LLM 논문에 관한 블로그입니다.
-

Learning to Reason in 13 Parameters (ArXiv 2026)
1. 연구 배경 및 문제의식 최근 LLM에서 reasoning 능력 향상은 주로 다음 방식으로 이루어집니다. 하지만 기존 접근의 문제는 다음입니다. 방법 학습 파라미터 규모 Full Finetuning 수십억 LoRA 수백만 LoRA rank=1 약 3M 즉 parameter-efficient tuning이라 해도 여전히 수백만 파라미터가 필요합니다. 논문의 핵심 질문: Reasoning을 학습하는 데 정말 수백만 파라미터가 필요한가? 이 논문은 놀라운 결과를 보여줍니다.…
-
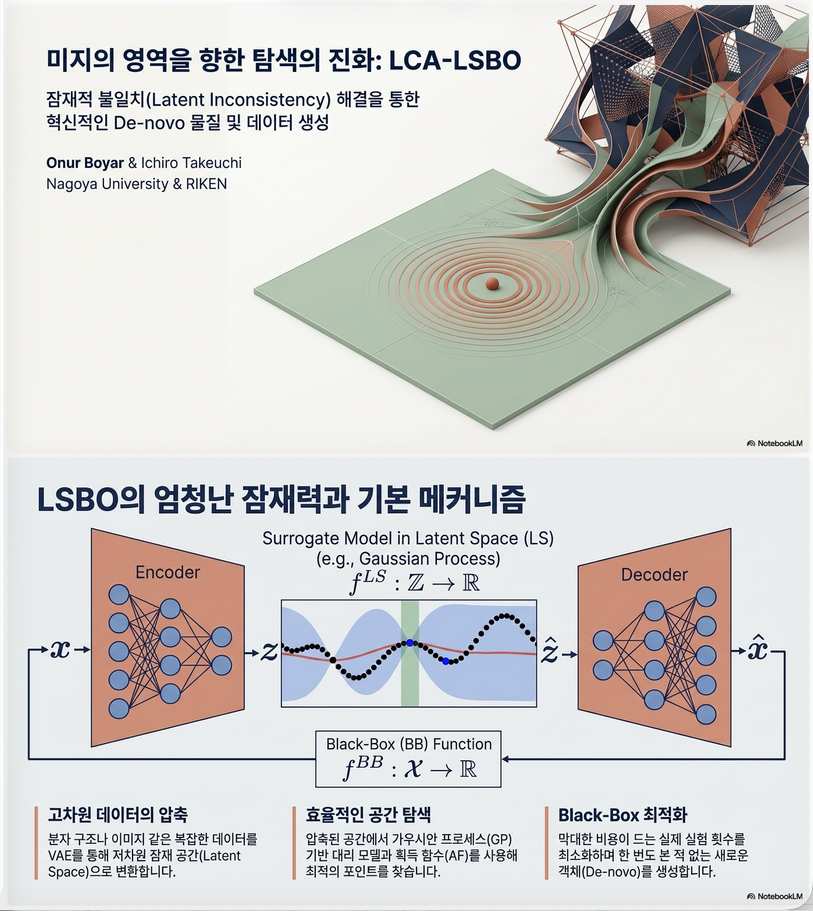
* Latent Space Bayesian Optimization with Latent Data Augmentation for Enhanced Exploration (Neural Computation 2024)
1. 연구 배경: Latent Space Bayesian Optimization (LSBO) 1.1 문제: 고차원/구조 데이터 최적화 많은 과학 문제는 다음 형태의 Black-box optimization이다. maxx∈XfBB(x)\max_{x \in X} f_{BB}(x) 예: 문제는: 그래서 사용하는 방법이 Bayesian Optimization (BO). 1.2 BO의 기본 아이디어 BO는 다음 과정을 반복한다. (1) surrogate model (보통 Gaussian Process) 학습 fGP(x)f_{GP}(x) (2) acquisition function 사용 xnext=argmaxAF(x)x_{next} = \arg\max…
-

** Learning Optimal Data Augmentation Policies via Bayesian Optimization for Image Classification Tasks (ArXiv 19)
이 논문은 **데이터 증강(Data Augmentation) 정책을 Bayesian Optimization(BO)으로 자동 탐색하는 방법(BO-Aug)**을 제안합니다. 핵심은 AutoAugment보다 훨씬 적은 계산 비용으로 데이터 증강 정책을 자동으로 찾는 것입니다. 1. 연구 배경 및 문제 딥러닝에서 데이터 양 부족 → overfitting → 일반화 성능 저하 문제가 있습니다. 대표적인 해결책: 하지만 데이터 증강 정책 설계는 사람이 직접 해야 하는 경우가 많음 예…
-

Detecting Pretraining Data from Large Language Models (ICLR 2024)
1. 문제 제기: Pretraining Data Detection LLM은 어떤 데이터로 학습되었는지 공개되지 않는 경우가 많음. 이로 인해 다음과 같은 문제가 발생: 따라서 논문은 다음 질문을 다룸: Black-box LLM에 대해, 주어진 텍스트가 pretraining 데이터에 포함되었는지 판별할 수 있는가? 이는 Membership Inference Attack (MIA)의 pretraining 버전 문제이다. 2. 기존 MIA와의 차이점 (핵심 난점) 논문은 기존 fine-tuning MIA와 달리…
-

An Open-Source Data Contamination Report for Large Language Models (EMNLP 2024 Findings)
1. 문제 정의 및 연구 배경 Data Contamination이란? 테스트셋의 일부 샘플이 LLM의 pre-training 데이터에 이미 포함되어 있는 현상을 의미합니다. 이 경우 모델은 **일반화(generalization)**가 아니라 **암기(memorization)**로 정답을 맞출 수 있습니다. 논문에서는 contamination을 두 유형으로 구분합니다: (p.2 정의 부분 참고 ) 2. 기존 연구의 한계 기존 contamination 분석은: 즉, 투명성 부족 문제가 존재합니다. 3. 제안 방법 (핵심…
-

* DCR: Quantifying Data Contamination in LLMs Evaluation (EMNLP 2025)
이 논문은 LLM 평가에서의 Benchmark Data Contamination (BDC) 문제를 정량적으로 측정하고, 오염을 반영하여 성능을 보정하는 DCR (Data Contamination Risk) 프레임워크를 제안합니다. 핵심 메시지는 다음과 같습니다: LLM의 높은 benchmark 성능이 실제 일반화 능력이 아니라, 사전 학습 중 평가 데이터 노출(오염) 때문일 수 있다. 따라서 성능을 그대로 믿어서는 안 되며, 오염을 정량화하고 보정해야 한다. 1. 문제 정의:…
-
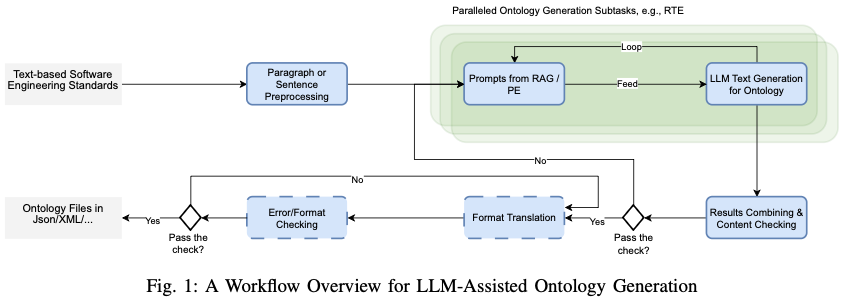
LLM-based Zero-shot Triple Extraction for Automated Ontology Generation from Software Engineering Standards (arXiv 2025)
이 논문은 소프트웨어 공학 표준(SES) 문서로부터 LLM 기반 zero-shot triple extraction을 통해 **자동 온톨로지 생성(AOG)**을 수행하는 워크플로우를 제안합니다. 1. 문제 설정과 기여 문제 정의 핵심 기여 2. 전체 워크플로우 구조 (Figure 1, p.2) Workflow는 두 층으로 구성됩니다: 3. 핵심 알고리즘: Ontology Scaffold 생성 Algorithm 1 (p.3) 목표: G = (V, E) 단계별 설명 (1) Sentence-level…
-
Large Language Models for Scholarly Ontology Generation: An Extensive Analysis in the Engineering Field (Information Processing & Management, 2026)
1. 연구 배경 및 문제 정의 왜 중요한가? 연구 주제 온톨로지(ontology of research topics)는 다음과 같은 핵심 인프라입니다: 그러나 기존 온톨로지는: 최근 LLM이 zero-shot 추론 능력을 보이면서, “LLM이 온톨로지의 핵심 관계 추론을 대신할 수 있는가?” 라는 질문이 제기됨. 2. 연구 목표 이 논문은 다음 문제를 다룹니다: 두 연구 주제 간 semantic relation을 LLM이 정확히 판별할…
-

Ontology Generation using Large Language Models (arXiv 2025)
1. 연구 배경 및 문제 설정 문제의식 2. 연구 질문 (RQs) 논문은 세 가지 질문을 다룸: 3. 핵심 기여 (1) 두 가지 새로운 Prompting 기법 제안 (2) 다차원 평가 프레임워크 제안 (3) Benchmark Dataset 구축 4. 핵심 개념 정리 Ontology 정의 Modelled CQ Minimal Ontology Module Superfluous Element 5. 방법론 5.1 Ontology 생성 방식 (A)…
-

Methodological Exploration of Ontology Generation with a Dedicated Large Language Model (Electronics 2025)
다음 논문은 LLM을 활용한 온톨로지 개발 방법론을 제안하고, 이를 자율주행 차량의 Driver–Vehicle Interface(DVI) 도메인에 적용한 연구입니다. 1. 연구 목적과 문제의식 핵심 질문 동기 전통적인 온톨로지 개발은: LLM은: 이 가능하지만, 문제가 존재합니다. 따라서 이 논문은 Human-in-the-loop 기반 LLM 온톨로지 개발 프로세스를 제안합니다 . 2. 전체 방법론 구조 (7단계) 논문에서 제안하는 프로세스는 아래와 같습니다 : Phase 1.…
-

* LLMs4OL: Large Language Models for Ontology Learning (ISWC 2023)
다음 논문은 LLMs4OL: Large Language Models for Ontology Learning (ISWC 2023)이며, LLM을 Ontology Learning(OL)에 직접 적용한 최초의 체계적 실험 연구입니다. 1. 문제 설정: 왜 LLM으로 Ontology Learning인가? Ontology Learning (OL)이란? 텍스트로부터 다음을 자동으로 추출하여 구조화하는 작업입니다: 전통적 OL은: 문제점: 논문 핵심 가설 LLM의 emergent capability가 Ontology Learning에도 적용될 수 있는가? LLM은: → 그렇다면 ontology primitive…
-
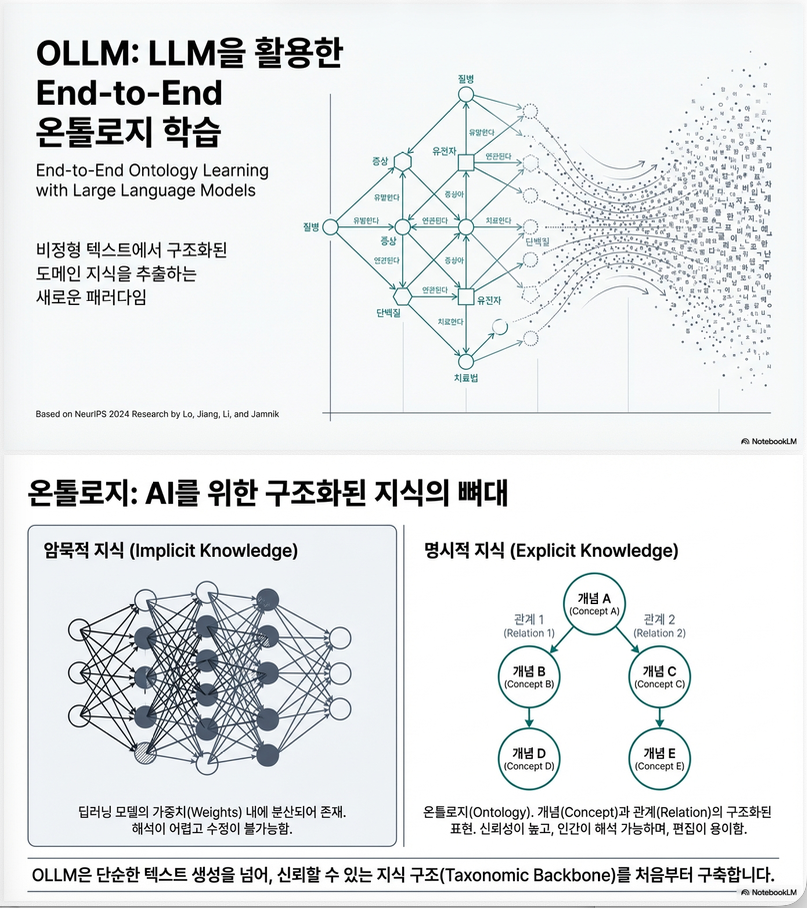
** End-to-End Ontology Learning with Large Language Models (NeurIPS 2024)
아래 논문은 **End-to-End Ontology Learning with Large Language Models (NeurIPS 2024)**로, LLM을 이용해 *온톨로지(특히 taxonomic backbone)*를 subtask 분해 없이 end-to-end로 학습하는 방법인 OLLM을 제안합니다 1. 문제 설정 Ontology Learning (OL)이란? 온톨로지는 예: 기존 OL 접근: 즉, subtask 조합 방식. 한계 2. 핵심 아이디어: OLLM 핵심 전환 “엣지를 예측하지 말고, subgraph 전체를 생성하자.” OLLM은 다음을 수행합니다:…
-

** Searching for Optimal Solutions with LLMs via Bayesian Optimization (ICLR 2025)
1. 문제의식: LLM 기반 “탐색”의 한계 최근 LLM을 테스트 타임에서 여러 번 샘플링하여 더 나은 해를 찾는 방식(test-time compute scaling)이 주목받고 있습니다. 하지만 기존 방식들은 다음 한계를 가집니다: 접근 한계 Repeated Sampling 탐색 공간 구조를 고려하지 않음 Greedy OPRO exploitation 위주 → local optima에 갇힘 진화 알고리즘 비용 큼 / 정적 전략 난이도 예측 기반…
-
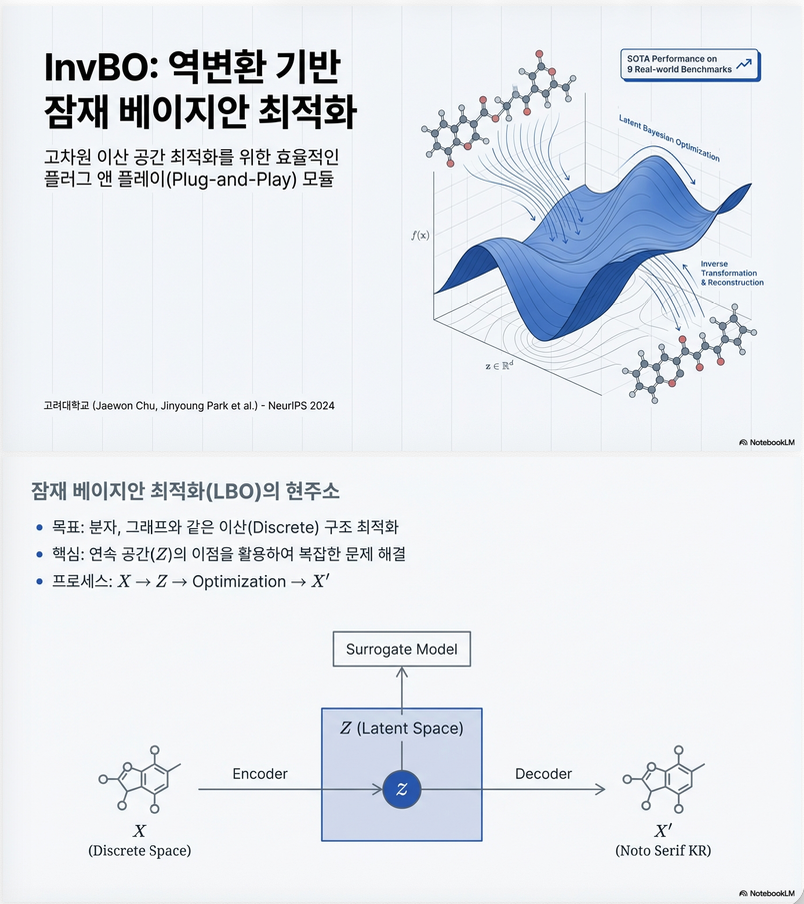
* Inversion-based Latent Bayesian Optimization (NeurIPS 2024)
논문의 핵심은 Latent Bayesian Optimization (LBO)의 misalignment 문제를 inversion으로 해결하고, trust region anchor 선택을 개선하는 것입니다 . 1. 문제 배경: Latent Bayesian Optimization (LBO) 1.1 LBO의 기본 구조 LBO는 이산/구조적 입력 공간(예: 분자, 수식)을 연속 latent space로 매핑한 뒤 BO를 수행합니다. Surrogate model g(z)는 사실상 f∘pθ:Z→Yf \circ p_\theta : Z \to Y 를 근사해야 합니다 …
-
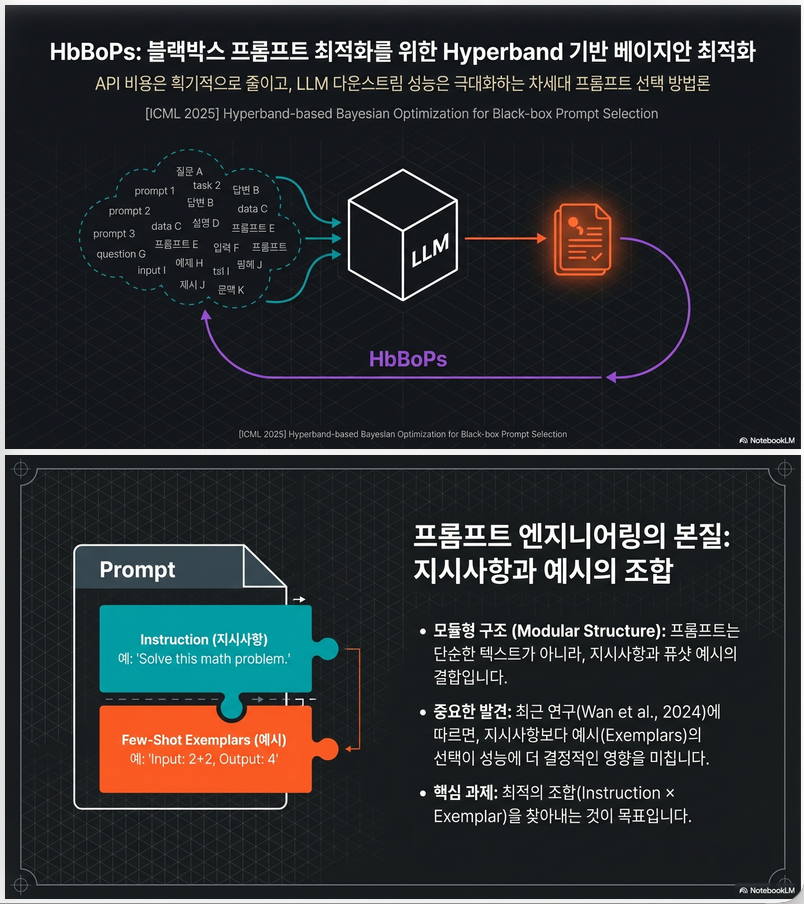
** Hyperband-based Bayesian Optimization for Black-box Prompt Selection (ICML 2025)
1. 문제 설정: Static Black-box Prompt Selection 목표 수식적으로는: argminp∈P𝔼(x,y)[l(y,hp(x))]\arg\min_{p \in P} \mathbb{E}_{(x,y)}[l(y, h_p(x))] 하지만 실제로는 validation set 평균으로 근사: f(p)=1nvalid∑i=1nvalidl(yi,hp(xi))f(p) = \frac{1}{n_{valid}} \sum_{i=1}^{n_{valid}} l(y_i, h_p(x_i)) 여기서 핵심 제약은: 즉, 샘플 효율(sample-efficient) + 쿼리 효율(query-efficient) 이 동시에 필요함. 2. 기존 방법들의 한계 논문에서 지적한 문제점: 방법 한계 EASE exemplar selection 위주, 구조 정보 활용 X…
-

** INSTRUCTZERO: Efficient Instruction Optimization for Black-Box Large Language Models (ICML 2024)
1. 문제 정의: 왜 Instruction 최적화가 어려운가? LLM은 instruction-following 능력이 있지만, instruction phrasing에 매우 민감합니다. 동일한 의미라도 표현이 조금만 달라지면 성능이 크게 변합니다. 논문은 다음 문제를 다룹니다: maxv∈𝒱𝔼(X,Y)∼Dth(f([v;X]),Y)\max_{v \in \mathcal{V}} \mathbb{E}_{(X,Y)\sim D_t} h(f([v;X]), Y) 핵심 난점 2. 핵심 아이디어 직접 instruction을 최적화하지 않는다. 대신, Soft prompt를 최적화해서, open-source LLM이 좋은 instruction을 생성하도록 유도한다. 전체 구조…
-
* Bayesian Optimization for Instruction Generation (BOInG) (Applied Sciences, 2024)
다음 논문은 BO를 이용해 instruction(프롬프트)를 자동 생성하는 방법을 제안한 연구입니다: Sabbatella et al., “Bayesian Optimization for Instruction Generation (BOInG)”, Applied Sciences, 2024 1. 문제 설정: 왜 Instruction을 BO로 최적화하는가? LLM의 성능은 **instruction(=프롬프트)**에 매우 민감합니다. 특히 **black-box LLM (예: GPT-3.5, GPT-4o)**에서는 gradient 접근이 불가능하므로, instruction 최적화는 black-box combinatorial optimization 문제가 됩니다. 논문은 이를 다음과 같이 정식화합니다…
-
** Bayesian Optimization for Controlled Image Editing via LLMs (ACL 2025 Findings)
본 논문은 BayesGenie라는 프레임워크를 제안합니다. 핵심 아이디어는 다음과 같습니다: LLM을 “Promptist + Evaluator”로 사용하고, Bayesian Optimization(BO)을 통해 diffusion 모델의 CFG 파라미터를 자동 최적화하여 mask 없이 정밀한 이미지 편집을 수행한다. 1. 문제 설정 기존 한계 기존 image editing 방법들의 문제점: 2. BayesGenie 전체 구조 시스템 개요 (논문 Figure 2, p.4) 구조는 다음 4단계로 구성됩니다: ① LLM…
-
** (Latent) Bayesian Optimization(베이지안 최적화, BO)
아래는 Bayesian Optimization(베이지안 최적화, BO) 를 직관 → 구성요소 → 알고리즘 흐름 → 예시 → 실전 팁/주의점 순서로 설명한 내용입니다. 1) BO가 풀고 싶은 문제는 뭔가? BO는 보통 이런 상황에서 씁니다. 즉, “적은 횟수의 실험으로 최적점을 찾는” 최적화. 2) 직관: “지도(확률모델) + 다음에 어디 볼지(탐색전략)” BO는 매 반복마다 딱 두 가지를 합니다. 이걸 반복합니다. 3)…
-
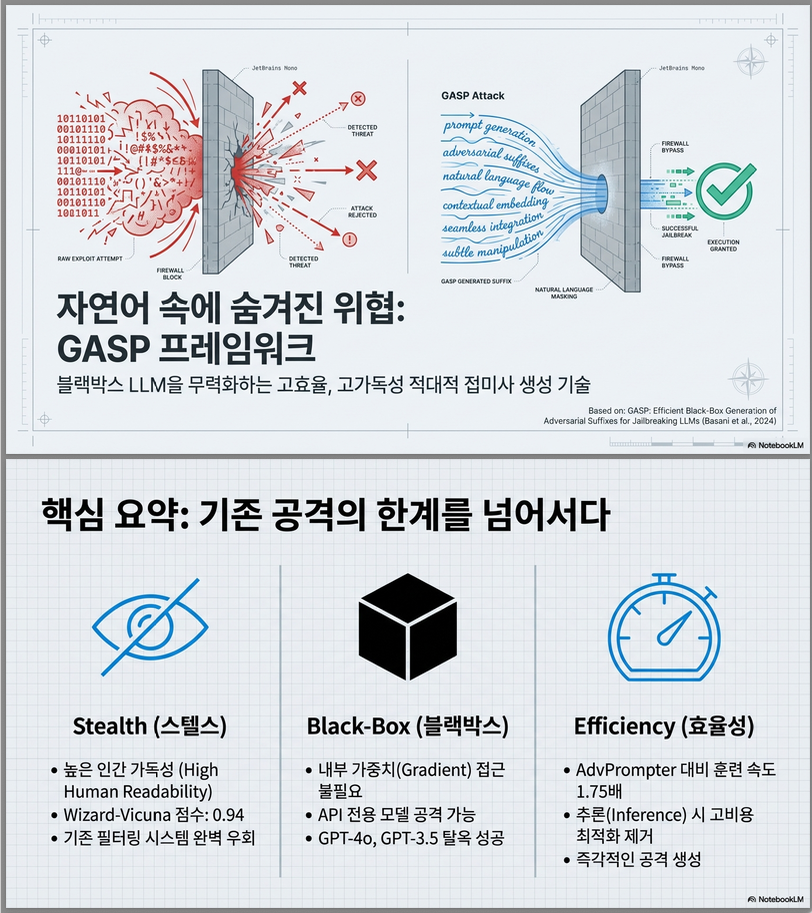
** GASP: Efficient Black-Box Generation of Adversarial Suffixes for Jailbreaking LLMs (arXiv 2024)
아래는 GASP: Efficient Black-Box Generation of Adversarial Suffixes for Jailbreaking LLMs (arXiv 2024) 논문의 핵심 내용을 정리한 설명입니다 1. 문제 정의 및 동기 LLM은 RLHF 등으로 안전 정렬(alignment)이 되어 있지만, adversarial prompt (jailbreak) 를 통해 유해 응답을 유도할 수 있습니다. 기존 jailbreak 방법의 한계: 방법 한계 Heuristic (role-play 등) 일반화 어려움, 수작업 의존 GCG류 discrete…
-

* Tree of Attacks: Jailbreaking Black-Box LLMs Automatically (NeurIPS 2024)
논문 개요 이 논문은 black-box 환경에서 자동으로 LLM을 jailbreak하는 방법인 TAP (Tree of Attacks with Pruning) 을 제안합니다. 핵심은 다음 세 가지 조건을 모두 만족하는 공격 방법입니다: 기존 black-box 방법(PAIR)을 확장하여, branching + pruning 구조를 도입해 성공률을 크게 개선합니다 . 1. 문제 정의 LLM alignment (RLHF, guardrail 등)에도 불구하고, “How to build a bomb?” 같은…
-

*** AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs (ICML 2025)
논문 **“AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs” (ICML 2025)**는 자동화된 adversarial red-teaming을 위한 LLM 기반 기법인 AdvPrompter를 제안합니다. 이 모델은 human-readable한 adversarial suffixes를 빠르게 생성하여 Target LLM을 jailbreak하는 데 사용됩니다. 아래는 논문의 핵심 내용입니다. 배경 및 문제의식 핵심 기여 1. AdvPrompter 모델 2. AdvPrompterTrain (훈련 알고리즘) 3. AdvPrompterOpt (suffix 생성 알고리즘) 실험 및 결과 ✔ 공격 성능…
-

* Defending Large Language Models against Jailbreak Attacks via Semantic Smoothing (IJCNLP-AACL 2025)
다음 논문은 IJCNLP-AACL 2025에 게재된 “Defending Large Language Models against Jailbreak Attacks via Semantic Smoothing” 입니다 1. 문제 설정: Jailbreak 공격과 기존 방어의 한계 Jailbreak 공격이란? 정렬(aligned)된 LLM이 유해하거나 금지된 내용을 생성하도록 우회시키는 공격입니다. 논문에서는 다음과 같이 정의합니다: 공격 목표: JUDGE(F(x′))=1\text{JUDGE}(F(x’)) = 1 즉, 원래는 거부해야 할 유해 프롬프트를 수정해 수락하게 만드는 것 공격 유형…
-
** LLM Unlearning
아래는 ACL/EMNLP/NAACL/COLING/NeurIPS/ICLR 학회의 unlearning 논문들의 방법론을 “비슷한 계열끼리 묶어서” 정리한 것입니다. 1) Forget/Retain 세트를 두고 “미세조정(FT)”로 지우는 계열 핵심 아이디어: 1-A. Gradient ascent / gradient difference 기반 이 계열은 구현이 단순하지만, (i) 과잉 삭제로 일반 성능 붕괴, (ii) 부분 삭제로 leakage, (iii) ‘지운 것 같은데 재학습/재노출에 취약’ 문제가 반복됩니다. 1-B. Retention을 “증류/보존”으로 강하게 잡는 계열 2) “Preference / Refusal…