[태그:] Circuit Discovery
-

* Hierarchical Sparse Circuit Extraction from Billion-Parameter Language Models through Scalable Attribution Graph Decomposition (ArXiv 2026)
이 논문은 최근 Sparse Feature Circuit 계열(SAE, Transcoder, Edge Pruning, EAP) 연구들을 모두 조합하여 70B 규모 LLM까지 회로(circuit)를 추출할 수 있는 scalable framework를 제안한 논문입니다. 새로운 알고리즘을 실제 구현하여 대규모 실험으로 검증했다기보다는 기존 연구들을 조합한 프레임워크 제안 성격이 강합니다. 특히 일부 실험 수치(70B까지의 결과 등)는 공개 코드나 재현성 정보가 부족하여 실제 구현 여부를 신중하게 해석할…
-

*** Scalable Circuit Learning for Interpreting Large Language Models (ArXiv 2026)
아래 논문은 CircuitLasso라는 방법을 제안합니다. 핵심은 SAE feature 기반 circuit discovery를 intervention 없이 Lasso sparse regression으로 확장 가능하게 수행하는 것입니다. 1. 문제의식 기존 circuit discovery 방법들, 예를 들어 activation patching, EAP, EAP-IG, causal tracing은 edge나 node의 causal effect를 intervention으로 측정합니다. 문제는 두 가지입니다. 첫째, raw neuron은 polysemantic이라서 circuit을 찾더라도 해석이 어렵습니다. 둘째, SAE feature는…
-

** Data-driven Circuit Discovery for Interpretability of Language Models (ArXiv 2026)
이 논문의 핵심 메시지는 매우 간단합니다. 기존 Circuit Discovery는 “task → 하나의 circuit”이라는 가정을 깔고 있는데, 실제 LLM은 같은 task도 여러 메커니즘으로 풀 수 있다. 따라서 기존 방법은 task circuit이 아니라 dataset-specific circuit을 찾고 있으며, 심지어 서로 다른 메커니즘을 하나의 circuit에 섞어버릴 수 있다. 이를 해결하기 위해 Data-driven Circuit Discovery (DCD) 를 제안한다. 1.…
-

*** Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models (ICLR 2025)
이 논문은 최근 SAE(Sparse Autoencoder) 기반 해석가능성 연구와 Circuit Discovery 연구를 결합한 대표적인 논문이다. 기존 ACDC, Activation Patching, EAP 등의 circuit discovery는 attention head, neuron, MLP block 수준에서 회로를 찾았는데, 이들은 대부분 polysemantic해서 사람이 이해하기 어렵다. 본 논문의 핵심 아이디어는: “Circuit의 기본 단위를 neuron 대신 SAE feature로 바꾸자.” 즉, Neuron Circuit→Sparse Feature Circuit\text{Neuron Circuit}\rightarrow\text{Sparse Feature Circuit} 로 전환한…
-

** Transcoders Find Interpretable LLM Feature Circuits (NeurIPS 2024)
이 논문은 최근 Mechanistic Interpretability에서 매우 중요한 논문 중 하나입니다. 한 줄 요약하면: SAE가 “해석 가능한 feature”를 찾는 데는 성공했지만, feature들 사이의 circuit을 분석하기는 어려웠다.Transcoder를 사용하면 MLP를 sparse feature graph로 직접 근사할 수 있고, feature-level circuit을 input-invariant하게 분석할 수 있다. 특히 이후의 계열 연구에 큰 영향을 주었습니다. 1. 문제의식 기존 Circuit Discovery의 문제 Transformer 회로를…
-

Dictionary Learning Improves Patch-Free Circuit Discovery (ArXiv 2024)
1. 논문 핵심 이 논문은 Sparse Dictionary Learning/SAE로 얻은 monosemantic feature들 사이의 circuit을 activation patching 없이 발견하는 방법을 제안한다. 대상 모델은 Othello-GPT, 즉 오델로 다음 합법 수 예측을 학습한 6-layer, hidden size 128의 작은 decoder-only Transformer이다. 핵심 주장은 다음이다: residual stream에 write하는 모든 module output, 즉 embedding, attention output, MLP output을 dictionary feature로 분해하면, logit이나…
-

*** RelP: Faithful and Efficient Circuit Discovery in Language Models via Relevance Patching (ArXiv 2025)
논문 개요 이 논문은 기존 Activation Patching과 Attribution Patching의 장단점을 결합하려는 논문입니다. 핵심 아이디어는 다음과 같습니다. Attribution Patching의 gradient 항을 Layer-wise Relevance Propagation, 즉 LRP 기반 propagation coefficient로 대체하면, Activation Patching에 더 가깝게 causal effect를 근사하면서도 계산 비용은 거의 그대로 유지할 수 있다. 논문에서 제안하는 방법 이름은 Relevance Patching, RelP입니다. 저자들은 RelP가 Activation Patching보다 훨씬…
-

*** Weight Patching: Toward Source-Level Mechanistic Localization in LLMs (ArXiv 2026)
이 논문의 핵심 아이디어는 다음 한 문장으로 요약할 수 있습니다. 기존 Mechanistic Interpretability가 “어디에서 신호가 보이는가?”(activation)를 찾았다면, 이 논문은 “그 능력이 실제로 어느 파라미터에 저장되어 있는가?”(weight)를 찾으려 한다. 1. 왜 새로운 방법이 필요한가? 기존 Circuit Discovery 계열: 등은 모두 activation 공간에서 동작한다. 예를 들어: Activation Patching을 하면 → Head C가 중요하다고 판단 하지만 실제로는…
-

* A Mathematical Framework for Transformer Circuits (Transformer Circuits 2021)
이 논문은 오늘날 Mechanistic Interpretability 분야의 출발점 중 하나로 평가받습니다. 특히 이후의 등의 연구들이 사실상 이 논문의 수학적 프레임워크 위에서 발전되었습니다. 1. 논문의 핵심 질문 Transformer 내부를 회로(circuit)처럼 해석할 수 있는가? 기존 Transformer 수식: Q=XWQQ=XW_Q K=XWKK=XW_K V=XWVV=XW_V A=softmax(QKT)A=\text{softmax}(QK^T) Y=AVWOY=AVW_O 은 학습과 구현에는 편하지만, “이 head가 실제로 무엇을 하는가?” 를 이해하기 어렵습니다. 저자들은 Transformer를 “token…
-

* Circuit Breaking: Removing Model Behaviors with Targeted Ablation (ArXiv 2023)
이 논문은 “모델의 특정 행동(behavior)만 제거할 수 있는가?” 라는 질문을 다룬다. 기존에는 Fine-tuning, RLHF, Model Editing 등이 주로 weight를 수정했는데, 이 논문은 훨씬 Mechanistic Interpretability 관점에서 접근한다. 핵심 아이디어는: “나쁜 행동을 만드는 circuit 전체를 찾는 대신, 그 circuit을 끊어버리는 최소 edge cut을 찾자.” 이다. 1. 문제 정의 논문은 “behavior removal”을 다음과 같이 정의한다. 모델…
-

* IPE: Isolating Path Effects for Improving Latent Circuit Identification (BlackboxNLP 2025)
아래 논문은 IPE: Isolating Path Effects for Improving Latent Circuit Identification입니다. 핵심은 기존 circuit discovery가 edge 단위로 중요도를 계산하는 반면, 이 논문은 입력 임베딩 → 중간 컴포넌트들 → 최종 logits까지 이어지는 전체 computational path의 효과를 직접 분리해서 평가한다는 점입니다. 1. 문제의식 기존 방법들, 예를 들어 Activation Patching, Edge Activation Patching, ACDC, EAP는 보통 특정…
-

* Circuit Component Reuse Across Tasks in Transformer Language Models (ICLR 2024)
논문: “Circuit Component Reuse Across Tasks in Transformer Language Models” (ICLR 2024) 1. 핵심 주장 이 논문은 Transformer LM 내부의 circuit component가 특정 task 전용이 아니라, 서로 다른 task에서도 재사용될 수 있다는 것을 보인다. 저자들은 두 task를 비교한다. Task 요구 행동 IOI: Indirect Object Identification 문장에서 indirect object 이름을 예측 Colored Objects 문맥에 나온…
-

** Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms (COLM 2024)
다음 논문은 **mechanistic interpretability (특히 circuits 분석)**에서 매우 중요한 문제를 짚는 연구입니다: “Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms” (COLM 2024) 1. 핵심 문제의식 (Why this paper matters) 기존 circuit 연구의 암묵적 가정: “찾은 circuit이 ground-truth circuit과 **overlap이 크면 → 잘 찾은 것” 하지만 이 논문은 이를 정면으로 반박합니다: 핵심…
-
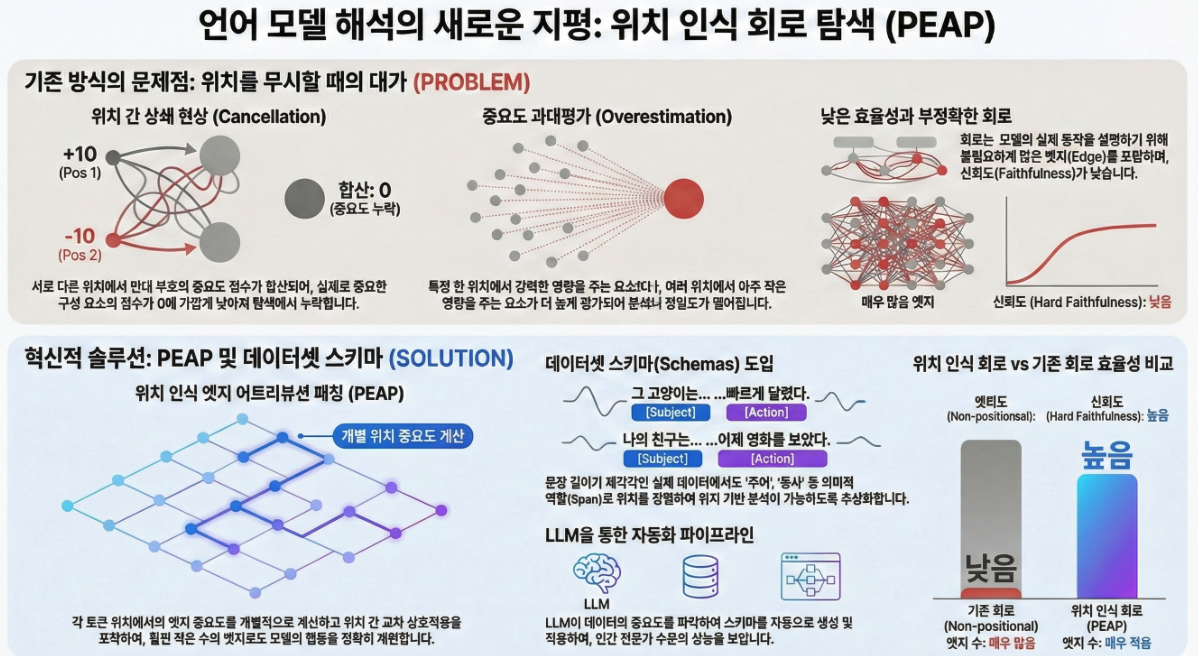
*** Position-aware Automatic Circuit Discovery (ACL 2025)
아래는 ACL 2025 논문 “Position-aware Automatic Circuit Discovery (PEAP)” 전체 내용을 기반으로 한 논문 설명입니다. Position-aware Automatic Circuit Discovery — 논문 전체 설명 1. 논문 문제의식 (Why?) 기존 자동 circuit discovery 기법(EAP, direct patching 등)은 “position-invariant” 가정을 한다. 즉, 이로 인해 이 문제를 해결하기 위해 저자들은 **“Position-aware Edge Attribution Patching (PEAP)”**을 제안한다. 2. 제안 핵심…
-
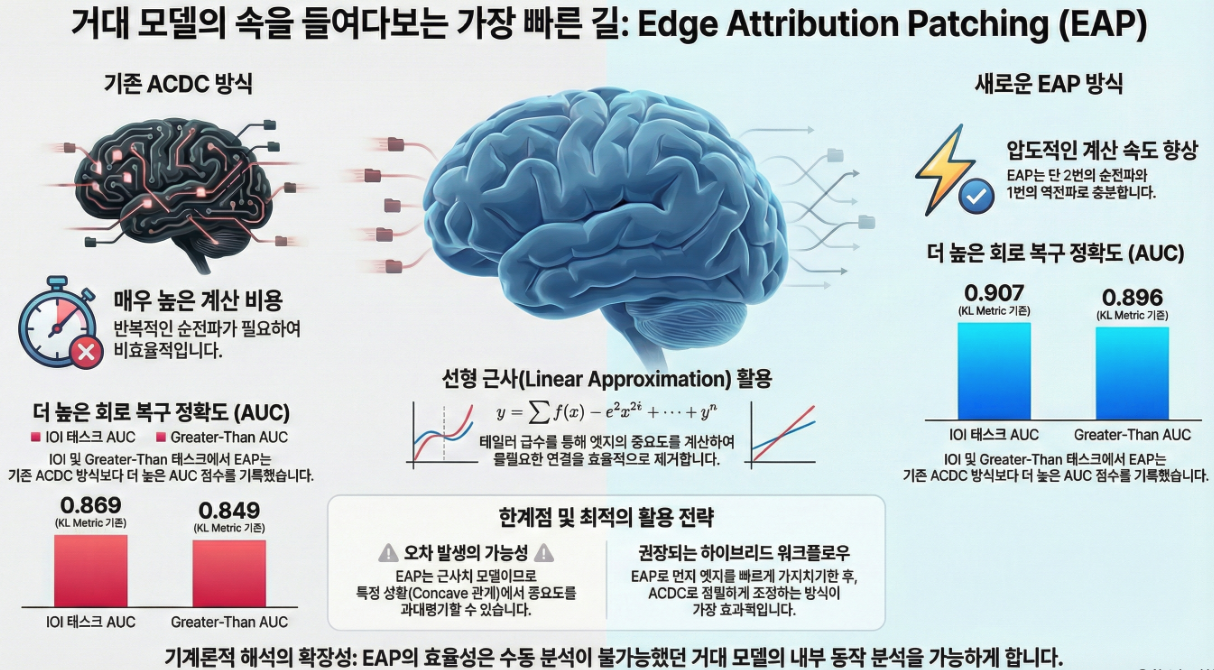
*** Attribution Patching Outperforms Automated Circuit Discovery (BlackboxNLP 2024)
아래는 **BlackboxNLP 2024 논문 〈Attribution Patching Outperforms Automated Circuit Discovery〉**의 핵심 내용을 구조적으로 정리한 상세 설명입니다. 1. 논문의 문제의식 (Introduction) 메커니스틱 인터프리터빌리티의 핵심 목표는 LLM 내부에서 특정 작업(Task)을 수행하는 서브네트워크(circuit)를 자동으로 찾아내는 것이다. 기존 자동화된 방법의 대표는 **ACDC (Automated Circuit Discovery)**로, 각 *edge(노드 간의 activation flow)*가 해당 작업에 얼마나 기여하는지 activation patching을 반복적으로 수행해 측정한다.…
-
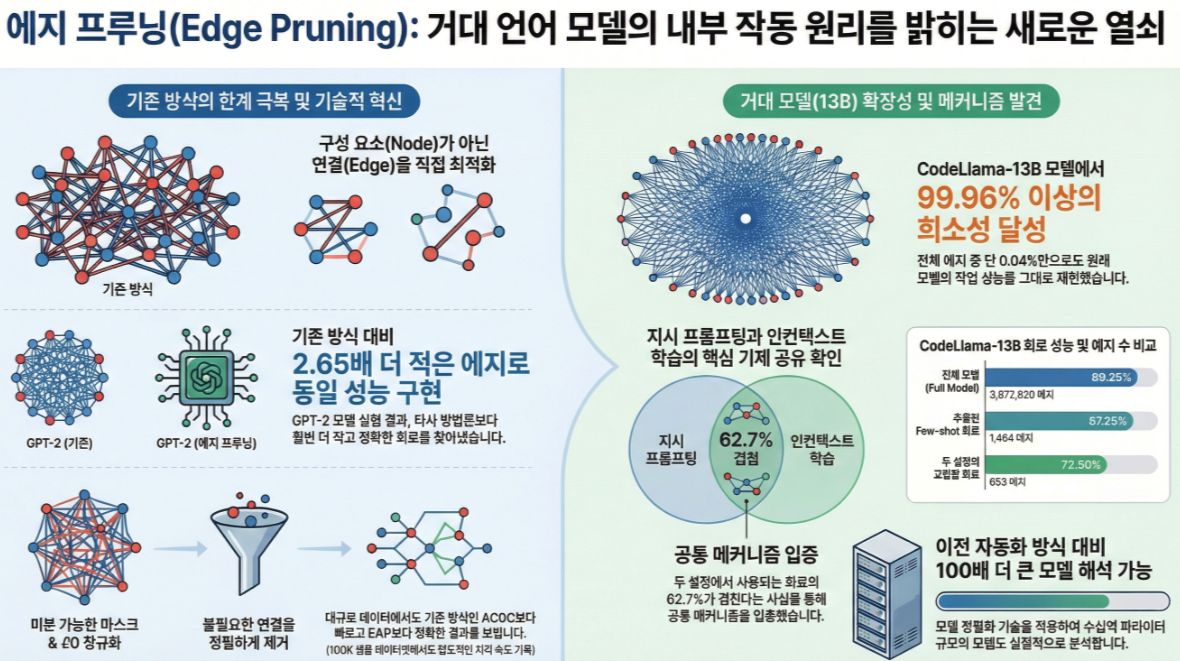
*** Finding Transformer Circuits with Edge Pruning (NeurIPS 2024)
아래는 논문 **“Finding Transformer Circuits with Edge Pruning (NeurIPS 2024)”**의 핵심 내용을 직관적으로, 기존 ACDC/EAP과의 차이를 중심으로, 수식·개념까지 포함해 정리한 설명입니다. 1. 연구 배경: 왜 Edge Pruning인가? Transformer의 동작을 해석하려면 모델 내부에서 특정 기능을 수행하는 회로(circuit) 를 찾아야 한다. 기존 자동 회로 추출 방식에는 두 가지 대표적 접근이 있다: (1) ACDC (2023) (2) EAP (Edge…
-
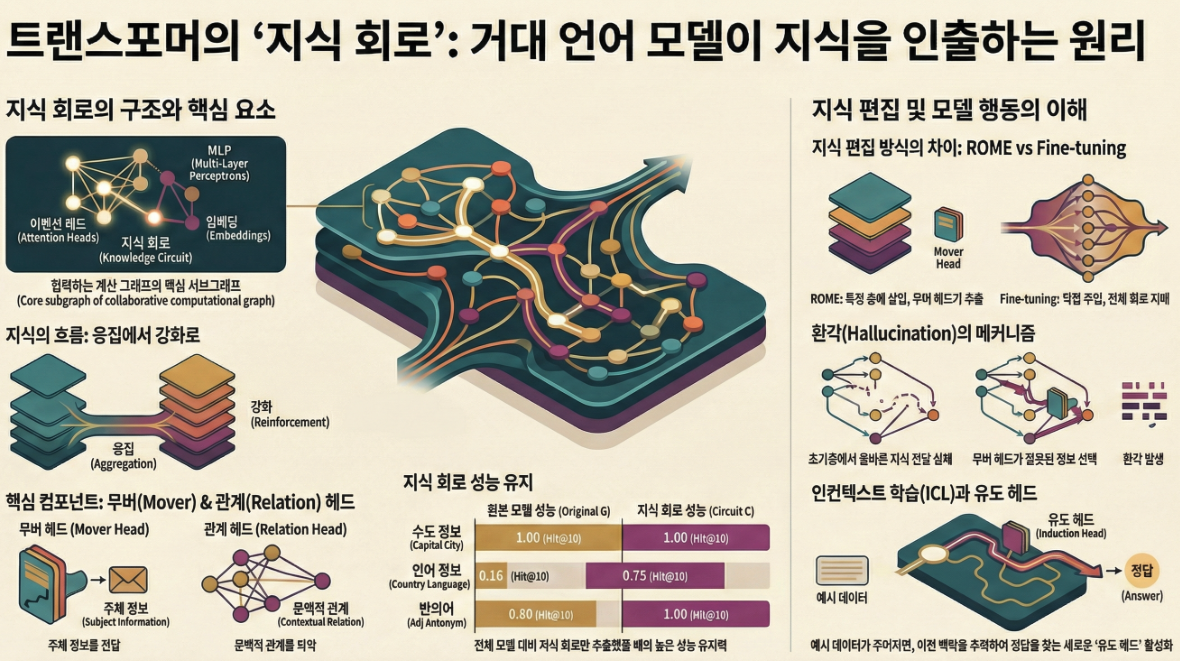
*** Knowledge Circuits in Pretrained Transformers (NeurIPS 2024)
다음은 NeurIPS 2024에 발표된 “Knowledge Circuits in Pretrained Transformers” 논문의 주요 내용 요약입니다. 이 논문은 LLM 내부의 지식 저장 메커니즘을 **회로(circuit)**의 관점에서 새롭게 분석한 연구입니다. 1. 연구 배경 2. Knowledge Circuit의 정의 3. 연구 방법론 (1) Knowledge Circuit 탐색 (2) 모델 및 데이터 4. 주요 실험 결과 (1) Knowledge Circuit의 성능 Knowledge Type Original (Hit@10)…
-
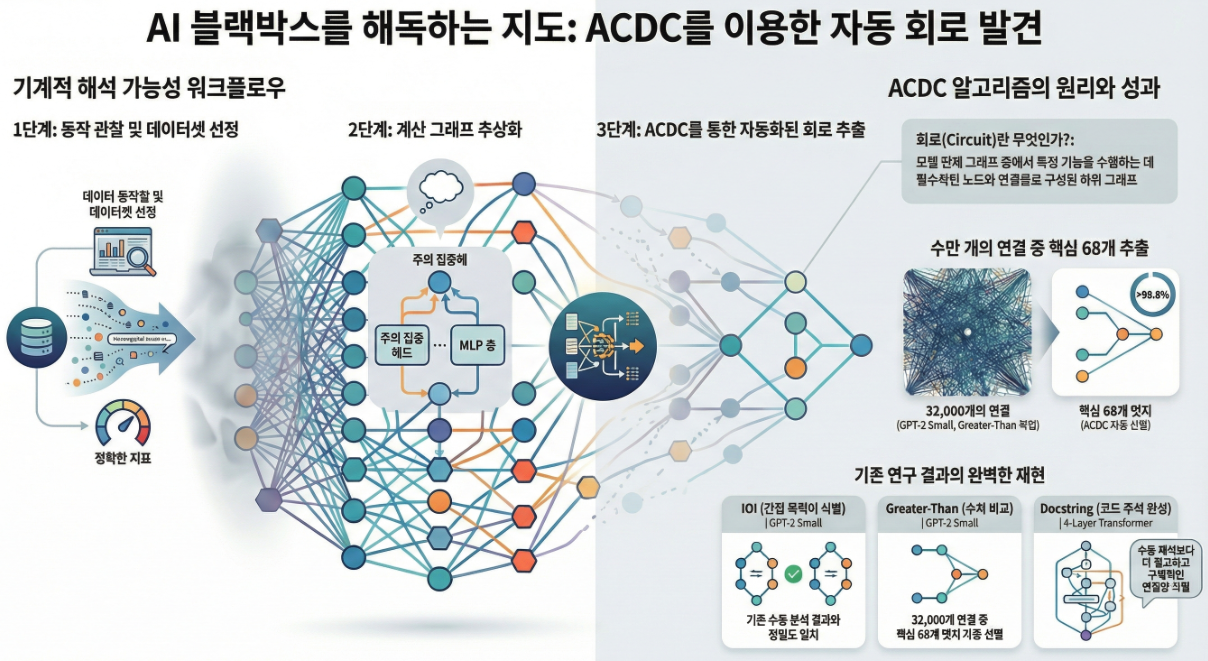
*** Towards Automated Circuit Discovery for Mechanistic Interpretability (NeurIPS 2023)
아래는 **“Towards Automated Circuit Discovery for Mechanistic Interpretability (NeurIPS 2023)”**의 핵심 내용을 정리한 설명입니다. 논문의 목적 Transformer 기반 LLM은 뛰어난 성능에도 불구하고 내부 동작이 블랙박스처럼 보입니다. 메커니스틱 인터프리터빌리티 연구는 내부 컴포넌트(Attention Head, MLP 등)가 구체적으로 어떤 알고리즘을 수행하는지 밝히려고 하지만, 현재는 사람이 일일이 수작업으로 분석하는 방식이라 확장성이 떨어집니다. 이 논문은 그 과정을 체계화하고 특히 회로(circuit)를…