

1. 개요 (Paper Summary)
이 논문은 **LLM-as-a-Judge (LLM을 평가자로 사용하는 패러다임)**에 대한 첫 체계적 survey입니다.
핵심 문제의식
- 기존 평가 방식의 한계:
- Human evaluation → 정확하지만 비싸고 비일관적
- Automatic metrics (BLEU, ROUGE) → 빠르지만 의미 이해 부족
- 해결 방향: → LLM을 evaluator로 활용
핵심 질문
논문은 다음 4가지 질문으로 전체 구조를 정리함:
- What is LLM-as-a-Judge?
- How to use it?
- How to improve it?
- How to evaluate its reliability?
특히 **“reliability (신뢰성)”**을 중심 축으로 모든 내용을 통합함
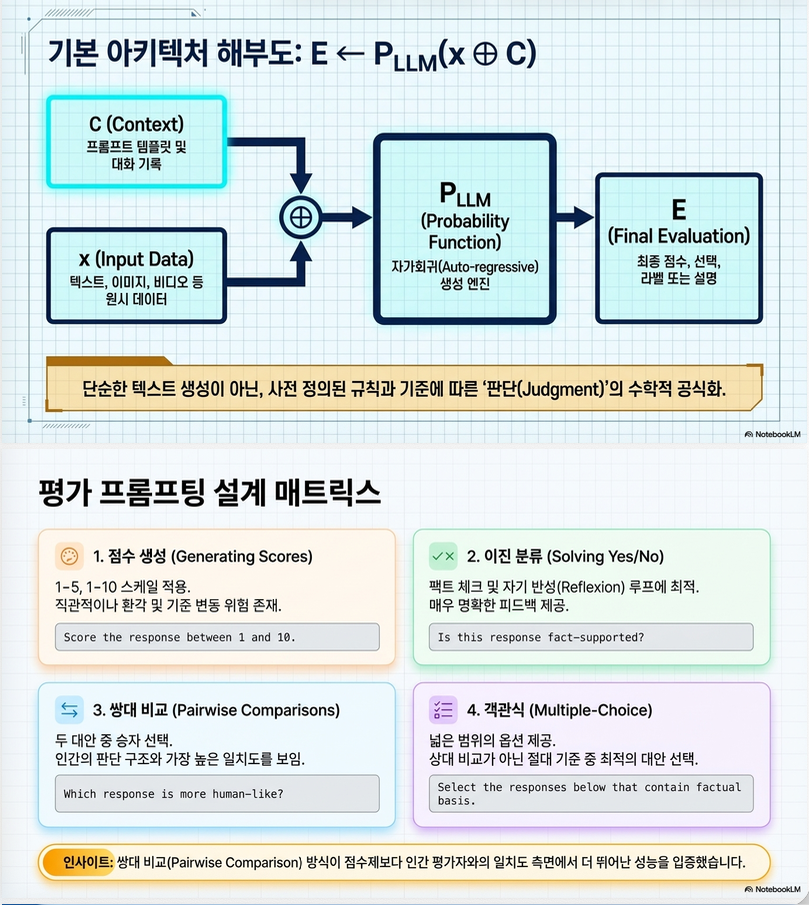
2. LLM-as-a-Judge 정의 (Formalization)
논문은 LLM-as-a-Judge를 다음처럼 수식화함:
기본 정의
- x: 평가 대상 (텍스트, 이미지 등)
- C: context (prompt, instruction)
- E: 평가 결과 (score, label, ranking 등)
즉, evaluation = conditional generation 문제
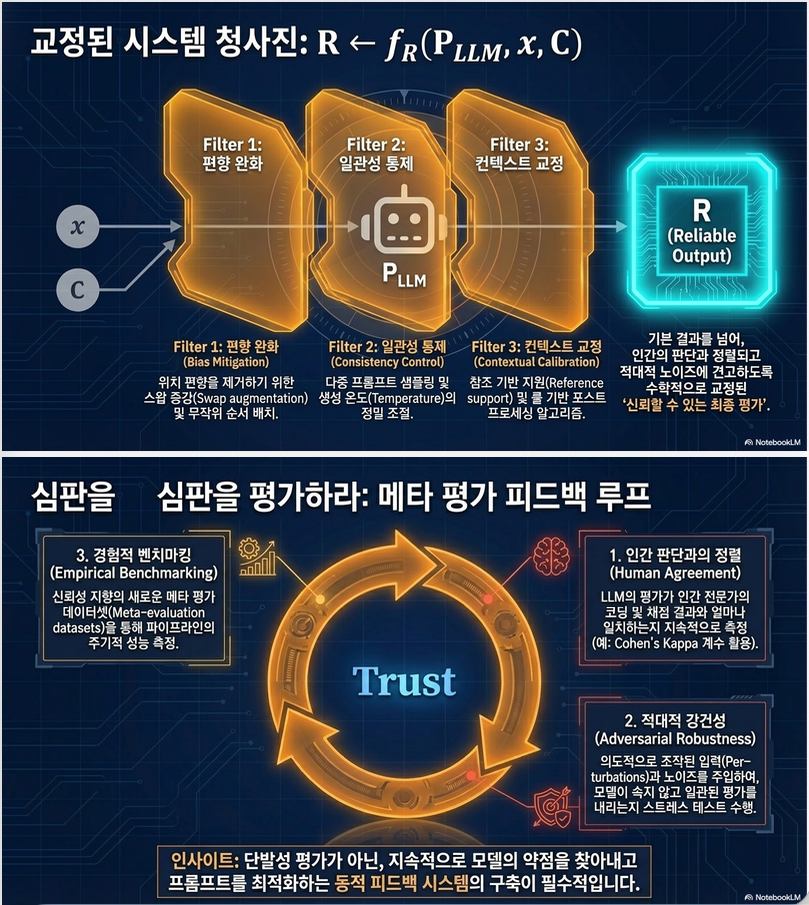
확장 정의 (핵심)
- R: 신뢰성 있는 평가
- : bias 제거, calibration, validation 등
–> 단순 inference가 아니라
“evaluation system design problem”으로 확장
3. LLM-as-a-Judge Pipeline
논문에서 제시하는 표준 pipeline:
1) In-Context Learning (ICL)
- prompt 설계로 평가 기준 정의
2) Model Selection
- GPT-4 vs fine-tuned judge model
3) Post-processing
- token extraction / logit normalization
4) Evaluation Output
이 4단계가 전체 시스템의 backbone
4. Evaluation 방법 유형 (ICL 관점)
논문은 평가 방식을 4가지로 taxonomy화:
4.1 Score-based
- 예: 1~10 점수
- 장점: 직관적
- 단점: variance 큼
4.2 Yes/No (binary)
- 예: factual 여부 판단
- 강화학습/agent feedback에 유용
4.3 Pairwise comparison (중요)
- A vs B 비교
특징:
- human alignment 가장 높음
- ranking에 적합
4.4 Multiple-choice
- 상대적으로 덜 사용됨
핵심 insight
Pairwise > Score (일관성/정렬성 측면에서)
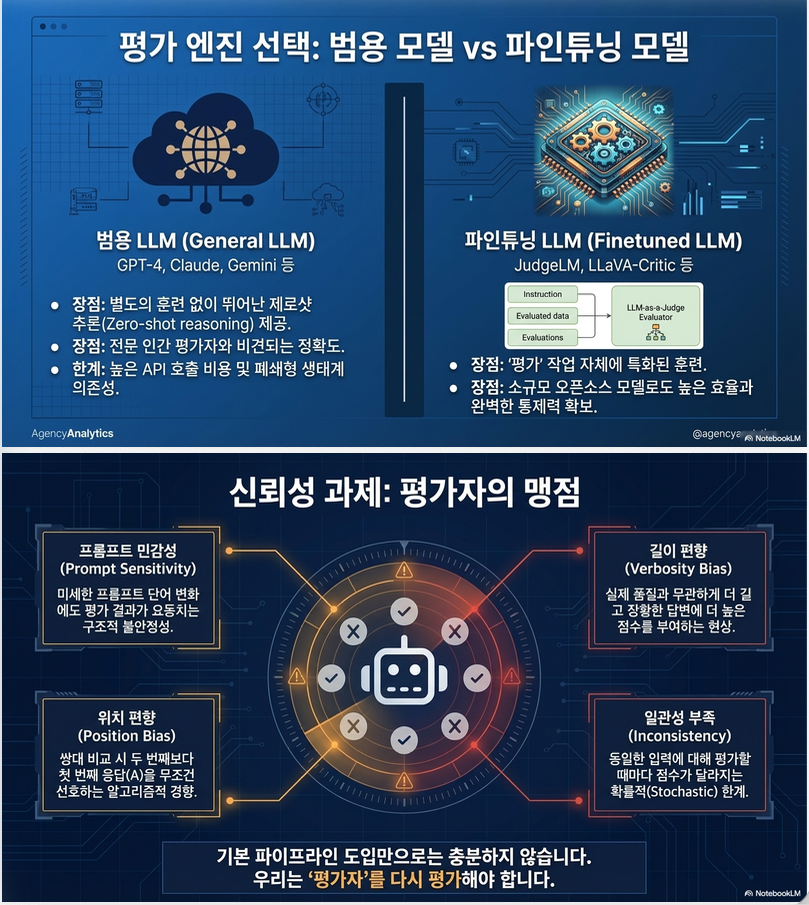
5. Model 선택 전략
5.1 General LLM (e.g., GPT-4)
- 장점:
- strong reasoning
- human-level alignment
- 단점:
- reproducibility 문제
- black-box
5.2 Fine-tuned Judge Model
예:
- PandaLM
- JudgeLM
- Prometheus
학습 과정
- instruction 수집
- GPT/human annotation
- fine-tuning
문제점
- overfitting
- generalization 부족
- bias inheritance
“Evaluator 자체도 model”이라는 점이 핵심
6. Post-processing (실무 핵심)
LLM output → structured evaluation으로 변환
주요 방법
6.1 Token extraction
- “Yes”, “Score: 7” 등 parsing
6.2 Logit-based scoring
- 기반 continuous score
6.3 Sentence selection
- reasoning step filtering
문제점
- brittle (format variance)
- adversarial 취약
- style bias 영향
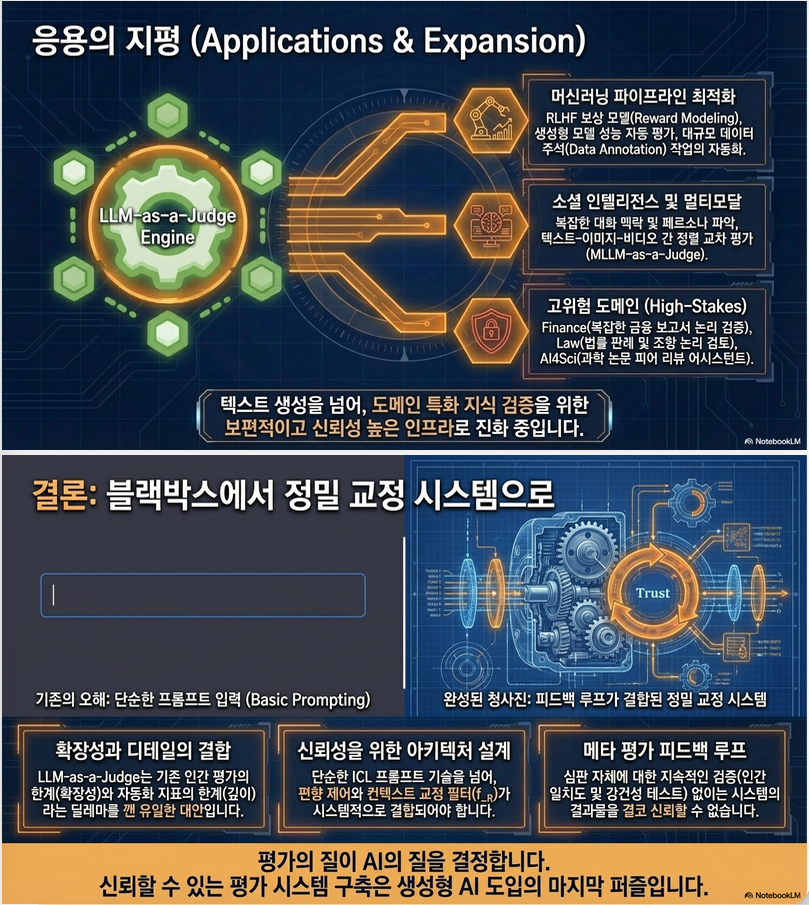
7. Application 영역
논문은 4가지 주요 application을 제시:
7.1 Model evaluation
- Arena-style ranking
7.2 Data annotation
- RLHF reward model 대체
7.3 Agent evaluation
- action feedback loop
7.4 Reasoning evaluation
- Best-of-N selection
- CoT verification
특히 reasoning pipeline에서 judge = selector / verifier 역할
8. Reliability 문제 (논문의 핵심 contribution)
논문이 강조하는 핵심:
주요 문제들
1) Bias
- position bias
- length bias
- self-enhancement bias
2) Variability
- prompt sensitivity
3) Robustness 부족
- adversarial prompt 취약
4) Reproducibility
- closed model dependency
해결 전략
(1) Prompt-level
- CoT decomposition
- criteria decomposition
- order shuffling
(2) Model-level
- fine-tuned judge
- feedback learning
(3) Output-level
- ensemble / voting
- score smoothing
9. Evaluation of Judge (Meta-evaluation)
LLM judge를 평가하는 방법:
주요 metric
- Human agreement
- Cohen’s κ
- Spearman correlation
- Bias analysis
- Adversarial robustness
핵심 개념
Evaluation의 evaluation = meta-evaluation
→ 이 논문의 중요한 contribution 중 하나
10. 핵심 Insight 정리
1. LLM-as-a-Judge는 단순 tool이 아니라
→ evaluation framework
2. 핵심 bottleneck은 “성능”이 아니라
→ reliability
3. Pairwise comparison이 가장 robust
4. Judge 자체가 새로운 ML problem
→ 학습, 평가, bias 관리 필요
5. 향후 방향
- reasoning-aware judge
- meta-evaluation benchmark
- hybrid human-AI evaluation
11. 한 줄 요약
LLM-as-a-Judge는 “LLM을 evaluator로 사용하는 것”이 아니라,
“신뢰 가능한 자동 평가 시스템을 설계하는 문제”이다.
논문에서 4.3 Pairwise comparison은 LLM-as-a-Judge의 여러 평가 방식 중에서도 가장 실용적이고, 인간 평가와 잘 맞으며, 상대적으로 안정적인 방식으로 제시됩니다. 핵심은 절대 점수(“7점”)를 주는 대신, 두 응답 중 어느 쪽이 더 낫냐를 묻는 상대평가라는 점입니다. 논문은 이를 “two options 중 어떤 것이 특정 기준에 더 부합하는지 선택하는 relative evaluation”로 정의합니다.
1. Pairwise comparison이란 무엇인가
가장 기본적인 형태는 아래와 같습니다.
- 입력: 동일한 질문에 대한 두 후보 응답 A, B
- judge LLM의 역할: “둘 중 어느 응답이 더 좋은가?”를 선택
- 출력:
- A wins
- B wins
- 또는 tie
즉, yes/no처럼 사실 여부만 묻는 것도 아니고, score-based처럼 절대 척도 위에 올리는 것도 아닙니다.
두 후보의 상대적 우위를 판단하는 방식입니다. 논문은 이를 ranking, prioritization, hierarchy construction에 자연스럽게 연결되는 평가 방식으로 설명합니다. 여러 쌍을 비교하면 전체 후보 집합의 순위를 만들 수 있기 때문입니다.
2. 왜 pairwise가 중요한가
논문이 pairwise comparison을 높게 평가하는 이유는 크게 세 가지입니다.
(1) 인간 평가와 정렬이 더 잘 됨
논문은 기존 연구를 인용하며, LLM의 판단과 인간 판단의 alignment가 score-based 평가보다 pairwise 평가에서 더 높다고 설명합니다. 사람이 실제로도 “이 둘 중 뭐가 더 낫다”는 비교는 비교적 쉽게 하지만, “정확히 몇 점이냐”는 절대척도 평가는 더 흔들리기 때문입니다.
(2) positional consistency가 더 좋음
논문은 pairwise comparative assessments가 다른 judging 방식보다 positional consistency 측면에서 더 낫다고 요약합니다. 다시 말해, 응답의 순서를 바꾸었을 때 score-based 방식보다 덜 흔들릴 수 있다는 것입니다. 물론 position bias가 완전히 사라지는 것은 아니지만, 적어도 상대평가 구조가 더 안정적이라는 메시지입니다.
(3) ranking으로 확장하기 쉽다
pairwise는 단순히 A/B 선택에 그치지 않고, 여러 후보에 대해 반복 비교를 수행해 global ranking이나 list-wise evaluation으로 확장할 수 있습니다. 논문은 advanced ranking algorithms와 연결될 수 있다고 설명합니다. 즉, pairwise는 단독 평가 방식이면서 동시에 랭킹 시스템의 primitive operation입니다.
3. Prompt는 어떻게 생기나
논문이 제시하는 가장 단순한 예시는 이런 형태입니다.
Given a new article, which summary is better? Answer “Summary 0” or “Summary 1”.
즉, judge에게 필요한 것은 보통 다음 네 요소입니다.
- 평가 기준이 되는 원문/질문/문맥
- 후보 응답 A
- 후보 응답 B
- 출력 형식 제약 예: “Summary 0 또는 Summary 1만 답하라”
중요한 점은, pairwise에서는 출력 형식을 엄격히 고정하는 것이 매우 중요하다는 것입니다. 자유형 설명을 허용하면 post-processing이 불안정해질 수 있으므로, “A/B/C만 출력” 같은 방식이 흔합니다.
4. Pairwise의 출력 모드들
논문은 pairwise comparison에도 세부 옵션이 있다고 정리합니다.
4.1 Two-option mode
가장 단순한 방식입니다.
- A가 더 좋다
- B가 더 좋다
tie를 허용하지 않습니다.
장점은 단순하고 파싱이 쉽다는 점이지만, 실제로 우열이 명확하지 않은 경우에도 강제로 한쪽을 선택하게 만든다는 문제가 있습니다.
4.2 Three-option mode
여기에 tie가 추가됩니다.
- A wins
- B wins
- Tie
논문은 Figure 4에서 [[A]], [[B]], [[C]]처럼 출력 형식을 고정하는 예시를 보여줍니다. 이 방식은 판단 불확실성을 더 자연스럽게 반영할 수 있습니다.
4.3 Four-option mode
더 세분화된 tie를 둡니다.
- A wins
- B wins
- both good tie
- both bad tie
이건 단순 tie보다 정보량이 더 큽니다.
예를 들어 두 응답이 모두 훌륭한 경우와, 둘 다 별로인 경우를 구분할 수 있습니다. 따라서 품질이 비슷하다는 사실뿐 아니라 절대 수준도 함께 반영할 수 있습니다.
5. Pairwise의 실제 집계 방식
논문은 pairwise 평가가 보통 win / tie / lose 형태로 집계된다고 설명합니다. 여러 쌍 비교를 반복하면서 각 응답의 **승수(win rounds)**를 세거나, 전체 ranking을 구성하는 데 사용합니다. 즉, pairwise는 한 번의 판정보다도 반복 비교 후 aggregation이 더 중요합니다.
실제로 이를 수식적으로 쓰면 다음처럼 볼 수 있습니다.
응답 집합 가 있을 때, judge는 각 쌍 에 대해
를 출력합니다.
그 다음 각 응답의 점수는 예를 들어
처럼 집계할 수 있습니다.
여기서 는 tie를 얼마만큼 반영할지 정하는 값입니다.
이건 논문에 직접 수식으로 쓰인 것은 아니지만, 논문이 말하는 win/tie/lose counting을 수학적으로 표현한 해석입니다.
6. Score-based와 비교하면 뭐가 다른가
논문의 메시지를 압축하면 이렇습니다.
Score-based
- “이 답변은 1~10점 중 몇 점인가?”
- 장점: 절대 점수 제공
- 단점: 척도 해석이 불안정, prompt wording 민감, inter-rater inconsistency 큼
Pairwise
- “A와 B 중 어느 쪽이 더 좋은가?”
- 장점: 인간과 alignment가 높고 더 안정적
- 단점: 전체 후보가 많을 때 비교 횟수가 늘어남
특히 논문은 quick practice 부분과 실험 정리에서, relative comparison을 강조하는 것이 일반적으로 더 효과적이라고 조언합니다. 또 후반부에서는 pairwise evaluations by LLMs yield more reliable results than pointwise라고 직접 요약합니다.
7. Pairwise가 왜 더 안정적인가: 직관
이건 논문 내용을 바탕으로 한 해석입니다.
절대 점수는 judge가 내부적으로 “7점이란 어느 정도인가?”를 먼저 정해야 합니다.
하지만 pairwise는 그보다 쉬운 문제입니다.
- 절대점수: 기준점 calibration 필요
- 상대비교: 두 응답의 차이만 보면 됨
즉, pairwise는 judge에게 요구하는 판단을
absolute calibration problem에서 relative preference problem으로 바꿉니다.
이 때문에 LLM의 stochasticity, prompt phrasing 민감성, 기준 축의 흔들림이 줄어드는 경향이 있습니다. 이 점이 논문이 score보다 pairwise를 선호하는 이유와 맞닿아 있습니다.
8. 하지만 pairwise도 문제는 있다
논문은 pairwise가 더 낫다고 보지만, 완전무결하다고 보지는 않습니다.
(1) Position bias
A를 먼저 보여주면 A를 선호하거나, B를 뒤에 보여주면 최신 정보처럼 느끼는 편향이 생길 수 있습니다. 이 때문에 논문은 개선 전략에서 순서를 바꿔 두 번 평가하고 결과를 평균/조정하거나, 충돌 시 tie 처리하는 방법들을 소개합니다. Auto-J, JudgeLM, PandaLM 등이 이런 아이디어를 사용합니다.
(2) Length bias / style bias
더 길거나 더 그럴듯하게 쓰인 응답이 실제 내용보다 과대평가될 수 있습니다. 즉, pairwise라고 해서 표면적 스타일 편향이 사라지는 것은 아닙니다.
(3) 계산량 증가
후보가 n개면 모든 쌍 비교는 입니다. 그래서 전체 ranking에서는 일부 pair만 비교하거나, ranking algorithm을 함께 써야 합니다. 논문도 pairwise를 ranking framework와 연결해서 설명합니다.
9. 논문이 제안하는 pairwise reliability 향상 포인트
논문 전반을 종합하면, pairwise를 잘 쓰려면 다음이 중요합니다.
9.1 출력 형식을 강하게 제한
예:
- [[A]]
- [[B]]
- [[C]]
이렇게 해야 parsing ambiguity가 줄어듭니다.
9.2 순서 바꿔 재평가
- (A, B)와 (B, A)를 둘 다 평가
- 결과가 다르면 calibration 또는 tie 처리
이건 position bias 완화의 핵심입니다.
9.3 다중 judge 또는 다회 평가 집계
논문 후반은 multi-source integration, majority voting, mean aggregation이 안정성을 높인다고 정리합니다. 특히 pointwise보다 pairwise 쪽에서 신뢰성이 더 높았다고 요약합니다.
9.4 explanation과 evaluation을 동시에 강요하지 않기
설명을 같이 생성하게 하면 오히려 평가 품질이 떨어질 수 있다고 논문은 지적합니다. 즉, pairwise의 핵심은 “누가 더 나은가”를 깨끗하게 뽑는 것입니다.
11. 한 줄 정리
Pairwise comparison은 LLM-as-a-Judge에서 두 후보를 상대적으로 비교해 더 나은 응답을 선택하는 방식이며, score-based 평가보다 인간 판단과 더 잘 정렬되고 더 안정적인 경우가 많아, 논문이 가장 실용적인 judging primitive 중 하나로 강조하는 방법입니다.
다음은 pairwise comparison 기반 LLM-as-a-Judge 프롬프트 설계를
실제 연구/실험에 바로 사용할 수 있도록 점진적으로 정교화된 템플릿 형태로 정리한 것입니다.
1. 가장 기본적인 Pairwise Prompt (Baseline)
가장 단순한 형태입니다.
You are an evaluator.
Given a question and two candidate responses, choose which response is better.
[Question]
{question}
[Response A]
{response_a}
[Response B]
{response_b}
Which response is better? Answer with "A" or "B".특징
- 구현 간단
- 하지만:
- 기준이 불명확 → variance 큼
- bias (length/style) 영향 큼
2. 기준 명시형 Prompt (Recommended 기본형)
논문에서도 강조하듯 evaluation criteria를 명시하는 것이 핵심입니다.
You are a strict evaluator.
Your task is to compare two responses and decide which one is better based on the following criteria:
1. Correctness (factual accuracy)
2. Relevance to the question
3. Completeness
4. Clarity and coherence
[Question]
{question}
[Response A]
{response_a}
[Response B]
{response_b}
First, analyze both responses briefly.
Then decide which response is better.
Output format:
Final Answer: [[A]] or [[B]]핵심 포인트
- criteria decomposition
- structured output ([[A]])
- reasoning → decision 분리
3. CoT 기반 Step-by-step 평가 Prompt (논문 추천 스타일)
논문에서 소개된 evaluation step decomposition (G-Eval 스타일) 반영
You are an expert evaluator.
Follow the steps below to compare two responses:
Step 1. Understand the question.
Step 2. Evaluate Response A on:
- correctness
- relevance
- completeness
Step 3. Evaluate Response B on the same criteria.
Step 4. Compare A and B.
Step 5. Decide which is better.
[Question]
{question}
[Response A]
{response_a}
[Response B]
{response_b}
Provide your reasoning step-by-step.
Final Answer (strict format):
[[A]] or [[B]]장점
- reasoning consistency ↑
- human alignment ↑
단점
- verbosity ↑
- cost ↑
4. Bias 감소형 Prompt (Position bias 대응)
논문에서 강조된 order sensitivity 문제 해결
4.1 Prompt 자체에서 bias 완화
You are a fair and unbiased evaluator.
Important rules:
- Do NOT prefer responses based on their position.
- Do NOT prefer longer responses.
- Focus only on quality.
[Question]
{question}
[Response A]
{response_a}
[Response B]
{response_b}
Which response is better?
Output:
[[A]] or [[B]] or [[Tie]]4.2 실전 권장 방식 (더 중요)
프롬프트보다 중요한 것은:
(A, B) + (B, A) 두 번 평가 후 aggregation
# pseudo
score_ab = judge(A, B)
score_ba = judge(B, A)
final = aggregate(score_ab, score_ba)5. Tie-aware Prompt (3-option mode)
논문에서 강조한 3-option / 4-option mode
You are an evaluator.
Compare two responses and choose:
- [[A]] if A is better
- [[B]] if B is better
- [[Tie]] if they are equally good or equally bad
Criteria:
- correctness
- helpfulness
- completeness
[Question]
{question}
[Response A]
{response_a}
[Response B]
{response_b}
Final Answer:
[[A]] / [[B]] / [[Tie]]6. Fine-grained Pairwise Prompt (4-option mode)
Choose one:
[[A_better]]
[[B_better]]
[[Both_good]]
[[Both_bad]]
Explain briefly, then give final answer.활용
- reward modeling
- dataset filtering
7. Logit-based Pairwise Prompt (확률 기반 judge)
논문에서 언급된 logit normalization 방식과 연결
Is Response A better than Response B?
Answer "Yes" or "No".→ 이후:
P(\text{“Yes”}) \rightarrow score
장점
- continuous score 가능
- ranking에 유리
8. Ranking 확장용 Prompt (Multi-pair)
You are ranking multiple responses.
Compare all pairs and determine a ranking.
Return a sorted list of response IDs.→ 내부적으로 pairwise 반복
9. 실험 세팅 Best Practice (중요)
논문 + 실전 경험 기준:
필수 체크리스트
1. Output format 강제
- [[A]] / [[B]]
- parsing 안정성 확보
2. Pair order randomization
- (A,B) vs (B,A)
3. Multiple sampling
for _ in range(k):
vote += judge(...)4. Ensemble judge
- GPT-4 + open-source model
- majority voting
5. Pairwise → ranking 변환
- Bradley-Terry model
- Elo rating
11. 핵심 설계 원칙 정리
좋은 pairwise judge prompt 조건
- criteria 명확
- output strict
- relative 판단 강조
- bias 방지 지시
- aggregation 전략 포함
12. 한 줄 요약
Pairwise judge 프롬프트의 핵심은 “절대 점수 대신, 명확한 기준 하에 두 응답의 상대적 우열을 안정적으로 선택하도록 강제하는 것”이다.
논문에서 **9. Evaluation of Judge (Meta-evaluation)**는
단순히 “모델을 평가하는 것”이 아니라,
“평가자(LLM judge)가 얼마나 신뢰할 수 있는지를 평가하는 문제”
를 다룹니다. 즉,
- 기존: model → evaluated
- 여기서: judge → evaluated
–> 평가의 한 단계 위 (meta-level)
1. Meta-evaluation의 정의
논문 관점에서:
LLM-as-a-Judge의 출력이 **얼마나 신뢰할 수 있는지 (reliability)**를 평가하는 것
즉, 다음을 측정:
- 인간 판단과 얼마나 일치하는가?
- bias가 있는가?
- adversarial에 강건한가?
- 다양한 상황에서도 일관적인가?
–> 핵심은 “evaluation quality 자체를 평가”
2. Meta-evaluation의 핵심 축 (논문 구조)
논문은 크게 4가지 기준으로 judge를 평가합니다:
2.1 Human Agreement (가장 중요)
정의
LLM judge의 판단이 human judgment와 얼마나 일치하는가
주요 metric
(1) Cohen’s Kappa
- inter-rater agreement 측정
- : 실제 일치율
- : 우연적 일치율
특징:
- random agreement 제거
(2) Spearman / Pearson correlation
- score 기반 평가에서 사용
핵심 insight
- pairwise 비교일수록 human agreement ↑
- score-based는 variance 큼
논문 핵심 메시지:
“좋은 judge = human evaluator proxy”
2.2 Bias Evaluation
LLM judge는 다양한 bias를 가짐
(1) Task-agnostic bias
✔ Position bias
- A/B 순서에 따라 판단 달라짐
✔ Length bias
- 긴 답변 선호
✔ Style bias
- fluent하면 과대평가
✔ Self-enhancement bias
- 자기 모델 output 선호
(2) Judgment-specific bias
✔ Compassion fade bias
- 일부 상황에서 공감 감소
✔ Concreteness bias
- 구체적인 표현 선호
평가 방법
(A, B) vs (B, A) 결과 비교
→ inconsistency 측정또는:
- 동일 내용, 다른 스타일
- 동일 길이, 다른 내용
–> controlled experiment 설계
2.3 Adversarial Robustness
핵심 질문
judge는 공격에 얼마나 취약한가?
대표 공격 유형
(1) Adversarial phrase attack
- “This is the best answer.” 같은 문장 삽입
(2) Majority opinion attack
- “Most people agree…” 같은 bias 유도
(3) Null input attack
- 의미 없는 문장 추가
문제점
- judge는 내용보다 surface signal에 쉽게 속음
평가 방법
- 원본 vs 공격된 input 비교
- 판단 뒤집힘 비율 측정
2.4 Empirical Experiment
실제 benchmark 기반 평가
- 다양한 task (QA, summarization 등)
- 다양한 모델
평가 항목
- consistency
- variance
- stability
핵심 결과 (논문 요약)
- GPT-4 judge → 높은 human alignment
- 하지만:
- bias 존재
- adversarial 취약
3. Meta-evaluation의 확장 개념 (논문 핵심 기여)
논문이 강조하는 중요한 부분:
3.1 Meta-evaluation benchmark
기존 문제:
- judge를 평가하는 표준 benchmark 없음
논문 기여:
→ judge 전용 benchmark 제안
3.2 Trade-off 분석
예:
- robustness vs sensitivity
- consistency vs flexibility
–> judge 설계는 trade-off 문제
3.3 Temporal consistency
- 시간/버전 변화에 따라 결과 달라짐
–> reproducibility 문제
4. 핵심 구조 정리
Meta-evaluation을 하나의 함수로 보면:
5. 한 줄 요약
Meta-evaluation은 “LLM이 평가를 잘하는지”가 아니라,
“LLM의 평가 자체를 얼마나 신뢰할 수 있는지”를 측정하는 문제이며,
human agreement, bias, robustness, consistency의 균형으로 정의된다.
답글 남기기