




1. 문제 설정 (핵심 motivation)
기존 activation steering:
- 대표 방식: CAA, ITI 등
- 기본 형태:
문제점:
- norm (크기) 변화 발생
- representation distribution 붕괴 (collapse)
- generation quality 저하
논문 핵심 주장:
“LLM의 semantic signal은 magnitude가 아니라 direction에 있다”
→ 따라서 steering도 벡터 이동이 아니라 방향 회전으로 해야 한다
2. 핵심 아이디어: Spherical Steering
(1) Representation을 hypersphere로 해석
- hidden state
- normalization →
⇒ (unit hypersphere 위의 점)
(2) Truthfulness axis 정의
contrastive 데이터로부터:
- positive (truthful):
- negative (hallucinated):
⇒ truthfulness direction
(3) 핵심: Geodesic Rotation (Slerp)
기존:
제안:
–> 구면 위에서 회전
최종:
핵심 특징:
- norm 완전히 보존
- minimal change (geodesic path)
- 방향만 수정
–> 논문의 가장 중요한 포인트
3. vMF 기반 Adaptive Gating (중요)
단순 rotation → 과도한 steering 위험
→ 입력별로 steering 강도 조절
(1) alignment 측정
(2) vMF 기반 확률
(3) confidence → steering strength
의미:
- 이미 truthful → steering 안함
- hallucination 방향 → 강하게 steering
4. 전체 알고리즘 (Inference-time)
각 token, 각 layer에서:
- activation 추출
- normalize
- alignment 계산
- gating → t
- Slerp rotation
- norm 복원
–> 완전히 training-free
5. 실험 결과 (핵심 정리)
(1) 성능
- TruthfulQA +10% 이상 향상
- 평균 +8% 이상 accuracy 증가
- generation quality 동시에 증가
기존 방법과의 차이:
| 방법 | Accuracy | Generation |
|---|---|---|
| CAA / ITI | ↑ | ↓ |
| Ours | ↑ | ↑ |
(2) 핵심 insight
논문 Figure 3:
- truthful vs hallucinated activation norm 거의 동일 → magnitude 정보 거의 없음
즉:
“behavior signal은 direction에 있다”
(3) collapse efficiency
- 같은 rank drop 대비 성능 ↑
- representation 붕괴 훨씬 적음
6. 기존 방법과 비교
(1) Activation Addition
- linear shift
- magnitude distortion
- distribution 붕괴
(2) Angular Steering (기존 연구)
- low-dim plane에서 rotation
- PCA / projection 필요
(3) Spherical Steering (본 논문)
- full space rotation
- norm-preserving
- geodesic 기반
- adaptive gating
–> 가장 “geometry-consistent” 방식
7. 한 줄 요약
Activation steering을 “벡터 이동”에서 “구면 위 회전”으로 바꿔,
representation geometry를 보존하면서 성능을 동시에 개선한 방법
논문의 **방법론(Method)**은 크게 4단계로 구성됩니다:
(1) Prototype 구성 → (2) Norm-preserving rotation → (3) vMF gating → (4) Inference-time 적용
아래는 수식 중심으로 정리한 내용입니다.
1. Prototype Construction (Steering direction 생성)
입력
contrastive dataset:
- : desirable (e.g., truthful)
- : undesirable (e.g., hallucinated)
(1) Activation 추출
각 샘플에 대해:
–> last token representation 사용 (semantic summary)
(2) 평균 representation
(3) contrastive direction
(4) 정규화
최종적으로:
- (truth direction)
- (hallucination direction)
2. Norm-Preserving Steering (핵심)
기존 방법 (문제점)
→ norm 변화:
–> magnitude distortion 발생
제안 방법: Rotation on Hypersphere
(1) normalization
(2) 각도 계산
(3) Slerp (Geodesic interpolation)
(4) norm 복원
✔ 핵심 특징
- (norm invariant)
- 최소 변화 (geodesic path)
- direction만 수정
–> “geometry-consistent intervention”
3. vMF Confidence Gating (Adaptive control)
목적
- 불필요한 steering 방지
- 입력별 adaptive strength
(1) alignment score
(2) vMF 기반 확률
–> directional likelihood 모델링
(3) hallucination tendency
(4) steering strength 결정
✔ 해석
- : 충분히 truthful → steering 없음
- : hallucination 방향 → rotation 적용
4. Inference-Time Procedure
각 decoding step j, 각 layer l에서:
Step-by-step
(1) activation 추출
(2) normalize
(3) alignment 계산
(4) gating
(5) rotation (if )
(6) 다음 layer로 전달
✔ 특징
- token-level adaptive
- layer-wise 적용 가능
- training-free
5. 방법론 핵심 요약 (압축)
기존 방식
- linear shift (vector addition)
- magnitude distortion
제안 방식
- hypersphere 상 rotation
- norm-preserving
- adaptive gating
6. 방법론의 본질 (중요 insight)
이 논문은 사실상 다음을 주장합니다:
LLM representation = direction dominates semantics
따라서:
- addition → 잘못된 intervention space
- rotation → 올바른 intervention manifold
7. 결론
방법론의 본질은 한 줄로 정리됩니다:
“Activation steering을 Euclidean shift에서 Riemannian rotation으로 바꾼 것”
논문의 **실험 결과(Experiments)**는 단순 성능 비교를 넘어서,
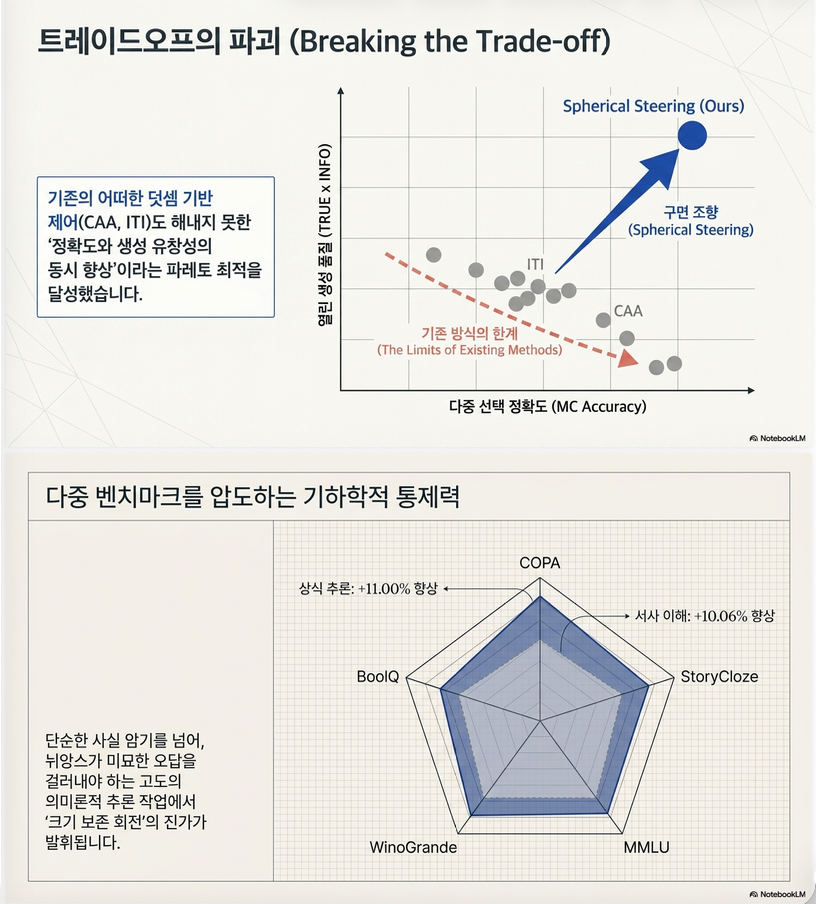
**“accuracy–generation trade-off를 깨고 Pareto 개선을 달성했다”**는 점이 핵심입니다.
정리하면 다음 4가지 축입니다:
1. 메인 결과: Accuracy vs Generation Trade-off
핵심 결론
기존 방법: accuracy ↑ → generation quality ↓
제안 방법: accuracy ↑ + generation quality ↑ (동시 개선)
TruthfulQA 결과 (핵심 테이블)
LLaMA-3.1-8B-Instruct
| Method | MC Avg | TRUE×INFO |
|---|---|---|
| Baseline | 38.16 | 48.24 |
| ITI | 41.97 | 40.31 ↓ |
| CAA | 40.54 | 49.66 |
| SADI | 41.71 | 51.18 |
| Spherical Steering | 53.17 | 54.63 |
–> +15% 이상 accuracy 증가 + generation quality 증가
Qwen-2.5-7B-Instruct
| Method | MC Avg | TRUE×INFO |
|---|---|---|
| Baseline | 39.15 | 74.40 |
| ITI | 43.11 | 67.82 ↓ |
| CAA | 43.22 | 67.95 ↓ |
| SADI | 41.74 | 69.09 |
| Spherical Steering | 51.59 | 77.84 |
–> consistency 유지 + 성능 향상
✔ 핵심 해석
- 기존 activation addition:
- 정확도는 올리지만
- representation distortion → generation quality 하락
- Spherical Steering:
- norm 유지 → distribution 유지
- → 두 metric 동시 개선
2. 다양한 Benchmark에서의 일반화 성능
결과 (Table 2)
| Task | Baseline | Ours |
|---|---|---|
| TruthfulQA | 34.15 | 49.95 |
| COPA | 83.0 | 95.0 |
| StoryCloze | 74.72 | 89.08 |
| MMLU | 60.60 | 62.05 |
| WinoGrande | 50.81 | 52.72 |
| BoolQ | 80.12 | 82.94 |
평균:
- Baseline: 63.90
- Ours: 71.96
특히:
- COPA +11%
- StoryCloze +10%
의미:
fine-grained semantic discrimination 능력 향상
3. 핵심 분석 ①: Direction vs Magnitude
Figure 3 결과
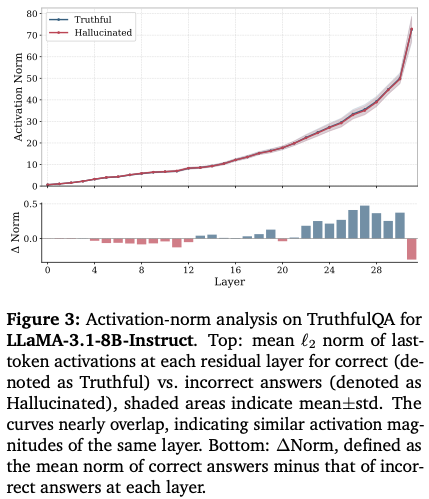
- truthful vs hallucinated activation norm
- 거의 완전히 동일
차이:
- < 1% 수준
✔ 결론
“semantic signal은 magnitude가 아니라 direction에 있다”
매우 중요한 insight
이 결과는 다음을 정당화:
- X: addition (magnitude 변화)
- O: rotation (direction 변화)
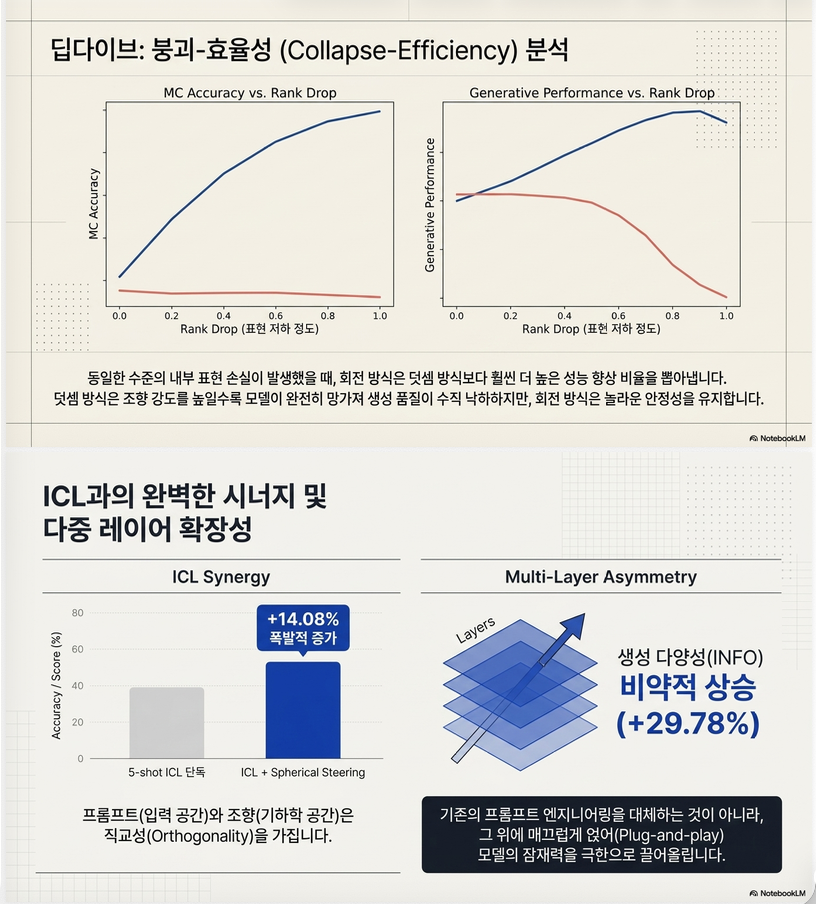
4. 핵심 분석 ②: Representation Collapse Efficiency
실험: Rank Drop vs Performance
비교:
- Activation Addition
- Spherical Steering
결과
동일한 collapse 수준에서:
- Spherical:
- +8~10% 높은 accuracy
- Generation:
- Addition → degrade
- Rotation → improve
✔ 핵심 결론
Rotation은 collapse-efficient하다
해석 (중요)
- addition:
- representation manifold 깨짐
- rotation:
- manifold 위에서 이동
–> 정보 보존
5. Ablation Study
5.1 vMF Gating 효과
결과
- gating 없음:
- high strength에서 성능 붕괴
- gating 있음:
- 안정적인 성능 유지
✔ 해석
adaptive steering이 매우 중요
5.2 Multi-layer 효과
| Layer 수 | MC 성능 | Generation |
|---|---|---|
| 1 | baseline | baseline |
| 2~3 | 약간 ↑ | 크게 ↑ |
| ≥4 | ↓ | ↓ |
✔ insight
- early layer:
- decision boundary 영향
- later layer:
- generation dynamics 영향
–> 매우 중요한 구조적 해석
5.3 ICL과의 결합
결과:
- ICL + Spherical Steering:
- MC1: 52.39% (+14%)
- MC2: +11%
–> additive method보다 훨씬 큰 개선
✔ 해석
- ICL: input space control
- Spherical: representation space control
–> orthogonal → synergy
5.4 Steering Strength (α)
결과:
- α ↑ → accuracy ↑
- α ↑ → generation ↓ (over-steering)
✔ 결론
- sweet spot 존재 (≈ 0.5~0.6)
- gating이 중요
6. 전체 실험 결과 핵심 요약
① Pareto Improvement
- 기존: accuracy vs generation trade-off
- 제안: 둘 다 개선
② Geometry Hypothesis 검증
- magnitude irrelevant
- direction critical
③ Collapse Efficiency
- 같은 distortion 대비 성능 ↑
④ Generalization
- 다양한 reasoning task에서 성능 향상
답글 남기기