



다음 논문은 LLM의 Natural Language Explanation (NLE)의 “faithfulness(충실성)”을 내부 causal 관점에서 측정하는 매우 중요한 메커니즘 기반 연구입니다
1. 핵심 문제 정의
문제
LLM은 CoT 등으로 **그럴듯한 설명(plausible explanation)**을 잘 생성하지만,
이 설명이 실제 내부 reasoning을 반영하는지 (faithful) 는 별개
즉,
- explanation = convincing ✔️
- explanation = true reasoning ✖️ (문제)
Faithfulness 정의
논문은 다음 정의를 채택:
“Explanation이 모델의 실제 reasoning process를 얼마나 정확히 반영하는가”
즉,
- input → hidden states → output
- explanation이 이 internal causal pathway를 반영해야 함
2. 기존 방법의 한계
논문이 강하게 비판하는 부분:
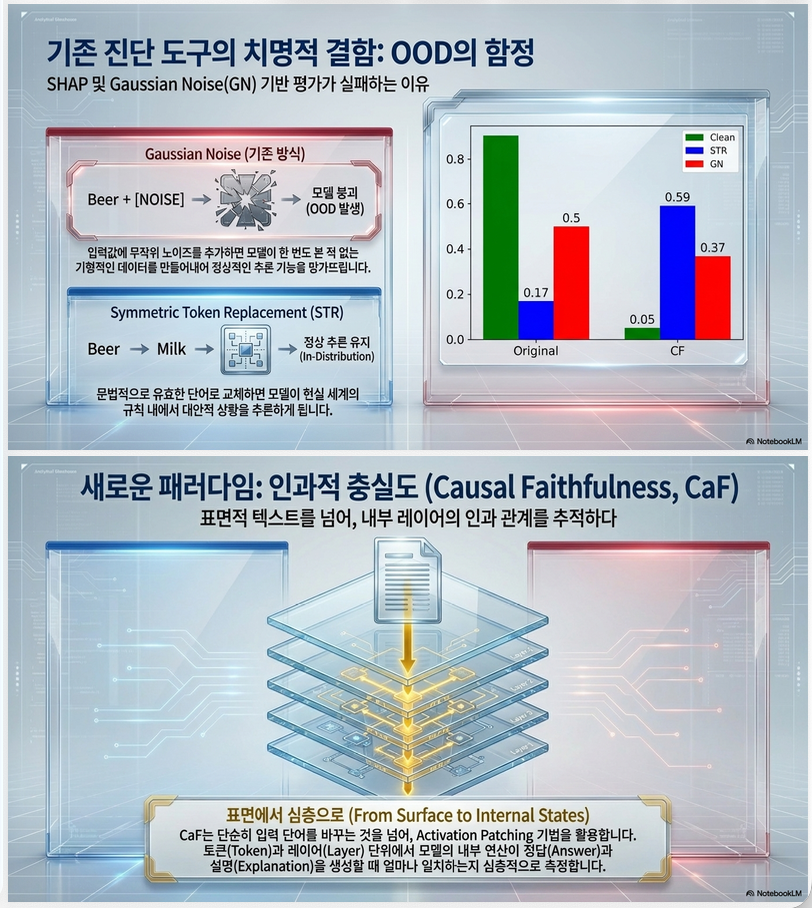
(1) Perturbation-based methods
- explanation 변형 / input corruption
- consistency 체크
문제:
- self-consistency 측정일 뿐
- reasoning 반영 여부는 아님
(2) SHAP 기반 (CC-SHAP)
- explanation vs answer의 attribution 비교
문제:
- feature permutation → OOD 샘플 생성
- 잘못된 attribution 발생
논문 실험:
- SHAP은 중요한 토큰을 제대로 못 잡는 경우 많음 (Fig.2, p.4)
3. 핵심 아이디어: Activation Patching 기반 Causal Faithfulness
핵심 전환
“표면 perturbation → 내부 causal tracing”
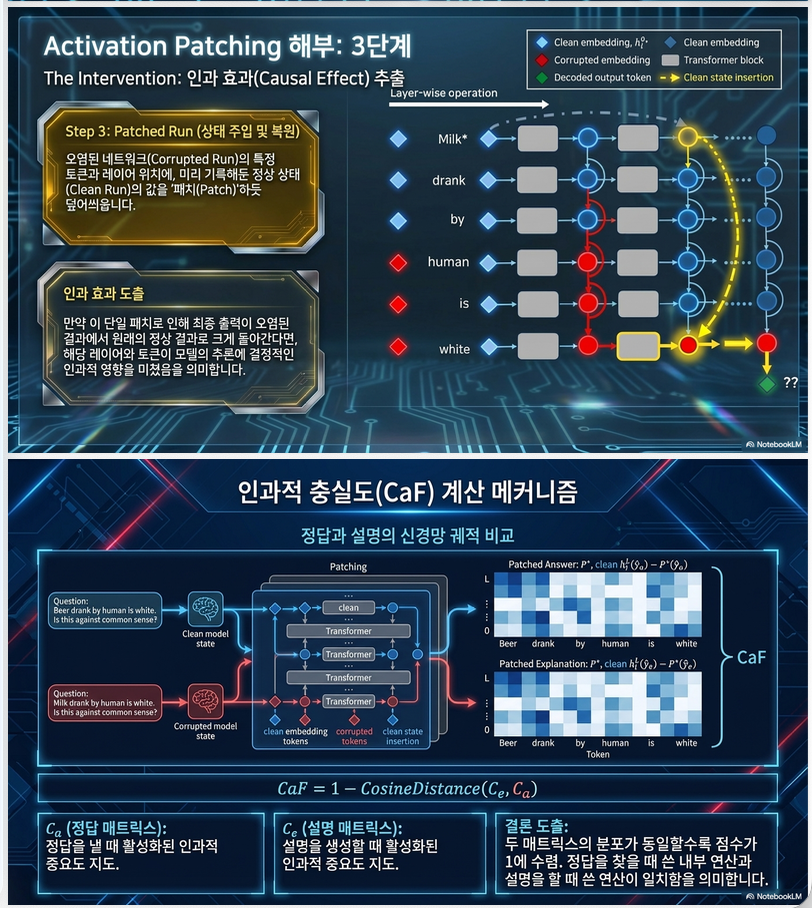
3.1 Activation Patching (AP)
직관
특정 hidden state가 output에 얼마나 영향을 주는지 측정
과정 (p.3, Fig.1)
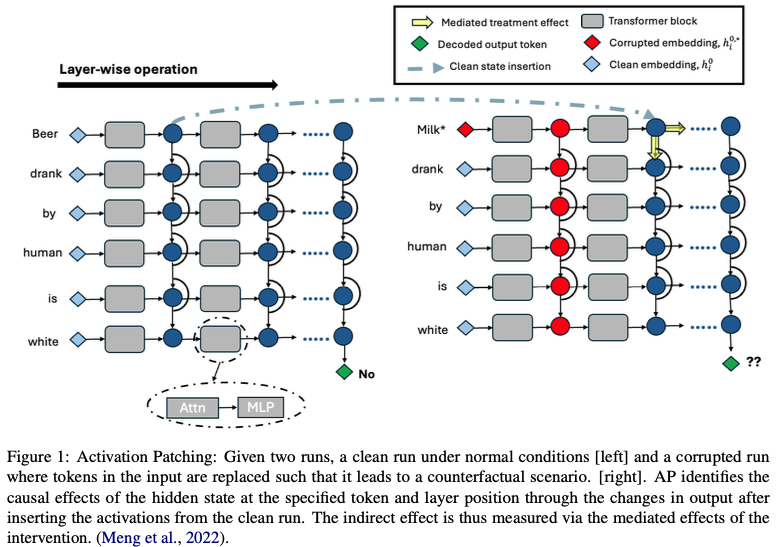
3개의 forward pass:
- Clean run
- 정상 입력 → p(y)
- Corrupted run
- 일부 토큰 변경 → p*(y)
- Patched run
- corrupted 상태에서 특정 layer/token hidden state를 clean 값으로 교체
Causal effect
–> 특정 hidden state가 output에 미친 영향
결과
모든 (token i, layer l)에 대해:
→ causal matrix 생성
4. 핵심 제안: Causal Faithfulness (CaF)
아이디어
explanation과 answer가 동일한 causal mechanism을 공유하는가?
정의
- : answer의 causal matrix
- : explanation의 causal matrix
metric (p.6)
의미
| 경우 | 의미 |
|---|---|
| CaF ↑ | explanation이 실제 reasoning 반영 |
| CaF ↓ | explanation이 hallucinated |
핵심 차별점
기존:
- feature-level alignment
제안:
- token + layer-level causal alignment
–> mechanistic interpretability 기반 평가
5. 중요한 설계 포인트
5.1 OOD 문제 해결: STR (Symmetric Token Replacement)
기존:
- Gaussian noise → OOD
제안:
- 의미적으로 counterfactual 생성
예:
- illogical → logical 문장 교체
–> in-distribution 유지
5.2 Multi-level 분석
- CaF(T): token-level
- CaF(L): layer-level
- CaF(M): multi-layer patching
–> 내부 reasoning 구조까지 평가
6. 실험 결과 핵심
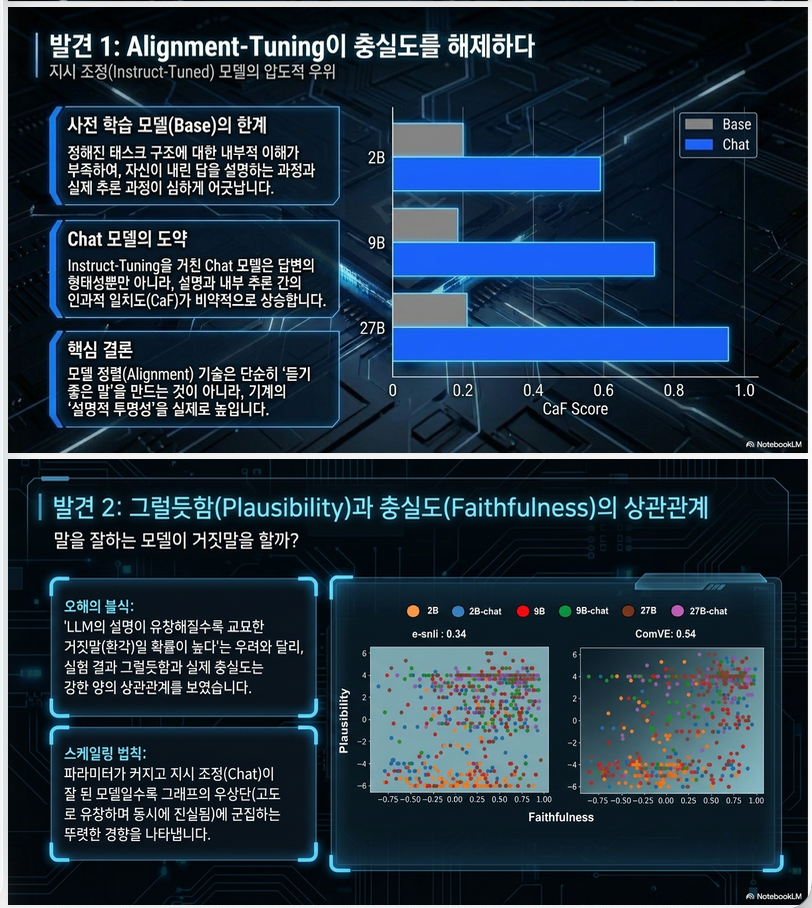
6.1 Alignment tuning 효과
결과 (Table 1, p.7)
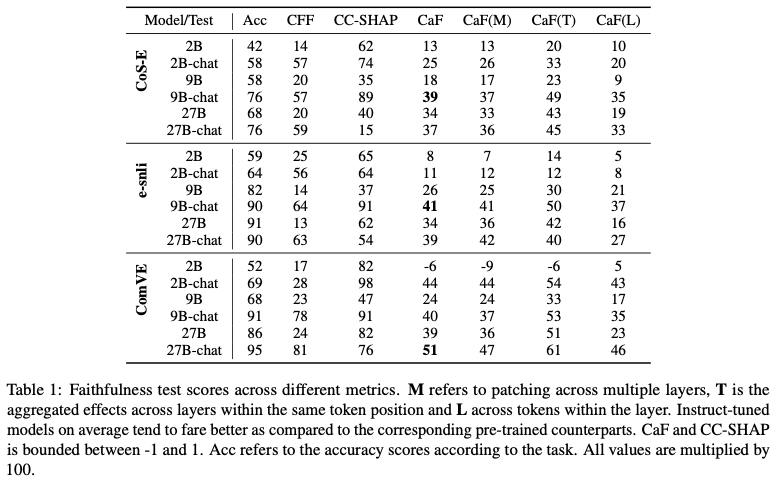
–> instruct-tuned 모델이 더 높은 CaF
2B vs 2B-chat:
CaF: 13 → 25해석:
- alignment는 단순히 “설명 잘함”이 아니라
- 실제 reasoning alignment도 개선
6.2 Plausibility vs Faithfulness
(Fig.4, p.8)
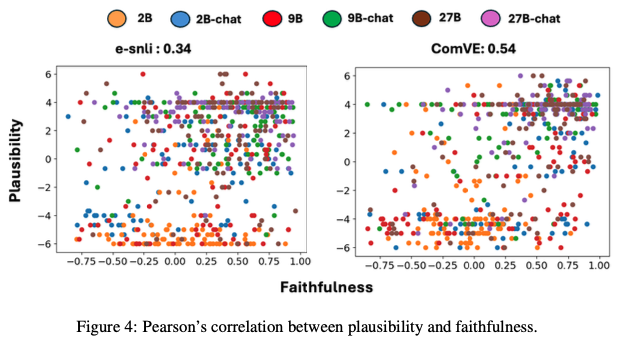
–> 양의 상관관계 존재
하지만:
- 완전히 동일하지 않음
- plausible ≠ faithful
6.3 내부 causal 분석
(Fig.5, p.8)
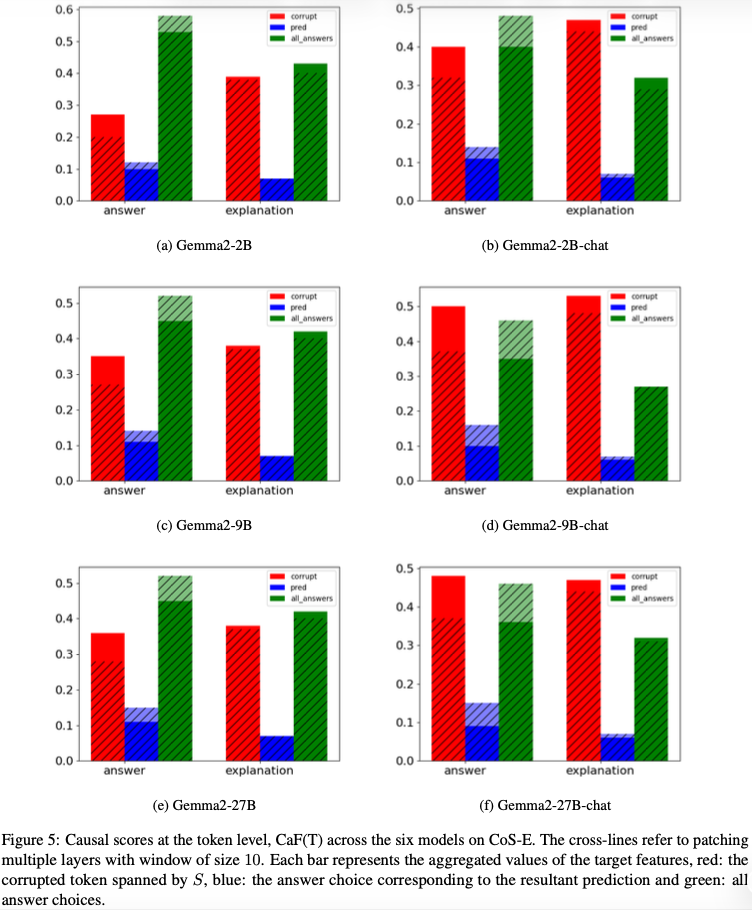
–> 흥미로운 발견:
- 모델은 prediction뿐 아니라 alternative answers도 함께 reasoning
→ explanation은 single-path가 아님
7. 핵심 기여 요약
1. 새로운 metric
- Causal Faithfulness (CaF)
2. mechanistic evaluation
- activation patching 기반
3. OOD 문제 해결
- STR 도입
4. 중요한 발견
- alignment → faithfulness 증가
- plausibility ≠ faithfulness
8. 한계
(1) 계산 비용
- forward pass 필요
(2) token replacement 제약
- 동일 길이 필요
(3) causal scope 제한
- corrupted span 이후만 분석 가능
9. 연구적 의미 (중요)
이 논문은 다음 흐름의 핵심 연결점입니다:
Faithfulness evaluation
↓
Attribution methods (SHAP)
↓
❌ OOD + surface-level
↓
Mechanistic interpretability
↓
Activation patching
↓
✅ Causal Faithfulness (본 논문)10. 한줄 핵심 정리
“Explanation이 실제 reasoning을 반영하는지는, 내부 causal structure alignment로 측정해야 한다.”
이 논문의 방법론을 “구조 + 수식 + 설계 의도 중심”으로 정리합니다.
1. 전체 파이프라인 (Method Overview)
논문의 방법론은 다음 3단계로 구성됩니다:
(1) Counterfactual 생성 (STR)
↓
(2) Activation Patching → causal matrix C 생성
↓
(3) Answer vs Explanation 간 causal distribution 비교 → CaF2. Counterfactual 생성: STR (Symmetric Token Replacement)
목적
- causal effect를 측정하려면 “원인 제거”가 필요
- 하지만 OOD를 피해야 함
방법
- 중요한 token span S을 선택
- 해당 부분을 semantic counterfactual로 치환
예:
- entailment → contradiction
- illogical → logical
특징
| 방식 | 특징 |
|---|---|
| Gaussian noise | OOD 발생 |
| STR (제안) | in-distribution 유지 |
결과:
- 모델의 reasoning을 유지한 채 causal intervention 가능
3. Activation Patching 기반 causal matrix 생성
3.1 Hidden state 정의
각 token i, layer l에서:
Transformer 내부:
3.2 세 가지 forward pass
각 입력에 대해:
(1) Clean run
p(y)
(2) Corrupted run
(3) Patched run
특정 위치 (i, l):
→ 이후 forward 진행
3.3 Indirect causal effect
논문은 indirect effect만 사용:
3.4 결과: causal matrix
모든 token × layer에 대해:
구현 디테일
- token span 이전 위치는 제외 (causal attention 특성)
- multi-layer patching: [l – w/2, l + w/2]
- multi-token output:
4. Answer vs Explanation causal alignment
핵심 아이디어
두 개의 causal matrix 생성:
- : answer 생성 시
- : explanation 생성 시
4.1 Divergence metric
논문은 magnitude보다 distribution을 강조
4.2 왜 cosine인가?
- scale 차이 제거
- attribution pattern 비교에 집중
5. Multi-granularity Faithfulness
논문은 세 가지 수준을 정의:
(1) Full (token + layer)
(2) Token-level aggregation
–> “어떤 token이 중요한가”
(3) Layer-level aggregation
–> “어느 layer에서 reasoning이 일어나는가”
(4) Multi-layer patching
–> local noise 감소 + 안정성 증가
6. Faithfulness 평가 설정
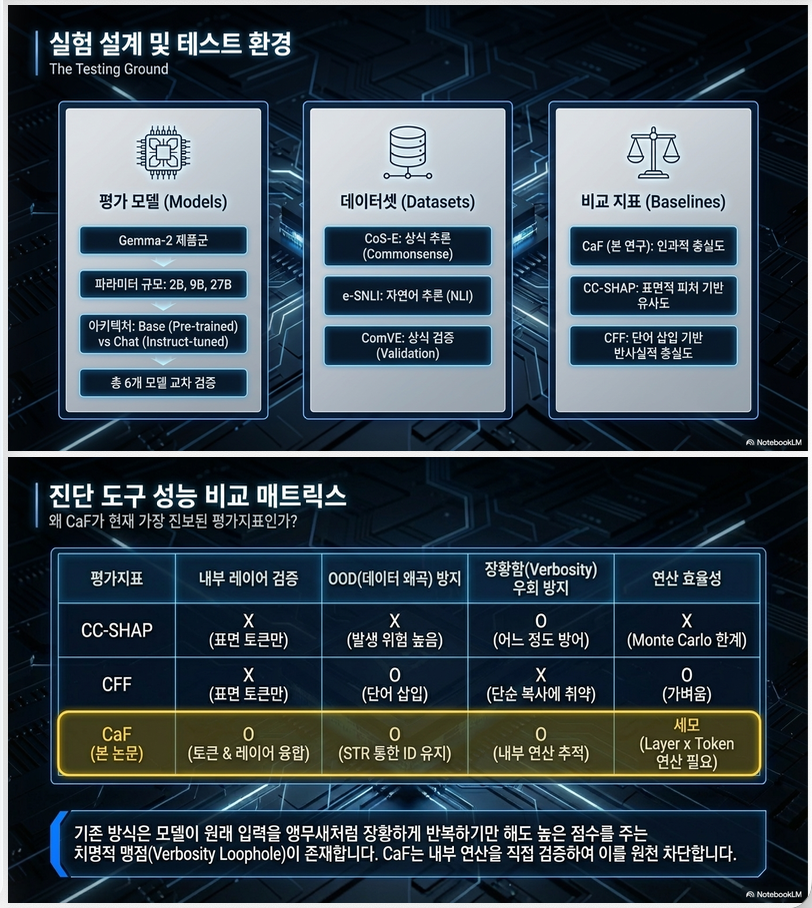
Dataset별 counterfactual 생성 전략
| Dataset | 방법 |
|---|---|
| CoS-E | rationale 수정 → 다른 선택지 유도 |
| e-SNLI | entailment ↔ contradiction |
| ComVE | logical ↔ illogical 문장 교체 |
모델 설정
- Gemma 2B / 9B / 27B
- pretrain vs instruct 비교
- explanation은 post-hoc (answer conditioned)
7. Baseline 비교 설계
비교 대상
(1) CC-SHAP
- feature attribution alignment
(2) CFF
- counterfactual consistency test
차별점 요약
| 방법 | 레벨 | 한계 |
|---|---|---|
| CFF | surface | syntax-level |
| CC-SHAP | feature | OOD |
| CaF | token + layer causal | 계산량 ↑ |
8. 방법론 핵심 포인트 (압축 정리)
1. STR로 in-distribution counterfactual 생성
2. Activation patching으로 causal effect 계산
3. token × layer causal matrix 구성
4. answer vs explanation causal alignment 비교
5. cosine 기반 divergence → CaF
6. multi-level 분석 (token / layer / multi-layer)9. 핵심 methodological insight
이 논문의 본질은 다음 한 줄로 요약됩니다:
Faithfulness = “같은 causal subspace를 공유하는가”
즉,
- 기존: explanation 내용 비교
- 제안: internal computation alignment 비교
답글 남기기