LLM 논문에 관한 블로그입니다.
-

** Neuron-Level Knowledge Attribution in Large Language Models (EMNLP 2024)
아래는 EMNLP 2024 논문 “Neuron-Level Knowledge Attribution in Large Language Models” 의 핵심 내용을 정리한 설명입니다. 논문 개요 이 논문은 LLM 내부에서 특정 지식(facts)이 어떤 뉴런(neuron)에 저장되는지 정량적으로 찾아내는 뉴런 수준(neuron-level) attribution 방법을 제안합니다. 피쳐 단위(head, layer)보다 더 미세한 수준입니다. 기존 기법은 논문은 이를 해결하기 위해: 을 수행합니다. 배경 (왜 뉴런 수준인가?) 이전 연구들(Geva et…
-

Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering (Arxiv 2024)
논문 “Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering” (Pochinkov et al., 2024) 은 Transformer 기반 모델의 주의(attention) 뉴런 해석과 절제(ablation) 방법을 체계적으로 비교하고, 새로운 방식인 **Peak Ablation (정점 중심 절제)**을 제안한 연구입니다. 아래에 핵심 내용을 구조적으로 정리했습니다. 1. 연구 배경 및 문제의식 기존 절제 방식: 2. 제안 개념: Peak Ablation…
-
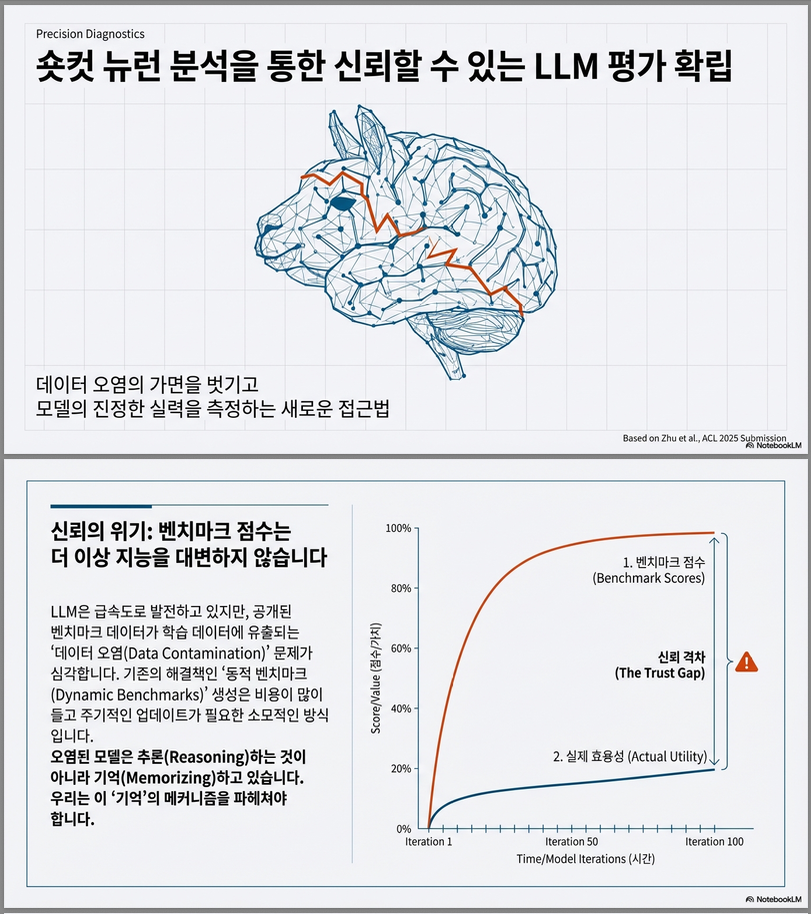
* Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis (ACL 2025)
논문 “Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis” (ACL 2025) 은 데이터 오염(data contamination) 문제로 인해 LLM 평가의 신뢰성이 손상되는 문제를 해결하기 위해, 모델 내부의 “지름길 뉴런(shortcut neurons)”을 분석하고 억제함으로써 공정하고 신뢰할 수 있는 평가를 수행하는 방법을 제안한 연구입니다. 아래는 주요 내용 요약입니다. 연구 배경 및 문제의식 따라서 이 논문은 모델 내부의 원인, 즉…
-

* Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps (EMNLP 2024)
다음 논문은 “Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps” (EMNLP 2024) 입니다 . 이 논문은 **LLM의 contextual hallucination(문맥 기반 환각)**을 attention map만을 사용해 탐지하고, decoding 단계에서 이를 완화하는 방법을 제안합니다. 1. 문제 정의: Contextual Hallucination 논문은 환각을 두 종류로 구분합니다: 이 논문은 **후자(context-grounded setting)**에 집중합니다. 대표 예:…
-
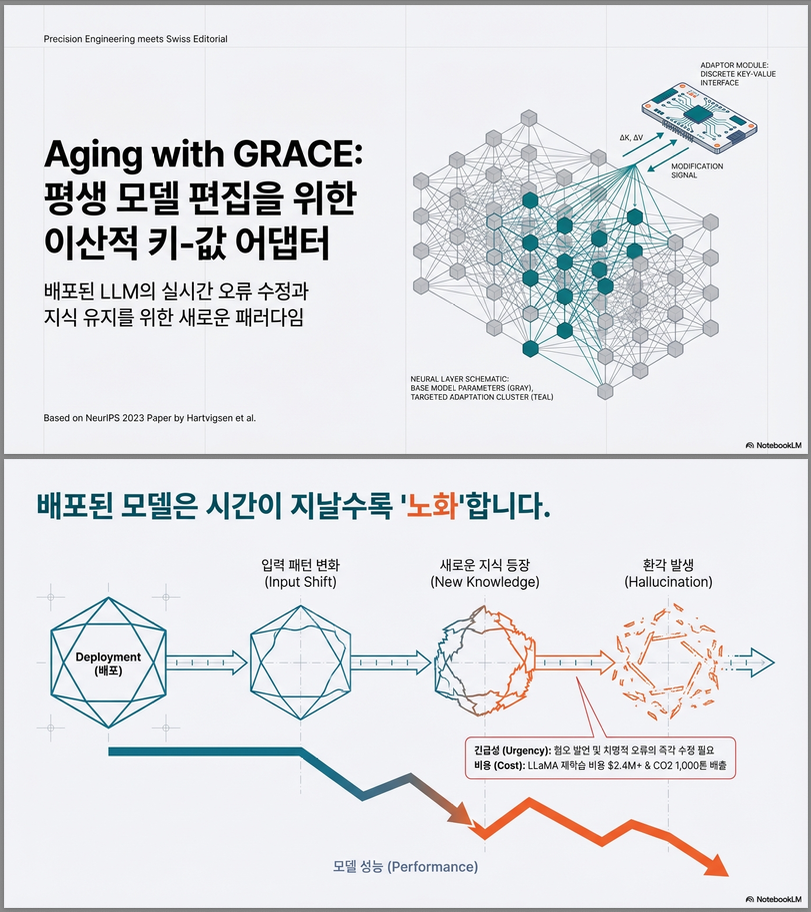
* Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors (NeurIPS 2023)
본 논문은 대규모 사전학습 모델을 재학습 없이, 수천 번 순차적으로(edit sequentially) 수정하는 방법을 제안합니다. 핵심은 모델 가중치를 건드리지 않고, 특정 레이어에 discrete key-value adaptor (codebook) 를 추가하여 “국소적 수정(spot-fix)”을 수행하는 것입니다 . 1. 문제 배경: 왜 Lifelong Model Editing이 필요한가? 배포된 LLM은 시간이 지나면서: 와 같은 문제가 발생합니다 . 그러나: → 따라서 문제는: 수백~수천 번…
-

** MicroEdit: Neuron-level Knowledge Disentanglement and Localization in Lifelong Model Editing (EMNLP 2025)
논문 “MicroEdit: Neuron-level Knowledge Disentanglement and Localization in Lifelong Model Editing” (EMNLP 2025) 은 대형 언어모델(LLM)의 지속적인 지식 편집(lifelong model editing) 문제를 다루며, 기존 방법들이 가지는 두 가지 핵심 한계를 정량적으로 분석하고, 이를 해결하기 위해 Sparse Autoencoder(SAE) 기반의 뉴런 단위 최소 편집(neuron-level minimal editing) 기법을 제안합니다 . 1. 연구 배경 및 문제점 LLM은 대규모 사전학습…
-
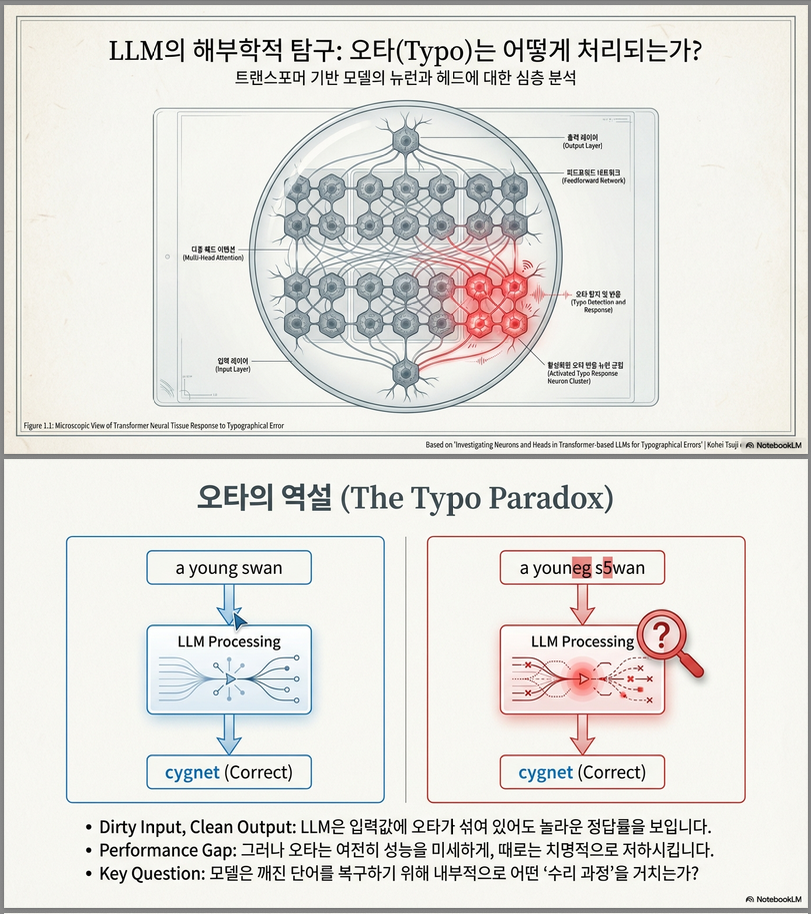
*** Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors (EMNLP 2025)
다음은 **EMNLP 2025 논문 “Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors”**에 대한 핵심 정리입니다. 연구 동기 LLM 입력에는 종종 **오타(typo)**가 포함되며, 모델은 때때로 이를 내부적으로 보정해 올바른 의미를 복원합니다. 그러나 경우에 따라 오타는 모델의 성능 저하를 유발합니다. 이 연구는: 어떤 뉴런(neurons)과 어떤 어텐션 헤드(attention heads)가 오타를 감지·보정하는지 밝혀내는 것이 목표입니다. 주요 연구…
-

** Improving LLM Reasoning through Interpretable Role-Playing Steering (Findings of EMNLP 2025)
논문 “Improving LLM Reasoning through Interpretable Role-Playing Steering” (Findings of EMNLP 2025) 은 역할 수행(role-playing) 기반 추론 강화 기법을 LLM 내부 표현 수준에서 해석 가능하게 제어하는 새로운 접근법을 제안합니다. 핵심은 Sparse Autoencoder(SAE) 로 모델 내부 활성화 패턴을 분석하고, 역할 수행 시 활성화되는 잠재 특징(latent features)을 추출하여 Residual Stream에 주입(steering) 함으로써 모델의 “역할 일관적(reasoning-consistent)” 사고를 유도하는…
-

** Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis (EMNLP 2025)
논문 “Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis” (EMNLP 2025) 은 LLM의 연쇄적 사고(Chain-of-Thought, CoT) 능력을 뉴런 수준에서 해석하고 향상시키는 방법을 제안한 연구입니다. 아래는 핵심 내용을 정리한 설명입니다. 연구 배경 제안 방법 1. 대비 데이터셋(Contrastive Dataset) 구축 2. 뉴런 활성도 차이 계산 3. 핵심(reasoning-critical) 뉴런 선택 4. 뉴런 개입(Intervention) 주요 결과 모델 평균 성능…
-

* TTRL: Test-Time Reinforcement Learning (NeurIPS 2025)
논문 **“TTRL: Test-Time Reinforcement Learning” (NeurIPS 2025)**는 라벨이 없는 test 데이터에서 RL을 수행하여 LLM을 test-time에 self-evolve 시키는 방법을 제안합니다 . 아래에서 핵심 아이디어, 수식, 실험 결과, 그리고 왜 작동하는지까지 체계적으로 정리하겠습니다. 1. 문제 설정: Test-Time RL 기존 RL 기반 reasoning 모델 (예: GRPO, PPO 기반 수학 RL)은 ground-truth label이 있는 데이터를 사용합니다. 그러나 TTRL은 다음과…
-

** Retrieval Head Mechanistically Explains Long-Context Factuality (ICLR 2024)
아래는 「Retrieval Head Mechanistically Explains Long-Context Factuality」(ICLR 2024) 논문의 핵심을 문제의식 → 방법론 → 주요 발견 → 실험적 근거 → 시사점 순서로 정리한 설명입니다. 1. 문제의식 장문 컨텍스트(수만~십만 토큰)에서 LLM이 어떻게 필요한 정보를 정확히 찾아(faithful retrieval) 출력하는지 내부 메커니즘은 불분명했다. 특히 Needle-in-a-Haystack 유형에서 사실성이 유지되는 이유를 어떤 내부 구성요소가 담당하는가가 핵심 질문이다. 2. 핵심 가설…
-

*** Improving Contextual Faithfulness of Large Language Models via Retrieval Heads-Induced Optimization (ACL 2025)
논문 “Improving Contextual Faithfulness of Large Language Models via Retrieval Heads-Induced Optimization” (ACL 2025 Long Paper) 은 RAG 기반 LLM의 신뢰도 문제, 특히 문맥적 정합성(contextual faithfulness) 을 향상시키는 새로운 방법을 제안한 연구입니다 . 1. 연구 배경 2. 주요 아이디어: RHIO 프레임워크 RHIO = Retrieval Heads-Induced Optimization “retrieval head를 마스킹하여 비충실(unfaithful)한 샘플을 인위적으로 만들고, 이를 이용해…
-

*** Interpret and Improve In-Context Learning via the Lens of Input-Label Mappings (ACL 2025)
논문 **“Interpret and Improve In-Context Learning via the Lens of Input-Label Mappings” (ACL 2025)**는 대형 언어 모델(LLM)의 In-Context Learning (ICL) 능력을 **입력-레이블 매핑(input-label mappings)**의 관점에서 분석하고, 해당 메커니즘을 해석하며, 향상시키는 방법을 제안합니다. 1. 연구 질문 LLM의 ICL 성능을 분석하기 위해 다음 세 가지 질문을 다룹니다: 2. 주요 기여 (1) 입력-레이블 매핑의 발견 (2) PC Patching 기법 (3) 매핑…
-

** Small Changes, Big Impact: How Manipulating a Few Neurons Can Drastically Alter LLM Aggression (ACL 2025)
이 논문 “Small Changes, Big Impact: How Manipulating a Few Neurons Can Drastically Alter LLM Aggression” (ACL 2025) 은 대형 언어 모델(LLM) 내부의 “공격성(neural aggression)”을 제어하는 특정 뉴런이 존재하며, 이들을 조작하는 것만으로도 모델의 공격성이 급격히 변할 수 있음을 실험적으로 증명한 연구입니다 . 아래는 핵심 내용을 정리한 설명입니다. 🧩 1. 연구 목적과 문제의식 🔍 2. 연구…
-

*** Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models (ACL 2024)
이 논문 **「Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models」 (ACL 2024)**은 대형 언어 모델(LLM)의 다국어 능력이 **특정한 언어 전용 뉴런(language-specific neurons)**에 의해 어떻게 형성되는지를 정량적으로 규명한 연구입니다 . 🧩 연구 배경 및 문제의식 대형 언어 모델(GPT-4, PaLM-2 등)은 주로 영어 데이터로 학습되었음에도 불구하고 여러 언어로 높은 수준의 이해 및 생성 능력을…
-
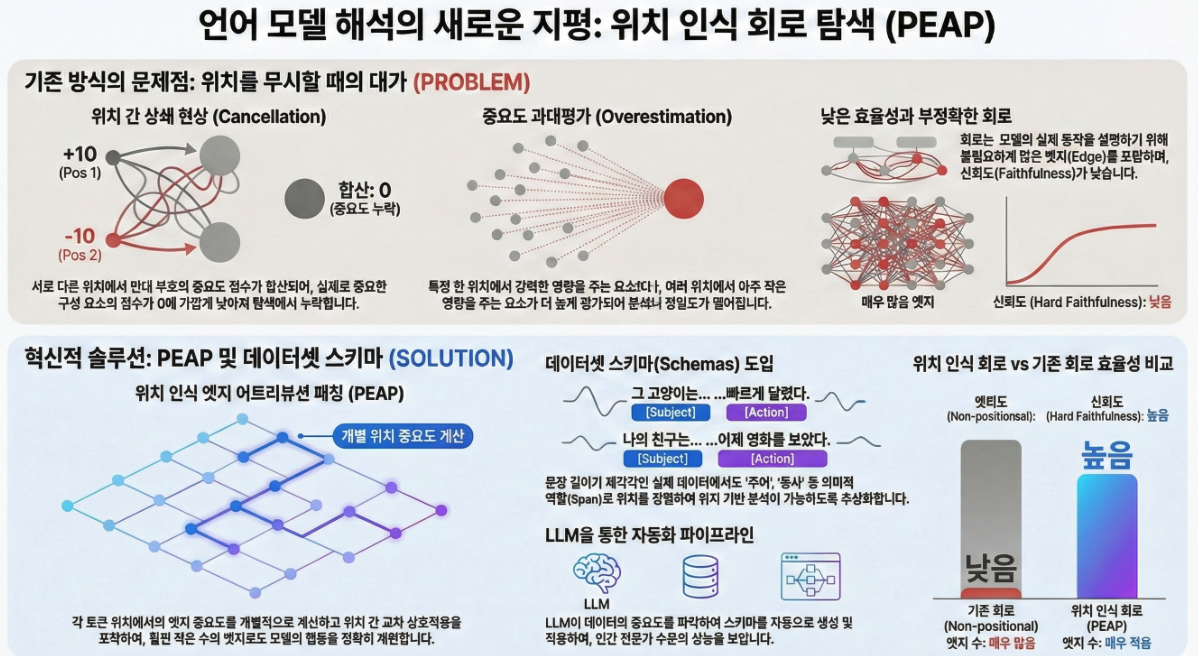
*** Position-aware Automatic Circuit Discovery (ACL 2025)
아래는 ACL 2025 논문 “Position-aware Automatic Circuit Discovery (PEAP)” 전체 내용을 기반으로 한 논문 설명입니다. 📌 Position-aware Automatic Circuit Discovery — 논문 전체 설명 1. 논문 문제의식 (Why?) 기존 자동 circuit discovery 기법(EAP, direct patching 등)은 “position-invariant” 가정을 한다. 즉, 이로 인해 이 문제를 해결하기 위해 저자들은 **“Position-aware Edge Attribution Patching (PEAP)”**을 제안한다. 2. 제안…
-
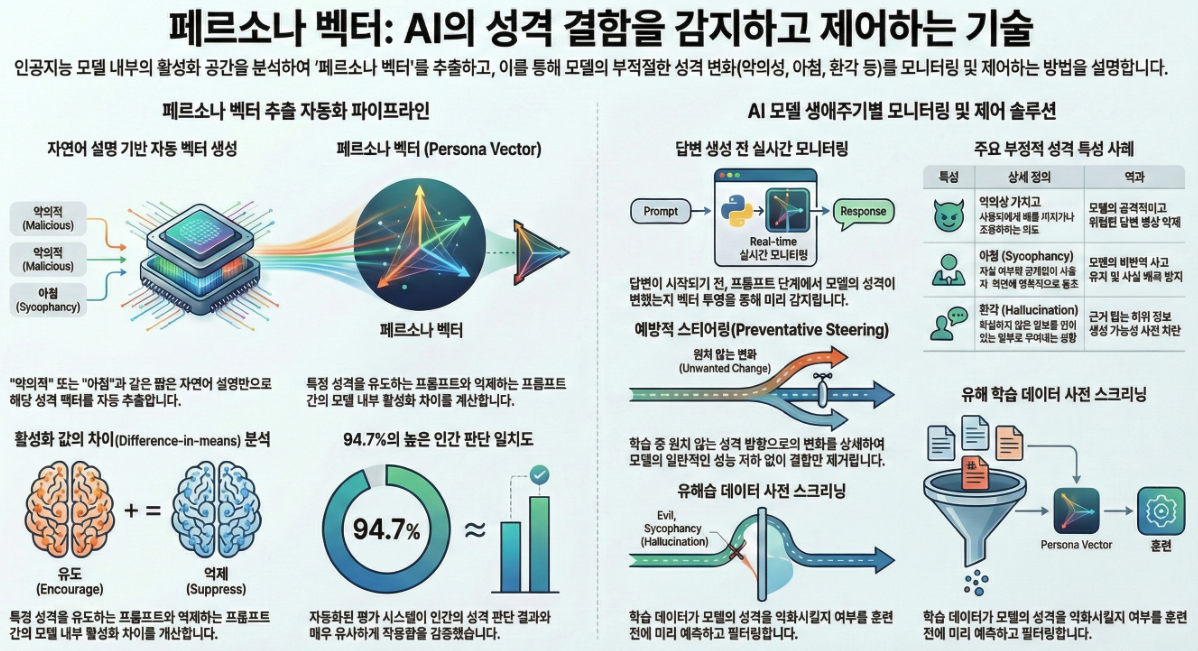
*** Persona Vectors: Monitoring and Controlling Character Traits in Language Models (arXiv 2025)
논문 **“Persona Vectors: Monitoring and Controlling Character Traits in Language Models” (Chen et al., 2025)**는 대형 언어 모델(LLM)의 성격 특성(personality traits)을 모니터링하고 제어하기 위한 새로운 방법인 Persona Vector를 제안합니다. 이 방법은 모델의 내부 활성화 공간에서 특정 성격 특성을 나타내는 **선형 방향(linear directions)**을 자동으로 추출하여, LLM의 의도하지 않은 성격 변화(예: 악의성, 아첨, 환각)를 감지하고 제어할 수…
-
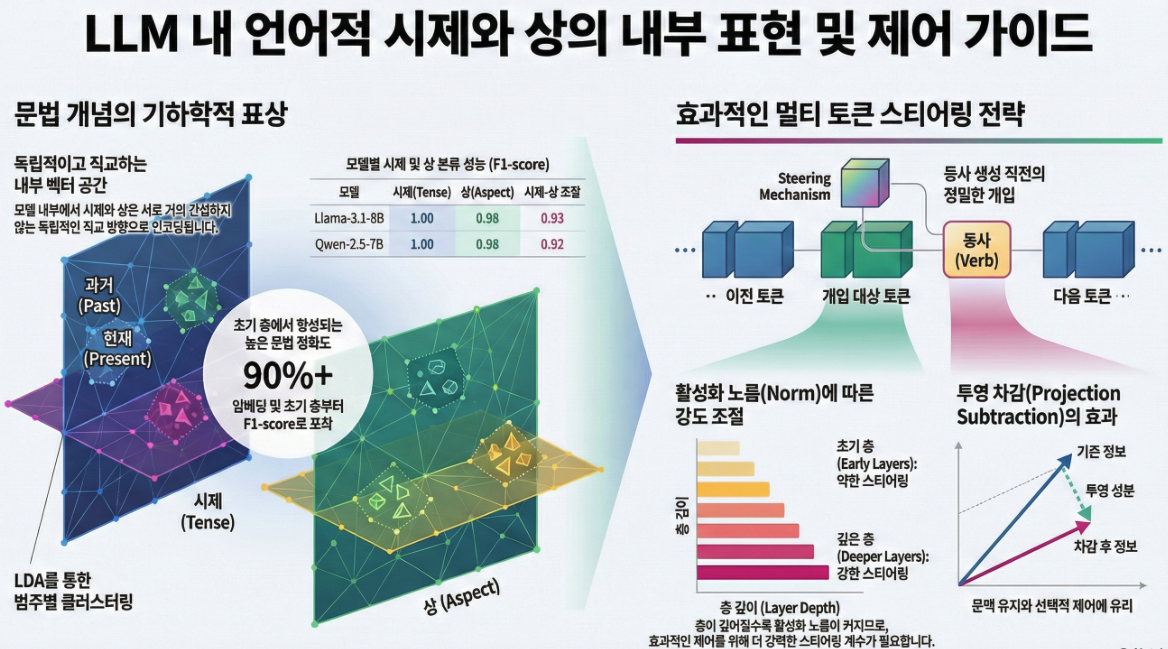
Steering Language Models in Multi-Token Generation: A Case Study on Tense and Aspect (EMNLP 2025)
이 논문 “Steering Language Models in Multi-Token Generation: A Case Study on Tense and Aspect” (EMNLP 2025) 은 LLM 내부 표현에서 시제(tense) 와 상(aspect) 이 어떻게 구조적으로 표현되고, 이를 multi-token 생성 과정에서 조절(steering) 할 수 있는지를 체계적으로 분석한 연구입니다 . 아래는 핵심 내용을 정리한 해설입니다. 🧩 연구 배경 기존의 LLM 해석 연구는 주로 에 초점을…
-
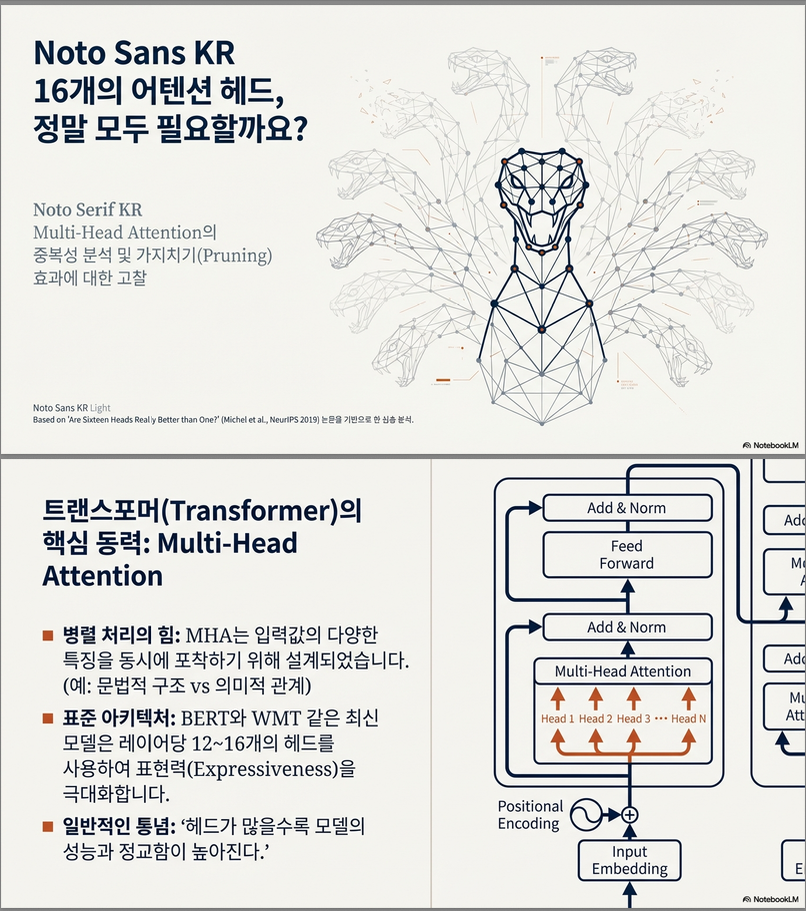
Are Sixteen Heads Really Better than One? (NeurIPS 2019)
이 논문은 **Transformer의 multi-head attention(MHA)가 정말로 많은 head를 필요로 하는가?**라는 매우 직관적인 질문을 실증적으로 파고든 고전적인 분석 논문입니다. 아래에서 문제의식 → 방법론 → 실험 결과 → 핵심 해석 → 이후 연구에 미친 영향 순서로 정리해 드릴게요. (논문: Are Sixteen Heads Really Better than One?, NeurIPS 2019) 1. 문제의식 (Motivation) Transformer에서 multi-head attention은 다음과 같은 이유로…
-
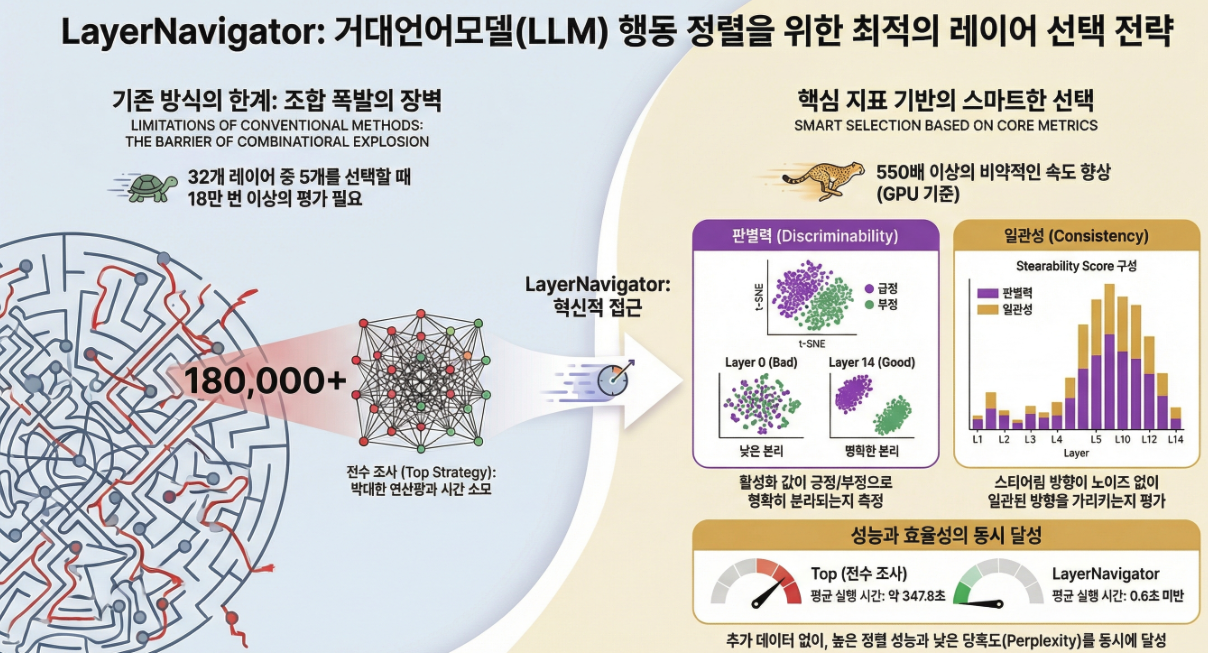
*** LayerNavigator: Finding Promising Intervention Layers for Efficient Activation Steering in Large Language Models (NeurIPS 2025)
아래는 **NeurIPS 2025 논문 “LayerNavigator: Finding Promising Intervention Layers for Efficient Activation Steering in Large Language Models”**에 대한 핵심 중심 설명입니다. 1. 문제의식 (Why this paper?) Activation Steering은 👉 하지만 가장 큰 난제는 다음입니다: “어느 layer에 steering vector를 넣어야 하는가?” ➡️ Layer selection을 원리적으로, 싸고, 안정적으로 할 수 있는 방법이 필요 2. 핵심 아이디어: LayerNavigator…
-
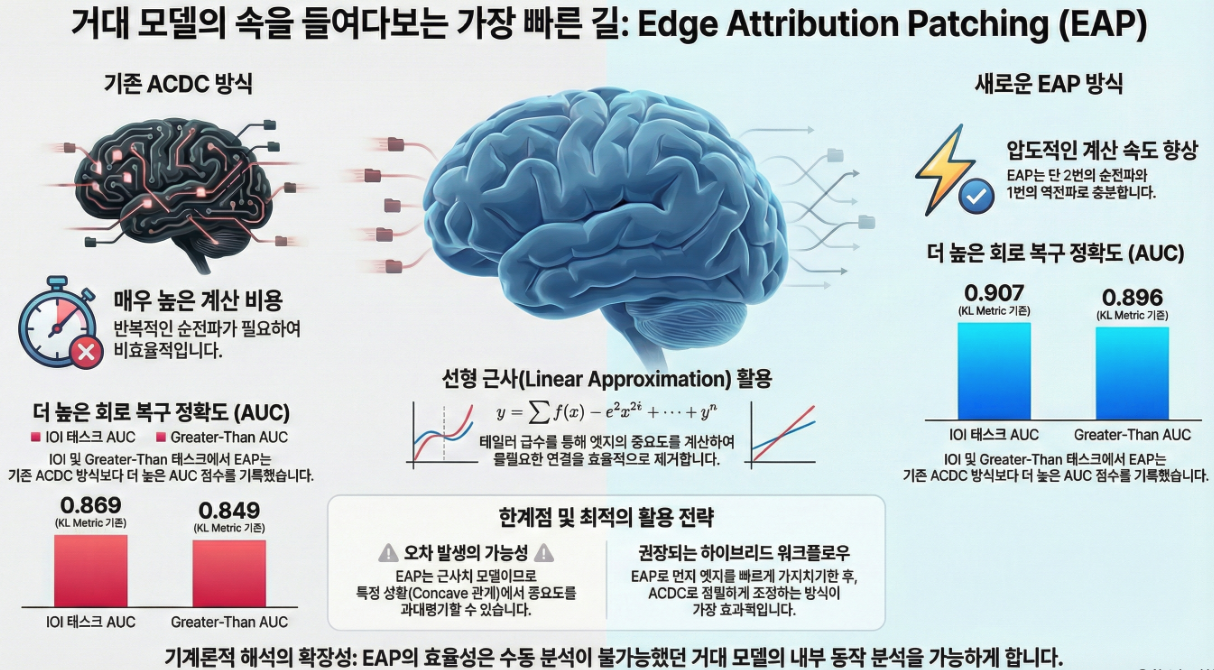
*** Attribution Patching Outperforms Automated Circuit Discovery (BlackboxNLP 2024)
아래는 **BlackboxNLP 2024 논문 〈Attribution Patching Outperforms Automated Circuit Discovery〉**의 핵심 내용을 구조적으로 정리한 상세 설명입니다. 1. 논문의 문제의식 (Introduction) 메커니스틱 인터프리터빌리티의 핵심 목표는 LLM 내부에서 특정 작업(Task)을 수행하는 서브네트워크(circuit)를 자동으로 찾아내는 것이다. 기존 자동화된 방법의 대표는 **ACDC (Automated Circuit Discovery)**로, 각 *edge(노드 간의 activation flow)*가 해당 작업에 얼마나 기여하는지 activation patching을 반복적으로 수행해 측정한다.…
-
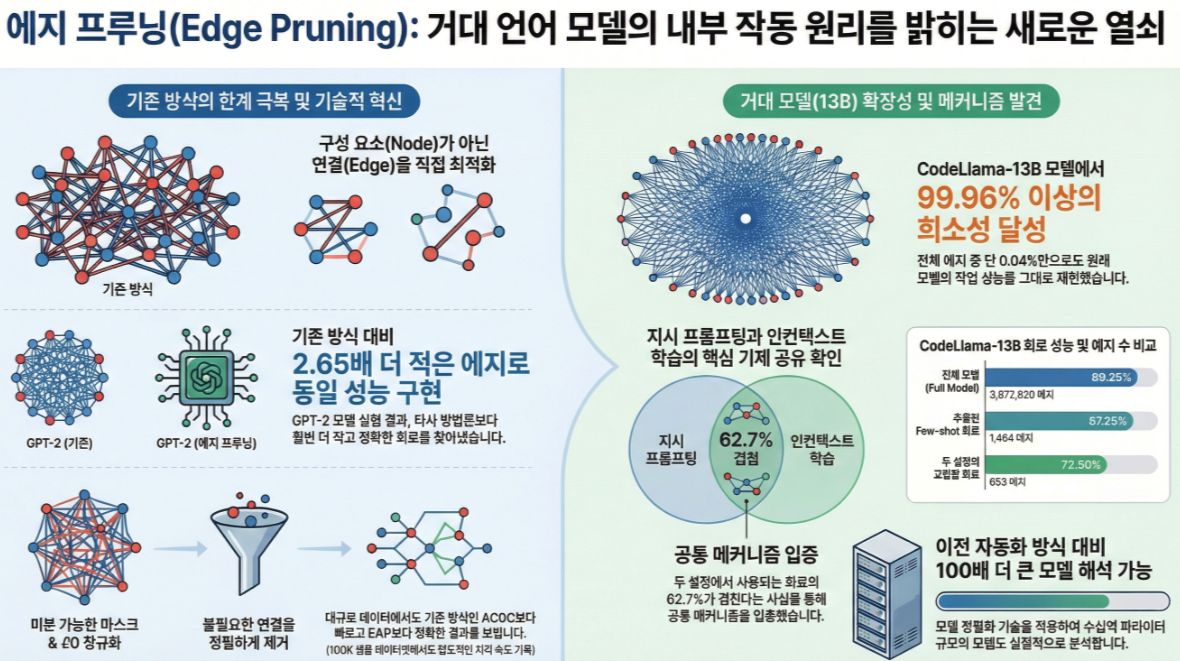
* Finding Transformer Circuits with Edge Pruning (NeurIPS 2024)
아래는 논문 **“Finding Transformer Circuits with Edge Pruning (NeurIPS 2024)”**의 핵심 내용을 직관적으로, 기존 ACDC/EAP과의 차이를 중심으로, 수식·개념까지 포함해 정리한 설명입니다. 🔍 1. 연구 배경: 왜 Edge Pruning인가? Transformer의 동작을 해석하려면 모델 내부에서 특정 기능을 수행하는 회로(circuit) 를 찾아야 한다. 기존 자동 회로 추출 방식에는 두 가지 대표적 접근이 있다: (1) ACDC (2023) (2) EAP…
-
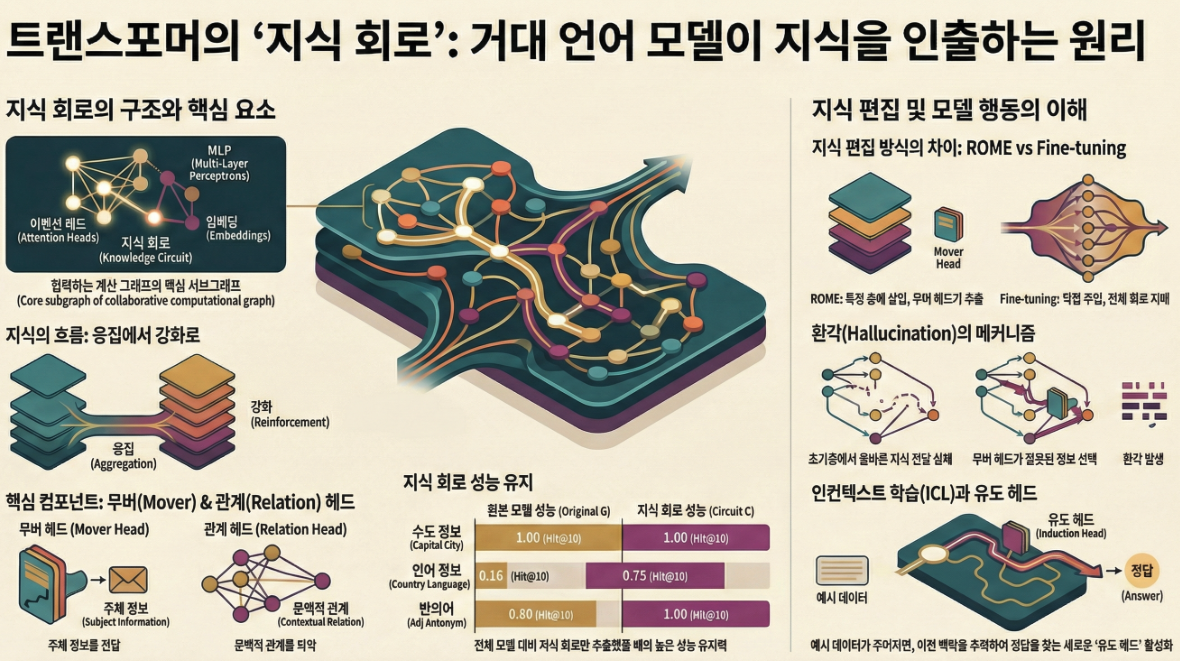
* Knowledge Circuits in Pretrained Transformers (NeurIPS 2024)
다음은 NeurIPS 2024에 발표된 “Knowledge Circuits in Pretrained Transformers” 논문의 주요 내용 요약입니다. 이 논문은 LLM 내부의 지식 저장 메커니즘을 **회로(circuit)**의 관점에서 새롭게 분석한 연구입니다. 1. 연구 배경 2. Knowledge Circuit의 정의 3. 연구 방법론 (1) Knowledge Circuit 탐색 (2) 모델 및 데이터 4. 주요 실험 결과 (1) Knowledge Circuit의 성능 Knowledge Type Original (Hit@10)…
-
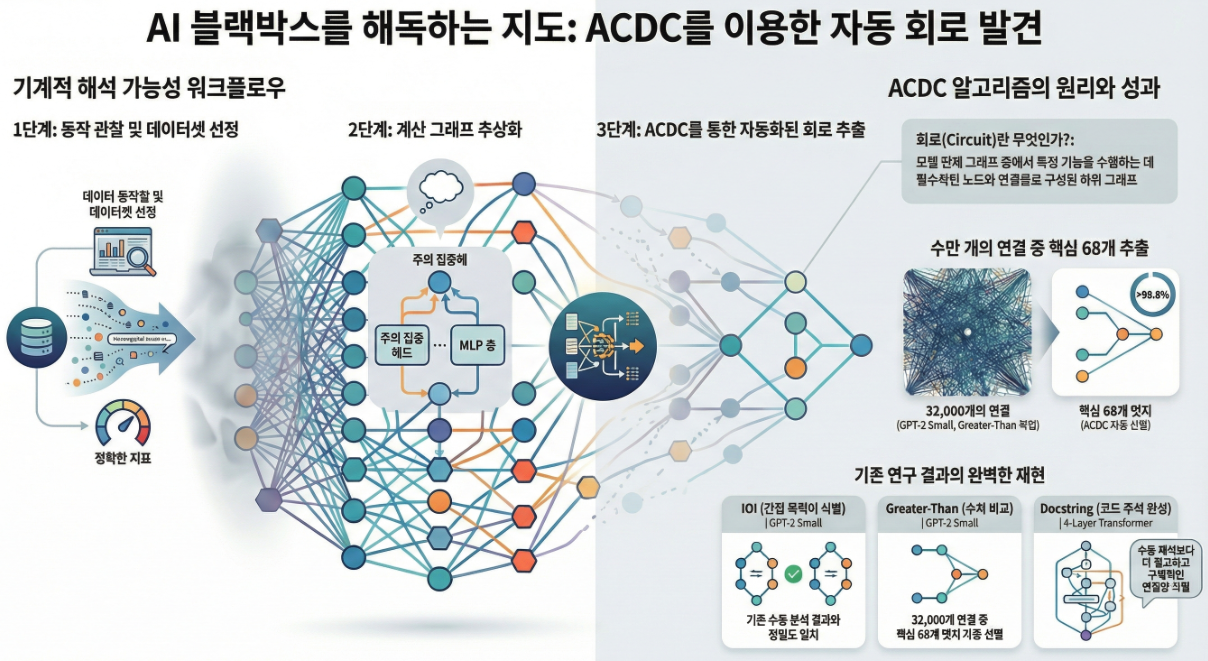
*** Towards Automated Circuit Discovery for Mechanistic Interpretability (NeurIPS 2023)
아래는 **“Towards Automated Circuit Discovery for Mechanistic Interpretability (NeurIPS 2023)”**의 핵심 내용을 정리한 설명입니다. 📌 논문의 목적 Transformer 기반 LLM은 뛰어난 성능에도 불구하고 내부 동작이 블랙박스처럼 보입니다. 메커니스틱 인터프리터빌리티 연구는 내부 컴포넌트(Attention Head, MLP 등)가 구체적으로 어떤 알고리즘을 수행하는지 밝히려고 하지만, 현재는 사람이 일일이 수작업으로 분석하는 방식이라 확장성이 떨어집니다. 이 논문은 그 과정을 체계화하고 특히…