[태그:] Prompt Compression
-

xRAG: Extreme Context Compression for Retrieval-Augmented Generation with One Token (NeurIPS 2024)
xRAG 논문 핵심 아이디어 이 논문의 핵심은 다음 한 문장으로 요약할 수 있습니다. 검색된 문서를 텍스트로 LLM에 넣지 말고, retrieval embedding 하나만 “문서 토큰 1개”처럼 넣자. 즉, 기존 RAG는: 를 입력으로 사용했지만, xRAG는: 만 사용합니다. 문제의식 기존 RAG의 가장 큰 문제는: 라는 점입니다. 예를 들어: 이면 대부분의 계산량이 retrieval context 처리에 사용됩니다. 기존…
-

PISCO: Pretty Simple Compression for Retrieval-Augmented Generation (Findings of ACL 2025)
이 논문은 RAG(Retrieval-Augmented Generation)에서 문서를 매우 강하게 압축하면서도 QA 성능 손실을 거의 없애는 soft compression 방법을 제안한 논문입니다. 핵심 메시지는 다음과 같습니다. 기존 soft compression은 압축률은 높지만 QA 정확도가 크게 떨어졌고, 대규모 pretraining + labeled QA 데이터가 필요했다.PISCO는 pretraining 없이, 단순한 sequence-level distillation만으로x16 압축에서도 원본 LLM과 거의 동일한 QA 성능을 달성한다. 1. 문제 배경…
-

* LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression (ACL Findings 2024)
이 논문은 기존 LLMLingua 계열의 한계를 개선한 task-agnostic prompt compression 논문입니다. 핵심 아이디어는 다음과 같습니다. “정보 엔트로피(perplexity) 기반으로 토큰을 제거하지 말고,LLM(GPT-4)로부터 압축 지식을 distillation하여‘이 토큰을 유지할지 버릴지’를 분류하도록 학습하자.” 즉: 입니다. 1. 문제 배경 LLM prompt는 점점 길어짐: → 수천~수만 token. 문제: 따라서: Original Prompt→Compressed Prompt\text{Original Prompt}\rightarrow\text{Compressed Prompt} 를 수행하고 싶음. 2. 기존 방법의 한계 논문은 기존…
-

* In-Context Autoencoder for Context Compression in a Large Language Model (ICLR 2024)
이 논문은 LLM의 긴 context를 매우 짧은 “memory slot”으로 압축하는 방법인 ICAE (In-context Autoencoder) 를 제안한다. 핵심 아이디어는: “원래 512-token context를, 예를 들어 128개의 latent memory slot으로 압축한 뒤, LLM이 이 compressed representation만 보고도 원래 context를 거의 복원하거나 질문에 답할 수 있게 하자.” 즉, 기존 long-context transformer처럼 attention 구조를 바꾸는 대신: 를 목표로 한다. …
-

* 500xCompressor: Generalized Prompt Compression for Large Language Models (ACL 2025)
이 논문은 LLM 입력 프롬프트를 극단적으로 압축하는 방법인 500xCompressor를 제안합니다. 핵심 아이디어는: 특히 기존 soft prompt compression 계열(ICAE 등)의 한계를 넘어서: 을 강조합니다. 핵심 아이디어 논문의 핵심은: “자연어 전체를 embedding 몇 개로 요약하는 것이 아니라,KV cache 자체를 압축 representation으로 사용하자” 입니다. 기존 ICAE는: 하지만 500xCompressor는: 즉: Text→Compression Tokens→KV cache\text{Text} \rightarrow \text{Compression Tokens} \rightarrow \text{KV cache} 를 latent…
-
Dynamic Compressing Prompts for Efficient Inference of Large Language Models (ArXiv 2025)
핵심 아이디어 Prompt compression을 “순차적 의사결정 문제 (MDP)”로 모델링하여token을 하나씩 제거하면서 성능을 유지하는 RL 기반 방법 1. 문제 정의 (Why this paper?) 배경 따라서: “짧지만 동일한 의미를 유지하는 prompt”가 필요 기존 방법 한계 논문에서 명확히 3가지로 정리: (1) Task-specific (2) Static token importance (3) Black-box dependency 2. 핵심 방법론: LLM-DCP 핵심 구조 Prompt compression =…
-

* Understanding and Improving Information Preservation in Prompt Compression for LLMs (Findings of EMNLP 2025)
이 논문은 LLM의 Prompt Compression 기법들을 단순히 “성능 유지” 관점이 아니라, 를 체계적으로 분석한 논문입니다. 1. 핵심 문제의식 최근 LLM은 수천~수십만 token context를 처리할 수 있지만: 문제가 발생합니다. 그래서 Prompt Compression이 필요합니다. 논문은 기존 연구들이 대부분: “압축 후 downstream accuracy만 측정” 하는 것이 문제라고 지적합니다. 즉: 를 봐야 한다는 것입니다. 2. Prompt Compression…
-
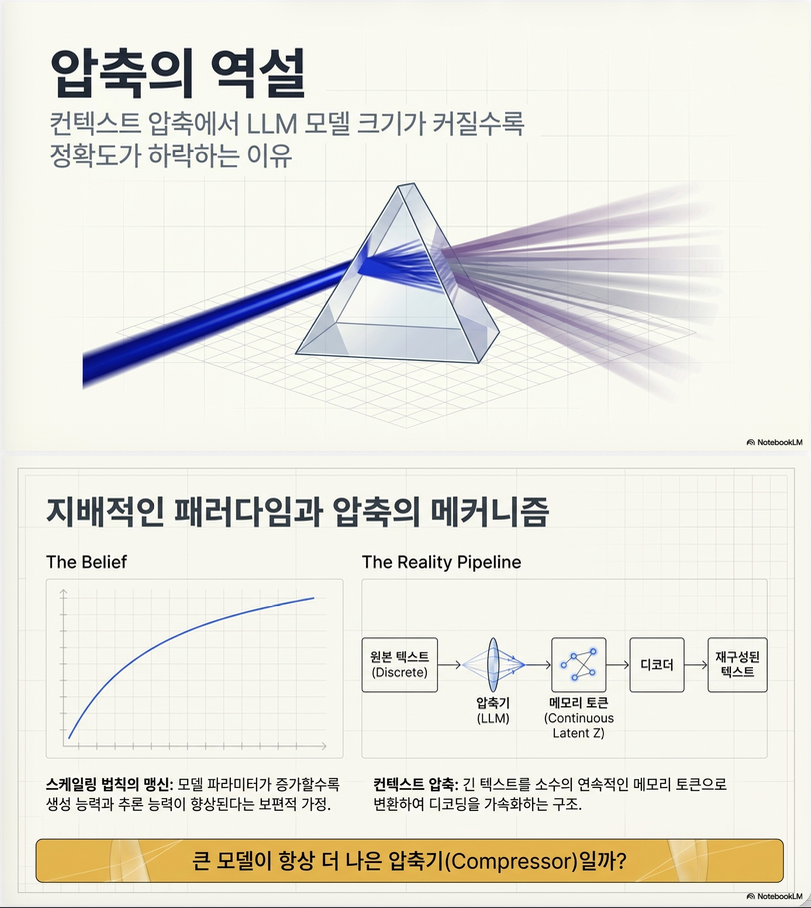
* When Less is More: The LLM Scaling Paradox in Context Compression (ArXiv 2026)
논문 개요 이 논문은 LLM 기반 context compression에서 기존 scaling law와 반대되는 현상을 발견한 논문이다. 핵심 주장은 다음과 같다: 압축기(compressor) 모델이 커질수록 reconstruction score는 좋아지지만, 실제 원문 충실성(faithfulness)은 오히려 나빠질 수 있다. 논문은 이를: Size-Fidelity Paradox 라고 부른다. 1. 문제 배경 최근 long-context compression에서는 다음 구조가 많이 사용된다. Compressor–Decoder 구조 입력 문서 x를:…
-

* Prompt Compression for Large Language Models: A Survey (NAACL 2025)
1. 핵심 문제의식 (Why Prompt Compression?) LLM 사용 시 가장 큰 병목 중 하나는 긴 prompt입니다. 따라서 목표는: “성능 유지하면서 prompt 길이 최소화” 2. 전체 프레임워크 논문은 prompt compression을 크게 두 가지로 분류합니다: (1) Hard Prompt Compression (2) Soft Prompt Compression 정리: 구분 방식 특징 Hard token filtering / paraphrasing 해석 가능 Soft embedding /…