[태그:] Neuron
-

*** Constructing Interpretable Features from Compositional Neuron Groups (ArXiv 2025)
이 논문은 최근 SAE(Sparse Autoencoder) 중심의 mechanistic interpretability 연구에 대해 상당히 흥미로운 문제 제기를 합니다. 핵심 질문은: “LLM 내부의 의미(concept)를 표현하는 진짜 단위(unit)는 무엇인가?” 입니다. 기존에는 등이 주로 사용되었는데, 저자들은 “실제로는 여러 neuron들이 조합(composition)되어 하나의 개념을 표현한다” 고 주장하며, MLP activation을 SNMF(Semi-Nonnegative Matrix Factorization)로 분해하여 neuron group 기반 feature를 찾는 방법을 제안합니다. 1. 논문의…
-

* Finding Neurons in a Haystack: Case Studies with Sparse Probing (ArXiv 2023)
이 논문은 **“LLM 내부에서 특정 개념(feature)이 몇 개의 뉴런에 의해 표현되는가?”**를 체계적으로 분석한 연구이다. 특히 기존 probing 연구를 확장하여 Sparse Probe를 사용함으로써 특정 feature와 관련된 뉴런을 매우 정밀하게 찾고, 이를 통해 monosemantic neuron, polysemantic neuron, superposition 현상을 실증적으로 분석한다. 1. 연구 배경 Mechanistic Interpretability 분야에서는 오래전부터 다음 질문이 존재했다. “특정 뉴런 하나가 하나의 의미(feature)를…
-

* On Relation-Specific Neurons in Large Language Models (EMNLP 2025)
이 논문은 **“LLM 내부에 특정 사실(fact)을 저장하는 neuron이 아니라, 특정 관계(relation) 자체를 처리하는 neuron이 존재하는가?”**를 분석한 연구입니다. 기존 연구의 Knowledge Neuron은 (NVIDIA, CEO, Jensen Huang) 이라는 사실 전체를 저장하는 뉴런을 찾으려 했습니다. 반면 이 논문은 CEO 관계 자체를 담당하는 neuron 즉, 처럼 entity가 달라도 공통적으로 활성화되는 Relation-Specific Neuron (RelSpec Neuron) 이 존재하는지를 탐구합니다. …
-

** Neuron-Level Knowledge Attribution in Large Language Models (EMNLP 2024)
아래는 EMNLP 2024 논문 “Neuron-Level Knowledge Attribution in Large Language Models” 의 핵심 내용을 정리한 설명입니다. 논문 개요 이 논문은 LLM 내부에서 특정 지식(facts)이 어떤 뉴런(neuron)에 저장되는지 정량적으로 찾아내는 뉴런 수준(neuron-level) attribution 방법을 제안합니다. 피쳐 단위(head, layer)보다 더 미세한 수준입니다. 기존 기법은 논문은 이를 해결하기 위해: 을 수행합니다. 배경 (왜 뉴런 수준인가?) 이전 연구들(Geva et…
-

* Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering (ArXiv 2024)
논문 “Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering” (Pochinkov et al., 2024) 은 Transformer 기반 모델의 주의(attention) 뉴런 해석과 절제(ablation) 방법을 체계적으로 비교하고, 새로운 방식인 **Peak Ablation (정점 중심 절제)**을 제안한 연구입니다. 아래에 핵심 내용을 구조적으로 정리했습니다. 1. 연구 배경 및 문제의식 기존 절제 방식: 2. 제안 개념: Peak Ablation…
-
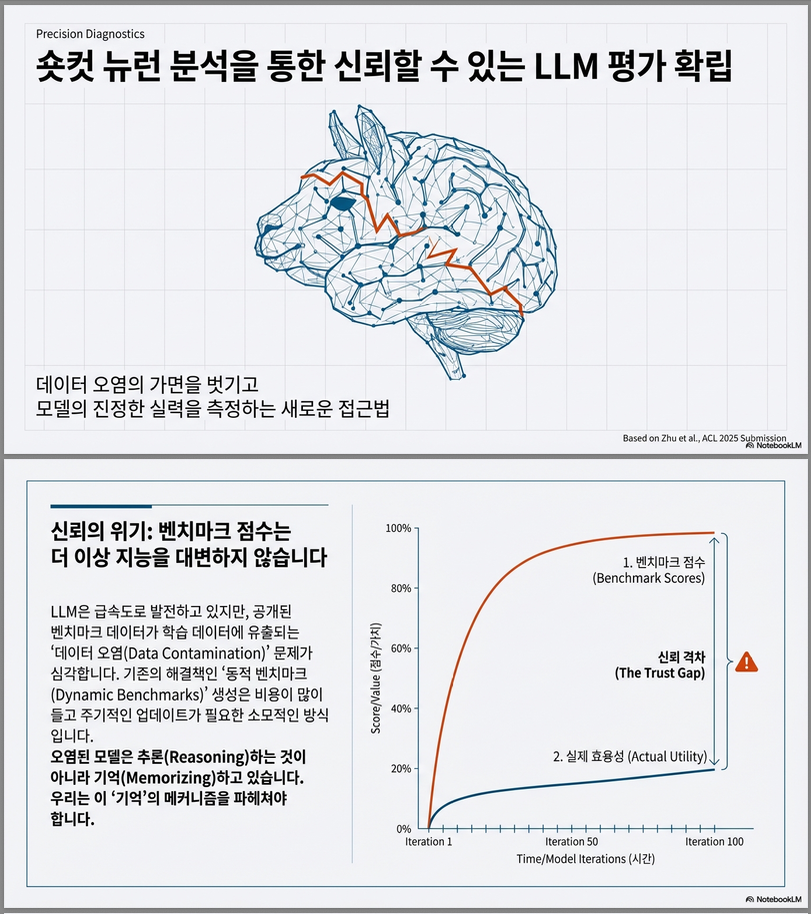
*** Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis (ACL 2025)
논문 “Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis” (ACL 2025) 은 데이터 오염(data contamination) 문제로 인해 LLM 평가의 신뢰성이 손상되는 문제를 해결하기 위해, 모델 내부의 “지름길 뉴런(shortcut neurons)”을 분석하고 억제함으로써 공정하고 신뢰할 수 있는 평가를 수행하는 방법을 제안한 연구입니다. 아래는 주요 내용 요약입니다. 연구 배경 및 문제의식 따라서 이 논문은 모델 내부의 원인, 즉…
-

** MicroEdit: Neuron-level Knowledge Disentanglement and Localization in Lifelong Model Editing (EMNLP 2025)
논문 “MicroEdit: Neuron-level Knowledge Disentanglement and Localization in Lifelong Model Editing” (EMNLP 2025) 은 대형 언어모델(LLM)의 지속적인 지식 편집(lifelong model editing) 문제를 다루며, 기존 방법들이 가지는 두 가지 핵심 한계를 정량적으로 분석하고, 이를 해결하기 위해 Sparse Autoencoder(SAE) 기반의 뉴런 단위 최소 편집(neuron-level minimal editing) 기법을 제안합니다 . 1. 연구 배경 및 문제점 LLM은 대규모 사전학습…
-
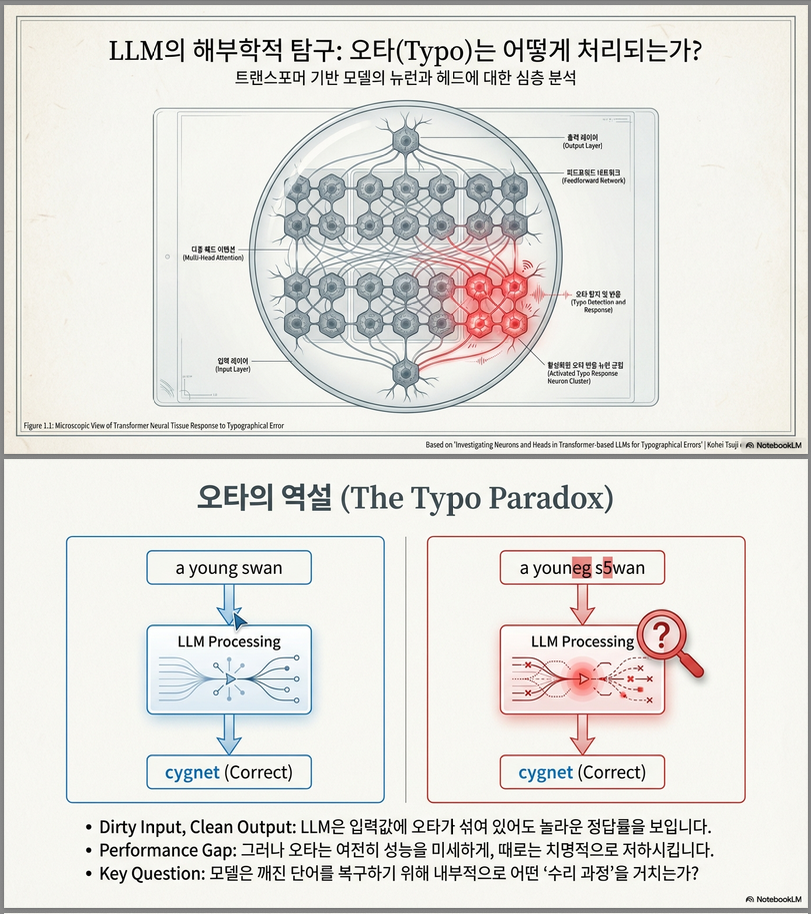
*** Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors (EMNLP 2025)
다음은 **EMNLP 2025 논문 “Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors”**에 대한 핵심 정리입니다. 연구 동기 LLM 입력에는 종종 **오타(typo)**가 포함되며, 모델은 때때로 이를 내부적으로 보정해 올바른 의미를 복원합니다. 그러나 경우에 따라 오타는 모델의 성능 저하를 유발합니다. 이 연구는: 어떤 뉴런(neurons)과 어떤 어텐션 헤드(attention heads)가 오타를 감지·보정하는지 밝혀내는 것이 목표입니다. 주요 연구…
-

*** Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis (EMNLP 2025)
논문 “Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis” (EMNLP 2025) 은 LLM의 연쇄적 사고(Chain-of-Thought, CoT) 능력을 뉴런 수준에서 해석하고 향상시키는 방법을 제안한 연구입니다. 아래는 핵심 내용을 정리한 설명입니다. 연구 배경 제안 방법 1. 대비 데이터셋(Contrastive Dataset) 구축 2. 뉴런 활성도 차이 계산 3. 핵심(reasoning-critical) 뉴런 선택 4. 뉴런 개입(Intervention) 주요 결과 모델 평균 성능…
-

** Small Changes, Big Impact: How Manipulating a Few Neurons Can Drastically Alter LLM Aggression (ACL 2025)
이 논문 “Small Changes, Big Impact: How Manipulating a Few Neurons Can Drastically Alter LLM Aggression” (ACL 2025) 은 대형 언어 모델(LLM) 내부의 “공격성(neural aggression)”을 제어하는 특정 뉴런이 존재하며, 이들을 조작하는 것만으로도 모델의 공격성이 급격히 변할 수 있음을 실험적으로 증명한 연구입니다 . 아래는 핵심 내용을 정리한 설명입니다. 🧩 1. 연구 목적과 문제의식 🔍 2. 연구…
-

*** Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models (ACL 2024)
이 논문 **「Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models」 (ACL 2024)**은 대형 언어 모델(LLM)의 다국어 능력이 **특정한 언어 전용 뉴런(language-specific neurons)**에 의해 어떻게 형성되는지를 정량적으로 규명한 연구입니다 . 🧩 연구 배경 및 문제의식 대형 언어 모델(GPT-4, PaLM-2 등)은 주로 영어 데이터로 학습되었음에도 불구하고 여러 언어로 높은 수준의 이해 및 생성 능력을…