



이 논문은 “LLM이 자신의 답이 틀렸다는 것을 스스로 예측할 수 있는가?”라는 질문을 다룹니다. 핵심 아이디어는 텍스트나 외부 judge 모델이 아니라 LLM 내부 activation(숨겨진 상태와 attention)에서 직접 오류 신호를 읽어내는 것입니다.
아래에서 연구 문제 → 핵심 아이디어 → 방법론(Gnosis) → 실험 결과 → 연구적 의미 순서로 정리합니다.
1. 연구 문제 (Problem)
LLM의 대표적인 문제:
- hallucination
- reasoning error
- confident but wrong answer
하지만 LLM은 자신의 오류를 잘 인식하지 못함.
기존 해결 방법:
(1) Self-critique
LLM이 자기 답을 다시 평가
예:
Answer: ...
Confidence: ...문제
→ 언어적 스타일을 평가할 뿐 reasoning correctness와 약하게 연관
(2) Self-consistency
여러 번 생성 후 voting
문제
- inference cost ↑
- long reasoning에서 비용 매우 큼
(3) External judge model
Reward model / judge LLM
예
- GPT judge
- reward model
문제
- 별도 모델 필요
- latency 증가
- annotation cost
논문의 질문:
정답 여부 신호가 이미 LLM 내부에 존재하는가?
(hidden states / attention patterns)
즉, LLM 내부 circuit을 읽어 correctness를 예측
2. 핵심 아이디어
논문에서 제안한 방법:
Gnosis
LLM 내부 상태를 이용한
self-awareness mechanism
특징:
- backbone LLM freeze
- 내부 signal만 사용
- 5M parameters만 추가
- sequence length와 무관한 비용
구조 개요:
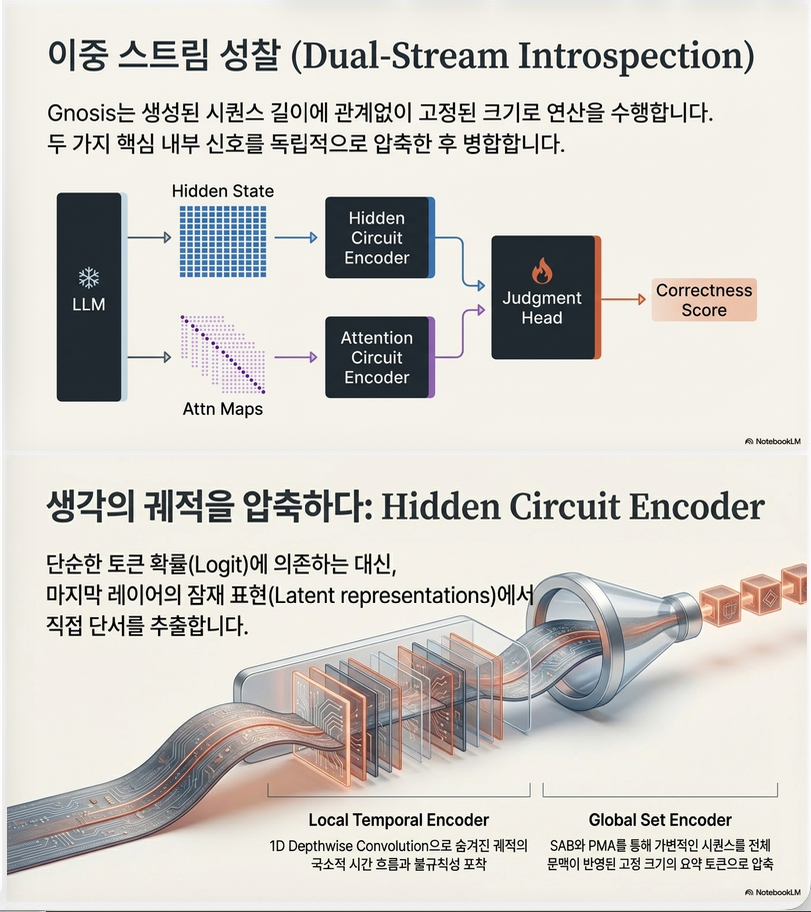
Prompt → LLM → Response
LLM 내부:
hidden states
attention maps
↓
Gnosis
hidden circuit encoder
attention circuit encoder
↓
correctness score (0~1)즉, LLM internal traces → correctness prediction
3. 문제 정의
입력:
prompt x
generated answer ysequence length
S = Sx + SyLLM에서 추출:
Hidden states
Attention maps
Gnosis는 다음 함수 학습:
p̂ = f(H_last , A)출력:
p̂ ∈ [0,1]의미:
p̂ = answer correctness probability4. Length-Invariant Representation
LLM sequence는 길이가 다양함.
문제:
attention: S × S→ 매우 큼
그래서 fixed-budget compression 사용.
(1) Hidden state compression
H_last ∈ R^(S×D)↓
adaptive pooling
H̃ ∈ R^(K_hid × D)예: K_hid = 192
즉, sequence → fixed tokens
(2) Attention map compression
각 attention map
A_(l,h) ∈ R^(S×S)↓
downsampling
Ã_(l,h) ∈ R^(k × k)예: k = 256
이렇게 하면, compute ⟂ sequence length
5. Hidden Circuit Encoder
목적:
hidden trajectory → correctness signal단계:
Step 1: Local temporal encoding
multi-scale convolution
Conv1D
dilated conv
SE block목적:
- reasoning trajectory irregularity 탐지
- hidden dynamics capture
Step 2: Global set encoder
Set Transformer
구조:
SAB (Set Attention Block)
→ PMA (Pooling Multihead Attention)출력
z_hid ∈ R^(D_hid)6. Attention Circuit Encoder
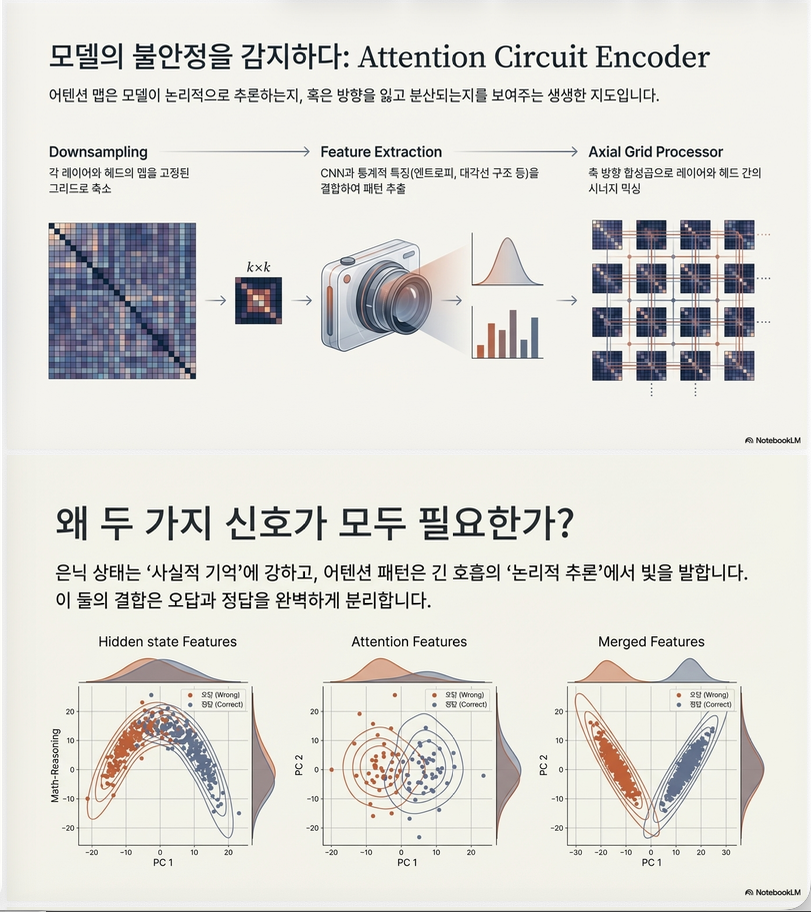
attention map은 reasoning 구조 정보를 포함.
예:
- reasoning 집중
- attention diffusion
- instability
각 attention map:
Ã_(l,h)에서 feature 추출.
(1) CNN features
attention map을 image로 처리
CNN(Ã)→ visual patterns
(2) statistics features
해석 가능한 feature
예:
entropy
attention 분산
spectral entropy
frequency pattern
diagonal mass
local reasoning 여부
center / spread
attention 위치
각 head feature
v_(l,h) ∈ R^(d_grid)(3) layer-head grid encoding
features arrange:
G ∈ R^(L × H × d_grid)processing:
Axial Convolution목적:
- head interaction
- layer interaction
마지막 pooling
PMA출력
z_attn ∈ R^(D_attn)7. Feature Fusion
두 representation 결합
z = [z_hid ; z_attn]prediction
p̂ = sigmoid(MLP(z))MLP는 gated 구조.
의미:
모델이 상황에 따라
hidden signal
vs
attention signal가중치 조절.
8. Training
dataset 생성:
(1) LLM으로 answer 생성
(2) 정답과 비교
(3) label 생성
y = 1 (correct)
y = 0 (wrong)학습 objective
Binary cross entropy중요:
LLM backbone freeze학습되는 것은
Gnosis head (~5M params)뿐.9. 실험 설정
Backbone LLM:
- Qwen3 1.7B
- Qwen3 4B
- Qwen3 8B
- GPT-OSS-20B
평가 데이터:
Math reasoning
- AMC12
- AIME
- HMMT
QA
- TriviaQA
Knowledge
- MMLU-Pro
평가 metric
- AUROC
- AUPR
- Brier score
- ECE (calibration)
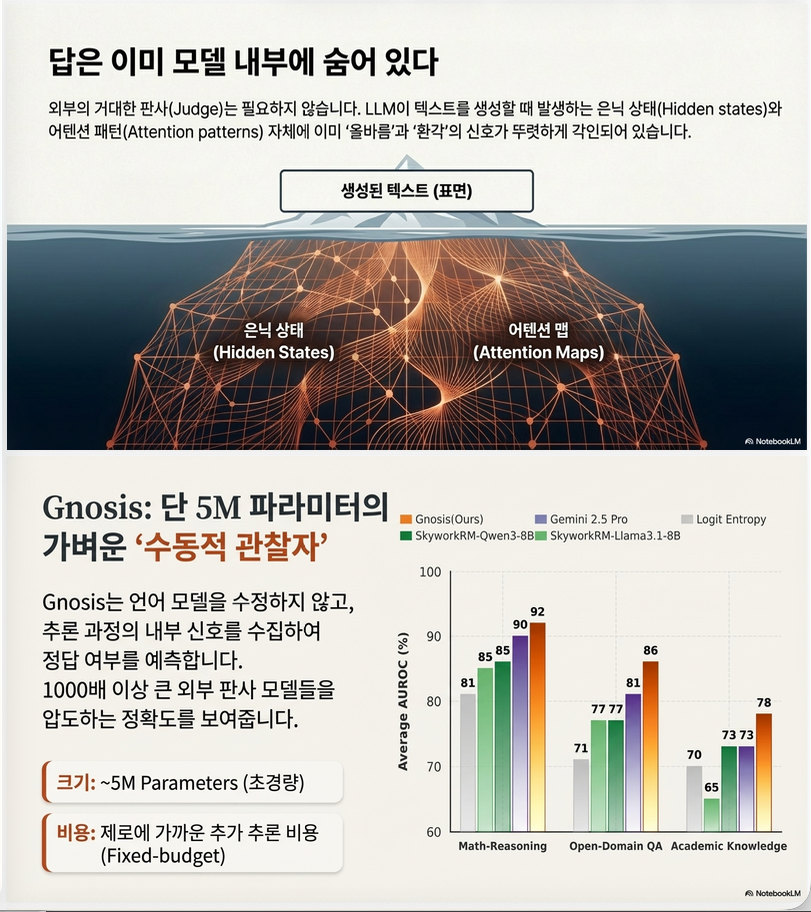
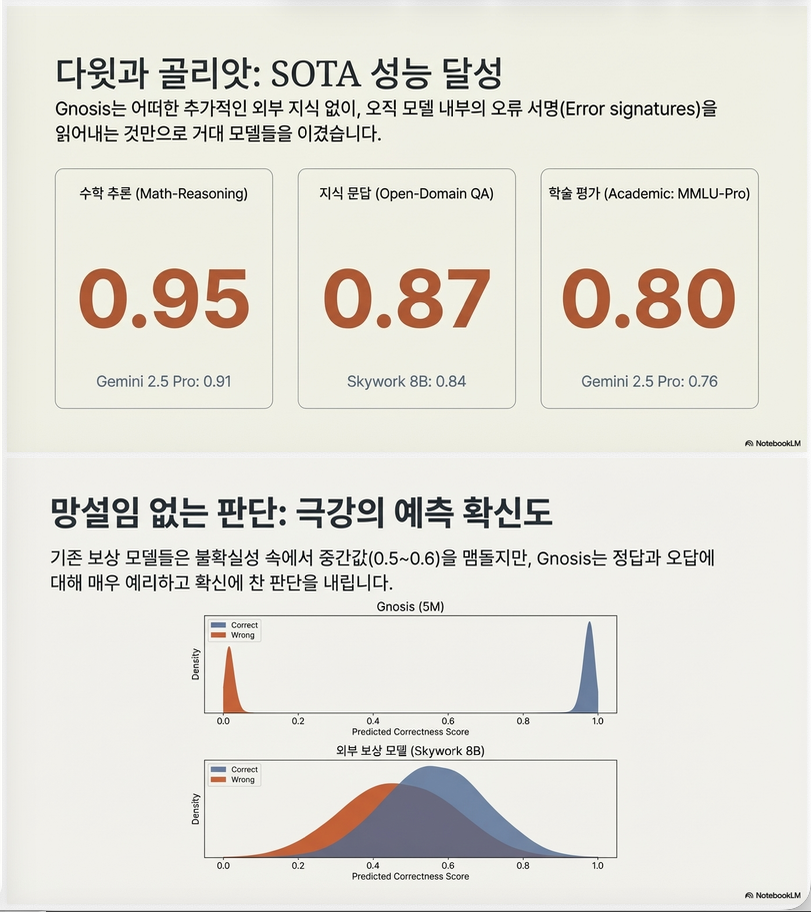
10. 주요 실험 결과
성능
예: Math reasoning
AUROC
| Method | AUROC |
|---|---|
| Logit entropy | ~0.79 |
| Reward model | ~0.90 |
| Gemini judge | ~0.91 |
| Gnosis | ~0.95 |
즉, external judge보다 정확.
모델 크기 비교
Reward model: 8B
Gnosis: 5M즉, 1000x smaller
latency
24k token generation
| Method | latency |
|---|---|
| Reward model | 2465 ms |
| Gnosis | 25 ms |
≈ 100x faster
11. Early Error Detection
핵심 발견:
Gnosis는 partial generation만 보고도 오류 예측 가능.
예:
40% generation만 봐도→ full answer와 거의 동일한 accuracy.
의미:
- early stopping
- compute saving
12. Cross-Scale Transfer
흥미로운 결과:
1.7B 모델로 학습한 Gnosis↓
4B / 8B 모델 평가에서도 잘 동작.즉, hallucination signature는 model scale invariant
13. Hidden vs Attention 분석
성능 기여:
| Signal | 역할 |
|---|---|
| Hidden states | general reliability |
| Attention | reasoning structure |
| Fusion | best |
특히
reasoning tasks → attention 중요
fact QA → hidden 중요14. 연구의 핵심 의미
이 논문의 중요한 메시지:
LLM이 틀릴 때의 신호는 이미 내부 activation에 존재한다
즉, Correctness signal ∈ LLM internal circuits
external judge가 꼭 필요하지 않음.
15. 논문의 한계
저자도 인정한 한계:
(1) universal judge 아님
family transfer는 가능하지만
Qwen → LLaMA 같은 transfer는 제한적.(2) correctness detection만 가능
왜 틀렸는지 설명하지는 못함.16. 핵심 요약
이 논문의 한 줄 요약:
LLM 내부 hidden state와 attention circuit을 읽으면, LLM이 틀릴지 맞을지 매우 정확하게 예측할 수 있다.
특징:
- external judge 불필요
- 5M parameter
- latency 거의 없음
- early failure detection 가능
논문의 **방법론(Method)**은 LLM의 **hidden states와 attention circuits에서 correctness 신호를 추출해 오류 가능성을 예측하는 lightweight verifier “Gnosis”**를 설계하는 것이다. 아래에서는 핵심 구성요소만 정리한다.
1. 문제 설정
입력:
- prompt x
- LLM이 생성한 응답
전체 시퀀스 길이
LLM 내부에서 다음 두 가지 신호를 읽는다.
- final-layer hidden states
- attention maps
목표:
여기서
- : 답이 correct일 확률
- : Gnosis verifier
중요한 제약:
- LLM backbone은 frozen
- correctness prediction만 학습
2. Length-Invariant Representation
hidden state와 attention은 시퀀스 길이에 따라 커진다.
그래서 논문은 fixed-budget compression을 적용한다.
Hidden state 압축
방법
- interpolation
- adaptive pooling
즉, variable length → fixed tokens
Attention map 압축
각 attention map
을 로 downsampling.
결과적으로
- 계산량이 sequence length와 무관
3. Hidden-State Circuit Encoder
hidden state trajectory에서 reasoning failure signal을 추출한다.
입력
구성은 두 단계.
(1) Local Temporal Encoder
hidden trajectory를 temporal signal로 처리한다.
사용 모듈
- multi-scale dilated convolution
- channel gating
- squeeze-excitation
목적
- hidden state 변화 패턴 분석
- reasoning instability 포착
(2) Global Set Encoder
sequence 전체 정보를 요약.
구조
- Set Attention Block (SAB)
- Pooling by Multihead Attention (PMA)
출력
즉, hidden trajectory → compact descriptor
4. Attention Circuit Encoder
attention routing 패턴에서 reasoning structure signal을 추출한다.
각 attention map 을 feature vector로 변환한다.
(1) Per-map Feature Extraction
두 가지 방식 사용.
CNN features
attention map을 image처럼 처리
- local patterns
- structure detection
Statistical features
attention distribution 특징.
예
- entropy
- spectral entropy
- diagonal mass
- spatial spread
출력
(2) Layer–Head Grid Encoding
모든 head feature를 grid로 구성.
이 grid를
- axial convolution
으로 처리한다.
목적
- layer interaction
- head interaction
(3) Global Aggregation
마지막으로
PMA pooling을 사용해
생성.
5. Dual-Stream Fusion
두 representation 결합.
이후
Gated MLP로 correctness 예측.
Gating의 역할:
- hidden signal
- attention signal
가중치를 상황별로 조절.
6. Training
학습 데이터 생성 과정:
- LLM으로 답 생성
- 정답과 비교
- correct / incorrect label 생성
데이터:
여기서
loss
학습되는 것은
- hidden encoder
- attention encoder
- fusion head
뿐이다.
7. 핵심 특징 (방법론 관점)
Gnosis 방법론의 핵심 설계 원칙:
(1) Trajectory-level introspection
final token이 아니라, generation trajectory 전체 사용
(2) Dual-circuit modeling
두 종류 circuit 사용
- hidden dynamics
- attention routing
(3) Length-invariant computation
압축을 통해
cost ⟂ sequence length(4) Lightweight verifier
추가 파라미터
≈ 5M8. 방법론 한 줄 정리
Gnosis는
LLM hidden trajectory + attention routing pattern을 compact representation으로 인코딩하여 correctness probability를 예측하는 dual-stream verifier이다.
답글 남기기