[카테고리:] Mechanistic Interpretability
-

* Hierarchical Sparse Circuit Extraction from Billion-Parameter Language Models through Scalable Attribution Graph Decomposition (ArXiv 2026)
이 논문은 최근 Sparse Feature Circuit 계열(SAE, Transcoder, Edge Pruning, EAP) 연구들을 모두 조합하여 70B 규모 LLM까지 회로(circuit)를 추출할 수 있는 scalable framework를 제안한 논문입니다. 새로운 알고리즘을 실제 구현하여 대규모 실험으로 검증했다기보다는 기존 연구들을 조합한 프레임워크 제안 성격이 강합니다. 특히 일부 실험 수치(70B까지의 결과 등)는 공개 코드나 재현성 정보가 부족하여 실제 구현 여부를 신중하게 해석할…
-

*** Scalable Circuit Learning for Interpreting Large Language Models (ArXiv 2026)
아래 논문은 CircuitLasso라는 방법을 제안합니다. 핵심은 SAE feature 기반 circuit discovery를 intervention 없이 Lasso sparse regression으로 확장 가능하게 수행하는 것입니다. 1. 문제의식 기존 circuit discovery 방법들, 예를 들어 activation patching, EAP, EAP-IG, causal tracing은 edge나 node의 causal effect를 intervention으로 측정합니다. 문제는 두 가지입니다. 첫째, raw neuron은 polysemantic이라서 circuit을 찾더라도 해석이 어렵습니다. 둘째, SAE feature는…
-

** Learning Multi-Level Features with Matryoshka Sparse Autoencoders (ICML 2025)
이 논문은 최근 Sparse Autoencoder(SAE) 연구에서 **가장 중요한 문제인 “dictionary를 크게 만들면 오히려 feature quality가 나빠지는 현상”**을 해결하려는 논문입니다. 1. 연구 배경 기존 SAE는 dictionary size를 크게 만들수록 reconstruction은 좋아집니다. 예를 들어, dictionary를 계속 늘리면 activation reconstruction error는 감소합니다. 하지만 interpretability에서는 문제가 생깁니다. 논문에서는 이를 크게 3가지 pathology로 설명합니다. (1) Feature Splitting 원래 Punctuation 하나의…
-

** Sparse Feature Coactivation Reveals Causal Semantic Modules in Large Language Models (ArXiv 2025)
이 논문은 **Sparse Autoencoder(SAE)의 feature를 개별적으로 보는 것이 아니라, 여러 layer에서 함께(co-activation) 활성화되는 feature들의 집합(component)**을 찾아 semantic module로 해석하는 논문입니다. 기존의 circuit discovery처럼 복잡한 edge attribution(EAP, ACDC, Transcoder Circuit)을 수행하지 않고도 상당히 의미 있는 semantic module을 발견할 수 있다는 것이 핵심입니다. 1. 연구 배경 Mechanistic Interpretability에서는 크게 두 가지 흐름이 있다. (1) Circuit Discovery…
-

** Data-driven Circuit Discovery for Interpretability of Language Models (ArXiv 2026)
이 논문의 핵심 메시지는 매우 간단합니다. 기존 Circuit Discovery는 “task → 하나의 circuit”이라는 가정을 깔고 있는데, 실제 LLM은 같은 task도 여러 메커니즘으로 풀 수 있다. 따라서 기존 방법은 task circuit이 아니라 dataset-specific circuit을 찾고 있으며, 심지어 서로 다른 메커니즘을 하나의 circuit에 섞어버릴 수 있다. 이를 해결하기 위해 Data-driven Circuit Discovery (DCD) 를 제안한다. 1.…
-

*** Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models (ICLR 2025)
이 논문은 최근 SAE(Sparse Autoencoder) 기반 해석가능성 연구와 Circuit Discovery 연구를 결합한 대표적인 논문이다. 기존 ACDC, Activation Patching, EAP 등의 circuit discovery는 attention head, neuron, MLP block 수준에서 회로를 찾았는데, 이들은 대부분 polysemantic해서 사람이 이해하기 어렵다. 본 논문의 핵심 아이디어는: “Circuit의 기본 단위를 neuron 대신 SAE feature로 바꾸자.” 즉, Neuron Circuit→Sparse Feature Circuit\text{Neuron Circuit}\rightarrow\text{Sparse Feature Circuit} 로 전환한…
-

** Transcoders Find Interpretable LLM Feature Circuits (NeurIPS 2024)
이 논문은 최근 Mechanistic Interpretability에서 매우 중요한 논문 중 하나입니다. 한 줄 요약하면: SAE가 “해석 가능한 feature”를 찾는 데는 성공했지만, feature들 사이의 circuit을 분석하기는 어려웠다.Transcoder를 사용하면 MLP를 sparse feature graph로 직접 근사할 수 있고, feature-level circuit을 input-invariant하게 분석할 수 있다. 특히 이후의 계열 연구에 큰 영향을 주었습니다. 1. 문제의식 기존 Circuit Discovery의 문제 Transformer 회로를…
-

Dictionary Learning Improves Patch-Free Circuit Discovery (ArXiv 2024)
1. 논문 핵심 이 논문은 Sparse Dictionary Learning/SAE로 얻은 monosemantic feature들 사이의 circuit을 activation patching 없이 발견하는 방법을 제안한다. 대상 모델은 Othello-GPT, 즉 오델로 다음 합법 수 예측을 학습한 6-layer, hidden size 128의 작은 decoder-only Transformer이다. 핵심 주장은 다음이다: residual stream에 write하는 모든 module output, 즉 embedding, attention output, MLP output을 dictionary feature로 분해하면, logit이나…
-

*** RelP: Faithful and Efficient Circuit Discovery in Language Models via Relevance Patching (ArXiv 2025)
논문 개요 이 논문은 기존 Activation Patching과 Attribution Patching의 장단점을 결합하려는 논문입니다. 핵심 아이디어는 다음과 같습니다. Attribution Patching의 gradient 항을 Layer-wise Relevance Propagation, 즉 LRP 기반 propagation coefficient로 대체하면, Activation Patching에 더 가깝게 causal effect를 근사하면서도 계산 비용은 거의 그대로 유지할 수 있다. 논문에서 제안하는 방법 이름은 Relevance Patching, RelP입니다. 저자들은 RelP가 Activation Patching보다 훨씬…
-

*** Constructing Interpretable Features from Compositional Neuron Groups (ArXiv 2025)
이 논문은 최근 SAE(Sparse Autoencoder) 중심의 mechanistic interpretability 연구에 대해 상당히 흥미로운 문제 제기를 합니다. 핵심 질문은: “LLM 내부의 의미(concept)를 표현하는 진짜 단위(unit)는 무엇인가?” 입니다. 기존에는 등이 주로 사용되었는데, 저자들은 “실제로는 여러 neuron들이 조합(composition)되어 하나의 개념을 표현한다” 고 주장하며, MLP activation을 SNMF(Semi-Nonnegative Matrix Factorization)로 분해하여 neuron group 기반 feature를 찾는 방법을 제안합니다. 1. 논문의…
-

*** Weight Patching: Toward Source-Level Mechanistic Localization in LLMs (ArXiv 2026)
이 논문의 핵심 아이디어는 다음 한 문장으로 요약할 수 있습니다. 기존 Mechanistic Interpretability가 “어디에서 신호가 보이는가?”(activation)를 찾았다면, 이 논문은 “그 능력이 실제로 어느 파라미터에 저장되어 있는가?”(weight)를 찾으려 한다. 1. 왜 새로운 방법이 필요한가? 기존 Circuit Discovery 계열: 등은 모두 activation 공간에서 동작한다. 예를 들어: Activation Patching을 하면 → Head C가 중요하다고 판단 하지만 실제로는…
-

* A Mathematical Framework for Transformer Circuits (Transformer Circuits 2021)
이 논문은 오늘날 Mechanistic Interpretability 분야의 출발점 중 하나로 평가받습니다. 특히 이후의 등의 연구들이 사실상 이 논문의 수학적 프레임워크 위에서 발전되었습니다. 1. 논문의 핵심 질문 Transformer 내부를 회로(circuit)처럼 해석할 수 있는가? 기존 Transformer 수식: Q=XWQQ=XW_Q K=XWKK=XW_K V=XWVV=XW_V A=softmax(QKT)A=\text{softmax}(QK^T) Y=AVWOY=AVW_O 은 학습과 구현에는 편하지만, “이 head가 실제로 무엇을 하는가?” 를 이해하기 어렵습니다. 저자들은 Transformer를 “token…
-

* Circuit Breaking: Removing Model Behaviors with Targeted Ablation (ArXiv 2023)
이 논문은 “모델의 특정 행동(behavior)만 제거할 수 있는가?” 라는 질문을 다룬다. 기존에는 Fine-tuning, RLHF, Model Editing 등이 주로 weight를 수정했는데, 이 논문은 훨씬 Mechanistic Interpretability 관점에서 접근한다. 핵심 아이디어는: “나쁜 행동을 만드는 circuit 전체를 찾는 대신, 그 circuit을 끊어버리는 최소 edge cut을 찾자.” 이다. 1. 문제 정의 논문은 “behavior removal”을 다음과 같이 정의한다. 모델…
-

* IPE: Isolating Path Effects for Improving Latent Circuit Identification (BlackboxNLP 2025)
아래 논문은 IPE: Isolating Path Effects for Improving Latent Circuit Identification입니다. 핵심은 기존 circuit discovery가 edge 단위로 중요도를 계산하는 반면, 이 논문은 입력 임베딩 → 중간 컴포넌트들 → 최종 logits까지 이어지는 전체 computational path의 효과를 직접 분리해서 평가한다는 점입니다. 1. 문제의식 기존 방법들, 예를 들어 Activation Patching, Edge Activation Patching, ACDC, EAP는 보통 특정…
-

* Circuit Component Reuse Across Tasks in Transformer Language Models (ICLR 2024)
논문: “Circuit Component Reuse Across Tasks in Transformer Language Models” (ICLR 2024) 1. 핵심 주장 이 논문은 Transformer LM 내부의 circuit component가 특정 task 전용이 아니라, 서로 다른 task에서도 재사용될 수 있다는 것을 보인다. 저자들은 두 task를 비교한다. Task 요구 행동 IOI: Indirect Object Identification 문장에서 indirect object 이름을 예측 Colored Objects 문맥에 나온…
-

* Finding Neurons in a Haystack: Case Studies with Sparse Probing (ArXiv 2023)
이 논문은 **“LLM 내부에서 특정 개념(feature)이 몇 개의 뉴런에 의해 표현되는가?”**를 체계적으로 분석한 연구이다. 특히 기존 probing 연구를 확장하여 Sparse Probe를 사용함으로써 특정 feature와 관련된 뉴런을 매우 정밀하게 찾고, 이를 통해 monosemantic neuron, polysemantic neuron, superposition 현상을 실증적으로 분석한다. 1. 연구 배경 Mechanistic Interpretability 분야에서는 오래전부터 다음 질문이 존재했다. “특정 뉴런 하나가 하나의 의미(feature)를…
-

** Function Vectors in Large Language Models (ICLR 2024)
논문: Function Vectors in Large Language Models, ICLR 2024. 핵심은 ICL prompt가 유도한 “작업 함수”가 LLM 내부의 특정 attention head 출력들의 합으로 벡터화되어 있으며, 이 벡터를 다른 문맥에 삽입하면 모델이 해당 작업을 수행한다는 주장입니다. 1. 핵심 아이디어 논문은 LLM이 few-shot ICL을 할 때 단순히 예시를 복사하거나 표면 패턴을 따르는 것이 아니라, 예시들로부터 “입력→출력 함수”…
-
* Interpretability Analysis of Arithmetic In-Context Learning in Large Language Models (EMNLP 2025)
이 논문은 “LLM이 arithmetic ICL(In-Context Learning)을 할 때 실제로 무엇을 배우는가?” 를 mechanistic interpretability 관점에서 분석한 연구입니다. 특히 기존 연구가 주로 2-operand arithmetic (a+b) 를 분석한 반면, 본 논문은 3-operand arithmetic (a+b+c) 를 대상으로 합니다. 논문의 핵심 결론은 다음 한 문장으로 요약됩니다. LLM은 ICE(In-Context Example)의 산술적 정답을 배우기보다는 ICE의 패턴(format, structure) 을 학습하여 문제를…
-

* On Relation-Specific Neurons in Large Language Models (EMNLP 2025)
이 논문은 **“LLM 내부에 특정 사실(fact)을 저장하는 neuron이 아니라, 특정 관계(relation) 자체를 처리하는 neuron이 존재하는가?”**를 분석한 연구입니다. 기존 연구의 Knowledge Neuron은 (NVIDIA, CEO, Jensen Huang) 이라는 사실 전체를 저장하는 뉴런을 찾으려 했습니다. 반면 이 논문은 CEO 관계 자체를 담당하는 neuron 즉, 처럼 entity가 달라도 공통적으로 활성화되는 Relation-Specific Neuron (RelSpec Neuron) 이 존재하는지를 탐구합니다. …
-

Towards Best Practices of Activation Patching in Language Models: Metrics and Methods (ICLR 2024)
이 논문은 activation patching(= causal tracing/interchange intervention)의 실험 설정(hyperparameter) 이 interpretability 결과를 얼마나 크게 바꾸는지를 체계적으로 분석한 논문입니다. 핵심 메시지는 다음과 같습니다. “Activation patching 자체보다도,어떤 corruption method를 쓰고 어떤 metric으로 측정하느냐가localization/circuit discovery 결과를 크게 바꾼다.” 즉, 기존 mechanistic interpretability 논문들의 결과가 설정에 민감할 수 있으며, activation patching에도 “best practice”가 필요하다는 주장입니다. 1. Activation Patching이란?…
-

* Mechanistic Understanding and Mitigation of Language Confusion in English-Centric Large Language Models (Findings of EMNLP 2025)
1. 문제 정의: Language Confusion 핵심 현상 유형 예시 (논문 Fig.1): 2. 핵심 개념: Confusion Point (CP) 정의 –> 매우 중요한 insight: 실험 결과 Table 2 (page 4) –> language confusion은 “local failure”임을 보여줌 3. Mechanistic Insight (핵심 기여) 3.1 Layer-wise 분석 (TunedLens 사용) 관찰 (page 5, Fig.2) 결론 language confusion =“latent → surface language…
-
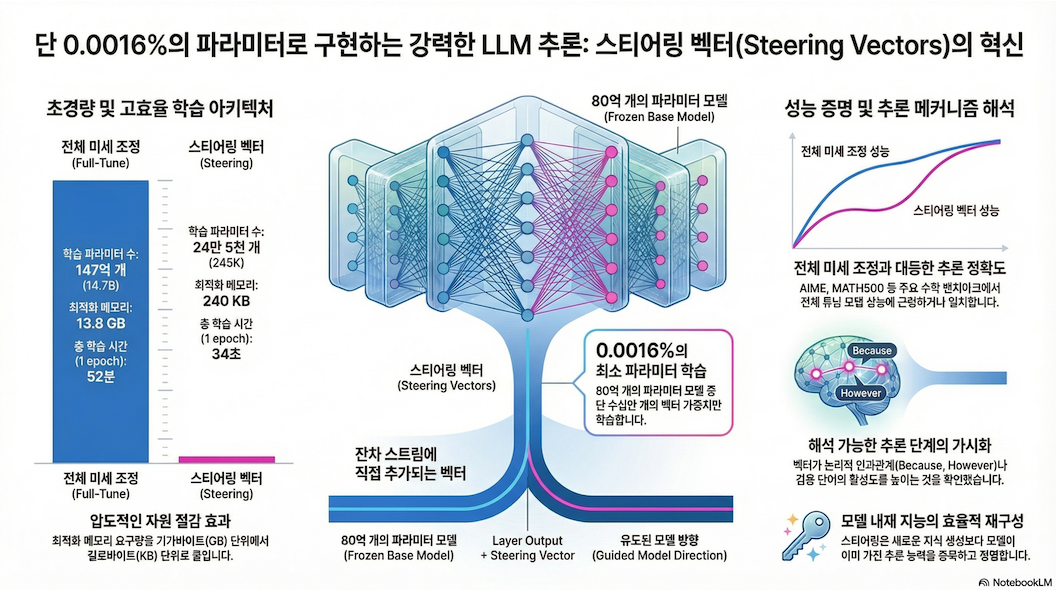
* Steering LLM Reasoning Through Bias-Only Adaptation (ArXiv 2025)
1. 핵심 아이디어 (TL;DR) 이 논문의 핵심은 매우 명확합니다: “LLM의 reasoning 능력은 매우 적은 파라미터 (layer별 vector)만 학습해도 충분히 끌어낼 수 있다.” 즉, reasoning은 “새로 학습되는 능력”이 아니라 이미 존재하는 능력을 특정 방향으로 “증폭(amplify)”하는 것이라는 강한 근거 제공 2. 방법론 (Methodology) 2.1 Steering Vector 정의 각 transformer layer ℓ에 대해: 다음과 같이 단순히 더함: hℓ,t←hℓ,t+sℓh_{\ell,t}…
-

** Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms (COLM 2024)
다음 논문은 **mechanistic interpretability (특히 circuits 분석)**에서 매우 중요한 문제를 짚는 연구입니다: “Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms” (COLM 2024) 1. 핵심 문제의식 (Why this paper matters) 기존 circuit 연구의 암묵적 가정: “찾은 circuit이 ground-truth circuit과 **overlap이 크면 → 잘 찾은 것” 하지만 이 논문은 이를 정면으로 반박합니다: 핵심…
-

* Towards Faithful Natural Language Explanations: A Study Using Activation Patching in LLMs (EMNLP 2025)
다음 논문은 LLM의 Natural Language Explanation (NLE)의 “faithfulness(충실성)”을 내부 causal 관점에서 측정하는 매우 중요한 메커니즘 기반 연구입니다 1. 핵심 문제 정의 문제 LLM은 CoT 등으로 **그럴듯한 설명(plausible explanation)**을 잘 생성하지만, 이 설명이 실제 내부 reasoning을 반영하는지 (faithful) 는 별개 즉, Faithfulness 정의 논문은 다음 정의를 채택: “Explanation이 모델의 실제 reasoning process를 얼마나 정확히 반영하는가” 즉,…