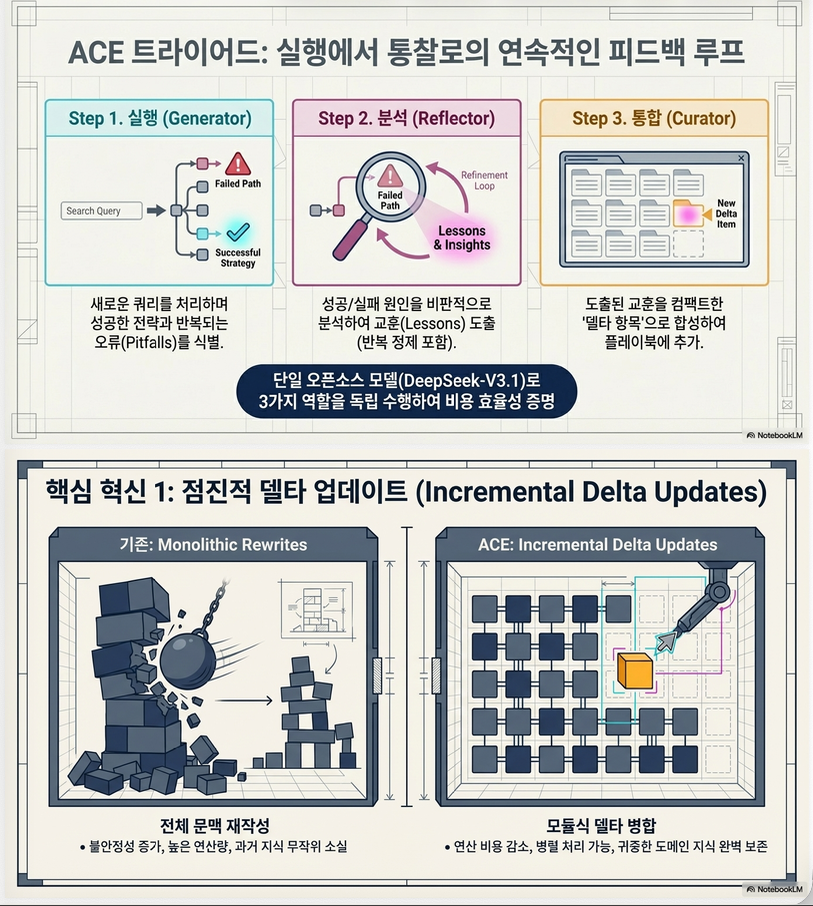
전체 루프
- Query → Generator 실행
- Trajectory 생성 (reasoning, tool use)
- Reflector:
- 성공/실패 분석
- reusable insight 추출
- Curator:
- structured “delta context” 생성
- 기존 context에 병합
4. 핵심 기술적 기여 (3가지)
4.1 Incremental Delta Update (핵심)
기존:
- context 전체 rewrite
ACE:
- 작은 단위(delta)로 업데이트
Context 구조
각 item = bullet:
{
id,
metadata (helpful count, harmful count),
content (strategy / rule / failure pattern)
}장점
- Local update (부분 수정)
- Fine-grained retrieval
- Context preservation
–> collapse 방지 핵심 메커니즘
4.2 Grow-and-Refine
단순히 늘리는 게 아니라:
- Grow: 새로운 knowledge 추가
- Refine:
- deduplication (embedding 기반)
- 중요도 업데이트
결과:
“길지만 structured + clean한 context 유지”
4.3 Reflector 분리 (중요한 설계)
기존:
- 생성 + 평가 혼합
ACE:
- Reflector를 독립 모듈로 분리
효과:
- insight quality ↑
- error propagation ↓
5. 실험 결과
Agent (AppWorld)
- +10.6% 평균 향상
- 최대 +17.1% improvement
특히:
- GT label 없이도 잘 동작 (self-improving)
Domain tasks (Finance 등)
- 평균 +8.6% 향상
- 일부 task:
- +18% 이상 improvement
비용 / 속도
- latency ↓ 최대 91.5%
- rollout ↓ 75%
- token cost ↓ 83%
핵심 이유:
- full rewrite 제거
- delta update 사용
6. 핵심 인사이트 (중요)
Insight 1: LLM은 “short prompt”보다 “rich context”를 선호
기존 가정:
concise = better
ACE 주장:
X 틀림
✔ detailed + structured = better
Insight 2: Context = Parameter-free learning
ACE는 사실상:
“test-time continual learning without weight update”
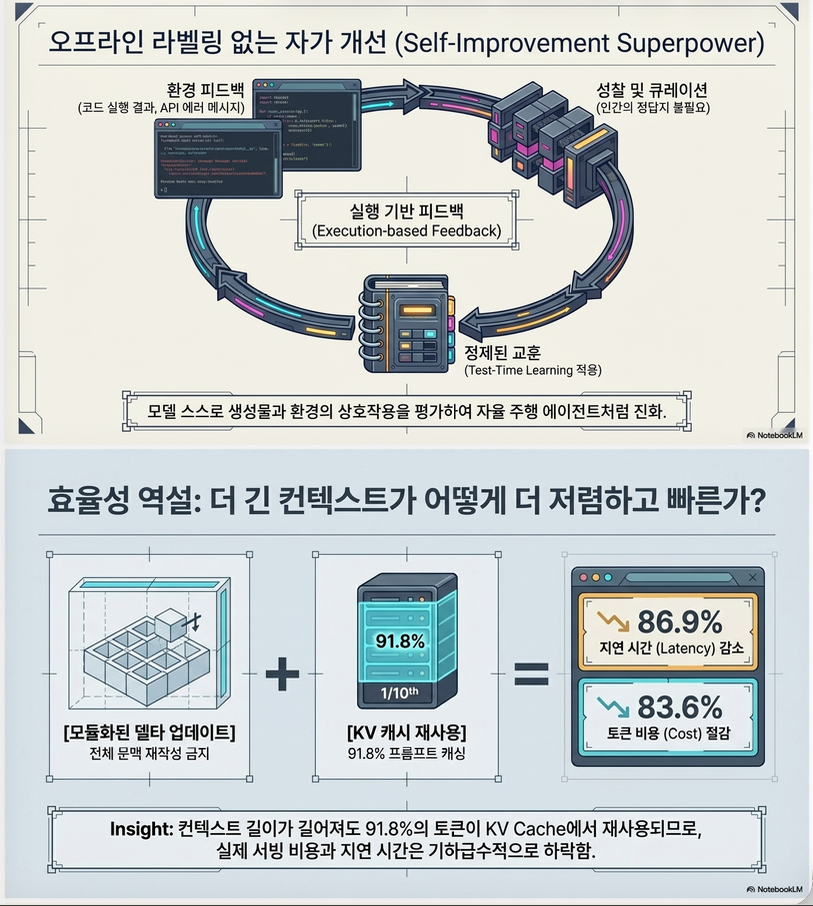
Insight 3: Self-improving system 가능
- label 없이도 가능
- execution feedback만으로 학습
7. 한계 (연구 관점)
1. Reflector 의존성
- reflection quality ↓ → context 오염
2. feedback 필요
- signal 없으면 성능 저하
3. 모든 task에 적합 X
- simple task → 긴 context 불필요
8. 한줄 요약
ACE는 **context를 static prompt가 아니라,
지속적으로 진화하는 structured memory(playbook)**로 보고
LLM을 test-time self-improving system으로 만든다.
2. 관련 연구 (Related Work)
2.1 Context Adaptation / Prompt Optimization
핵심 흐름
LLM 성능 향상을 위해 모델 파라미터 업데이트 없이 input(context)을 최적화하는 연구
대표 방법들
(1) In-Context Learning (ICL)
- few-shot / many-shot example 제공
- 장점: 간단, 빠름
- 한계:
- static context
- generalization 제한
(2) Prompt Optimization
- MIPROv2 (DSPy): Bayesian optimization 기반 prompt tuning
- GEPA:
- reflection + genetic search
- Pareto frontier 유지
특징:
- iterative optimization
- execution feedback 활용
한계 (ACE에서 지적)
- brevity bias
- 점점 짧고 generic prompt로 수렴
- domain knowledge 손실
2.2 Natural Language Feedback 기반 학습
핵심 아이디어
LLM이 자신의 output을 평가 → 자연어 feedback 생성 → context 업데이트
대표 방법
(1) Reflexion
- 실패 분석 → reasoning 개선
- trial-and-error 기반 self-improvement
(2) TextGrad
- gradient 대신 textual feedback
- prompt optimization을 differentiable-like하게 수행
(3) GEPA (확장)
- reflection + evolution 결합
한계
- feedback → 결국 prompt rewriting
- 반복될수록 정보 압축 발생 → context collapse 문제
2.3 Test-time Memory / Agent Memory
핵심 흐름
LLM이 실행 중에 memory를 축적하여 성능 향상
대표 방법
(1) Dynamic Cheatsheet (DC)
- 실행 결과 기반 memory 저장
- strategy / code / failure pattern 축적
특징:
- label 없이 self-improving 가능
한계
- memory를 통째로 재작성 → 정보 손실
- context collapse 발생 가능
2.4 Retrieval-based Context Augmentation (RAG 계열)
핵심 아이디어
외부 knowledge를 context에 추가
- RAG (Lewis et al.)
- Self-RAG
- retrieval-augmented agents
한계
- retrieval 중심 → “context evolution” 없음
- static knowledge injection
2.5 Agentic Learning / Self-improving Agents
핵심 흐름
- agent가 environment interaction을 통해 학습
- planning + tool use + reflection
대표 흐름
- ReAct (reasoning + acting)
- Agent memory (A-MEM 등)
- compound AI systems
한계
- memory 구조가 단순 (log 수준)
- structured knowledge accumulation 부족
2.6 Context Engineering (Emerging Paradigm)
최근 연구는 다음 방향으로 발전:
Prompt → Context → System-level memory
핵심 개념
- context = agent의 “operating environment”
- long-context LLM + KV cache → practical
기존 접근의 공통 한계
| 접근 | 한계 |
|---|---|
| Prompt optimization | 정보 압축 |
| Memory methods | collapse |
| RAG | static |
| Agent learning | 구조 부족 |
2.7 ACE의 위치 (핵심 차별점)
ACE는 위 흐름을 통합하면서 다음을 해결:
핵심 차별성
(1) Context = “Evolving Playbook”
- static prompt X
- dynamic structured memory ✔
(2) Delta Update
- full rewrite X
- incremental update ✔
(3) Role Decomposition
- Generator / Reflector / Curator 분리
(4) Self-improving without labels
- execution feedback만으로 학습 가능
2.8 정리 (한 줄 비교)
| 방법 | 핵심 아이디어 | 한계 |
|---|---|---|
| ICL | example 기반 | static |
| GEPA | prompt optimization | brevity bias |
| Reflexion | self-feedback | rewrite 문제 |
| Dynamic Cheatsheet | memory 축적 | collapse |
| ACE | evolving structured context | ✔ 해결 |
다음은 ACE (Agentic Context Engineering)의 방법론을 정리한 내용입니다.
3. 방법론 (Methodology)
3.1 문제 정의 (Problem Formulation)
ACE는 다음 문제를 푼다:
LLM의 context C를 점진적으로 업데이트하여 성능을 최대화
기본 설정
- 입력: query x
- context:
- 모델:
- 출력:
목표
- : task reward (accuracy, execution success 등)
핵심 제약
- weight 업데이트 없음
- 오직 **context C**만 업데이트
즉:
test-time learning / inference-time adaptation
3.2 Context Representation
ACE의 핵심:
context를 “monolithic prompt”가 아니라
**structured memory (playbook)**로 표현
Context 구조
각 bullet :
구성 요소
- content
- strategy
- rule
- failure pattern
- metadata
- helpful count
- harmful count
- usage frequency
특징
- compositional
- interpretable
- incremental update 가능
–> context collapse 방지의 핵심
3.3 ACE Pipeline
ACE는 3-agent 구조로 동작
전체 흐름
3.3.1 Generator
역할
- query 해결
- trajectory 생성
출력
특징
- ReAct-style reasoning 가능
- tool interaction 포함
3.3.2 Reflector
역할
- trajectory 분석
- insight 추출
입력
출력
예시
- 성공 전략 추출
- 실패 패턴 분석
- 개선 rule 생성
핵심 포인트
- evaluation과 generation 분리
- iterative refinement 가능
3.3.3 Curator
역할
- structured update 생성
- context와 merge
출력
특징
- non-LLM merge 가능
- deterministic integration
–> 비용 절감 핵심
3.4 Incremental Delta Update (핵심)
기존 방식
문제:
- 정보 손실
- 비용 증가
ACE 방식
Delta 구성
- new bullets
- update existing bullets
장점
- local update
- knowledge preservation
- parallelizable
3.5 Grow-and-Refine
단순 accumulation → X
ACE:
growth + refinement
과정
(1) Grow
(2) Refine
- deduplication
- conflict resolution
- importance update
Deduplication
- embedding similarity 기반
Importance Update
핵심:
context를 “long but clean” 상태 유지
3.6 Offline vs Online Adaptation
Offline
- training set 사용
- context 사전 구축
Online
- test-time 업데이트
특징
- sequential update
- self-improving agent
3.7 Feedback Signal
ACE는 supervised signal 없이도 가능
가능한 feedback
- execution success/failure
- reward signal
- validation result
특징
–> reinforcement learning 없이도 가능
3.8 Algorithm (Pseudo-code)
C = init_context()
for x in data:
# 1. Generator
tau = generate_trajectory(x, C)
# 2. Feedback
reward = evaluate(tau)
# 3. Reflector
delta_raw = reflect(tau, reward, C)
# 4. Curator
delta = curate(delta_raw)
# 5. Update
C = merge(C, delta)
# 6. Refine
C = deduplicate(C)3.9 Complexity & Efficiency
기존 방법
- full rewrite → O(|C|)
ACE
- delta update →
결과:
- latency ↓
- token cost ↓
- scalability ↑
4. 핵심 요약 (Research Insight)
핵심 구조
ACE =
(trajectory generation) + (reflection) + (structured memory update)
핵심 기여
- Context를 structured memory로 정의
- delta update로 collapse 방지
- reflector 분리로 quality 향상
수식적 해석
ACE는 사실상:
where:
- gradient ≈ natural language feedback
논문에서 실제로 사용한 **AppWorld (agent)**와 FiNER/Formula (금융) 기준으로
end-to-end 예제를 단계별로 설명하겠습니다.
1. Agent Task 예제 (AppWorld)
특성:
- API 호출 / multi-step reasoning
- execution feedback 존재 (성공/실패)
Step 0: 초기 상태
Query
"Find the contact info of John Doe and send him an email about the meeting."초기 Context
[rule-0001] Use APIs to retrieve user information.
[rule-0002] Send email using email API.–> 매우 generic (ICL 수준)
Step 1: Generator
실행 결과 (trajectory)
1. search_contact("John Doe")
2. result: multiple entries found
3. pick first entry
4. send_email(to=wrong_person)
→ FAIL–> 실패 발생
Step 2: Reflector
입력
- trajectory
- failure signal (email 실패)
분석 결과 (insight)
- Name search is ambiguous
- Need additional filtering (e.g., phone/email match)
- Must verify identity before sending emailRaw Delta
[insight]
When searching contacts by name, ambiguity may occur.
Always disambiguate using additional attributes before action.Step 3: Curator
Structured Delta 생성
[rule-0003]
When processing name-sensitive tasks involving contacts:
- Avoid selecting first match
- Use additional identifiers (phone/email)
- Validate identity before actionStep 4: Context Update
업데이트된 Context
[rule-0001] Use APIs to retrieve user information.
[rule-0002] Send email using email API.
[rule-0003] Disambiguate contacts using additional attributes before action.Step 5: 다음 Query 수행
동일/유사 Query
"Email John Doe about the meeting"Generator 행동 변화
1. search_contact("John Doe")
2. multiple results
3. filter by email domain / phone
4. select correct contact
5. send_email → SUCCESS핵심 변화
| 요소 | 기존 | ACE |
|---|---|---|
| 선택 전략 | first match | disambiguation |
| 실패율 | 높음 | 감소 |
| knowledge | 없음 | 누적 |
–> 이것이 self-improving agent의 실제 작동 방식
2. Domain Task 예제 (Finance – Formula)
특성:
- 정확한 rule / 계산 필요
- hallucination 발생 가능
Query
"What is the debt-to-equity ratio?"Step 1: Generator (초기)
Debt-to-equity ratio = Total Assets / Total Equity–> 오류
Step 2: Reflector
분석
- Incorrect formula used
- Correct definition:
Debt-to-equity = Total Liabilities / Shareholder EquityStep 3: Curator
[rule-fin-001]
Debt-to-equity ratio is defined as:
Total Liabilities / Shareholder EquityStep 4: Context 업데이트
Step 5: 동일 유형 문제
"What is the D/E ratio for company X?"Generator (개선됨)
Debt-to-equity = liabilities / equity
→ correct computation효과
- hallucination 감소
- domain knowledge 축적
3. Failure Pattern 학습 예제
ACE의 중요한 특징:
성공뿐 아니라 실패 패턴도 저장
예제
실패
"Revenue growth = profit difference"Reflector
Confusion between revenue and profitCurator
[error-pattern-002]
Do not confuse revenue with profit.
Revenue = total income
Profit = revenue - cost–> 이후 모델은 이 오류를 회피
4. Context Evolution 모습
시간에 따라 context는 이렇게 변함:
초기
2 rules (generic)중간
+ 전략
+ 실패 패턴
+ domain knowledge후반 (Playbook)
[STRATEGY]
- disambiguate entity
- validate before action
[FORMULAS]
- debt-to-equity
- revenue growth
[FAILURE PATTERNS]
- avoid name ambiguity
- avoid concept confusion–> 논문 Figure 3 구조와 동일
5. 핵심 메커니즘 요약
기존 방식
prompt = compressed summaryACE
context = accumulated structured knowledge6. 중요한 연구적 포인트
(1) “학습 대상”이 바뀜
- 기존: model weights
- ACE: context
(2) Generalization 방식
- weight generalization X
- experience reuse ✔
4. 실험 결과 (Experimental Results)
4.1 전체 요약
ACE는 agent + domain task 모두에서 일관되게 SOTA 대비 큰 성능 향상을 달성
- Agent: +10.6% 평균 향상
- Domain: +8.6% 평균 향상
4.2 Agent Benchmark (AppWorld)
설정
- 환경: AppWorld (API + tool-use agent)
- base: ReAct + DeepSeek-V3.1
- metric:
- TGC (Task Goal Completion)
- SGC (Scenario Goal Completion)
주요 결과 (Table 1)
| 방법 | Average Accuracy |
|---|---|
| ReAct (baseline) | 42.4 |
| + ICL | 46.0 |
| + GEPA | 46.4 |
| + DC (online) | 51.9 |
| + ACE (offline) | 59.4 |
| + ACE (online) | 59.5 |
–> 최대 +17.1% 향상
핵심 해석
(1) Prompt optimization vs ACE
- GEPA 대비:
- +11~12% 이상 개선
이유:
- GEPA → “짧은 instruction”
- ACE → “누적된 전략”
(2) Memory 방법 vs ACE
- Dynamic Cheatsheet 대비:
- +7.6% 향상
이유:
- DC: rewrite 기반
- ACE: delta update (collapse 방지)
(3) Label 없이도 성능 유지
| 설정 | 성능 |
|---|---|
| GT label 있음 | 59.4 |
| GT label 없음 | 57.2 |
–> 거의 동일
의미:
execution feedback만으로 self-improving 가능
Leaderboard 결과
- ACE (59.4%) ≈ IBM CUGA (60.3%)
- 더 작은 모델 사용 (DeepSeek vs GPT-4.1)
–> 매우 중요한 포인트
4.3 Domain-specific Tasks (Finance 중심)
설정
- FiNER: entity tagging
- Formula: numerical reasoning
주요 결과 (Table 2)
| 방법 | 평균 성능 |
|---|---|
| Base LLM | 69.1 |
| ICL | 69.6 |
| MIPROv2 | 70.9 |
| GEPA | 72.5 |
| ACE (offline) | 81.9 |
–> +12.8% 향상
세부 분석
Formula task (핵심)
- GEPA: 71.5
- ACE: 85.5
–> +14% 이상 상승
왜 크게 향상?
domain task 특징:
- 정확한 rule 필요
- 계산 / 정의 중요
ACE 효과:
- rule 축적
- 오류 패턴 기억
- 재사용 가능
4.4 Online Adaptation 성능
결과
| 방법 | 성능 |
|---|---|
| DC | 51.9 |
| ACE | 59.5 |
–> +7~8% 향상
핵심 의미
test-time learning에서
ACE가 기존 memory 방법보다 훨씬 안정적
4.5 Ablation Study
주요 구성 요소
| 구성 요소 | 제거 시 성능 |
|---|---|
| Reflector 없음 | ↓ |
| multi-epoch 없음 | ↓ |
| full ACE | 최고 |
핵심 인사이트
(1) Reflector 중요성
- insight quality 직접 영향
(2) Iterative refinement 효과
- 단일 업데이트보다 안정적
(3) Offline warmup
- online 성능 추가 향상
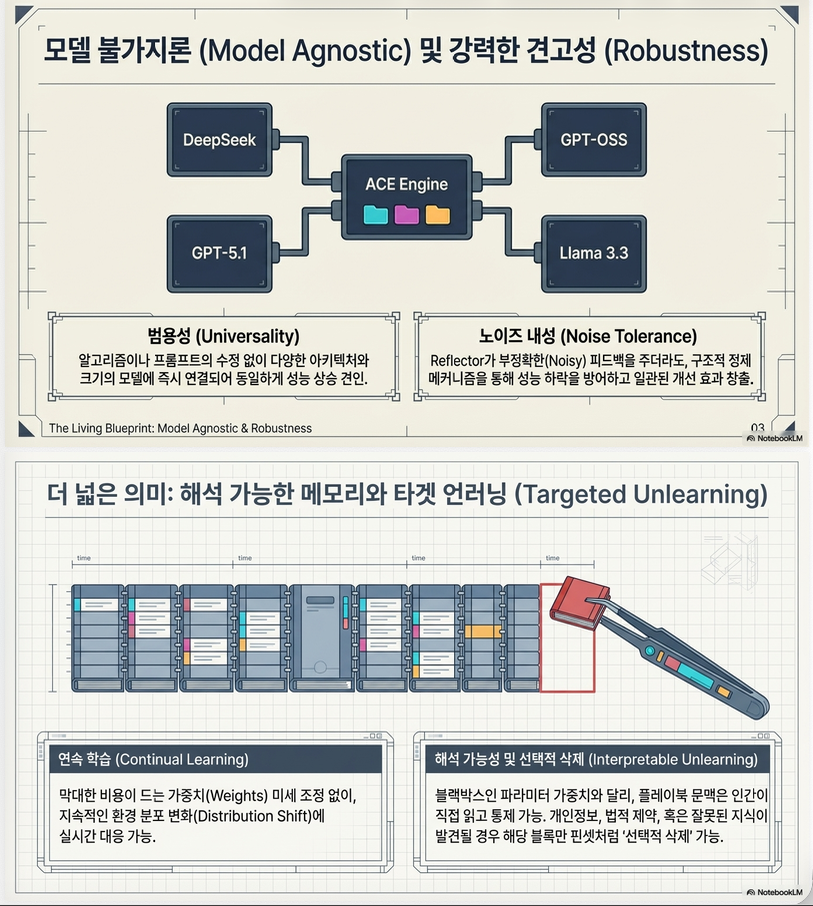
4.6 Robustness
Reflector 품질 변화
- 약한 reflector → 성능 유지
- noisy reflector → 점진적 degradation
- adversarial → 급락
–> 하지만 baseline보다는 항상 높음
Hyperparameter sensitivity
- 매우 안정적
- 튜닝 민감도 낮음
4.7 Cost & Efficiency (중요)
Offline (vs GEPA)
- latency ↓ 82.3%
- rollout ↓ 75.1%
Online (vs DC)
- latency ↓ 91.5%
- token cost ↓ 83.6%
–> 매우 큰 개선
왜 비용이 줄어드나?
기존
- full prompt rewrite
- 반복 evaluation
ACE
- delta update
- non-LLM merge
4.8 KV Cache 효과
결과
- 91.8% token cache reuse
- 비용 82.6% 절감
–> 중요한 시스템적 insight
5. 종합 분석
핵심 성능 패턴
| 조건 | ACE 효과 |
|---|---|
| Agent task | 매우 큼 |
| Domain knowledge | 매우 큼 |
| simple task | 제한적 |
언제 잘 작동하는가
ACE가 특히 강한 경우:
- multi-step reasoning
- tool-use
- domain-specific knowledge
- failure-driven learning
언제 약한가
- feedback 없음
- simple rule task
- reflector 품질 낮음
6. 연구적 핵심 결론
(1) Context > Prompt
prompt optimization보다
context evolution이 훨씬 효과적
(2) Test-time learning 가능
- label 없이도 학습
- RL 없이도 가능
(3) Cost-performance tradeoff 개선
- 더 좋은 성능
- 더 낮은 비용
답글 남기기