





1. 핵심 문제의식 (Why Prompt Compression?)
LLM 사용 시 가장 큰 병목 중 하나는 긴 prompt입니다.
- 긴 context / ICL example / instruction → ➜ 메모리 ↑, latency ↑, 비용 ↑
- 특히 RAG, agent, multi-step reasoning에서는 심각
따라서 목표는:
“성능 유지하면서 prompt 길이 최소화”
2. 전체 프레임워크
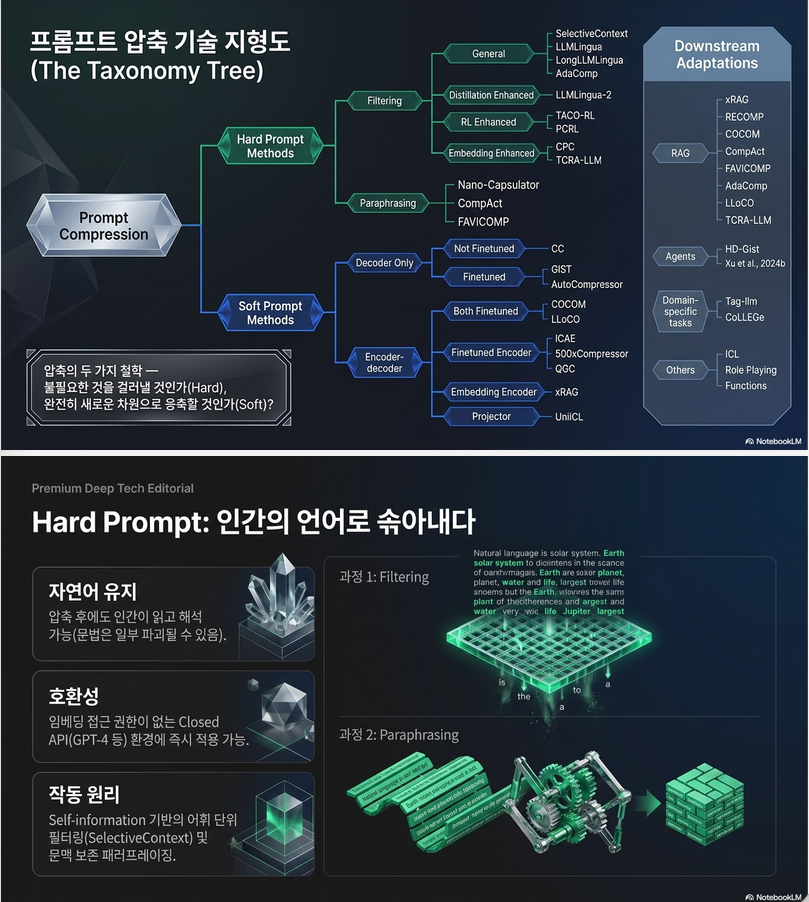
논문은 prompt compression을 크게 두 가지로 분류합니다:
(1) Hard Prompt Compression
- 자연어 형태 유지 (token 삭제/요약)
- 사람이 읽을 수 있음
(2) Soft Prompt Compression
- continuous embedding으로 압축
- 사람이 이해 불가능 (latent representation)
정리:
| 구분 | 방식 | 특징 |
|---|---|---|
| Hard | token filtering / paraphrasing | 해석 가능 |
| Soft | embedding / KV 압축 | 고압축, 고성능 |
3. Hard Prompt Methods (핵심 아이디어)
3.1 Filtering 기반
(a) SelectiveContext
- 각 token의 self-information (정보량) 계산
- 중요도 낮은 토큰 제거
특징:
- 모델 변경 없음 (plug-and-play)
- syntax 유지 위해 phrase 단위 삭제
(b) LLMLingua
- 작은 LM (e.g., GPT-2)으로 중요도 평가
- token-level filtering
특징:
- 최대 20× 압축
- 숫자, unit 등 중요 token 보호
3.2 Paraphrasing 기반
(c) Nano-Capsulator
- prompt를 요약해서 새로운 prompt 생성
특징:
- semantic preservation loss 사용
- 단순 요약보다 task-aware
핵심 insight
Hard prompt는 결국:
정보 밀도 ↑ (redundancy 제거)
4. Soft Prompt Methods (핵심 기여)
핵심 아이디어:
긴 prompt → 소수의 “compression tokens”로 인코딩
4.1 구조 (중요)

논문 Figure 4 (p.5) 기반 구조:
Original Prompt → Encoder → Compressed Tokens → LLM → Output핵심:
- encoder가 정보 요약
- decoder(LLM)는 compressed tokens만 사용
4.2 대표 방법
(1) GIST
- compression token 추가
- attention 제한
효과:
- 이후 token은 compressed token만 참조
(2) AutoCompressor
- prompt를 chunk로 나눠 반복 압축
특징:
- 매우 긴 context 처리 가능
(3) ICAE (In-context AutoEncoder)
- encoder: prompt → embedding
- decoder: frozen LLM
특징:
- decoder 수정 없음
- 최대 ~16× 압축
(4) 500xCompressor (핵심)
- embedding 대신 KV pair 사용
결과:
- 최대 480× 압축
- 정보 보존 ↑
(5) xRAG
- embedding model 기반
- RAG 문서 → 1 token으로 압축
(6) UniICL
- demonstration만 압축
- query는 그대로 유지
핵심 insight
Soft prompt는:
“텍스트 → 새로운 latent language”로 변환
논문에서도 이를:
- 새로운 modality
- 새로운 language
로 해석함
5. 이론적 해석 (중요 포인트)
논문은 단순 방법 소개를 넘어서 메커니즘 해석을 제시합니다:
5.1 Attention 관점
- 기존: 모든 token 간 attention → O(n²)
- 압축 후:
- 일부 token만 전체 정보 저장
- 이후 token은 compressed token만 참조
–> Attention cost 감소
5.2 PEFT 관점
- soft prompt ≈ prompt tuning / prefix tuning
특히:
- ICAE → prompt tuning
- 500xCompressor → prefix tuning (KV 기반)
5.3 Multimodal 관점
- compressed token = image embedding처럼 동작
–> text → latent modality 변환
5.4 New Language 관점
논문 핵심 철학:
compressed prompt는 “LLM 내부 언어”
- 사람이 읽을 수 없음
- LLM 간 전달 가능
- 정보 압축된 representation
6. Downstream Applications
Prompt compression은 다양한 분야에 적용됨:
✔ RAG
- 문서 → embedding token
- inference 비용 감소
✔ ICL
- demonstration 압축
✔ Agents
- API 문서 압축
✔ QA / reasoning
- 긴 context 처리
7. 한계 (매우 중요)
7.1 정보 손실
- compression ratio ↑ → 성능 ↓
7.2 Fine-tuning 문제
- soft prompt는 사실상 tuning → overfitting / drift 발생
7.3 효율성 paradox
- encoder 비용 존재
–> 짧은 output에서는 이득 적음
7.4 Attention 방법과 비교 부족
- sliding window / sparse attention 대비 분석 부족
8. Future Directions (연구 포인트)
논문에서 제시한 중요한 연구 방향:
(1) Encoder 최적화
- 작은 encoder (e.g., BERT) 활용
(2) Hard + Soft 결합
- filtering + embedding
(3) Multimodal 구조 활용
- cross-attention 기반 compression
9. 한줄 핵심 요약
Prompt compression은 “LLM 입력을 더 짧은 표현으로 재인코딩하여, 계산 효율을 높이는 기술”이며,
hard (token-level) vs soft (latent-level) 두 축으로 발전하고 있다.
이 survey의 핵심은 Hard Prompt Methods와 Soft Prompt Methods를 나누고, 각각에서 대표 방법들의 압축 방식, 구조, 장단점, 서로의 차이를 정리하는 것입니다. 아래에서는 논문이 소개한 방법론들을 메커니즘 중심으로 설명합니다.
1. Hard Prompt Methods
Hard prompt compression은 원래의 자연어 prompt를 유지한 채, 일부 token을 삭제하거나 더 짧은 자연어로 바꾸는 방식입니다. 즉, 출력 결과물도 여전히 사람이 읽을 수 있는 자연어입니다. 논문은 이를 크게 filtering과 paraphrasing으로 나눕니다.
1.1 Hard Prompt의 기본 아이디어
기본 목표는 다음과 같습니다.
- 원래 prompt에서 정보량이 낮은 부분을 제거하거나
- 같은 의미를 더 짧은 문장으로 다시 표현해서
- 최종적으로 LLM에 들어가는 입력 길이를 줄이는 것
이 방식의 장점은 다음과 같습니다.
- 압축 결과가 자연어라서 해석 가능
- closed API 모델처럼 embedding 입력을 직접 받을 수 없는 모델에도 적용 가능
- LLM 본체를 수정하지 않아도 됨
반면 한계는,
- 중요한 token을 잘못 지우면 성능 저하
- filtering 후 문법이 깨질 수 있음
- compression 자체에도 별도 계산이 들어감 이라는 점입니다.
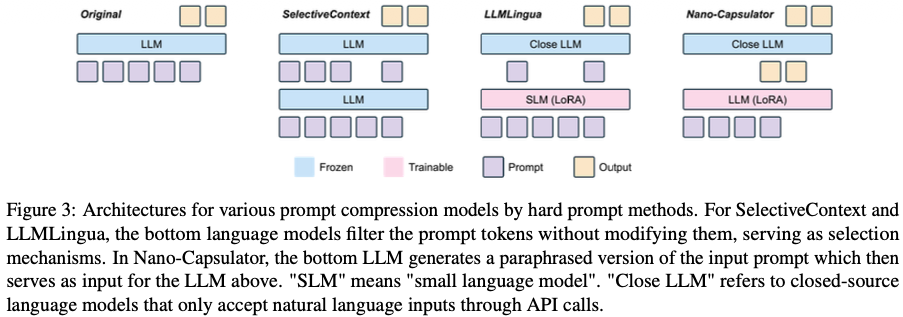
1.2 SelectiveContext
논문은 SelectiveContext를 hard prompt filtering의 대표 방법으로 소개합니다. 핵심은 각 lexical unit의 informativeness를 self-information으로 측정해서, 정보량이 낮은 부분을 삭제하는 것입니다.
작동 방식
SelectiveContext의 절차는 대략 다음과 같습니다.
- 원문 prompt의 각 token 또는 lexical unit에 대해 정보량(self-information) 을 추정
- 정보량이 낮은 부분을 제거 후보로 선정
- 문장 일관성을 유지하기 위해 단일 token이 아니라 noun phrase 단위로 묶어서 삭제
- 압축된 자연어 prompt를 원래 LLM에 입력
여기서 self-information은 직관적으로 말하면,
- 많이 예측되는 평범한 token은 정보량이 낮고
- 덜 예측되는 token은 정보량이 높다
는 개념입니다.
왜 noun phrase 단위로 삭제하나?
단순히 token 단위로 지우면 문법이 심하게 망가질 수 있습니다. 그래서 SelectiveContext는 SpaCy의 dependency parsing을 이용해 noun chunk를 만들고, 이를 기준으로 삭제합니다. 논문이 지적하듯 이것은 자연어의 coherence를 유지하기 위한 장치입니다.
장점
- 외부의 대형 compressor 없이도 적용 가능
- LLM architecture에 거의 독립적
- 사람이 읽을 수 있는 compressed prompt 생성
한계
논문은 두 가지를 명시합니다.
- SpaCy의 phrase boundary detection 정확도에 의존
- 현재 방식은 verb phrase 병합/처리에는 약함
요약
SelectiveContext는 본질적으로
“정보량이 낮은 구를 잘라내는 구문 기반 pruning”
이라고 볼 수 있습니다.
1.3 LLMLingua
LLMLingua는 SelectiveContext와 유사하게 information-based filtering을 수행하지만, 더 실용적인 long prompt/ICL 환경에 맞게 설계되어 있습니다. 논문에 따르면 작은 language model을 사용해 prompt의 self-information을 계산하고, 이를 바탕으로 token-level filtering을 수행합니다.
기본 구조
LLMLingua는 보통 prompt를 다음 구조로 봅니다.
- Instruction
- Input / Demonstrations
- Question
그 다음 압축은 두 단계로 진행됩니다.
- 중요한 demonstration 선택
- 전체 prompt에 대해 token-level filtering
즉, 단순히 모든 token을 일괄적으로 자르는 것이 아니라,
- 먼저 예시(demo) 자체의 중요도를 보고
- 그 다음 내부 token도 정교하게 줄입니다.
SelectiveContext와 차이
SelectiveContext는 phrase-level coherence를 더 중시하는 반면, LLMLingua는 더 미세한 subword/token-level 삭제를 허용합니다. 그래서 SpaCy 기반 phrase merge에 덜 의존하고, 보다 세밀한 압축이 가능합니다.
중요 token 보호
논문에서 특히 언급하는 점은,
- 숫자
- 단위
- instruction/question 내 핵심 요소
같은 token은 보존 알고리즘으로 보호한다는 점입니다.
이는 단순 삭제가 아니라 task-sensitive filtering이라는 의미입니다.
장점
- 최대 20x 수준의 압축률 보고
- closed LLM에도 사용 가능
- ICL prompt 같은 긴 입력에서 효과적
한계
논문은 다음 두 가지를 지적합니다.
- 작은 LM을 추가로 써야 하므로 추가 메모리 필요
- compressor와 target LLM의 tokenizer가 다를 수 있음
- 또한 prompt 중 많은 부분이 demonstration이 아닌 경우, 이것이 prompt compression인지 demo selection인지 경계가 모호할 수 있음
요약
LLMLingua는
“작은 LM으로 정보량을 추정해, 데모와 token을 계층적으로 필터링하는 방식”
입니다.
1.4 Nano-Capsulator
Nano-Capsulator는 filtering이 아니라 paraphrasing 계열입니다. 즉, 원 prompt의 일부를 삭제하는 대신, 전체 prompt를 더 짧은 자연어 prompt로 다시 생성합니다. 논문은 이것을 “summarizes the original prompt into a concise natural language version”이라고 설명합니다.
기본 아이디어
일반 summarization과 비슷해 보이지만, 단순 요약이 아닙니다. 목표는:
- irrelevant information 제거
- 핵심 의미 보존
- downstream LLM task 성능 유지
즉, “짧고도 task-useful한 자연어 prompt”를 만드는 것입니다.
구조
- 아래쪽 compressor model이 원 prompt를 입력받아
- 더 짧은 paraphrased prompt를 생성
- 이 새 prompt를 위쪽 target LLM에 입력
Figure 3에서도 이 구조가 나타납니다. filtering 방식은 token 삭제지만, Nano-Capsulator는 compressor LLM이 새 텍스트를 생성합니다.
학습 방식
논문은 Nano-Capsulator가 단순 summarizer와 달리 다음을 사용한다고 설명합니다.
- semantic preservation loss
- reward function for downstream utility
즉,
- 원 의미를 잃지 않도록 하고
- target LLM이 실제 task를 잘 수행하게 만드는 방향으로 학습합니다.
장점
- filtering보다 문장 유창성이 좋을 수 있음
- 자연어 형태 유지
- task relevant information을 적극적으로 재구성 가능
한계
- compressor model 자체의 메모리 비용이 큼
- 추가 inference가 필요하므로 compression이 pre-generation step처럼 동작
- 따라서 encoding만 하는 방식보다 계산비용이 더 큼
요약
Nano-Capsulator는
“원 prompt를 더 짧고 task-preserving한 자연어로 재작성하는 generative compressor”
입니다.
1.5 Hard Prompt 계열의 확장들
논문은 대표 방법 외에도 몇 가지 확장 방향을 정리합니다.
LongLLMLingua
- LLMLingua의 long-context 버전
- document reordering과 subsequence recovery 사용
- 긴 문맥 환경에서 더 긴 compression window 지원
AdaComp
- query difficulty와 retrieval quality를 바탕으로 adaptive compression
- RAG 상황에서 relevant document를 동적으로 선택
LLMLingua-2
- data distillation로 compressed dataset 생성
- classifier를 학습해 essential token 유지
PCRL / TACO-RL
- RL 기반 token selection
- PCRL은 model-agnostic
- TACO-RL은 task-specific
CPC / TCRA-LLM
- embedding을 활용하는 방향
- CPC는 context-aware sentence embedding으로 relevance ranking
- TCRA-LLM은 embedding 기반 summarization/semantic compression
이들을 보면 hard prompt 쪽도 점차
- token importance 추정
- task-aware filtering
- RL 기반 selection
- retrieval-aware adaptation 쪽으로 확장되고 있습니다.
2. Soft Prompt Methods
Soft prompt compression은 원 prompt를 짧은 연속 벡터 시퀀스(continuous special tokens) 로 변환하는 방식입니다. 즉 최종 압축 결과가 더 이상 자연어가 아니라 embedding space 상의 latent prompt입니다. 논문은 이를 encoder-decoder 관점으로 설명합니다.
2.1 Soft Prompt의 기본 아이디어
핵심은 다음과 같습니다.
- 긴 자연어 prompt를 encoder가 읽고
- 그 의미를 소수의 compression tokens 또는 KV representations에 저장한 뒤
- decoder LLM은 원문 대신 그 압축 표현만 보고 출력 생성
즉,
“긴 discrete text를 짧은 continuous representation으로 바꾸어 downstream generation cost를 줄이는 방식”
입니다.
논문은 이 구조를 Figure 4에서 다양한 방식으로 보여주며, 대표 방법으로
- CC
- GIST
- AutoCompressor
- ICAE
- 500xCompressor
- xRAG
- UniICL 을 설명합니다.
2.2 Contrastive Conditioning (CC)
CC는 decoder-only 스타일의 초기 soft prompt 방법입니다. 기본 아이디어는 자연어 prompt가 유도하는 출력 분포를 더 짧은 soft prompt가 근사하도록 학습하는 것입니다. 논문은 이를 KL divergence 최소화로 설명합니다.
작동 방식
- 원래 natural language prompt를 넣었을 때의 출력 분포를 구함
- 짧은 soft prompt를 학습해서
- 그 soft prompt를 넣었을 때의 출력 분포가 자연어 prompt의 출력 분포와 비슷해지도록 함
즉, 목표는
가 되게 하는 것입니다.
특징
- 특정 natural prompt를 대체하는 compressed continuous prompt를 직접 학습
- contrastive contexts를 통해 sentiment 등 특정 속성을 제어 가능
핵심 한계
논문이 가장 강하게 지적하는 부분은 generalization 부족입니다.
- soft prompt 하나는 특정 natural prompt에 대해 학습됨
- 새로운 prompt가 오면 다시 학습해야 함
즉, prompt-specific compression입니다.
요약
CC는
“자연어 prompt의 조건부 출력분포를 짧은 soft prompt로 distill하는 방식”
입니다.
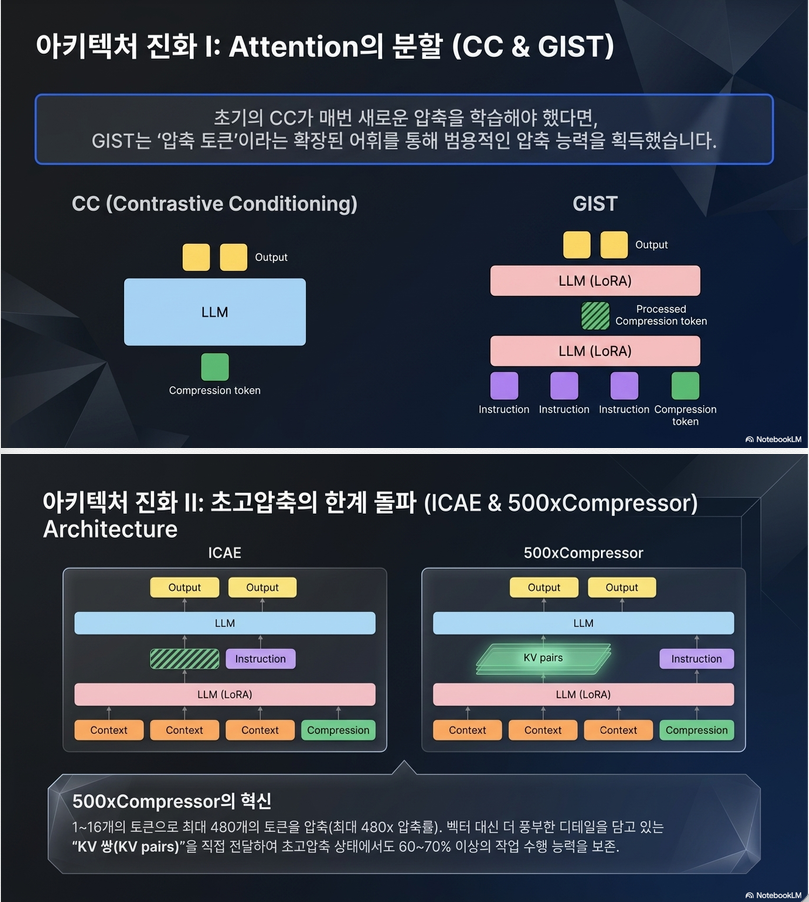
2.3 GIST
GIST는 survey에서 매우 중요한 방법으로 다뤄집니다. 이 방법의 본질은 attention 구조 자체를 수정해 compression token이 전체 입력을 요약하도록 만드는 것입니다.
구조
- 원 prompt 뒤에 여러 개의 compression tokens (gist tokens) 를 붙임
- 이 gist token들은 원 prompt 전체를 attend 가능
- 하지만 이후 생성되는 output token은 원래 prompt 전체를 보지 못하고 gist token만 참조
이게 핵심입니다.
직관
원래는 output token이 모든 이전 token을 attend합니다.
그런데 GIST에서는 다음 구조가 됩니다.
- gist token: 전체 입력 읽기 가능
- output token: gist token만 읽기 가능
즉, gist token이 information bottleneck 역할을 합니다.
Figure 1, Figure 4의 attention 그림이 바로 이 메커니즘을 보여줍니다.
왜 encoder-decoder처럼 보나?
논문은 GIST를 encoder-decoder처럼 해석합니다.
- encoder 역할: same LLM이 원 prompt를 읽어 gist token의 state/KV를 형성
- decoder 역할: 이후 generation은 gist token 기반으로 수행
즉 별도의 encoder 모델은 없지만, attention mask로 두 단계 처리를 만든 셈입니다.
장점
- unseen prompt도 추가 fine-tuning 없이 압축 가능
- 최대 약 26x compression ratio
- 구조가 비교적 단순
한계
- fine-tuning 시 사용한 최대 compressible prompt length에 제한
- gist token은 원래 untuned LLM과 호환되지 않음
- 즉, target LLM을 튜닝해야 함
요약
GIST는
“attention bottleneck으로 전체 입력을 소수의 special token에 응축하는 방법”
입니다.
2.4 AutoCompressor
AutoCompressor는 GIST와 유사하지만, 더 긴 문맥을 처리하기 위해 recursive compression을 도입합니다.
핵심 아이디어
긴 prompt를 한 번에 압축하지 않고:
- prompt를 여러 sub-prompt로 나눔
- 각 sub-prompt를 작은 continuous prompt vector로 압축
- 이전 단계의 compressed representation과 다음 sub-prompt를 함께 다시 압축
- 이 과정을 반복해 전체 문맥을 요약
즉, 계층적/재귀적으로 긴 문맥을 작은 representation으로 축적합니다.
장점
- 논문에 따르면 최대 30,720 tokens 수준의 long-context compression 가능
- 긴 문맥을 chunk-wise로 처리할 수 있음
한계
- recursive training과 compression 과정이 시간 소모적
- GIST와 마찬가지로 compression token은 원래 untuned LLM에 바로 못 씀
요약
AutoCompressor는
“긴 문맥을 여러 단계에 걸쳐 재귀적으로 압축하는 soft prompt 방식”
입니다.
2.5 ICAE (In-Context AutoEncoder)
ICAE는 soft prompt compression의 중요한 전환점입니다. 이 방법은 encoder만 학습하고 decoder LLM은 frozen 상태로 둡니다. 논문은 이 점을 큰 장점으로 봅니다.
구조
- encoder가 긴 context를 입력받아
- 소수의 continuous prompt vectors로 압축
- decoder는 frozen LLM
- 질문(question)은 보통 압축하지 않고 그대로 유지
- decoder는 compressed context + raw question을 기반으로 답변 생성
즉, context compression에 초점을 둔 구조입니다.
GIST와의 차이
GIST는 question/instruction까지 포함된 prompt 전체를 gist token으로 bottleneck할 수 있지만, ICAE는 특히 정보량 높은 detailed context를 압축하고, 질의는 그대로 유지하는 QA 지향 구조입니다. 논문이 이 차이를 명확히 언급합니다.
성능/설정
- 최대 512 tokens를 32, 64, 128 continuous vectors로 압축
- 약 4x~16x compression ratio
- 여러 encoded embedding group을 concat하여 최대 5,120 tokens도 처리 가능
장점
- decoder가 frozen이라 원래 LLM을 그대로 활용 가능
- compression token을 원 LLM에서 직접 사용 가능
- 튜닝 비용과 drift가 상대적으로 줄어듦
한계
- GIST보다 압축률은 낮음
- The Pile 기반 학습/평가로 인해 data leakage 우려
- 즉, LLM pretraining corpus와 overlap 가능성
요약
ICAE는
“긴 context를 continuous embeddings로 autoencoding하되, decoder LLM은 그대로 유지하는 구조”
입니다.
2.6 500xCompressor
이 방법은 ICAE 계열을 더 밀어붙인 방식으로, embedding이 아니라 KV pair를 decoder 입력으로 사용하는 것이 핵심입니다. 논문은 이것을 high compression ratio에서 매우 중요한 차이로 봅니다.
핵심 차이: embedding vs KV pair
- ICAE: compressed embedding vectors 전달
- 500xCompressor: compressed token들의 KV pairs 전달
KV pair는 각 layer의 attention memory 역할을 하므로, 단순 embedding보다 더 풍부한 정보를 담을 수 있다고 보는 것입니다.
구조
- encoder에는 trainable LoRA가 붙음
- decoder는 frozen
- encoder가 compression tokens에 해당하는 KV 정보를 생성
- decoder는 그 KV들을 바탕으로 응답 생성
논문은 이 방식을 prefix tuning과 유사한 관점으로 해석합니다.
성능
- 1~16 tokens로 최대 480 tokens를 압축
- 6x~480x compression ratio
- uncompressed prompt capability의 60~70% 이상 유지 보고
장점
- 매우 높은 압축률
- embedding보다 높은 정보 보존력
- strict unseen data로 평가해 leakage 우려 완화
중요한 개념적 포인트
논문은 분명히 말합니다.
- KV pairs를 모으긴 하지만
- 입력 token의 KV를 조작하는 KV compression과는 다르다
- 여기서는 compression tokens의 KV를 생성하는 것이므로 여전히 prompt compression 범주
즉, 이것은 “prompt의 latent prefix화”에 가깝습니다.
요약
500xCompressor는
“compressed prompt를 embedding이 아니라 KV memory 형태로 넘겨 고압축에서도 정보 보존을 높인 방식”
입니다.
2.7 xRAG
xRAG는 원래 RAG용이지만, survey에서는 일반적인 prompt compression 방법으로도 해석합니다. 핵심은 retrieved documents를 embedding encoder로 매우 작은 표현으로 바꾸고, 그 표현만 decoder에 넘기는 것입니다.
구조
- frozen embedding model이 encoder 역할
- encoder와 decoder 사이에 작은 adapter/projector만 학습
- decoder LLM은 compressed embedding을 받아 응답 생성
특징
논문은 xRAG가 **“한 개 token으로 QA 문맥을 압축할 수 있음을 보여준다”**고 설명합니다. 매우 공격적인 extreme compression 사례입니다.
장점
- RAG context를 아주 compact하게 표현 가능
- embedding model 활용으로 구조 단순화 가능
한계
- 최종적으로는 embedding model도 꽤 큰 모델일 수 있음
- SFR-Embedding-Mistral 같은 encoder를 쓰면 사실상 두 개의 LLM + projector가 필요
- ICAE/500xCompressor보다 로딩 비용이 클 수 있음
요약
xRAG는
“retrieved text를 embedding space에서 극도로 압축해 decoder에 전달하는 RAG형 soft compression”
입니다.
2.8 UniICL
UniICL은 soft prompt compression을 in-context learning example compression에 특화한 방식입니다. 즉, prompt 전체가 아니라 demonstration 부분만 압축합니다.
구조
- encoder와 decoder 모두 frozen
- 둘 다 같은 LLM 사용
- 중간에 projector만 trainable
- demonstrations를 continuous vectors로 압축
- query는 그대로 유지
왜 중요한가?
ICL에서는 examples의 선택과 품질이 매우 중요합니다. UniICL은 demonstration 자체를 embedding-like continuous vector로 바꿔 저장/활용함으로써, example selection과 compression을 결합하는 관점을 제시합니다.
장점
- trainable component가 projector뿐이라 메모리 절약
- encoder/decoder 모두 frozen이라 학습 부담 감소
- example retrieval/selection과 결합하기 좋음
요약
UniICL은
“ICL demonstration을 연속 표현으로 요약해 query와 함께 쓰는 예시 특화 compression 방식”
입니다.
3. Soft Prompt 방법론의 공통 메커니즘
논문은 단순 분류를 넘어서 soft prompt compression을 해석하는 관점도 제시합니다. 이 부분이 방법론 이해에 중요합니다.
3.1 Attention Optimization 관점
기존 transformer에서는 새 token이 모든 이전 token을 attend하므로 문맥이 길수록 비용이 커집니다.
Soft prompt compression에서는 두 단계가 일어납니다.
- 소수의 compression tokens가 전체 입력을 읽음
- 이후 생성은 전체 입력이 아니라 compression tokens만 참조
즉, 긴 입력을 짧은 attention memory로 치환하는 셈입니다.
논문은 이를 attention optimization의 한 형태로 볼 수 있다고 설명합니다.
3.2 Prompt Tuning / Prefix Tuning 관점
논문은 이 연결을 명시적으로 제시합니다.
- ICAE류는 prompt tuning과 유사
- encoder가 각 입력마다 새로운 soft embeddings를 생성
- 500xCompressor는 prefix tuning과 유사
- decoder 입력이 embedding이 아니라 KV pairs이기 때문
즉, soft prompt compression은
“입력마다 동적으로 생성되는 prompt tuning / prefix tuning”
으로 볼 수 있습니다.
3.3 Modality Integration 관점
논문은 compressed text를 새로운 modality처럼 보기도 합니다.
- 이미지 encoder가 image → embeddings로 바꾸듯
- prompt compressor는 text → compressed embeddings로 바꿈
- decoder LLM은 이 latent modality를 이해해 응답 생성
이 관점은 특히 multimodal architectures와의 연결 가능성을 보여줍니다.
3.4 New Synthetic Language 관점
가장 흥미로운 해석 중 하나는, 이 compressed embeddings를 LLM이 이해하는 새로운 언어로 보는 것입니다.
즉,
- 자연어를 latent vectors로 번역하고
- 이를 다른 LLM에 전달 가능하며
- 입력이 달라지면 decoder가 적응적으로 반응
한다는 점에서, compressed prompt를 일종의 LLM 내부 통신 언어로 볼 수 있다는 것입니다.
4. Hard vs Soft의 방법론적 차이
아래처럼 정리할 수 있습니다.
| 항목 | Hard Prompt | Soft Prompt |
|---|---|---|
| 압축 결과 | 자연어 | continuous vectors / KV |
| 해석 가능성 | 높음 | 낮음 |
| 적용 대상 | closed API LLM 포함 | 보통 model-side access 필요 |
| 핵심 연산 | 삭제 / 재서술 | 인코딩 / latent bottleneck |
| 장점 | 단순, 범용, readable | 고압축, 구조적 효율 |
| 단점 | 정보 손실, 문법 손상 가능 | 학습 필요, encoder 비용 큼 |
이 survey의 전체 메시지는 단순합니다.
- Hard prompt는 “자연어를 더 조밀하게 만든다”
- Soft prompt는 “자연어를 latent representation으로 바꾼다”
5. 논문 기준으로 본 각 방법의 한 줄 요약
Hard Prompt
- SelectiveContext: self-information 기반 phrase 삭제
- LLMLingua: 작은 LM 기반 token-level 중요도 필터링
- Nano-Capsulator: task-aware 자연어 재서술 압축
Soft Prompt
- CC: 자연어 prompt의 출력분포를 soft prompt가 모사
- GIST: attention bottleneck을 만드는 gist tokens
- AutoCompressor: 긴 문맥을 recursive하게 압축
- ICAE: frozen decoder를 둔 context autoencoding
- 500xCompressor: embedding 대신 KV 기반 고압축
- xRAG: retrieval context를 extreme embedding compression
- UniICL: demonstration 전용 compression
6. 연구적으로 가장 중요한 포인트
이 논문을 방법론 관점에서 읽으면, 실질적으로 다음 세 축으로 정리됩니다.
축 1. 무엇을 압축하나?
- token
- phrase
- sentence
- demonstration
- context 전체
- retrieval document
축 2. 어떤 표현으로 바꾸나?
- 삭제된 자연어
- 재작성된 자연어
- continuous embedding
- KV prefix
축 3. decoder는 얼마나 바뀌나?
- 전혀 안 바뀜
- attention mask만 바뀜
- LoRA 부착
- frozen decoder + learned encoder
- projector만 학습
즉, prompt compression 연구는 사실상
“입력 정보를 어떤 bottleneck representation에 넣을 것인가”
의 문제로 볼 수 있습니다.
답글 남기기