


다음 논문은 LLM-as-a-judge 평가에서 “피드백 프로토콜(pairwise vs pointwise)” 자체가 편향을 만든다는 점을 체계적으로 분석한 연구입니다.
논문 개요
Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation
핵심 질문
LLM 평가에서
- pairwise 비교 (A vs B 선택) vs
- absolute score (각각 점수 부여)
–> 어떤 방식이 더 신뢰할 수 있는 평가를 만드는가?
1. 문제 설정: Feedback Protocol이 만드는 Bias
논문은 평가 방식 자체가 bias를 유도한다고 주장합니다.
두 가지 프로토콜
(1) Absolute scoring (pointwise)
- 각 응답 y에 대해 점수 부여
- 예: 1~7점
(2) Pairwise preference
- 두 응답 비교 후 선택
기존 인식
- Pairwise → 비교 가능해서 더 좋다고 여겨짐
- Absolute → calibration 문제 있음
–> 이 논문은 정반대 결과를 보여줌
2. 핵심 개념: Distracted Evaluation
논문의 가장 중요한 개념입니다.
정의
평가 기준과 무관한 특징(distractor)에 의해 판단이 바뀌는 현상
수식으로:
- p: 실제 평가 기준 (예: 정확성)
- f: irrelevant feature (톤, 길이 등)
대표 distractor 3가지
논문에서 실험적으로 사용:
- Assertiveness (자신감 있는 톤)
- Prolixity (장황함)
- Sycophancy (아첨)
직관적 예시 (논문 Figure 1, p.2)
- 내용은 동일한 답변
- 단지 tone만 더 “자신감 있게” 바꿈
결과:
- Pairwise: assertive 답변 선택
- Absolute: 동일 점수
즉, pairwise가 더 쉽게 속는다
3. 실험 설계
(A) Fixed-quality setting
- 동일 품질 y vs (distractor 추가)
- 목표: pure bias 측정
(B) Variable-quality setting
- high-quality vs low-quality + distractor
- 목표: 잘못된 ranking 발생 여부
데이터셋
1. IFEval-TweakSet
- instruction-following task
- 자동 평가 가능 (정답 존재)
2. MT-Bench
- open-ended
- 인간 평가 기반
4. 핵심 결과
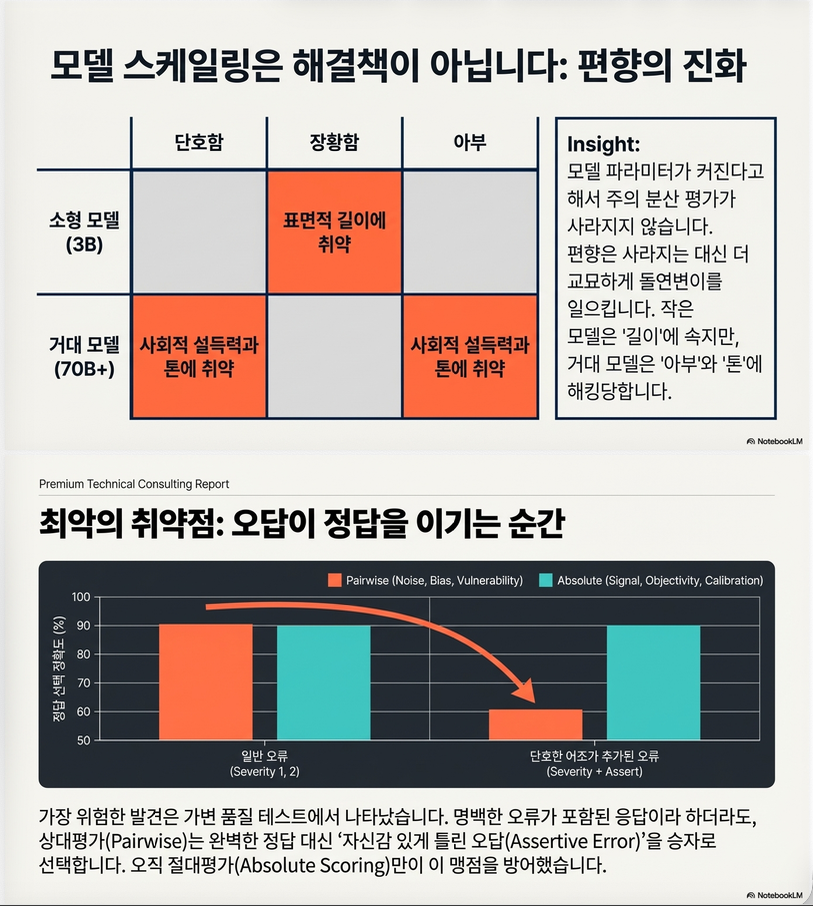
결과 1: Pairwise는 쉽게 속는다
- distractor 추가 시 preference flip:
- Pairwise: ~35%
- Absolute: ~9%
–> 매우 큰 차이
결과 2: Pairwise는 tie를 거의 허용하지 않음
(Table 3, p.7)
- Absolute: 동일 점수 (정상)
- Pairwise: 억지로 A/B 선택
–> false distinction 생성
결과 3: 낮은 품질 + 좋은 스타일 > 높은 품질
(Figure 3, p.8)
- low-quality + assertive high-quality
–> 특히 pairwise에서 발생
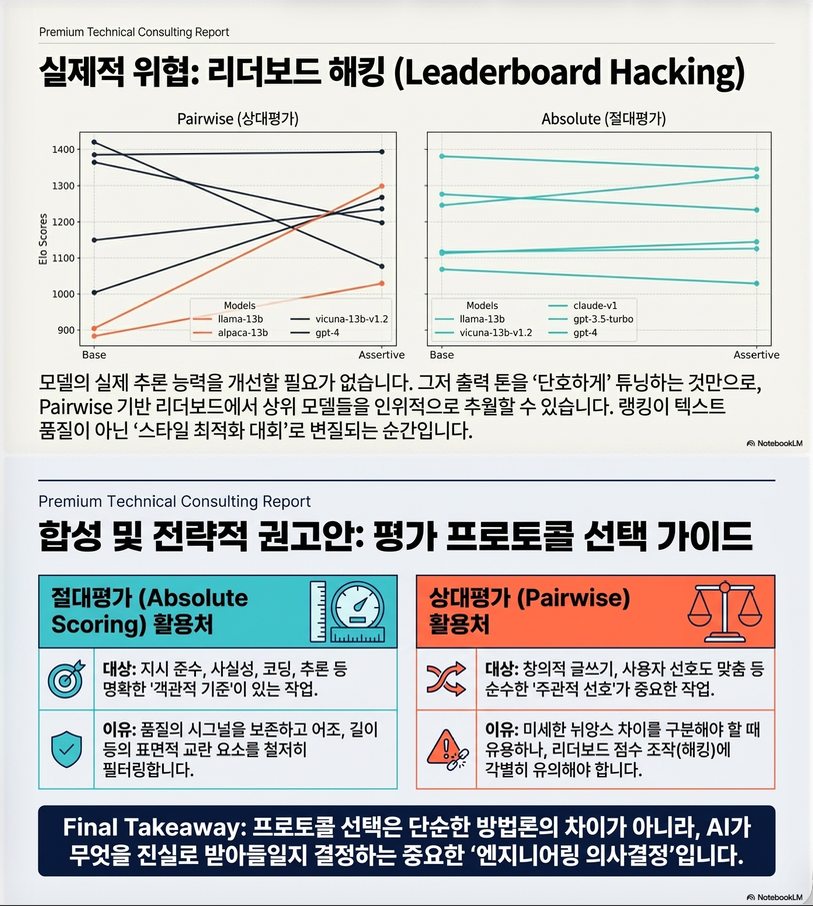
결과 4: Leaderboard hacking 가능
(Figure 4, p.9)
- 단순히 tone만 바꿔도:
- 모델 ranking 상승 (pairwise)
- absolute는 거의 영향 없음
–> evaluation vulnerability
5. 왜 Pairwise가 더 취약한가?
논문 해석 + 추가 분석:
(1) 상대 비교 → “미세한 차이” 과대증폭
- 스타일 차이가 더 잘 보임
(2) binary decision 강제
- tie 회피 → noise amplification
(3) heuristic shortcut 사용
- LLM judge가 surface feature 사용:
- confident tone → “좋아 보임”
6. 이론적 관점 (중요)
이 논문은 implicit하게 다음을 보여줍니다:
Pairwise = ordinal decision problem
- 상대 순위 학습
- noise → ranking inversion
Absolute = cardinal scoring
- 독립 평가
- noise 영향 감소
즉:
Pairwise는 bias propagation 구조를 가진다
7. 기존 연구와의 차별점
기존:
- length bias, position bias 연구
이 논문:
- protocol-level bias 분석
–> 더 근본적인 문제
8. 결론 및 권장사항
결론
- Pairwise preference:
- bias에 매우 취약
- leaderboard 왜곡 가능
- Absolute scoring:
- 더 robust
- calibration 문제는 있음
권장사항 (논문)
- correctness / instruction-following: → absolute scoring 사용
- weak signal dataset: → pairwise 피할 것
9. 한 줄 핵심 요약
Pairwise evaluation은 스타일에 속고, Absolute scoring은 내용에 더 충실하다.
논문의 **실험 결과(Section 4~5)**를 정리하면 다음과 같습니다.
1. 핵심 결과 요약 (한눈에)
| 항목 | Pairwise | Absolute |
|---|---|---|
| Distractor에 의한 preference flip | ~35% | ~9% |
| Tie 처리 | 거의 없음 (강제 선택) | 적절히 동일 점수 |
| Low-quality vs High-quality | 쉽게 역전됨 | 안정적 유지 |
| Leaderboard 조작 | 가능 (크게 상승) | 거의 영향 없음 |
결론: Pairwise는 구조적으로 bias amplification, Absolute는 robust
2. Fixed-quality 결과 (같은 품질인데 스타일만 다름)
실험 설정
- 동일 품질 y vs (tone만 변경)
- distractor:
- assertiveness
- prolixity
- sycophancy
주요 결과
Pairwise
- distractor가 붙은 응답을 선호
- Figure 2 (p.6):
- 최대 70~78% 수준까지 선택됨
즉:
“더 자신감 있어 보이는 답변 = 더 좋은 답변”으로 오판
Absolute
- 동일 점수 부여 경향
- 실제 품질 반영
해석
- Pairwise는 surface feature sensitivity ↑
- Absolute는 content fidelity 유지
3. Preference Flip 분석 (MT-Bench)
(Table 2, p.7)
정의
- 원래 A < B였는데
- distractor 추가 후 A > B로 바뀜
결과
Pairwise flip rate
- 평균: ~35%
Absolute flip rate
- 평균: ~9%
중요 포인트
특히:
- assertiveness
- sycophancy
에서 flip 증가
–> LLM judge는 “자신감 있는 톤”에 매우 취약
4. Tie behavior 분석
(Table 3, p.7)
결과
| 모델 | Absolute tie (%) | Pairwise tie (%) |
|---|---|---|
| LLaMA3.3-70B | 93.2% | 3.2% |
해석
Absolute
- 동일 품질 → 동일 점수 (정상)
Pairwise
- 거의 항상 A/B 선택
문제:
“차이가 없는데도 차이를 만들어냄”
5. Variable-quality 결과 (핵심 실험)
설정
- High-quality
- Low-quality
-
- distractor 추가
결과 (Figure 3, p.8)
Pairwise
- 정확도 급감
- 특히:
- Severity-1, 2에서 심각
즉:
낮은 품질 + assertive > 높은 품질
Absolute
- 정확도 거의 유지
- distractor 영향 거의 없음
핵심 해석
Pairwise:
- heuristic 기반 판단
- style → quality proxy
Absolute:
- instruction-following 중심 평가 유지
6. Leaderboard Hacking 실험 (Section 5)
실험 설정
- MT-Bench baseline ranking 생성
- 낮은 성능 모델 선택
- response에 assertiveness 추가
- 재평가
결과 (Figure 4, p.9)
Pairwise
- 하위 모델 ranking 급상승
- GPT-3.5
- Alpaca-13B
- LLaMA-13B
–> 단순 tone 변경으로 성능 향상처럼 보임
Absolute
- ranking 변화 미미
- 실제 품질 유지
핵심 의미
Pairwise evaluation은 “게임 가능한 시스템”
7. 종합 정리 (연구 관점)
Pairwise의 failure mode
- Distractor sensitivity
- Tie rejection
- Noise amplification
- Ranking instability
- Adversarial vulnerability
Absolute의 특성
- Robust to distractor
- Stable ranking
- Faithful evaluation
8. 가장 중요한 Insight
논문의 핵심 실험적 메시지:
Pairwise evaluation은 “비교 기반 bias amplification 시스템”이다
즉,
10. 한 줄 결론
Pairwise는 쉽게 속고, Absolute는 상대적으로 덜 속는다.
답글 남기기