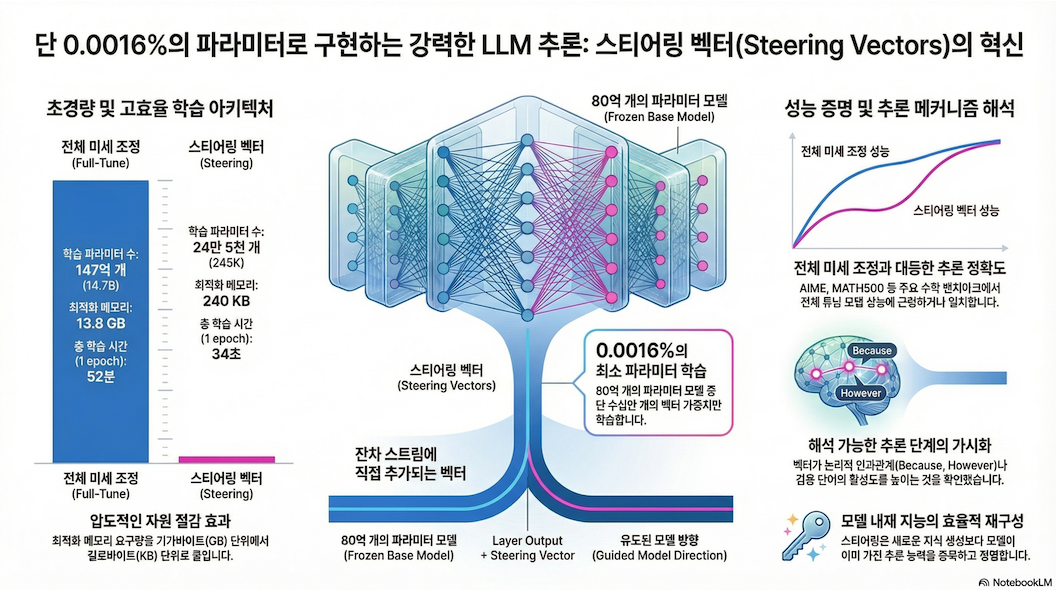
1. 핵심 아이디어 (TL;DR)
이 논문의 핵심은 매우 명확합니다:
“LLM의 reasoning 능력은 매우 적은 파라미터 (layer별 vector)만 학습해도 충분히 끌어낼 수 있다.”
- 전체 파라미터를 업데이트할 필요 없음
- 각 layer마다 단 하나의 vector만 학습
- 전체 파라미터의 0.0016%만 사용
- 그런데도 full RL fine-tuning과 거의 동일한 성능
즉,
reasoning은 “새로 학습되는 능력”이 아니라
이미 존재하는 능력을 특정 방향으로 “증폭(amplify)”하는 것이라는 강한 근거 제공
2. 방법론 (Methodology)
2.1 Steering Vector 정의
각 transformer layer ℓ에 대해:
- hidden state:
- steering vector:
다음과 같이 단순히 더함:
✔ 특징:
- 모든 token에 동일하게 적용 (position-independent)
- 모든 기존 weight는 freeze
- 학습되는 것은 오직
총 파라미터 수:
2.2 구현 관점
논문 코드 핵심:
class SteeringVector(nn.Module):
def __init__(self, hidden_size):
self.steering_vector = nn.Parameter(...)
def forward(self, x):
return x + self.steering_vector→ Transformer layer output 뒤에 bias처럼 더하는 구조
사실상:
- BitFit의 extreme 버전
- Activation engineering + parameter learning
2.3 학습 방식 (RL)
DeepSeek-R1 스타일 RL:
Step 1: 샘플링
Step 2: reward
- 정답이 \boxed{} 안에 있으면 1, 아니면 0
Step 3: Advantage 계산
Step 4: Policy Gradient
중요한 점:
- θ는 steering vector만 포함
- base model은 완전히 frozen
3. 결과 (핵심 실험 결과)
3.1 성능 비교
결론:
Steering ≈ Full Fine-tuning
예시 (Qwen2.5-7B):
| 모델 | Avg |
|---|---|
| Base | 24.2 |
| Steering | 36.4 |
| Full-tune | 37.1 |
–> 거의 동일
3.2 비용 절감
| 항목 | Full-Tune | Steering |
|---|---|---|
| 파라미터 | 14.7B | 245K |
| Optimizer memory | 13.8GB | 240KB |
| Step time | 9.94s | 0.11s |
–> 압도적 효율성
4. 해석 (Interpretability)
4.1 Logit Lens 분석
각 token v에 대해:
- : token embedding 방향
- 의미:
- 값 ↑ → 해당 token 방향으로 bias
- 값 ↓ → suppression
4.2 발견된 패턴 (중요)
Layer별 역할:
(1) 초기 layer
- programming tokens
- named entities
–> 구조적 reasoning 준비
(2) 중간 layer
- correctness, validation
–> reasoning step 검증
(3) 마지막 layer
- because, therefore, however
–> reasoning 연결
매우 중요한 해석:
reasoning은 특정 layer별로 기능적으로 분리된 circuit로 존재
5. 중요한 해석 (논문의 Implication)
5.1 핵심 주장
Steering vector는 새로운 능력을 만들지 않는다
→ 기존 latent capability를 증폭한다
5.2 증거
- base model이 이미 능력이 있을 때: → steering ≈ full-tune
- 능력이 부족할 때: → steering < full-tune
즉:
5.3 LoRA와 비교
| 방법 | 특징 |
|---|---|
| Steering | global vector |
| LoRA | token-dependent |
결과:
- LoRA가 gap을 항상 메움
- 이유: → 더 fine-grained control 가능
6. 한계
논문에서 명시:
- token-independent vector → 표현력 제한
- logit lens 한계 → downstream effect 반영 못함
- reasoning task 편중 → generalization 불명확
7. 한 줄 요약
Reasoning 능력은 학습되는 것이 아니라, 이미 존재하는 circuit을 steering으로 증폭하는 것이다.
논문의 **방법론(Methodology)**을 수식 중심으로 정리합니다.
1. 전체 구조 개요
이 논문의 방법론은 다음 3가지 요소로 구성됩니다:
- Layer-wise steering vector 삽입
- Base model freeze
- RL 기반 학습 (RLOO)
2. Steering Vector 설계
2.1 기본 정의
Transformer의 각 layer ℓ에서:
- hidden state:
- steering vector:
2.2 Forward 과정
각 token t에 대해:
✔ 특징:
- token-independent (모든 token에 동일)
- layer-specific
- residual stream에 직접 추가
즉:
global bias를 layer마다 주입하는 구조
2.3 전체 모델 동작
Transformer forward를 쓰면:
→ 모든 layer에서 additive perturbation 발생
3. 학습 대상 파라미터
전체 모델 파라미터 θ를 분리하면:
- : freeze
- : trainable
파라미터 수
#params =
예:
- L=32, d=4096 → 약 131K
논문:
전체의 약 0.0016%
4. 학습 알고리즘 (RL)
4.1 샘플링
입력 x에 대해:
- temperature τ = 1
- N rollouts
4.2 reward 정의
r(x, y_i) = \begin{cases} 1 & \text{정답이 \boxed{} 안에 있음} \\ 0 & \text{otherwise} \end{cases}
–> 매우 sparse reward
4.3 baseline (variance reduction)
4.4 Policy Gradient (RLOO)
✔ 여기서 중요한 점:
- gradient는 오직 steering vector로만 흐름
- base model은 완전히 고정
5. 왜 이게 동작하는가? (Mechanistic 해석)
논문의 implicit assumption:
Steering vector는 새로운 feature를 생성하지 않고
이미 존재하는 representation을 특정 방향으로 이동시킨다
수식적 해석
hidden state를 feature basis로 보면:
steering 적용:
h’ = h + s
→ 결과:
즉:
특정 feature 방향을 amplify / suppress
6. Logit Lens 기반 해석
각 token v에 대해:
- : unembedding vector
의미:
- : token v를 더 생성하도록 bias
- : 억제
7. LoRA 확장 (논문 Appendix D)
7.1 문제점
기본 steering:
h’ = h + s
–> token-independent → 표현력 부족
7.2 LoRA 기반 steering
특징:
- token-dependent
- low-rank adaptation
비교
| 방법 | 표현력 |
|---|---|
| Steering | global shift |
| LoRA | input-dependent shift |
8. 전체 알고리즘 정리
Algorithm
for each batch:
for each input x:
sample y1,...,yN ~ πθ
compute reward r_i
compute baseline b
compute advantage a_i = r_i - b
update steering vectors:
∇θ J = E[a_i ∇ log π(y_i|x)]9. 핵심 설계 요약
Design Principles
(1) Minimal Intervention
- 단 하나의 vector per layer
(2) Activation-level control
- weight 수정 없음
(3) RL-driven alignment
- reasoning behavior 유도
10. 한 줄 핵심
Layer-wise additive vector + RL만으로 reasoning을 유도할 수 있다.
논문의 **실험 결과(Results)**를 핵심 지표 중심으로 정리합니다. (성능 / 효율 / 해석 / 추가 실험까지)
1. 핵심 결과 요약
Steering-only 학습 ≈ Full fine-tuning 성능
- 대부분 모델/벤치마크에서 동일 수준
- 일부 경우 오히려 더 높은 성능
- 단, base capability가 부족한 경우에는 gap 존재
2. 메인 벤치마크 결과 (Table 1)
2.1 실험 설정
- 모델:
- Qwen2.5 (1.5B / 7B / 14B)
- Qwen2.5-Math
- LLaMA3.1-8B
- 벤치마크:
- AIME24/25
- AMC23
- MATH500
- MinervaMath
- OlympiadBench
2.2 대표 결과
(1) Qwen2.5-7B
| 모델 | Avg |
|---|---|
| Base | 24.2 |
| Steering | 36.4 |
| Full-tune | 37.1 |
–> Steering ≈ Full-tune
(2) Qwen2.5-14B
| 모델 | Avg |
|---|---|
| Base | 26.1 |
| Steering | 42.3 |
| Full-tune | 41.3 |
–> Steering > Full-tune
(3) Qwen2.5-Math-7B
| 모델 | Avg |
|---|---|
| Base | 24.8 |
| Steering | 43.3 |
| Full-tune | 43.5 |
–> 거의 동일
(4) LLaMA3.1-8B
| 모델 | Avg |
|---|---|
| Base | 3.9 |
| Steering | 9.1 |
| Full-tune | 11.5 |
–> 약 70% 수준만 회복
2.3 핵심 관찰
✔ Observation 1
대부분 경우:
✔ Observation 2
일부 경우:
이유:
- base model에 reasoning capability 부족
✔ Observation 3
일부 경우:
해석:
- implicit regularization 효과
3. 데이터셋 교차 실험 (Table 4)
3.1 GSM8K → GSM8K
| 모델 | Full | Steering |
|---|---|---|
| Qwen2.5-1.5B | 78.9 | 73.8 |
| Qwen2.5-Math | 86.5 | 79.9 |
| LLaMA3.1 | 76.5 | 70.4 |
–> 항상 약간 낮음 (56%)
3.2 GSM8K → MATH (generalization)
| 모델 | Full | Steering |
|---|---|---|
| Qwen2.5-1.5B | 40.8 | 48.7 |
| LLaMA3.1 | 16.9 | 22.8 |
–> Steering이 더 좋음
3.3 MATH → MATH
| 모델 | Full | Steering |
|---|---|---|
| Qwen2.5-1.5B | 44.5 | 51.4 |
–> 다시 Steering > Full
3.4 핵심 해석
✔ In-domain
- Steering slightly worse
✔ Out-of-domain
- Steering often better
이유:
parameter 적음 → overfitting 감소 → generalization 향상
4. LoRA 비교 실험
결과:
LoRA는 항상 Full-tune 수준까지 도달
예시
| 방법 | 성능 |
|---|---|
| Steering | 약간 낮음 |
| LoRA | 거의 동일 |
| Full-tune | 기준 |
해석
- Steering:
- global shift → coarse control
- LoRA:
- token-dependent → fine-grained control
따라서:
5. 효율성 결과 (Table 3, 5)
Qwen2.5-14B 기준
| 항목 | Full | Steering |
|---|---|---|
| 파라미터 | 14.7B | 245K |
| Optimizer memory | 13.8GB | 240KB |
| Step time | 9.94s | 0.11s |
| 총 학습 시간 | 52분 | 거의 없음 |
–> 약 100~1000배 효율 개선
핵심 메시지
거의 동일 성능 + 극단적 비용 절감
6. 해석 결과 (Interpretability)
6.1 Layer별 역할
논문에서 발견:
Layer 2
- programming tokens
- named entities
–> 문제 구조 파싱
Layer 17
- correctness, validation
–> reasoning 검증 단계
Layer 30
- because, therefore, however
–> reasoning 연결
6.2 핵심 insight
reasoning은 layer-wise로 분리된 기능 구조를 가짐
7. 종합 결론
7.1 가장 중요한 결과
(1) 성능
(2) 비용
(3) 해석
reasoning = latent feature amplification
7.2 논문이 주장하는 바
“Reasoning training does not create new abilities
but amplifies existing ones.”
8. 한 줄 정리
극소수의 layer-wise vector만으로 full RL reasoning 성능을 재현할 수 있다.
답글 남기기