

다음 논문은 최근 LLM 연구에서 매우 중요한 흐름인 **“Context Engineering”**을 체계적으로 정리한 대규모 survey입니다.
1. 핵심 개념 (Paper Summary)
이 논문의 핵심 메시지는 다음 한 줄로 요약됩니다:
LLM 성능은 “모델 파라미터”보다 “컨텍스트 설계”에 의해 결정된다.
기존:
- Prompt engineering = 단일 문자열 최적화
제안:
- Context engineering = 정보 흐름(system-level) 최적화
2. Context Engineering의 정의 (수식 기반)
논문은 CE를 명확하게 최적화 문제로 formalization 합니다.
(1) 기본 LLM 모델
(2) Context 재정의
기존:
- C = prompt
논문:
즉, context는 단일 텍스트가 아니라
–> 다양한 정보 component들의 조합
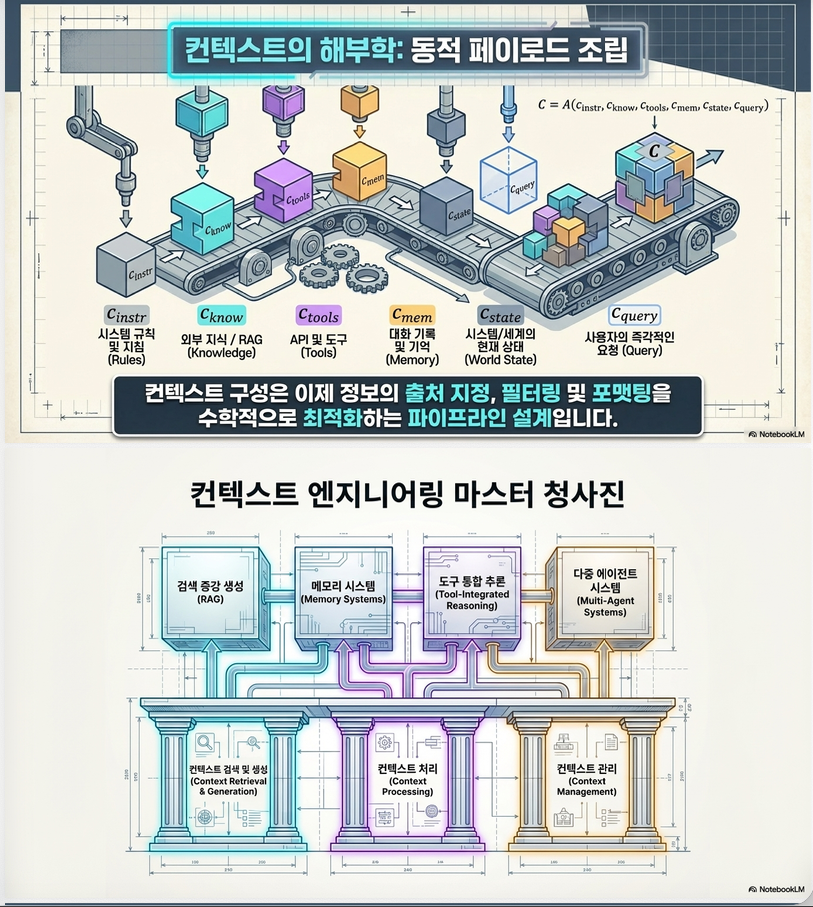
(3) Context 구성 요소 (중요)
논문에서 정의한 핵심 구성:
| Component | 의미 |
|---|---|
| c_{instr} | system prompt / instruction |
| c_{know} | external knowledge (RAG) |
| c_{tools} | tool/function 정의 |
| c_{mem} | memory |
| c_{state} | agent 상태 |
| c_{query} | user input |
핵심 insight:
LLM 입력 = multi-source information fusion pipeline
(4) Optimization Problem
즉:
- 목표 = context 생성 함수 집합 F 최적화
- 구성:
- Retrieve
- Select
- Assemble
기존 prompt engineering과의 본질적 차이:
- prompt → string search
- context → system optimization
3. 전체 프레임워크 (Taxonomy)
논문의 가장 중요한 기여는 전체 구조를 통합 taxonomy로 정리한 것
(A) Foundational Components
(1) Context Retrieval & Generation
- Prompting (CoT, ToT, GoT)
- RAG
- Dynamic context assembly
(2) Context Processing
- Long context 처리 (LongNet, FlashAttention 등)
- Self-refinement (Self-Refine, Reflexion)
- Structured / graph context
(3) Context Management
- Memory (short/long-term)
- Compression
- KV cache 관리
–> 정리:
Retrieve → Process → Manage(B) System Implementations
이 component들이 실제 시스템으로 발전:
(1) RAG systems
- Modular RAG
- Agentic RAG
- GraphRAG
(2) Memory systems
- MemGPT
- A-MEM
- MemoryBank
(3) Tool-integrated reasoning
- ReAct
- Toolformer
- API calling
(4) Multi-agent systems
- AutoGen
- CAMEL
- CrewAI
–> 중요한 관점:
RAG, Agent, Tool use 모두 “context engineering의 특수 사례”
4. 왜 Context Engineering이 필요한가
논문은 3가지 이유를 강조:
(1) LLM 한계
- O(n²) attention → long context bottleneck
- hallucination
- prompt sensitivity
- stateless limitation
(2) 성능 향상
- CoT → reasoning 개선
- RAG → factuality 개선
- Few-shot → generalization 증가
(3) 자원 최적화
- token cost 감소
- context compression
- selective retrieval
5. 핵심 기술 포인트 (연구적으로 중요)
(1) Information-theoretic retrieval
–> retrieval = 단순 similarity가 아니라
–> task-relevant information maximization
(2) Bayesian Context Inference
–> context selection을 probabilistic inference로 해석
(3) Dynamic Orchestration
–> context assembly = pipeline 최적화 문제
6. 논문의 핵심 인사이트 (중요)
Insight 1
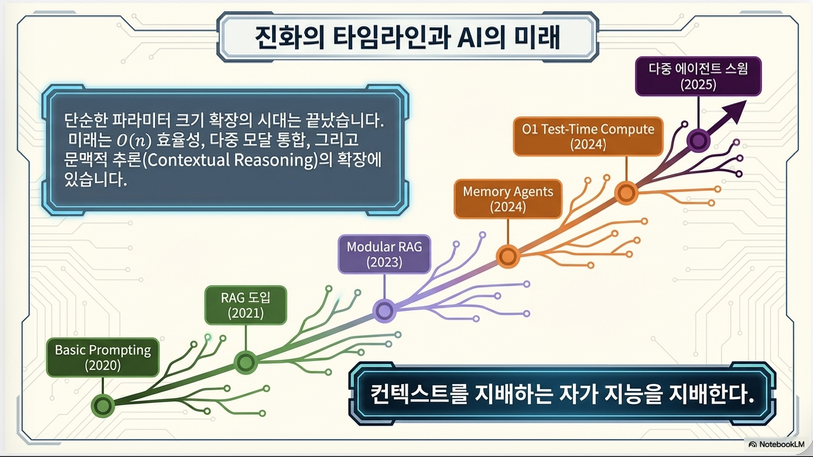
Prompt engineering → Context engineering으로 패러다임 전환
Insight 2
LLM은 “모델”이 아니라 context-driven system
Insight 3
모든 최신 연구 (RAG, Agent, Tool use)는
–> 하나의 unified framework로 설명 가능
Insight 4 (가장 중요한 부분)
논문이 지적한 핵심 research gap:
❗ 모델은 context 이해는 잘하지만
❗ complex long-form generation은 여전히 약함
RAG Systems (핵심 개념)
정의
RAG는 LLM의 parametric knowledge + external knowledge를 결합하여
context를 동적으로 생성하는 시스템이다.
핵심 구조
기본 RAG는 다음과 같은 구조:
Query → Retriever → Documents → Context → LLM → Output수식 관점
의미:
- retrieval 자체가 확률적 latent variable
- output은 retrieved context에 조건부
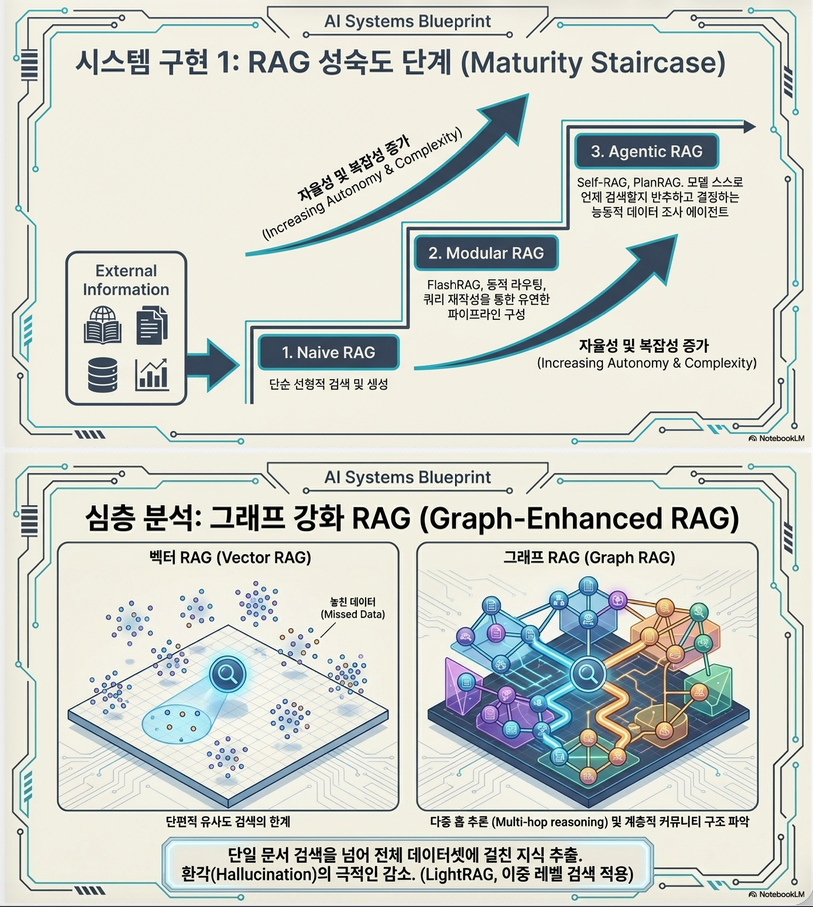
2. RAG의 Evolution (논문의 핵심 포인트)
논문은 RAG를 단순 retrieval에서 다음과 같이 확장합니다:
(1) Classical RAG
- Dense retrieval (DPR)
- BM25 / hybrid
특징:
- static pipeline
- single-shot retrieval
(2) Modular RAG
RAG를 여러 모듈로 분해
구성:
- Retriever
- Reranker
- Generator
- Fusion module
장점:
- plug-and-play
- component-level optimization
(3) Agentic RAG (중요)
Retrieval을 agent가 “결정”하는 구조
구조
Query
↓
Agent (planning)
↓
Retrieve / Reformulate / Iterate
↓
LLM특징
- multi-step retrieval
- query rewriting
- reflection / self-correction
핵심:
retrieval이 decision-making problem으로 변함
(4) Graph-Enhanced RAG
knowledge graph 기반 retrieval
특징
- relational reasoning
- multi-hop retrieval
- structured knowledge 활용
예
Entity → Relation → Entity → Answer(5) Advanced RAG variants
논문에서 언급된 주요 시스템:
- Self-RAG → retrieval 필요 여부를 model이 판단
- RAPTOR → hierarchical document retrieval
- HippoRAG → memory-inspired retrieval
- GraphRAG → KG 기반 reasoning
3. RAG의 핵심 구성 요소
논문 기준으로 RAG는 다음 3단계:
(1) Retrieval
- dense / sparse / hybrid
- semantic similarity
(2) Selection / Filtering
- top-k
- reranking
- diversity selection
(3) Context Assembly
중요한 포인트:
- retrieval보다 assembly가 더 중요
4. RAG의 핵심 문제들
(1) Retrieval mismatch
- semantic similarity ≠ task relevance
(2) Context overload
- 너무 많은 document → noise
(3) Long context bottleneck
- O(n²) attention
(4) Hallucination
- retrieval이 있어도 hallucination 발생
(5) Static pipeline
- 대부분 adaptive하지 않음
5. 논문의 핵심 Insight
Insight 1
RAG는 단순 retrieval이 아니라
–> context generation system
Insight 2
Retrieval quality보다
–> context assembly가 더 중요
Insight 3
미래 RAG는 반드시 agentic 방향
Insight 4
RAG = Memory + Retrieval + Reasoning 통합 구조
6. 최신 연구 방향 (논문 기반)
(1) Adaptive Retrieval
- 필요할 때만 retrieval
- dynamic depth
(2) Multi-hop reasoning
- iterative retrieval
(3) Structured retrieval
- graph-based
(4) Multi-agent RAG
- 여러 agent가 협업
(5) Context optimization
- selection + compression + ordering
8. 핵심 비교 (정리)
| 유형 | 특징 | 한계 |
|---|---|---|
| Classical RAG | 단순 retrieval | 정적 |
| Modular RAG | 구조 분리 | tuning 어려움 |
| Agentic RAG | adaptive | 복잡 |
| Graph RAG | 구조적 reasoning | 비용 높음 |
Agentic RAG (핵심 개념)
정의
Agentic RAG는 retrieval을 정적인 단계가 아니라, agent가 계획·판단·반복 수행하는 과정으로 재구성한 시스템이다.
1. Classical RAG vs Agentic RAG
Classical RAG
Query → Retrieve → Generate- single-shot
- static pipeline
- no feedback
Agentic RAG
Query
↓
Agent (planning)
↓
Retrieve → Evaluate → Refine → Repeat
↓
Generate핵심:
Retrieval이 loop + decision-making problem으로 변함
2. 핵심 구조 (Agent Loop)
표준 Agentic RAG loop
1. Query 이해
2. Retrieval 필요 여부 판단
3. Query reformulation
4. Document retrieval
5. Evidence evaluation
6. 부족하면 반복
7. 최종 generationIterative 구조
–> context가 iterative하게 업데이트됨
3. 핵심 구성 요소
(1) Planner (중요)
- 어떤 정보를 찾아야 하는가?
- 몇 번 retrieval 할 것인가?
(2) Retriever Controller
- 어떤 retriever?
- top-k?
- query rewriting?
(3) Evaluator / Critic
- retrieved doc quality 평가
- hallucination 탐지
(4) Memory
- 이전 retrieval 결과 저장
- reasoning trace 유지
(5) Generator
- 최종 answer 생성
4. 주요 기술 메커니즘
(1) Query Reformulation
Original Query → Sub-queries → Multi-hop retrieval예:
- “Who is the CEO of the company that acquired X?”
→
- X 인수 기업 찾기
- CEO 찾기
(2) Adaptive Retrieval
- 필요할 때만 retrieval 수행
(Self-RAG 스타일)
(3) Multi-step reasoning
- reasoning ↔ retrieval interleaving
(4) Reflection
- 잘못된 retrieval 수정
5. 대표 시스템
논문에서 언급된 흐름:
ReAct 계열
- reasoning + action 결합
Thought → Action → ObservationSelf-RAG
- retrieval 필요 여부 판단
- special token으로 control
RAG-Gym
- RL 기반 retrieval optimization
Agentic RAG frameworks
- AutoGen
- CrewAI
- MetaGPT
6. 핵심 장점
(1) Multi-hop reasoning 가능
- 기존 RAG → 1-step
- Agentic → iterative reasoning
(2) Adaptive retrieval
- 불필요한 retrieval 제거
(3) 오류 수정 가능
- reflection loop
(4) 복잡한 task 처리
- planning 기반
7. 핵심 문제 (매우 중요)
(1) Search explosion
가능한 retrieval sequence ↑↑–> combinatorial explosion
(2) Credit assignment
- 어떤 retrieval이 좋은가?
(3) Cost / latency
- multiple retrieval calls
(4) Stability
- loop divergence
- hallucination amplification
8. 수식적 관점 (중요)
Agentic RAG는 다음과 같이 볼 수 있음:
Sequential decision problem
- state s_t: current context
- action a_t: retrieval / reformulation
최적화 목표
–> RL / Bandit 문제
9. 핵심 Insight
Insight 1
Retrieval은 static step이 아니라
–> sequential decision process
Insight 2
RAG → Agent system으로 진화
Insight 3
Planning + Retrieval + Reasoning 통합 필요
Insight 4 (가장 중요)
Agentic RAG = Context Engineering의 완성형
Graph-Enhanced RAG (핵심 개념)
정의
Graph-Enhanced RAG는 knowledge graph 또는 구조화된 관계 정보를 활용하여
multi-hop reasoning과 정밀한 context 생성을 수행하는 RAG 확장이다.
1. 왜 Graph가 필요한가?
기존 RAG의 한계
Query → Similar Documents → LLM문제:
- 관계 정보 없음
- multi-hop reasoning 어려움
- irrelevant chunk retrieval
Graph RAG의 해결
Query → Entity → Graph traversal → Evidence → LLM핵심:
retrieval = similarity → reasoning over structure
2. 기본 구조
Graph RAG pipeline
1. Query → entity extraction
2. Entity linking
3. Graph traversal (multi-hop)
4. Subgraph selection
5. Context construction
6. LLM generation수식 관점
기존:
Graph RAG:
핵심:
- document → subgraph selection 문제
3. 핵심 구성 요소
(1) Entity Linking
- query → graph node 매핑
예:
- “Apple CEO” → (Apple Inc., Tim Cook)
(2) Graph Traversal (핵심)
방법:
✔ BFS / DFS
- multi-hop 탐색
✔ Path-based reasoning
A → B → C✔ Learned traversal
- neural path selection
(3) Subgraph Selection
- 중요한 부분만 선택
문제:
- graph 전체는 너무 큼
(4) Context Construction
- graph → text 변환 (verbalization)
예:
(A, acquired, B)
→ "A acquired B"4. 주요 방법론
논문에서 언급된 핵심 계열:
(1) Knowledge Graph 기반
- KAPING
- KARPA
- Think-on-Graph
특징:
- semantic + structural reasoning
(2) GraphRAG
- document → graph 변환
- chunk 간 관계 연결
(3) Hybrid Graph + Vector
Dense retrieval + Graph traversal(4) Reasoning-guided Graph Retrieval
- query → reasoning path 생성
- path 기반 retrieval
5. 핵심 장점
(1) Multi-hop reasoning
A → B → C → Answer(2) Explainability
- reasoning path 제공 가능
(3) Noise 감소
- 관계 기반 filtering
(4) Structured knowledge 활용
- KG, DB, ontology
6. 핵심 문제
(1) Graph construction cost
- document → graph 변환 어려움
(2) Traversal explosion
가능한 path 수 ↑↑(3) Error propagation
- 잘못된 node → 전체 reasoning 실패
(4) Text conversion loss
- graph → text 변환 시 정보 손실
7. Agentic RAG와의 결합 (중요)
Graph RAG는 Agentic과 매우 잘 결합됨:
Graph Agent Loop
Query
↓
Agent (planning)
↓
Graph traversal
↓
Evaluate
↓
Refine path
↓
Answer핵심:
- path selection = decision problem
8. 핵심 Insight
Insight 1
Graph RAG는 retrieval을
–> reasoning problem으로 바꿈
Insight 2
document → graph → subgraph 선택
Insight 3
path = explanation
Insight 4 (가장 중요)
Graph RAG는 causal reasoning으로 확장 가능
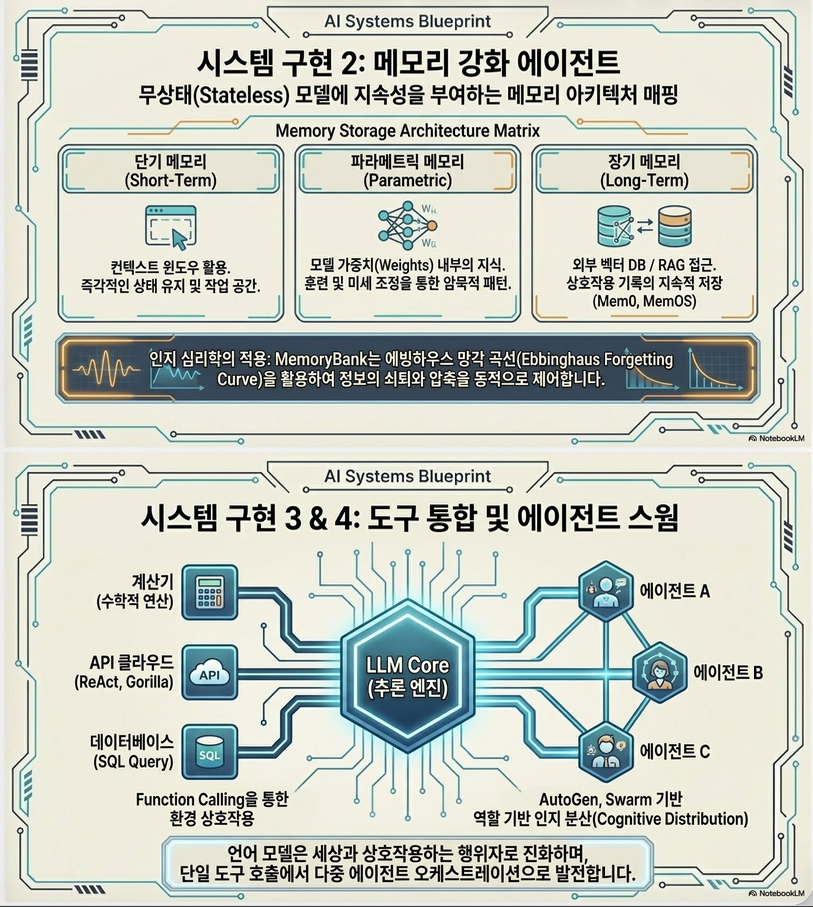
Memory Systems (핵심 개념)
정의
Memory systems는 **과거 정보(cmeme)**를 지속적으로 저장·검색·활용하여
LLM의 context를 확장하는 구조이다.
핵심 역할
Memory는 단순 저장이 아니라:
- state 유지
- long-horizon reasoning 지원
- context window 한계 극복
- agent behavior consistency 유지
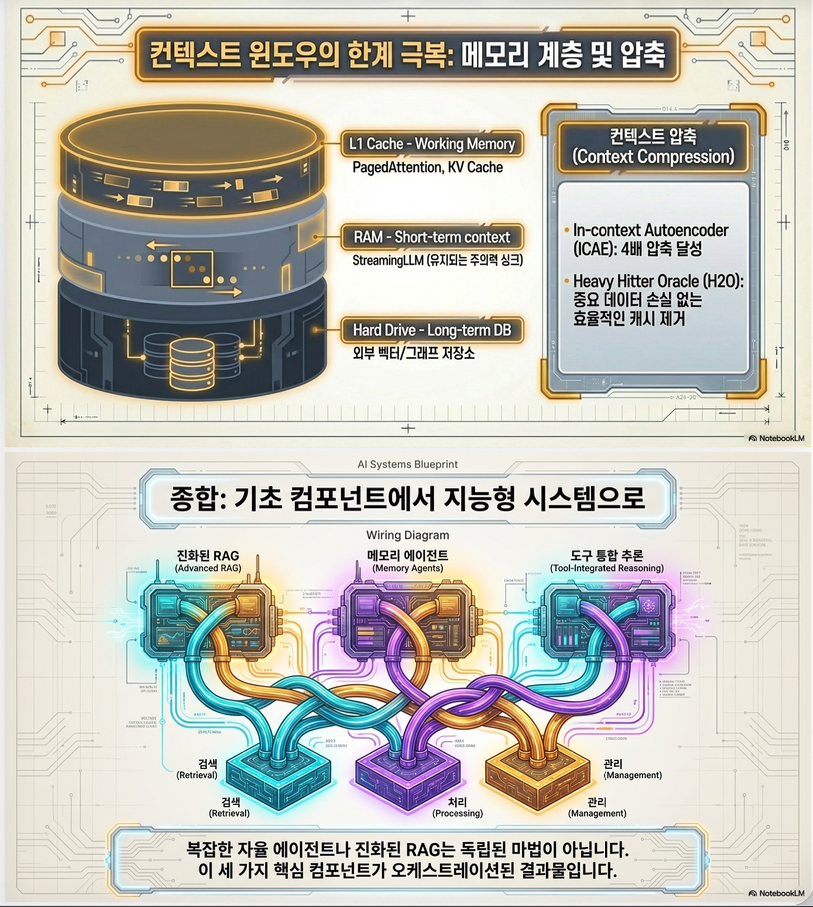
1. Memory 구조 (Architecture)
논문은 memory를 **계층 구조 (hierarchical memory)**로 봅니다.
(1) Short-term Memory (STM)
- 현재 context window
- 최근 대화 / reasoning trace
특징
- 빠름
- 제한된 길이
- 즉각적 reasoning에 사용
(2) Long-term Memory (LTM)
- 외부 저장소 (vector DB, KG 등)
- persistent storage
특징
- 느림 (retrieval 필요)
- 무제한 확장 가능
- knowledge accumulation
(3) Working Memory / Intermediate
- STM ↔ LTM 사이
- reasoning state buffer
핵심 구조
User Query
↓
STM (현재 context)
↓
Retrieve from LTM
↓
Augmented Context
↓
LLM2. Memory 동작 방식 (Pipeline)
논문 기준 memory lifecycle:
(1) Write (저장)
- interaction → memory 저장
- filtering / summarization 수행
예:
- 중요 정보만 저장
- trajectory compression
(2) Store (구조화)
- vector DB (FAISS)
- key-value
- knowledge graph
(3) Retrieve (검색)
- similarity search
- task-aware retrieval
- query-conditioned selection
(4) Read (사용)
- context에 삽입
- reasoning에 활용
3. 대표 Memory Systems
논문에서 언급된 주요 시스템들:
MemGPT
- LLM이 memory를 직접 관리
- paging-like mechanism
–> OS analogy:
LLM = CPU
Memory = RAM + DiskMemoryBank
- 경험 기반 memory 저장
- similarity retrieval
A-MEM (Agentic Memory)
- agent workflow와 결합
- task-specific memory 사용
MemOS
- memory를 OS처럼 abstraction
RecMind / REMEMBERER
- personalized memory
- user modeling
4. Memory-Enhanced Agents
논문의 중요한 포인트:
Memory는 agent의 핵심 구성 요소
Agent loop
Observe → Retrieve Memory → Plan → Act → Store Memory특징
- iterative refinement
- experience accumulation
- self-improvement 가능
5. 기술적 핵심 이슈
(1) Memory selection 문제
- 어떤 memory를 가져올 것인가?
매우 중요:
Too much → noise
Too little → missing info(2) Memory compression
- long history → 요약 필요
방법:
- summarization
- clustering
- abstraction
(3) Memory consistency
- outdated 정보 문제
- conflicting memory
(4) Credit assignment
- 어떤 memory가 도움이 되었는가?
6. 연구적으로 중요한 관점
(1) Memory = Context Management의 핵심
논문 구조에서:
Memory ⊂ Context Management즉:
- context engineering의 core module
(2) Retrieval ≠ RAG
- RAG: external knowledge
- Memory: experience / state
차이:
| 구분 | RAG | Memory |
|---|---|---|
| 내용 | factual knowledge | experience |
| 업데이트 | static | dynamic |
| 역할 | 정보 제공 | state 유지 |
(3) Stateful LLM
기존:
- stateless
Memory:
- stateful system으로 전환
7. 핵심 Insight 정리
Insight 1
Memory는 단순 저장이 아니라 context 확장 메커니즘
Insight 2
LLM을 stateless → stateful system으로 바꿈
Insight 3
Memory selection이 성능의 핵심 bottleneck
Insight 4 (가장 중요)
Memory = long-horizon reasoning의 핵심 인프라
답글 남기기