[태그:] SAE
-

* Hierarchical Sparse Circuit Extraction from Billion-Parameter Language Models through Scalable Attribution Graph Decomposition (ArXiv 2026)
이 논문은 최근 Sparse Feature Circuit 계열(SAE, Transcoder, Edge Pruning, EAP) 연구들을 모두 조합하여 70B 규모 LLM까지 회로(circuit)를 추출할 수 있는 scalable framework를 제안한 논문입니다. 새로운 알고리즘을 실제 구현하여 대규모 실험으로 검증했다기보다는 기존 연구들을 조합한 프레임워크 제안 성격이 강합니다. 특히 일부 실험 수치(70B까지의 결과 등)는 공개 코드나 재현성 정보가 부족하여 실제 구현 여부를 신중하게 해석할…
-

*** Scalable Circuit Learning for Interpreting Large Language Models (ArXiv 2026)
아래 논문은 CircuitLasso라는 방법을 제안합니다. 핵심은 SAE feature 기반 circuit discovery를 intervention 없이 Lasso sparse regression으로 확장 가능하게 수행하는 것입니다. 1. 문제의식 기존 circuit discovery 방법들, 예를 들어 activation patching, EAP, EAP-IG, causal tracing은 edge나 node의 causal effect를 intervention으로 측정합니다. 문제는 두 가지입니다. 첫째, raw neuron은 polysemantic이라서 circuit을 찾더라도 해석이 어렵습니다. 둘째, SAE feature는…
-

** Learning Multi-Level Features with Matryoshka Sparse Autoencoders (ICML 2025)
이 논문은 최근 Sparse Autoencoder(SAE) 연구에서 **가장 중요한 문제인 “dictionary를 크게 만들면 오히려 feature quality가 나빠지는 현상”**을 해결하려는 논문입니다. 1. 연구 배경 기존 SAE는 dictionary size를 크게 만들수록 reconstruction은 좋아집니다. 예를 들어, dictionary를 계속 늘리면 activation reconstruction error는 감소합니다. 하지만 interpretability에서는 문제가 생깁니다. 논문에서는 이를 크게 3가지 pathology로 설명합니다. (1) Feature Splitting 원래 Punctuation 하나의…
-

** Sparse Feature Coactivation Reveals Causal Semantic Modules in Large Language Models (ArXiv 2025)
이 논문은 **Sparse Autoencoder(SAE)의 feature를 개별적으로 보는 것이 아니라, 여러 layer에서 함께(co-activation) 활성화되는 feature들의 집합(component)**을 찾아 semantic module로 해석하는 논문입니다. 기존의 circuit discovery처럼 복잡한 edge attribution(EAP, ACDC, Transcoder Circuit)을 수행하지 않고도 상당히 의미 있는 semantic module을 발견할 수 있다는 것이 핵심입니다. 1. 연구 배경 Mechanistic Interpretability에서는 크게 두 가지 흐름이 있다. (1) Circuit Discovery…
-

*** Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models (ICLR 2025)
이 논문은 최근 SAE(Sparse Autoencoder) 기반 해석가능성 연구와 Circuit Discovery 연구를 결합한 대표적인 논문이다. 기존 ACDC, Activation Patching, EAP 등의 circuit discovery는 attention head, neuron, MLP block 수준에서 회로를 찾았는데, 이들은 대부분 polysemantic해서 사람이 이해하기 어렵다. 본 논문의 핵심 아이디어는: “Circuit의 기본 단위를 neuron 대신 SAE feature로 바꾸자.” 즉, Neuron Circuit→Sparse Feature Circuit\text{Neuron Circuit}\rightarrow\text{Sparse Feature Circuit} 로 전환한…
-

** Improving LLM Reasoning through Interpretable Role-Playing Steering (Findings of EMNLP 2025)
논문 “Improving LLM Reasoning through Interpretable Role-Playing Steering” (Findings of EMNLP 2025) 은 역할 수행(role-playing) 기반 추론 강화 기법을 LLM 내부 표현 수준에서 해석 가능하게 제어하는 새로운 접근법을 제안합니다. 핵심은 Sparse Autoencoder(SAE) 로 모델 내부 활성화 패턴을 분석하고, 역할 수행 시 활성화되는 잠재 특징(latent features)을 추출하여 Residual Stream에 주입(steering) 함으로써 모델의 “역할 일관적(reasoning-consistent)” 사고를 유도하는…
-
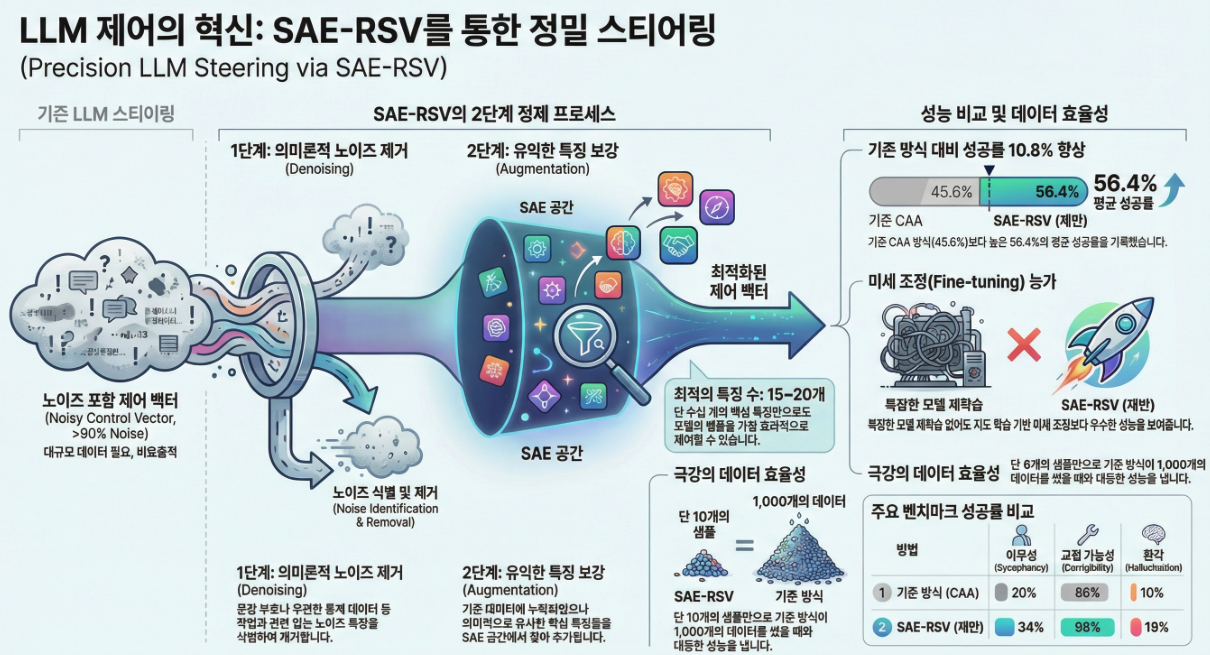
** Enhancing LLM Steering through Sparse Autoencoder-based Vector Refininement (ArXiv 2025)
아래에서는 「Enhancing LLM Steering through Sparse Autoencoder-based Vector Refininement (SAE-RSV)」 논문의 관련연구, 방법론, 실험 결과를 핵심만 구조적으로 정리해 설명합니다. 1. 관련연구 (Related Work) (1) Steering / Difference-in-Means 계열 (2) Sparse Autoencoder(SAE) 기반 Steering (3) 본 논문의 포지션 2. 방법론 (Methodology) 논문은 **SAE-RSV (Sparse Autoencoder-based Refinement of Steering Vector)**라는 2-단계 정제 프레임워크를 제안합니다. (1) 기본 Steering…
-

* Latent Inter-User Difference Modeling for LLM Personalization (EMNLP 2025)
아래에서는 **EMNLP 2025 논문 “Latent Inter-User Difference Modeling for LLM Personalization”**을 중심으로 관련 연구, 방법론, 실험 결과를 연구 흐름 관점에서 정리해 설명합니다. (설명은 논문 전체 내용을 종합한 요약입니다) 1. 관련 연구 (Related Work) (1) LLM 개인화의 주류: Memory-Retrieval Paradigm (2) Inter-User Difference를 명시적으로 다룬 연구 (3) Latent-Space Personalization –> 이 논문의 핵심 포지션 “Inter-user difference는…
-
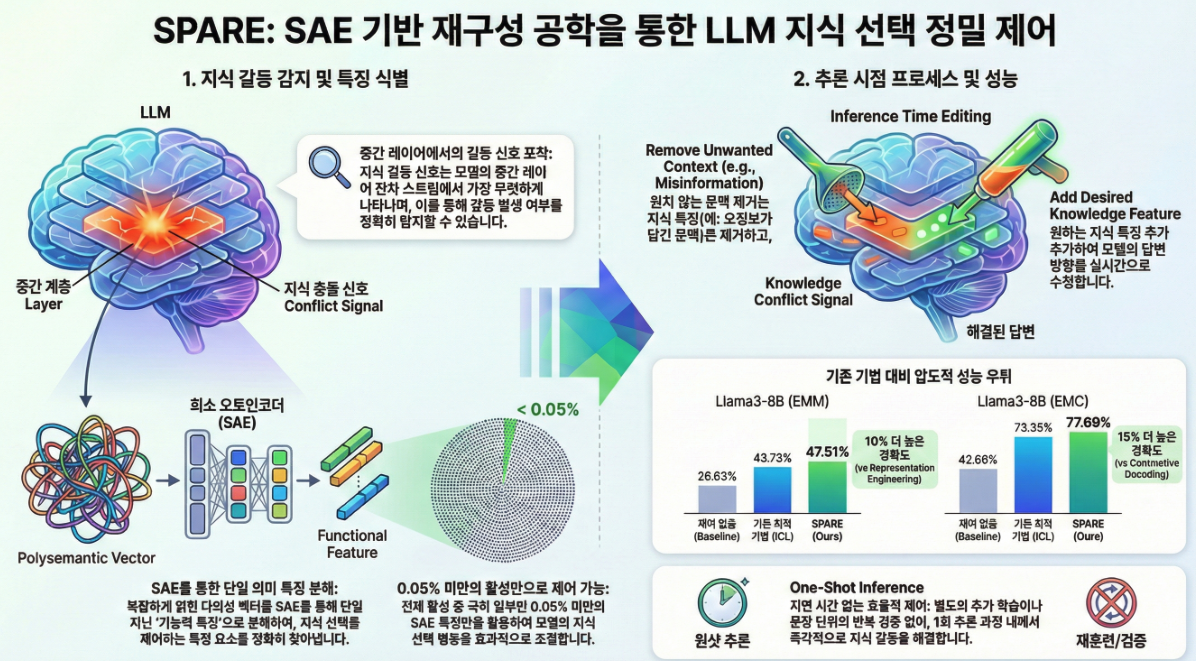
*** Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering (NAACL 2025)
논문 **“Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering” (NAACL 2025)**은대형 언어모델(LLM)이 내부 파라미터(기억된 지식, parametric knowledge)와 입력 문맥(contextual knowledge) 간의 지식 충돌(knowledge conflict) 상황에서 어떤 지식을 사용할지 조절하는 방법을 제안한 연구입니다. 핵심 내용은 다음과 같습니다. 1. 문제 배경: Knowledge Conflict LLMs는 내부적으로 방대한 사실 지식을 학습하지만,새로운 컨텍스트(예: 검색 결과, 최신 정보)가 주어지면 기존 지식과 충돌할 수…
-
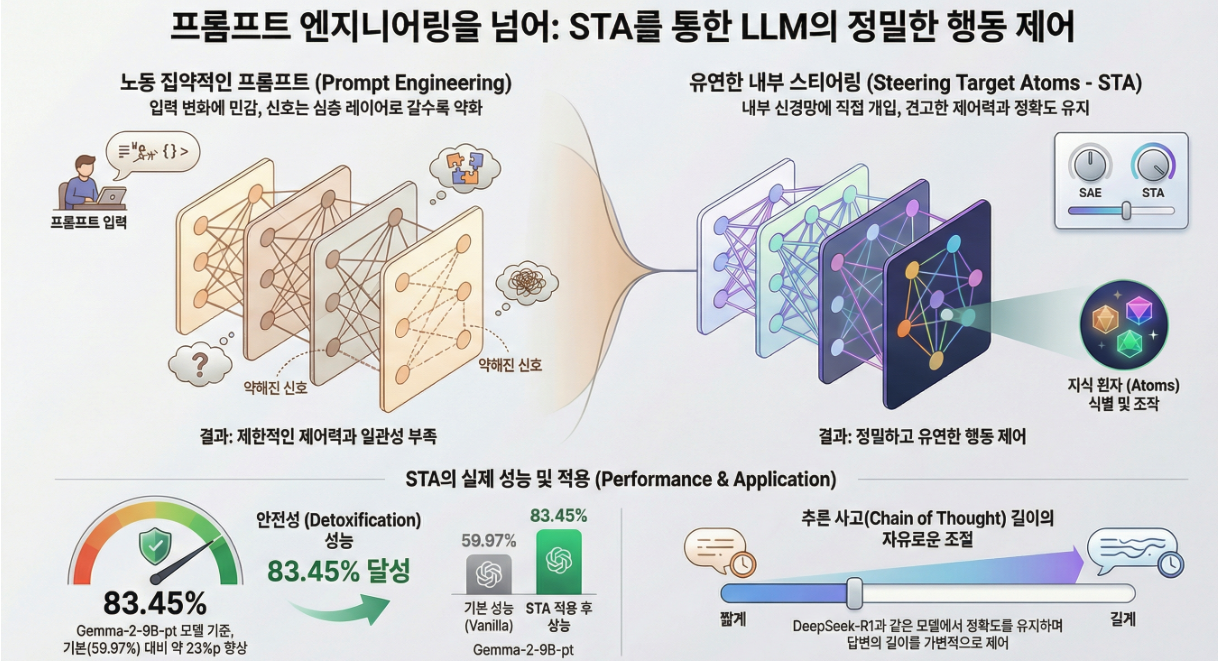
*** Beyond Prompt Engineering: Robust Behavior Control in LLMs via Steering Target Atoms (ACL 2025)
연구 배경 제안 방법: Steering Target Atoms (STA) 1. SAE 기반 표현 분해 모델의 은닉 상태 hh 를 SAE를 통해 고차원, 희소 공간으로 투영합니다. 복원(reconstruction)은 여기서 각 row of WdecW_{dec} 는 하나의 atom direction을 나타냅니다.즉, 모델 표현을 구성하는 기본 단위입니다. 2. Target Atom 식별 (Identify Target Atoms) positive(예: 안전한 응답)과 negative(예: 위험한 응답) 샘플의 SAE 활성도를 비교하여 활성…