


1. 핵심 아이디어 (Executive Summary)
이 논문은 다음 질문에서 출발합니다:
“LLM을 downstream task에 맞게 최적화할 때, RL(예: GRPO)이 정말 최선인가?”
결론:
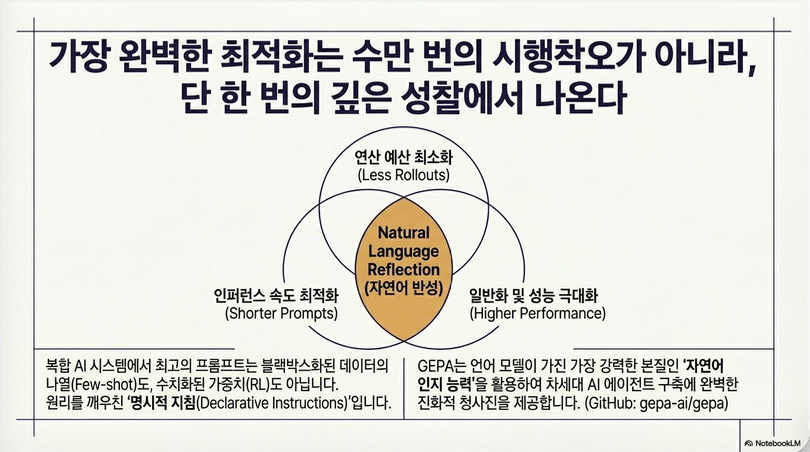
- 자연어 기반 reflection + prompt evolution이
- RL보다 훨씬 sample-efficient하며 성능도 더 좋다
이를 위해 제안한 방법이:
GEPA (Genetic-Pareto Prompt Optimization)
2. 문제 설정 (Problem Formulation)
논문은 LLM 시스템을 다음과 같이 정의합니다:
- Compound AI system
- 여러 LLM 모듈 + tool + control flow
- 각 모듈:
- prompt (π)
- weights (θ)
- 전체 목표:
핵심 제약:
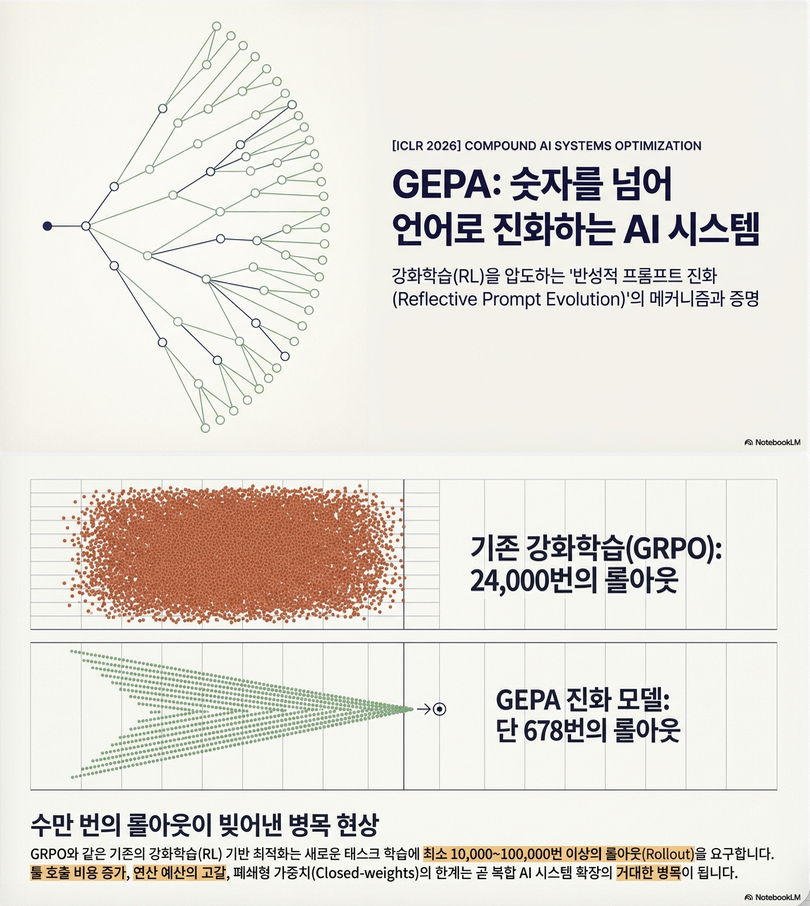
- rollout 비용이 매우 큼 → sample efficiency가 중요
3. GEPA 방법론
3.1 전체 구조
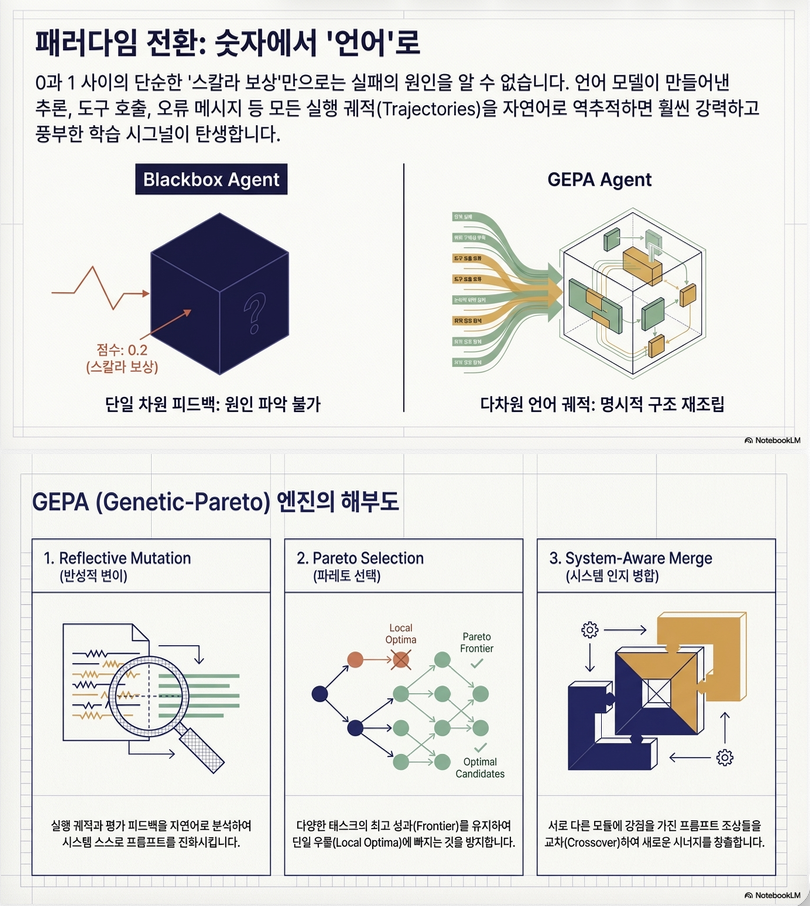
GEPA는 다음 3가지 아이디어의 결합:
(1) Genetic Evolution
- prompt를 “개체”로 보고
- mutation / crossover 수행
(2) Natural Language Reflection
- rollout trace (reasoning, tool outputs 등)를 분석
- LLM이 자연어로 오류 원인 분석 + 수정 제안
(3) Pareto-based Selection
- 단일 best 대신
- task별 best 후보 집합 유지 (Pareto frontier)
3.2 알고리즘 흐름
(논문 Figure 3 기반)
- 초기 prompt set P
- 반복:
- 후보 선택 (Pareto sampling)
- rollout 실행
- feedback 수집 (score + text)
- reflection으로 prompt 수정
- 성능 개선 시 pool에 추가
- 최종 best 선택
특징:
- gradient 없음
- policy gradient 대신 language reasoning 사용
3.3 Reflective Prompt Mutation (핵심)
GEPA의 가장 중요한 부분:
입력
- 현재 prompt
- 실행 trace (CoT, tool call 등)
- score + feedback
수행
LLM이 다음을 수행:
- 어떤 부분이 실패 원인인지 분석
- 어떤 규칙이 필요한지 추론
- prompt를 수정
즉:
credit assignment를 natural language로 수행
3.4 Feedback 함수 (μ → )
기존 RL:
- scalar reward만 사용
GEPA:
- reward + textual feedback
예:
- compiler error
- evaluation rubric 실패 이유
–> 훨씬 richer signal
3.5 Pareto 기반 탐색
문제:
- greedy → local optimum
해결:
- 각 task별 best 유지
- Pareto frontier 구성
- 그 중에서 sampling
효과:
- exploration ↑
- diversity 유지
4. 예제 (논문 Figure 2)
멀티홉 QA에서:
기존 prompt
- 단순: “query 생성”
GEPA prompt
- 매우 구조화됨:
- missing information 찾기
- entity expansion 전략
- retrieval 목적 명시
핵심 변화:
“instruction → reasoning policy”로 진화
5. 실험 결과
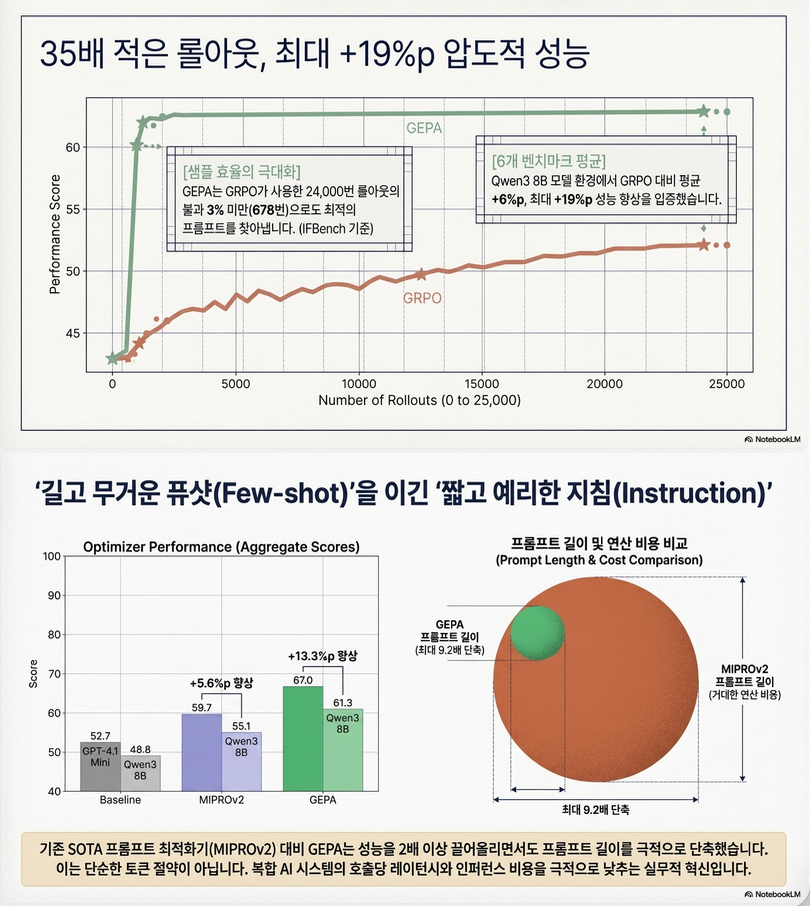
5.1 RL (GRPO) 대비
- +6pp 평균 성능 향상
- 최대 +19pp
- 최대 35× 적은 rollout
핵심:
RL보다 훨씬 sample-efficient
5.2 Prompt optimizer 대비
- MIPROv2 대비:
- +10~13pp
특히 중요한 결과:
instruction-only optimization이 few-shot보다 더 강력
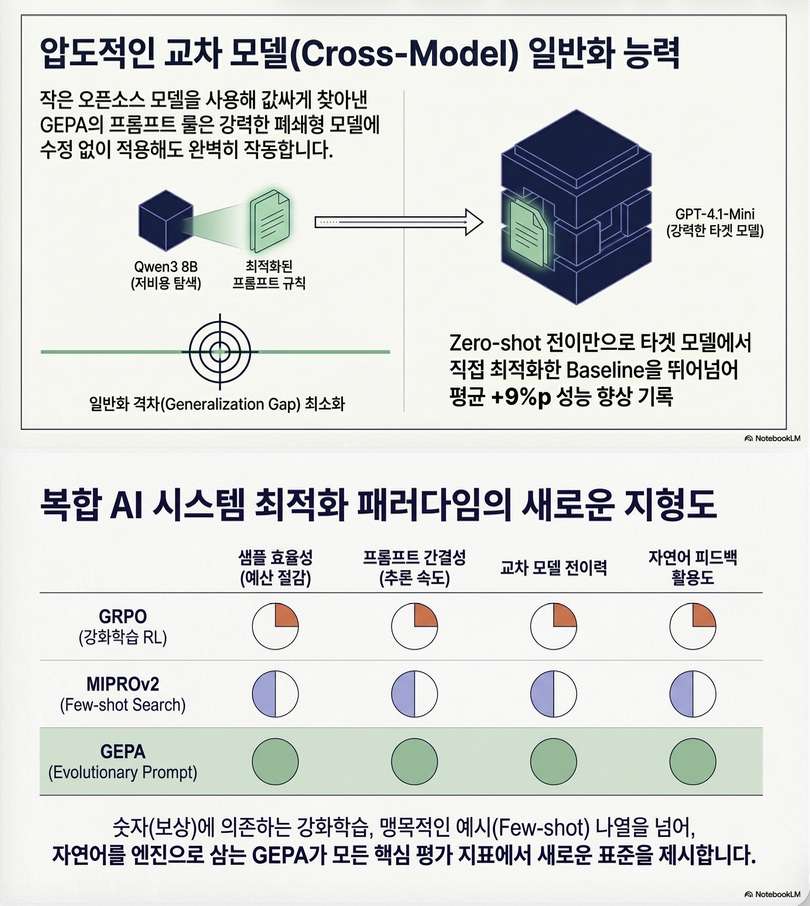
5.3 Generalization
- Qwen에서 최적화 → GPT-4.1에서도 성능 향상
–> cross-model transfer 가능
6. 핵심 인사이트
Insight 1: Language > Gradient
- RL: scalar reward → 정보 부족
- GEPA: natural language → rich signal
–> LLM은 “language로 배우는 것이 더 강함”
Insight 2: Reflection = Credit Assignment
기존:
- gradient-based credit assignment
GEPA:
- reasoning-based credit assignment
Insight 3: Prompt = Program
GEPA는 prompt를:
정적 instruction → 진화하는 프로그램
으로 취급
Insight 4: Evolution + Pareto 중요
- 단일 best → local opt
- Pareto → diversity 유지
7. 기존 방법과 비교
| 방법 | 특징 | 한계 |
|---|---|---|
| GRPO (RL) | weight 업데이트 | sample inefficiency |
| MIPROv2 | prompt + demo 최적화 | global reward |
| TextGrad | textual gradient | greedy |
| GEPA | reflection + evolution | ✔ best |
다음은 **GEPA 논문의 방법론(Section 3)**을 알고리즘 중심으로 정리한 것입니다.
1. 전체 방법론 개요
GEPA는 다음 최적화 문제를 푼다:
- : prompt 집합 (모듈별 prompt)
- : 고정 (no finetuning)
- 핵심: prompt space에서 탐색
2. 핵심 구성 요소
GEPA = 3가지 모듈의 결합
(1) Genetic Prompt Evolution
- prompt를 population으로 관리
- mutation / crossover
(2) Reflective Feedback Learning
- 실행 trace 기반 자연어 reflection
(3) Pareto-based Selection
- multi-objective 탐색 (task-wise best 유지)
3. 알고리즘 구조 (Core Loop)
3.1 Candidate Pool
- 각 candidate = 전체 시스템 prompt set
3.2 반복 루프
while rollout budget > 0:
Step 1. Candidate Selection
- Pareto frontier에서 샘플링
Step 2. Rollout 실행
각 candidate 에 대해:
Step 3. Feedback 생성
- score: scalar metric
- feedback: 자연어 설명 (e.g., 오류 원인, rubric 실패 이유)
Step 4. Reflective Mutation
선택된 module 에 대해:
LLM이 수행:
- failure attribution
- rule extraction
- prompt rewrite
Step 5. 평가 및 선택
- minibatch에서 성능 개선 여부 확인
- 개선 시:
- candidate pool에 추가
- Pareto set 업데이트
4. Reflective Prompt Mutation (핵심)
입력
- current prompt
- execution trace
- score s
- feedback f
내부 동작 (LLM reasoning)
LLM이 다음을 수행:
(1) Error Attribution
- 어떤 instruction이 문제인지 식별
(2) Rule Extraction
- 일반화된 규칙 생성
(3) Prompt Update
- instruction 재작성
수식적 표현
여기서 는 language-based update operator
핵심 특징
| 기존 RL | GEPA |
|---|---|
| gradient 기반 | language 기반 |
| implicit credit assignment | explicit reasoning |
| scalar reward | structured feedback |
5. Feedback 함수 확장 ()
기존:
GEPA:
feedback 구성
- execution trace
- evaluation trace (e.g., compiler error)
- human feedback (optional)
–> credit assignment signal 강화
6. Pareto-based Candidate Selection
문제
- greedy → local optimum
해결: Pareto Frontier
각 task t에 대해:
전체 Pareto set:
Sampling 전략
- candidate 선택 확률 ∝ 해당 candidate가 best인 task 수
효과
- diversity 유지
- exploration 강화
- local optimum 탈출
7. System-aware Crossover (Merge)
(appendix 기반)
두 candidate 를 결합:
- module 단위 선택:
- 더 잘 진화된 module 채택
8. 전체 알고리즘 (Pseudo-code)
Initialize P = {Π_0}
while budget > 0:
# 1. Pareto-based sampling
Π ← sample_from_pareto(P)
# 2. rollout
τ ← run_system(Φ, Π)
# 3. feedback
score, feedback ← μ_f(τ)
# 4. select module
i ← select_module()
# 5. reflective mutation
π_i' ← reflect(π_i, τ, feedback)
Π_new ← replace(Π, i, π_i')
# 6. evaluate
if performance(Π_new) > performance(Π):
P.add(Π_new)
return best_candidate(P)9. 기존 방법과의 구조적 차이
RL (GRPO)
- weight 업데이트
- rollout 많이 필요
GEPA
- prompt 업데이트
- rollout 적게 필요
10. 방법론 핵심 요약
핵심 메커니즘
- Trace 수집
- Textual feedback 생성
- LLM reflection
- Prompt mutation
- Pareto 기반 탐색
핵심 철학
“LLM은 gradient보다 language를 통해 더 잘 학습한다”
11. 연구적으로 중요한 포인트
(A) Credit Assignment 혁신
- gradient → reasoning
(B) Search Space 전환
- weight space → prompt space
(C) Learning Signal 강화
- scalar → structured language
답글 남기기