



1. 문제 설정: Black-box Optimization
TPE는 Bayesian Optimization (BO) 계열 알고리즘으로, 다음 문제를 해결합니다:
- 함수 f(x): black-box (gradient 없음, expensive evaluation)
- 목적: 적은 평가 횟수로 최적값 탐색
2. 핵심 아이디어: 기존 BO와의 차이
일반 BO (e.g., GP-based)
- 모델링: p(y|x)
- acquisition: EI, PI 등
TPE의 핵심 차별점
역방향 모델링:
즉,
- : 좋은 샘플 (top γ)
- : 나쁜 샘플
–> 이게 TPE의 가장 중요한 구조입니다.
3. Acquisition Function
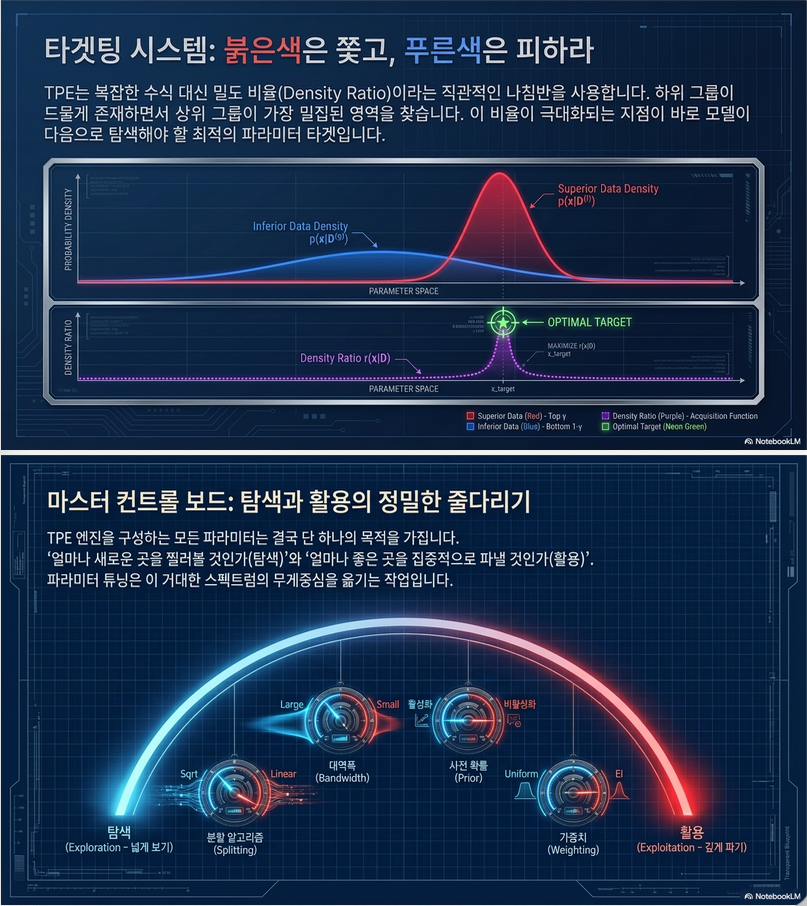
TPE는 다음 density ratio를 최대화:
- 직관:
- 좋은 영역에서 확률 ↑
- 나쁜 영역에서 확률 ↓
- 이는 **PI (Probability of Improvement)**와 동등
4. 전체 알고리즘 (핵심 루프)
논문 Algorithm 1 요약:
Step 0: 초기화
- 랜덤 샘플 개
Step 1: 데이터 분할
- 기준: 상위 γ quantile
Step 2: KDE 모델링
- Kernel Density Estimation 사용
Step 3: 후보 샘플링
–> “좋은 영역에서만 샘플링” (exploitative)
Step 4: 최적 후보 선택
Step 5: 평가 및 반복
5. KDE 모델 구조 (중요)
구성 요소:
| 요소 | 의미 |
|---|---|
| kernel (Gaussian 등) | |
| b | bandwidth |
| weight | |
| prior |
–> 즉, mixture density model
6. 핵심 하이퍼파라미터 역할
논문의 핵심 기여는 “각 파라미터의 역할 분석”
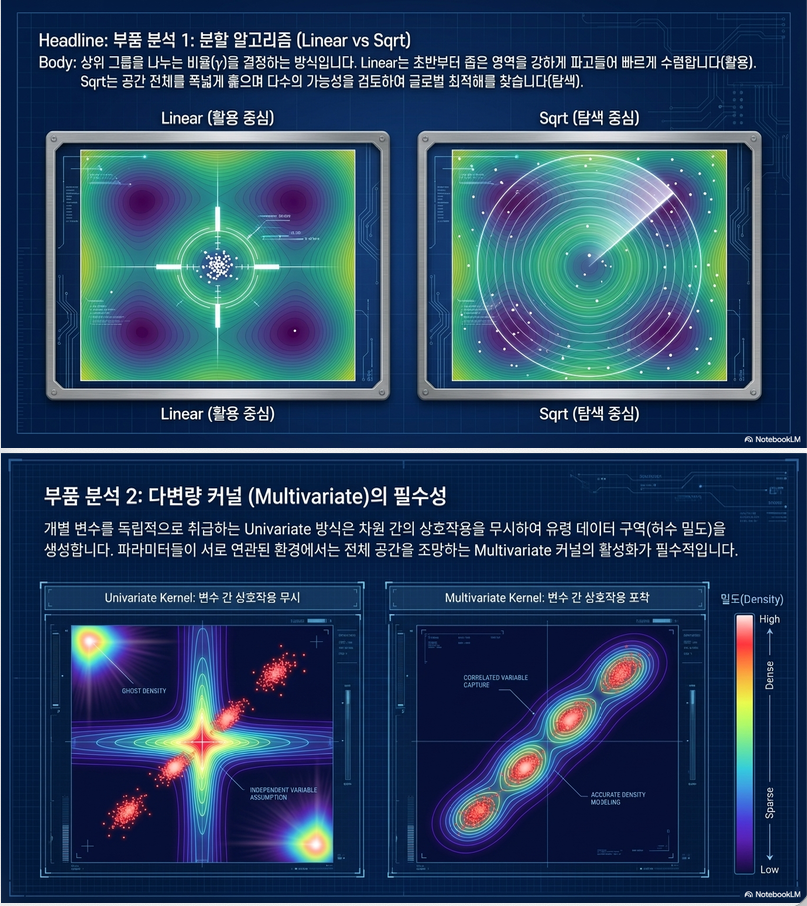
(1) γ (Splitting ratio)
- small γ → exploration ↑
- large γ → exploitation ↑
대표 설정:
- linear: γ = constant
- sqrt: γ ∝ 1/√N
–> sqrt가 더 exploratory
(2) Weighting
- uniform
- decay
- EI-based
특징:
- EI → best 성능 (top-5%)
- uniform → robust
(3) Bandwidth b
- small b → sharp KDE → exploitation
- large b → smooth KDE → exploration
–> exploration–exploitation 핵심 조절 변수
(4) Prior
- exploration 유지 역할
- 없으면 local optimum에 갇힘
–> 매우 중요 (논문에서 “indispensable” 수준)
(5) Multivariate vs Univariate
- univariate:
- 각 dimension 독립
- interaction 못 잡음
- multivariate:
- correlation 반영
- 성능 ↑
–> 실험에서 가장 중요한 요소 중 하나
7. 직관 요약
TPE는 다음 전략:
Step 1
좋은 샘플만 모음
Step 2
좋은 분포 vs 나쁜 분포 비교
Step 3
“좋은/나쁜 비율이 높은 지점” 선택
즉,
“좋은 분포에서는 많이 나오고, 나쁜 분포에서는 잘 안 나오는 x를 찾는다”
8. 왜 잘 동작하는가?
1. density ratio = implicit ranking
- absolute 값보다 상대 비교
2. KDE = flexible
- GP보다 scaling 좋음
- discrete / conditional 처리 가능
3. tree-structured space 대응
- conditional hyperparameter 가능
9. 기존 BO와 비교
| 방법 | 모델링 | 장점 |
|---|---|---|
| GP-BO | p(y|x) | uncertainty modeling |
| TPE | p(x|y) | scalable, discrete OK |
10. 핵심 takeaway
TPE의 본질
- BO의 변형이 아니라
- density ratio optimization
성능 핵심 요인
- multivariate KDE
- bandwidth
- γ tuning
직관
- “좋은 샘플 분포를 직접 모델링”
좋은 샘플과 나쁜 샘플을 나누는 의 의미, p(x|y) 의미, tree-structured space 의미?
1. 의 의미 (좋은/나쁜 샘플 분할 기준)
정의
즉,
- 전체 관측값 중 상위 γ 비율의 경계값
- 논문에서는 최소화 문제이므로:
- 작을수록 좋은 값
데이터 분할
- l: lower → 좋은 샘플
- g: greater → 나쁜 샘플
직관
- 전체 데이터를 성능 기준으로 binary split
- “좋은 region vs 나쁜 region”을 분리
중요한 점:
절대 값이 아니라 상대 순위 기반 분할
왜 중요한가?
- BO에서 핵심은 “좋은 영역 찾기”
- TPE는 이를 density modeling 문제로 변환
γ의 역할
| γ 값 | 효과 |
|---|---|
| 작음 | 좋은 샘플 적음 → exploration ↑ |
| 큼 | 좋은 샘플 많음 → exploitation ↑ |
2. p(x|y) 의 의미
일반 BO vs TPE
일반 BO
p(y|x)
- “이 x에서 성능이 어떻게 나올까?”
TPE
p(x|y)
- “이 성능을 낸 x는 어떤 분포일까?”
–> 완전히 관점이 뒤집힘
TPE에서의 정의
직관
→ 좋은 성능을 내는 x들의 분포
→ 나쁜 성능을 내는 x들의 분포
핵심 해석
TPE는 “좋은 결과를 만든 x의 패턴”을 학습한다
왜 이렇게 하나?
Bayes rule:
→ 직접 p(y|x) 모델링 대신
→ 더 쉬운 p(x|y)를 모델링
최종 목적
–> 의미:
“좋은 샘플에서 많이 나오고, 나쁜 샘플에서는 잘 안 나오는 x”
3. Tree-Structured Space 의미
정의
조건부(parameter dependency)가 존재하는 탐색 공간
논문 정의:
일부 파라미터는 특정 조건에서만 존재
예시
Neural Network 구조
L ∈ {2, 3}
if L = 2:
dropout_1, dropout_2
if L = 3:
dropout_1, dropout_2, dropout_3여기서:
- dropout_3는
- L=3일 때만 존재
- L=2일 때는 없음
왜 “tree”?
구조가 이렇게 됨:
L
/ \
2 3
/ / \
(d1,d2) (d1,d2,d3)–> 트리 형태의 조건 분기
기존 BO 문제점
- GP 기반 BO:
- fixed-dimensional input 필요
- conditional parameter 처리 어려움
TPE의 장점
TPE는
형태로 분해 가능 → 각 변수 독립 처리 가능
–> 그래서
- 존재하지 않는 parameter는 무시 가능
- conditional 구조 자연스럽게 처리
핵심 직관
“모든 parameter가 항상 존재할 필요 없음”
4. 세 개 개념의 연결
이 세 개는 따로가 아니라 하나의 파이프라인
전체 흐름
Step 1: 성능 기준 분할
Step 2: 분포 학습
Step 3: 최적화
Step 4: 구조 지원
- tree-structured space에서도 동작
5. 핵심 요약 (연구 관점)
✔
- 성능 기반 threshold
- ranking 기반 BO
✔ p(x|y)
- “좋은 해를 만드는 구조” 학습
- generative view
✔ tree-structured space
- conditional parameter space
- 실제 HPO 문제의 핵심
6. 한 줄 정리
TPE는 “좋은 결과를 만드는 parameter 분포”를 학습해서, 그 분포에서 다음 후보를 샘플링하는 알고리즘이다.
TPE도 BO에 포함되는가?
결론부터 명확히 말하면:
TPE는 Bayesian Optimization (BO)의 한 종류입니다.
다만, **“표준적인 GP 기반 BO와는 다른 계열의 BO”**라고 이해하는 것이 정확합니다.
1. 왜 TPE가 BO인가?
BO의 본질은 다음 두 가지입니다:
(1) surrogate model 구축
(2) acquisition function 기반 탐색
TPE도 이 두 조건을 만족
✔ surrogate model
- 일반 BO:
- TPE:
–> 형태만 다르고 동일한 역할 수행
✔ acquisition function
TPE:
→ 이것은 이론적으로
와 동등
–> 즉, 정식 BO acquisition function을 사용
2. GP-BO vs TPE (핵심 차이)
| 구분 | GP-based BO | TPE |
|---|---|---|
| 모델링 | p(y|x) | p(x|y) |
| 모델 | Gaussian Process | KDE |
| acquisition | EI / PI | density ratio (≈ PI) |
| 특징 | global uncertainty modeling | density-based local modeling |
| 장점 | 이론적 우아함 | scalability, discrete 지원 |
| 단점 | high-dim 약함 | local search tendency |
3. BO 내부에서의 위치
BO 계열을 구조적으로 보면:
Bayesian Optimization
│
├── GP-based BO (classical)
│
├── Tree-based BO
│ └── SMAC (Random Forest)
│
├── Density-based BO
│ └── TPE ← 여기
│
└── Neural BO (recent)–> TPE는 density estimation 기반 BO
4. 왜 “BO처럼 안 보이는가?”
좋은 질문입니다. 헷갈리는 이유는:
이유 1: 모델 방향이 반대
- 일반 BO: → “x → y” 예측
- TPE: → “좋은 y → x” 생성
–> generative optimization 느낌
이유 2: sampling 방식
- GP-BO: optimization over acquisition
- TPE: sampling + ranking
–> heuristic처럼 보임
이유 3: uncertainty 표현 없음
- GP: variance 명시적
- TPE: density ratio로 implicit 표현
5. 핵심 통찰 (중요)
TPE는 다음 관점으로 보면 이해가 쉽습니다:
✔ BO의 일반 형태
✔ TPE의 변형
즉,
BO의 acquisition을 density ratio 형태로 재구성한 것
6. 연구 관점에서 중요한 포인트
(1) BO의 일반화된 형태
TPE는 BO를 이렇게 확장:
“uncertainty modeling 없이도 BO 가능”
(2) discrete optimization에 강함
- token sequence
- architecture search
- prompt optimization
–> 그래서 AutoML에서 많이 사용
(3) LLM 연구와 연결
- TPE = discrete latent BO
답글 남기기