


1. 문제 정의 (Motivation)
기존 LLM의 핵심 한계:
- test-time에서 학습 불가능
- 매 문제마다 초기 상태에서 다시 추론
- 동일한 실수 반복 / 동일한 전략 재발견
논문 핵심 주장:
“LLM도 inference 과정에서 지속적으로 학습해야 한다”
즉,
- fine-tuning 없이
- black-box 상태에서
- test-time learning (online learning) 구현
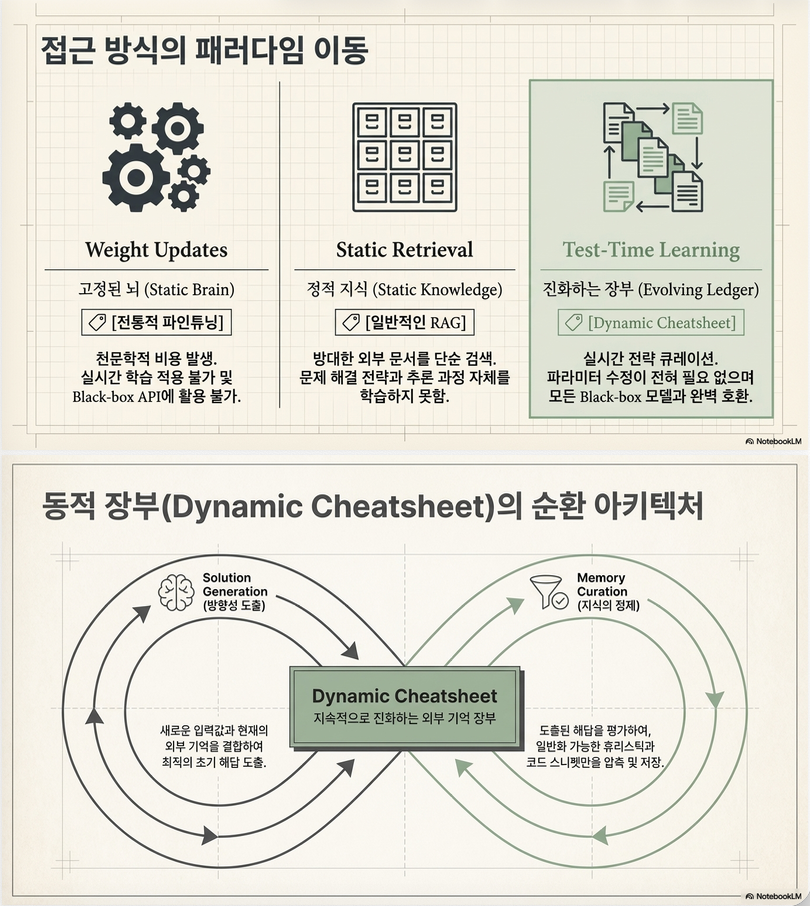
2. 핵심 아이디어: Dynamic Cheatsheet (DC)
직관
LLM에게 “치트시트(cheatsheet)”를 만들어주자:
- 잘 풀린 문제 → 전략 저장
- 틀린 문제 → 전략 수정/삭제
- 다음 문제 → 재사용
전체 구조 (핵심 loop)
논문 수식으로 표현:
(1) 생성 단계
- 입력: 문제 , 메모리
- 출력: 답변
(2) 메모리 업데이트
- 성공 → 전략 저장
- 실패 → 수정/삭제
- 압축 → generalizable knowledge 유지
핵심 특징:
- parameter update 없음 (black-box)
- external memory만 업데이트
- self-supervised (GT 필요 없음)
3. DC의 두 가지 버전
3.1 DC-Cu (Cumulative)
가장 기본 구조:
Query → Generate → Curate → Memory update특징:
- 단순 누적
- retrieval 없음
3.2 DC-RS (Retrieval + Synthesis) 핵심
확장된 구조:
Retrieval
Memory update
Generation
차이:
| 요소 | DC-Cu | DC-RS |
|---|---|---|
| retrieval | ❌ | ✅ |
| update 시점 | after | before |
| 성능 | 좋음 | 최고 |
4. 기존 방법들과의 차별성
논문에서 비교:
| 방법 | 특징 | 한계 |
|---|---|---|
| Baseline | memory 없음 | 반복 실수 |
| Full History | 전체 대화 append | context explosion |
| Retrieval (DR) | retrieve only | abstraction 없음 |
| DC | curated memory | 없음 |
핵심 차별점
“raw data가 아니라 abstracted strategy를 저장한다”
즉:
- RAG → fact retrieval
- DC → strategy retrieval
5. 실험 결과 (핵심 인사이트)
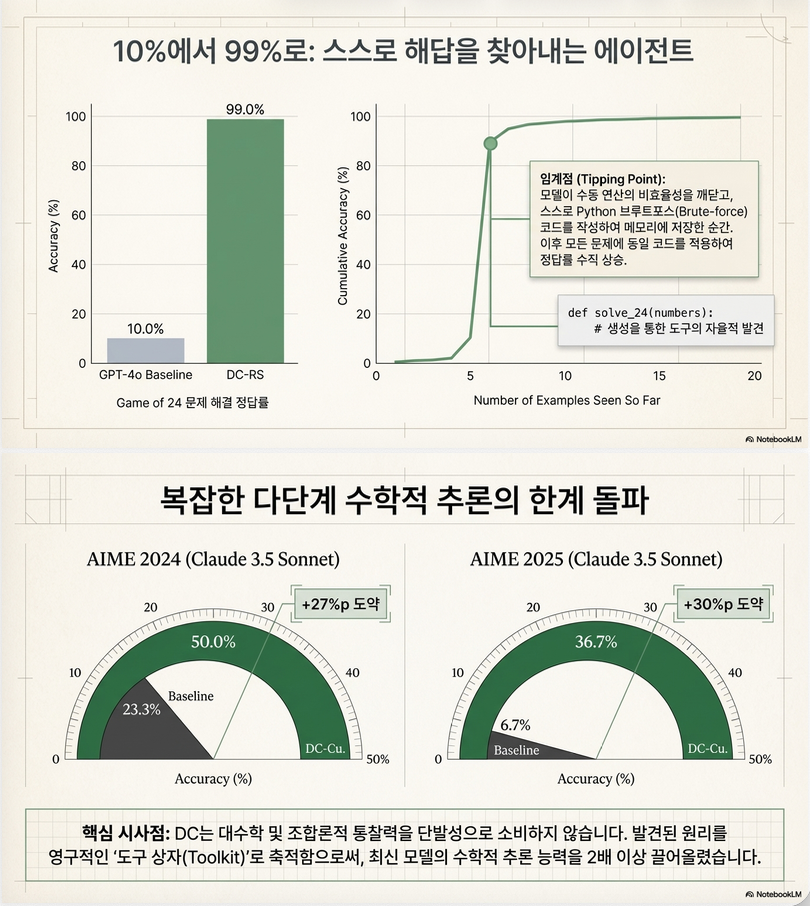
5.1 Game of 24 (가장 중요한 결과)
- GPT-4o:
- Baseline: 10%
- DC-RS: 99%
원인:
Python brute-force solver 발견 → 저장 → 반복 사용
5.2 AIME (수학 문제)
- Claude Sonnet:
- 6.7% → 40.6% (6배 상승)
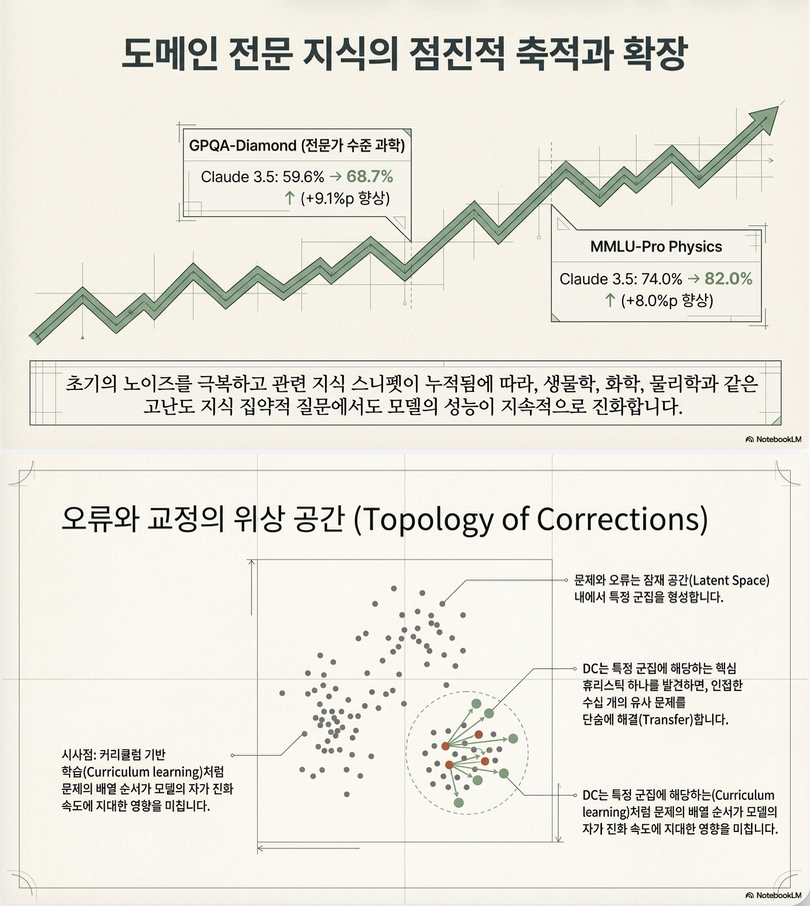
5.3 GPQA / MMLU
- +5~9% 성능 향상
- 특히 reasoning task에서 효과 큼
핵심 해석
성능 향상의 본질:
“문제를 잘 푸는 것이 아니라
문제를 푸는 방법을 학습한다”
6. 중요한 발견 (Research Insights)
6.1 Test-time learning 가능
- 반복 task에서 성능 지속 증가
- cumulative learning 발생
6.2 Tool-use emergence
- 모델이 자동으로:
- Python 사용
- 알고리즘 저장
- 재사용
→ Toolformer-like behavior at inference
6.3 Memory quality가 핵심
- 좋은 전략 → 성능 상승
- 나쁜 전략 → 성능 붕괴
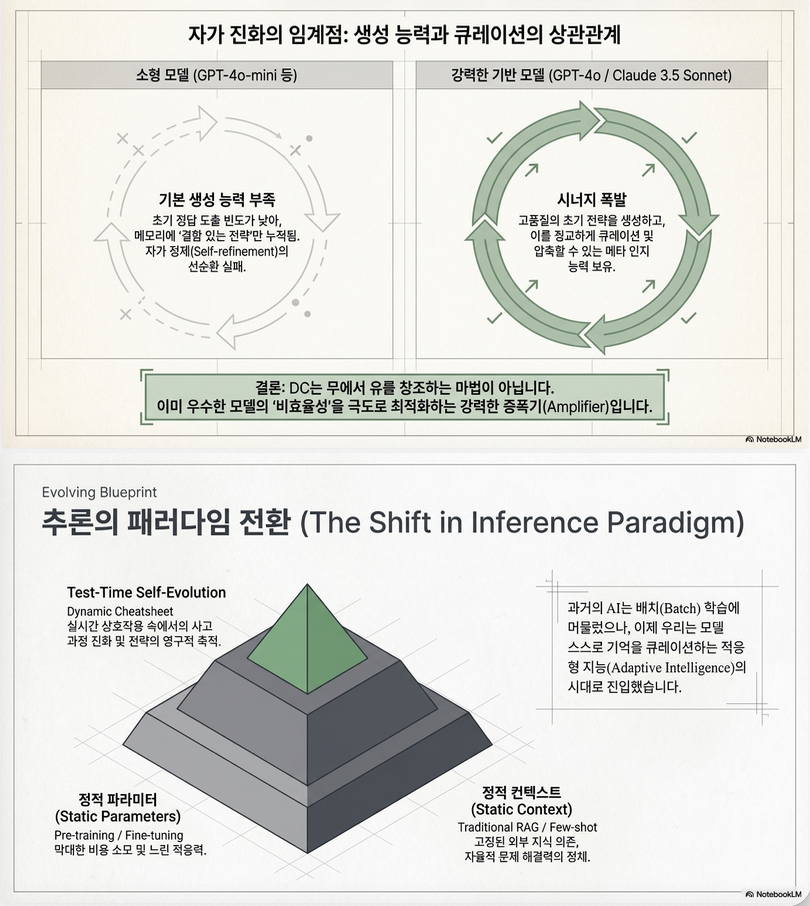
6.4 Model scale dependency
- 큰 모델 → 효과 큼
- 작은 모델 → 효과 제한
이유:
좋은 전략을 “생성”해야 저장 가능
7. 한계 (Critical Analysis)
7.1 error propagation
- 잘못된 전략이 memory에 들어가면 → 계속 재사용
7.2 retrieval noise
- 잘못된 example retrieve → 혼란
7.3 small model failure
- 초기 성능 낮으면 → memory 자체가 오염됨
7.4 sequential dependency
- 병렬 inference 어려움
8. 연구적 의미 (중요)
8.1 기존 패러다임
| 방식 | 특징 |
|---|---|
| Fine-tuning | parameter update |
| RAG | static knowledge |
| CoT / ToT | inference compute 증가 |
8.2 DC
“Memory-based test-time learning”
- parameter-free
- online adaptation
- strategy accumulation
9. 한줄 요약
Dynamic Cheatsheet는
LLM이 inference 중 스스로 전략을 축적하고 재사용하는
parameter-free test-time learning framework이다.
논문의 **방법론(Dynamic Cheatsheet, DC)**을 핵심 수식, 모듈, 알고리즘 관점에서 정리합니다.
1. 전체 프레임워크 개요
DC는 다음 3개 모듈로 구성됩니다:
- Generator (Gen): 답 생성
- Curator (Cur): memory 업데이트
- Retriever (Retr): 유사 사례 검색 (DC-RS에서만)
Core Loop (Test-time learning)
각 step i에서:
- memory 기반 생성
- 결과 평가 및 memory 업데이트
- 다음 문제로 진행
–> online sequential learning
2. 수식 기반 정의
2.1 기본 정의 (DC-Cu)
(1) Generation
- : 현재 문제
- : 현재 memory
- : 모델 출력
(2) Memory Update
Curator는 다음을 수행:
- correctness 평가
- generalization 가능성 평가
- 압축/추상화
- 잘못된 전략 제거
핵심: raw output → abstract strategy 변환
3. Memory 구조
논문에서 memory는 단순 텍스트가 아니라:
Memory Entry 구조
각 entry는 다음 형태:
{
"pattern": problem_type,
"strategy": solution_heuristic,
"code": optional_tool,
"notes": generalization
}예:
If task == "Game of 24":
→ Use brute-force permutation search in Python특징
- compact
- generalizable
- task-agnostic
–> full history가 아니라 “핵심 전략만 저장”
4. Curator (핵심 모듈)
Curator가 DC의 핵심입니다.
4.1 입력
4.2 수행 기능
(1) 평가 (self-evaluation)
- 답이 맞는지 판단 (GT 없이)
- heuristic:
- consistency
- plausibility
- execution 결과
(2) 추상화 (abstraction)
raw solution → reusable rule예:
- 특정 숫자 → 일반 패턴으로 변환
- 특정 코드 → 함수화
(3) pruning
- 중복 제거
- 잘못된 전략 제거
- 비효율 전략 삭제
(4) compression
- memory 길이 제한 유지
- 핵심 정보만 유지
핵심 포인트
Curator = “test-time optimizer” 역할
5. DC-RS (Retrieval + Synthesis)
DC-Cu의 한계를 해결한 확장 버전
5.1 Retrieval 단계
- embedding similarity 기반
- top-k 선택
논문 설정:
- embedding: text-embedding-3-small
- k = 3
5.2 Memory update (before generation)
기존과 차이:
- 생성 전에 memory 개선
5.3 Generation
전체 흐름
Retrieve → Curate → Generate6. 알고리즘 (Pseudo-code)
6.1 DC-Cu
M = []
for x in test_data:
y = Gen(x, M)
M = Cur(M, x, y)6.2 DC-RS
M = []
D = [] # past (x, y)
for x in test_data:
R = retrieve(x, D, k=3)
M = Cur(M, x, R)
y = Gen(x, M)
D.append((x, y))7. 핵심 설계 요소
7.1 Memory vs RAG 차이
| 요소 | RAG | DC |
|---|---|---|
| 저장 | facts | strategies |
| 업데이트 | 없음 | 있음 |
| 목적 | knowledge recall | problem-solving improvement |
7.2 Full History vs DC
| 방법 | 문제 |
|---|---|
| Full history | context explosion |
| DC | compressed knowledge |
8. 성능이 좋아지는 이유 (Mechanism)
핵심 메커니즘
(1) Error correction loop
- 틀린 전략 → 제거
(2) Strategy reuse
- 반복 task → 동일 해결법 적용
(3) Tool discovery
- 한번 발견 → 계속 사용
핵심 insight
DC는 “search amortization”을 수행
- 초기 비용: 전략 발견
- 이후: reuse
9. 복잡도 분석
시간 복잡도
- 각 step:
- Gen: O(LLM)
- Cur: O(LLM)
- Retr: O(log N) (vector DB)
전체:
메모리 복잡도
- naive: O(T)
- DC: O(K) (압축됨)
10. 방법론 핵심 요약
핵심 3줄
- LLM이 inference 중 memory를 축적
- memory는 전략 단위로 압축 저장
- retrieval + curation으로 지속 개선
11. 연구적으로 중요한 포인트
이 방법론을 한 줄로 정리하면:
“parameter-free online meta-learning”
답글 남기기