

논문 “Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis” (EMNLP 2025) 은 LLM의 연쇄적 사고(Chain-of-Thought, CoT) 능력을 뉴런 수준에서 해석하고 향상시키는 방법을 제안한 연구입니다.
아래는 핵심 내용을 정리한 설명입니다.
연구 배경
- CoT 프롬프트(Wei et al., 2022)는 LLM이 단계별 추론을 수행하게 하지만, 종종 잘못된 중간 단계를 생성함.
- 기존 연구들은 프롬프트 최적화나 외부적 기법에 집중했지만, 내부 메커니즘(뉴런 단위에서 어떤 뉴런이 추론 품질을 결정하는가)에 대한 이해는 부족했음.
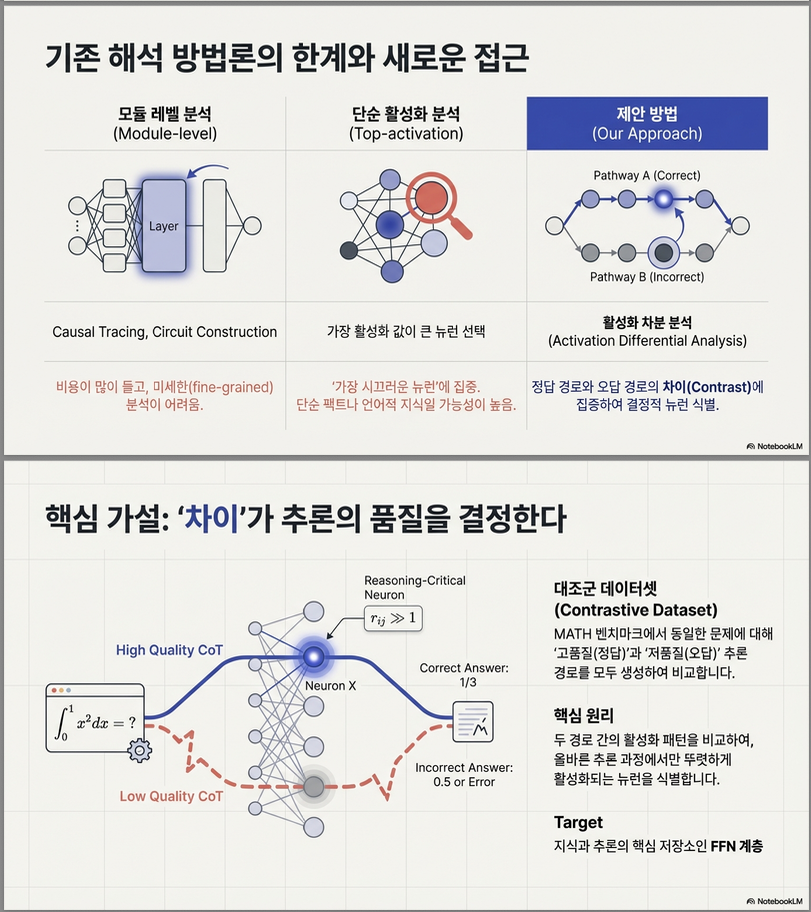
- 본 연구는 FFN(Feed-Forward Network) 뉴런의 활성화 패턴을 분석하여 고품질 CoT와 저품질 CoT의 차이를 찾아내고, 이를 통해 추론 능력을 직접 향상시키는 방법을 제안함.
제안 방법
1. 대비 데이터셋(Contrastive Dataset) 구축
- MATH benchmark의 문제를 이용하여 여러 CoT trajectory를 생성.
- 정답의 정확도와 중간 추론의 논리성 기준으로 “고품질 CoT”와 “저품질 CoT”로 분류.
2. 뉴런 활성도 차이 계산
- 각 뉴런 (i, j) 에 대해
- : 고품질 CoT 에서의 평균 활성도
- : 저품질 CoT 에서의 평균 활성도
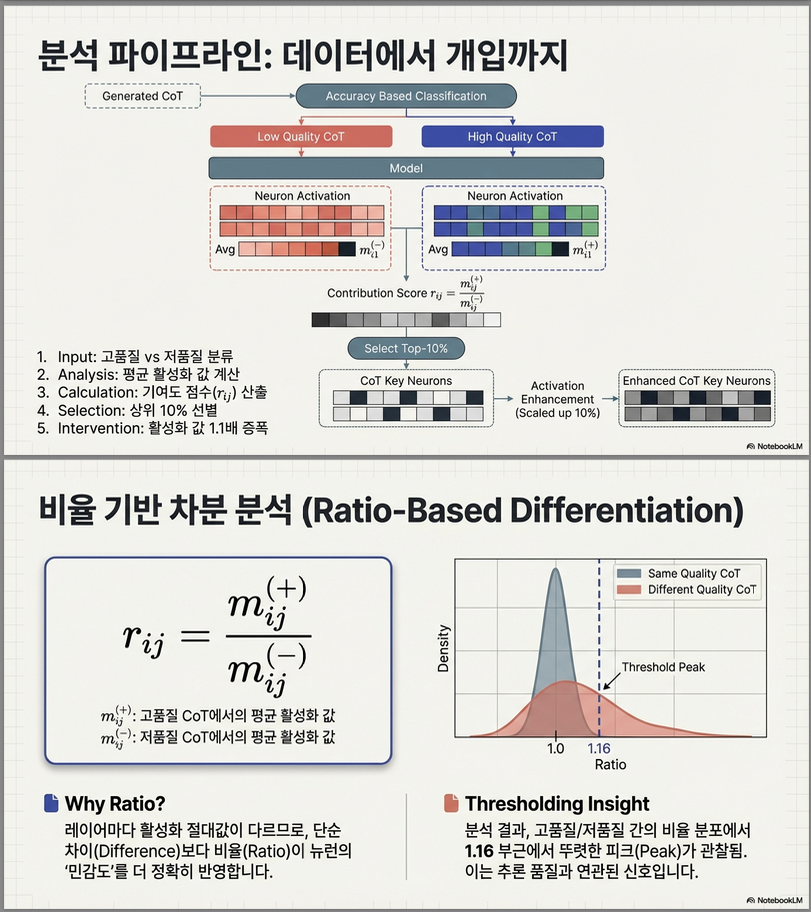
- 비율 기반(ratio-based) 차이를 사용하여 각 뉴런의 기여도를 측정.
3. 핵심(reasoning-critical) 뉴런 선택
- 상위 10 % 이내에서 threshold (예: 1.15 이상) 넘는 뉴런만 선택.
- 이들은 고품질 추론 시 더 강하게 활성화되는 뉴런으로 간주.
4. 뉴런 개입(Intervention)
- 증폭(Enhancement) : 선정된 뉴런의 활성값을 1.1× 으로 확대
- 억제(Interference) : 해당 뉴런을 0으로 설정
- 두 실험을 통해 해당 뉴런이 CoT 성능에 인과적 영향을 미친다는 점을 검증.
주요 결과
| 모델 | 평균 성능 ( MATH dataset ) |
|---|---|
| Greedy CoT | 47.7 % |
| Top-activation | 47.3 % |
| MathNeuro (Christ et al., 2024) | 47.6 % |
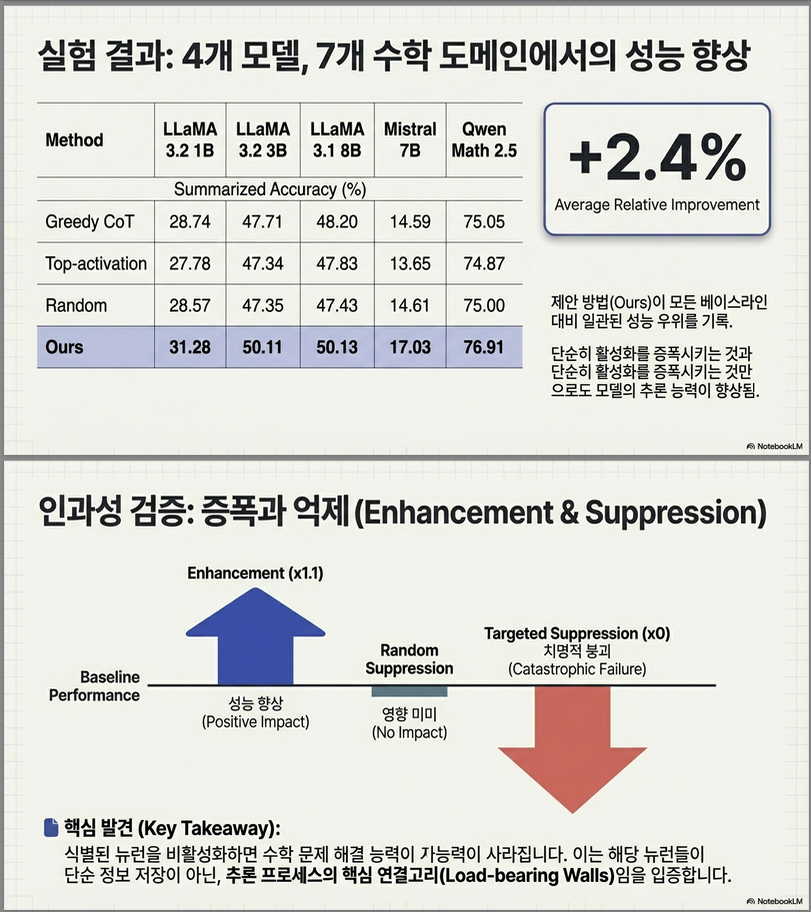
| Ours | 50.1 % (+ 2.4 %) |
- LLaMA 3.2 3B Instruct 기준 2.4 % 상승.
- 뉴런을 억제하면 성능이 급격히 하락, 무작위 뉴런 억제는 영향 작음 → 선정된 뉴런이 실제로 핵심 역할.
추가 분석
● 활성 패턴 차이
- 고품질 CoT 대 저품질 CoT 비교 시 분포 ≈ 1.16 부근에서 뾰족 → 차별적 활성 존재 입증.
● 층별 분포
- 중간~후반부 FFN 층에 집중, 특히 마지막 층에 많음. → 중간 층은 문제 해결 정보 인코딩, 후반 층은 정답 생성 담당 (기존 분석과 일치).
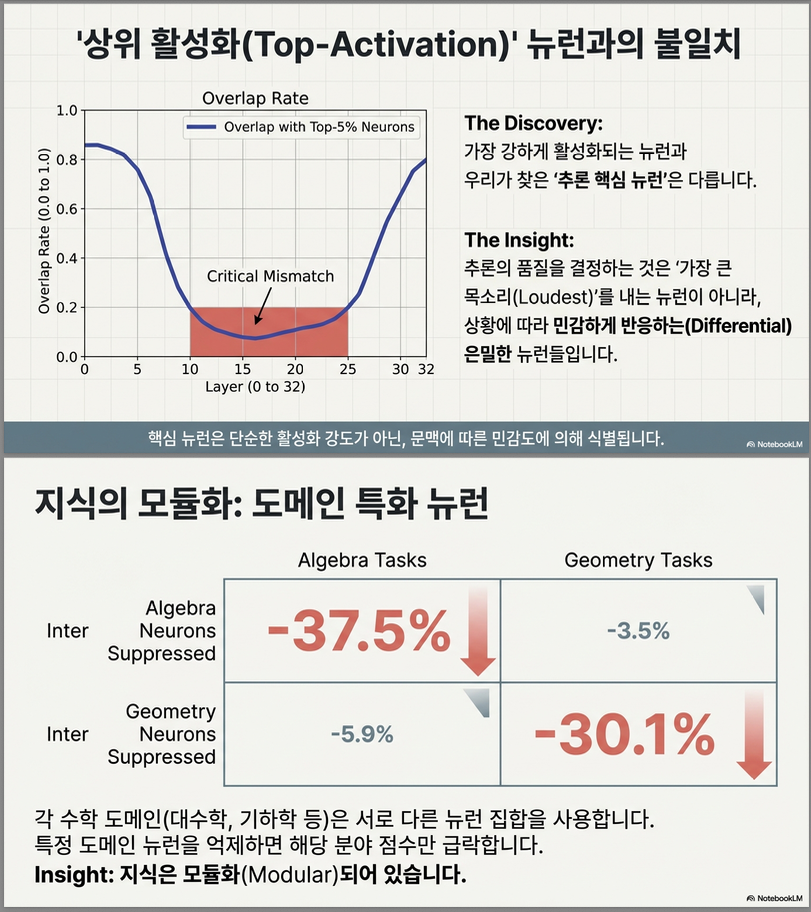
● Top-activation 뉴런과의 중첩
- 중간 층에서는 상위 활성 뉴런과 중첩이 낮음 → “강한 활성 뉴런 = 중요 뉴런” 이 아님.
● 일반 추론 과제 전이
- CommonsenseQA (70.27 %) / StrategyQA (69.57 %) → 수학 추론 외 일반 추론에도 효과 있음.
부가 분석 및 확장
- Domain-Specific Neuron Analysis : 수학 세부 영역별(Algebra, Geometry 등) 뉴런을 별도로 추출.
- 예: “Geometry 뉴런” 은 volume, sphere, radius 등 토큰과 연관.
- 특정 영역 뉴런을 억제하면 해당 도메인 성능만 크게 감소 → 모듈화된 추론 회로 존재 시사.
한계 및 미래 과제
- 실험은 주로 LLaMA-3.2 3B 에 국한 → 다른 LLM 으로 일반화 필요.
- FFN 층만 분석했으며, Self-Attention 층과의 상호작용 은 미분석.
- 대비 데이터셋 구성 전략 최적화 (샘플 수, 다양성 등) 은 추가 연구 필요.
요약 정리
| 항목 | 내용 |
|---|---|
| 핵심 아이디어 | 고품질 vs 저품질 CoT 간 뉴런 활성 비율 분석으로 ‘추론 핵심 뉴런’ 탐지 |
| 핵심 지표 | (활성 비율) |
| 개입 전략 | 선택 뉴런의 활성값 1.1× 증폭 → 추론 품질 향상 |
| 결과 | MATH 성능 +2.4 %, 일반 추론에도 전이 효과 확인 |
| 의의 | CoT 품질 차이를 뉴런 활성 차이로 정량화 → 해석적 LLM 개선 경로 제시 |
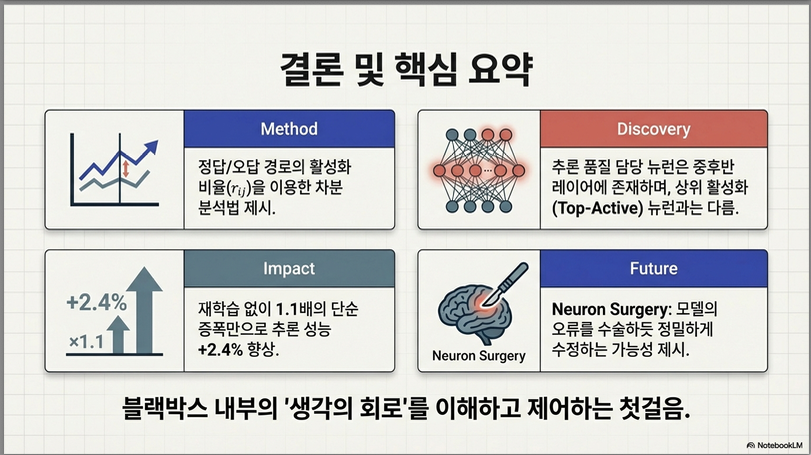
Methodology — Neuron Activation Differential Analysis (NADA)
이 논문의 방법론은 “고품질 CoT vs 저품질 CoT에서 뉴런 활성 차이를 이용해 reasoning-critical neuron을 찾고 직접 개입하는 것” 입니다.
구성은 크게 4단계입니다:
1) 대비 CoT 데이터 생성
2) 뉴런 activation 차이 계산
3) 핵심 뉴런 선택
4) 뉴런 활성 개입 (steering)아래에서 수식 중심으로 단계별 설명합니다.
1. Transformer 내부 모델링 (문제 설정)
논문은 FFN layer의 뉴런을 분석 대상으로 정의합니다.
Transformer layer l 에서:
- : attention output (token hidden state)
- : up-projection
- : down-projection
- : activation function
- 뉴런 정의: 의 특정 scalar parameter
즉:
FFN hidden dimension 하나 = 하나의 neuron.
논문의 핵심 가설:
좋은 reasoning chain → 특정 뉴런 activation pattern 존재
2. Contrastive CoT Dataset 구축
목적
고품질 reasoning과 저품질 reasoning에서 내부 활성 차이를 보기 위해.
생성 과정
(1) 문제 샘플링
- MATH benchmark 사용.
(2) 여러 CoT trajectory 생성
- sampling decoding으로 reasoning chain 생성.
(3) 품질 분류
High-quality CoT
- 정답 맞음
- 중간 reasoning 논리적으로 올바름
Low-quality CoT
- 정답 틀림
- 또는 reasoning 오류 포함
논문은 정답만 맞는 CoT도 사람이 검증하여 제거함.
결과
contrastive set:
이게 전체 방법의 핵심 데이터.
3. Neuron Contribution Estimation (핵심 아이디어)
이 논문의 가장 중요한 부분입니다.
Step 1 — 뉴런 activation 측정
각 layer i, neuron j 에 대해:
high-quality CoT 평균 activation
low-quality CoT 평균 activation
실제로는 token-level activation의 L2 norm 평균을 사용:
그리고 dataset 평균:
Step 2 — Activation Difference (논문의 핵심)
기존 연구:
absolute activation ↑ → 중요한 뉴런이 논문:
quality별 activation 차이 ↑ → 중요한 뉴런Activation ratio 정의
의미
| 값 | 의미 |
|---|---|
| 좋은 reasoning에서 더 활성 | |
| 무관 | |
| 나쁜 reasoning 관련 |
왜 ratio인가?
논문 이유:
- layer마다 activation scale 다름
- absolute difference 비교 불가능
- ratio가 더 robust
이건 매우 중요한 설계.
4. Reasoning-Critical Neuron Selection
뉴런 선택은 cascade filtering 방식.
Step 1 — 상위 10% 선택
Step 2 — threshold filtering
논문 default:
τ ≈ 1.15결과:
이 집합이 reasoning-critical neurons.
Algorithm (논문 Algorithm 1 요약)
for high-quality CoT:
accumulate neuron activation
for low-quality CoT:
accumulate neuron activation
compute activation ratio r_ij
select neurons with high r_ij즉 매우 단순한 통계 기반 selection.
5. Neuron Intervention (Steering 단계)
선택된 뉴런이 실제로 reasoning을 제어하는지 검증.
(A) Enhancement — activation 증폭
선택된 뉴런에 대해:
논문 설정:
α = 1.1즉, reasoning neuron activation boost.
(B) Interference — activation 제거
→ reasoning 능력 붕괴 확인.
개입 위치
- FFN activation coefficient 직접 수정.
- inference-time intervention.
(즉 training 없음)
6. Method 전체 파이프라인
논문 방법 전체 구조:
CoT 생성
↓
quality label
↓
neuron activation 분석
↓
activation ratio 계산
↓
critical neuron 선택
↓
activation steering
↓
CoT 품질 개선매우 간단하지만 효과 있음.
* 핵심 methodological contribution (연구 관점)
이 논문이 기존과 다른 점:
기존 neuron importance
- saliency
- activation magnitude
- weight norm
- pruning score
→ static importance
이 논문
importance = reasoning quality sensitivity즉
이게 novelty.
✔️ 핵심 takeaway (한 줄)
좋은 reasoning과 나쁜 reasoning을 구분하는 뉴런을 찾아 직접 활성 조작하면 CoT 품질이 개선된다.
논문에서 Contrastive CoT Dataset은 방법론 전체의 핵심입니다.
하지만 EMNLP short paper 특성상 정확한 샘플 수나 생성 횟수는 자세히 공개하지 않고, 구성 방식과 분류 프로토콜 중심으로 설명합니다. 아래에 논문 기준으로 정확히 정리합니다.
Contrastive CoT Dataset 구축
1. 데이터셋 출처 및 규모
사용 데이터
- MATH benchmark training set 사용
- 7개 수학 영역 포함:
- Algebra
- Counting & Probability
- Precalculus
- Prealgebra
- Geometry
- Intermediate Algebra
- Number Theory
MATH training set 규모 (논문 Appendix)
| Category | Train size |
|---|---|
| Algebra | 1744 |
| CP | 771 |
| Precalculus | 746 |
| Prealgebra | 1205 |
| Geometry | 870 |
| Intermediate Algebra | 1295 |
| Number Theory | 869 |
총 약:
(하지만 contrastive dataset 최종 크기는 공개되지 않음)
중요한 점 (논문 limitation)
논문이 명시적으로 밝힘:
optimal dataset characteristics는 systematic하게 탐색하지 않았다.
즉:
- CoT sample 수
- per-problem trajectory 수
- 최종 positive/negative ratio
→ 모두 미공개.
연구 reproducibility 관점에서는 약점.
2. CoT trajectory 생성 방식
각 문제에 대해:
문제 → multiple reasoning chains 생성생성 방식
논문 표현:
“we generate multiple CoT trajectories through controlled sampling”
즉:
- temperature sampling / stochastic decoding
- 여러 reasoning path 확보 목적
목적
같은 문제에 대해:
good reasoning
bad reasoning둘 다 확보.
3. High-quality / Low-quality CoT 분류 기준
이 부분이 논문에서 매우 중요한 설계입니다.
1단계 — 자동 분류 (answer correctness)
기본 기준:
final answer correct → candidate positive
final answer wrong → candidate negative즉:
2단계 — 인간 검증 (manual verification)
논문에서 매우 강조:
정답 맞더라도 reasoning 오류 있으면 제거
즉:
제거되는 경우
- intermediate step 오류
- 논리적 비약
- 계산 오류
- spurious reasoning
결과
최종:
High-quality CoT:
- 정답 맞음
- reasoning 과정도 올바름
Low-quality CoT:
- 정답 틀림
- 또는 reasoning 오류 포함논문 문장:
manually verify and filter out reasoning chains that yield correct final answers but contain incorrect intermediate reasoning steps
왜 manual verification 필요한가?
이 논문 핵심 motivation:
CoT ≠ faithful reasoning즉:
- 정답 맞아도 reasoning 틀릴 수 있음.
- reasoning quality 자체를 supervision signal로 사용하려면 필수.
4. 최종 contrastive dataset 구조
구성:
그리고:
- 동일 task distribution
- 동일 problem source
- reasoning quality만 차이
이게 activation ratio 계산의 핵심.
5. 실제 dataset 사용 방식 (neuron analysis 단계)
각 CoT trajectory를 모델에 다시 넣어서:
forward pass
→ layer별 neuron activation 수집그리고 평균 activation 계산:
6. 이 설계의 핵심 특징 (연구적 의미)
① outcome-based → reasoning-based supervision
기존:
correct answer vs wrong answer이 논문:
correct reasoning vs incorrect reasoning큰 차이.
② weak reward model 역할
이 dataset은 사실상:
reasoning reward signal역할을 함.
→ RL 없이 internal supervision 생성.
③ causal attribution 가능
이 contrastive 구조 때문에:
activation difference → causal importance해석 가능.
7. dataset 설계의 한계
논문에서 직접 인정:
dataset size 불명확
- 생성 trajectory 수 미공개
- label distribution 미공개
manual labeling scalability 문제
- 사람 검증 필요
- 자동화 방법 없음
domain bias 가능
- 수학 중심
- 일반 reasoning representation과 차이 가능
핵심 요약
| 항목 | 내용 |
|---|---|
| 데이터 출처 | MATH training set (~7500 문제) |
| CoT 생성 | stochastic sampling으로 multiple reasoning |
| high-quality 기준 | 정답 + reasoning 과정 correct |
| low-quality 기준 | 정답 틀림 또는 reasoning 오류 |
| 추가 검증 | 인간 manual filtering |
| 최종 구조 | contrastive dataset E_1, E_2 |
| dataset size | 논문 미공개 |
Experimental Results — Enhancing CoT Reasoning via Neuron Activation Differential Analysis
이 논문의 실험은 다음 4가지 질문을 검증합니다.
- 선택한 뉴런이 실제로 CoT 성능을 올리는가?
- 뉴런이 reasoning capability에 causal 영향이 있는가?
- 어떤 뉴런 구조적 특성이 있는가?
- 수학 외 일반 reasoning에도 일반화되는가?
아래에서 핵심 결과를 체계적으로 설명합니다.
1. Main Results — MATH Benchmark
실험 설정
- 모델:
- LLaMA 3.2 3B (main)
- LLaMA 3.1 8B
- LLaMA 3.2 1B
- Mistral 7B
- Qwen Math 2.5B
- intervention:
- 선택된 뉴런 activation × 1.1
- 비교 baseline:
- Greedy CoT
- Top-activation neuron
- MathNeuro
- Wanda pruning
- Random selection
주요 결과 (평균 정확도)
LLaMA 3.2 3B Instruct
| Method | Avg Accuracy |
|---|---|
| Greedy CoT | 47.71 |
| Top activation | 47.34 |
| MathNeuro | 47.64 |
| Wanda | 47.36 |
| Random | 47.35 |
| Ours | 50.11 |
–> +2.4% relative improvement
다른 모델에서도 동일 경향
| Model | Greedy | Ours |
|---|---|---|
| LLaMA 3.1 8B | 48.20 | 50.13 |
| LLaMA 3.2 1B | 28.74 | 31.28 |
| Mistral 7B | 14.59 | 17.03 |
| Qwen Math 2.5B | 75.05 | 76.91 |
–> 모델 크기/구조와 무관하게 일관된 개선.
핵심 해석
논문 주장:
activation difference 기반 뉴런이 실제 reasoning 과정과 직접 연관됨을 의미
특히:
top activation neuron보다 성능 좋음→ 단순히 activation 큰 뉴런 ≠ 중요한 뉴런.
2. Causal Test — Neuron Suppression Experiment
실험
선택된 뉴런:
activation = 0vs
random neuron suppression결과
- 선택된 뉴런 제거 → catastrophic failure
- random 제거 → 성능 약간 감소
논문 설명:
reasoning capability 유지에 필수적인 뉴런임을 확인
의미 (매우 중요)
이건 단순 correlation이 아니라:
causal importance evidence즉:
3. Activation Pattern Analysis
핵심 관찰
High vs Low quality CoT activation ratio 분포
- 서로 다른 quality CoT 비교:
- ratio peak ≈ 1.16
- 동일 quality 비교:
- 차이 없음
의미
good reasoning → 특정 activation signature 존재즉 reasoning representation 존재.
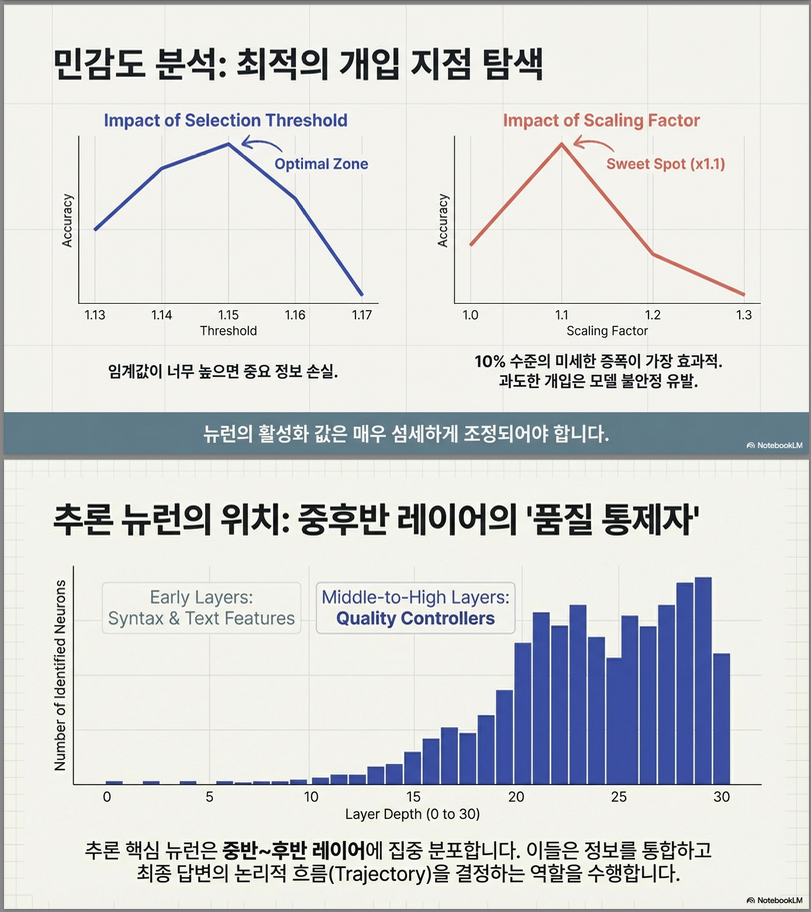
4. Layer-wise Distribution
결과
- reasoning-critical neuron 분포:
- 중간~후반 layer 집중
- 마지막 layer 최다
해석
논문 설명:
- middle layer → task solving representation
- final layer → answer generation control
연구적으로 중요한 점
reasoning = late-stage computation→ mechanistic interpretability와 일치.
5. Top-Activation Neuron과의 관계
결과
- overlap rate = U-shape
- middle layer에서 overlap 낮음
의미
high activation ≠ reasoning neuron즉:
- magnitude-based saliency 한계
- quality-sensitive neuron 필요
6. Generalization — General Reasoning Tasks
수학 외 reasoning 평가.
CommonsenseQA / StrategyQA
| Method | CommonsenseQA | StrategyQA |
|---|---|---|
| Greedy CoT | 68.30 | 66.08 |
| Top activation | 68.80 | 66.38 |
| MathNeuro | 69.21 | 67.69 |
| Ours | 70.27 | 69.57 |
의미
- domain-specific trick 아님
- reasoning process 자체 개선
7. General Capability 영향 (Side Effect Test)
MMLU 포함 평가
| Method | MMLU |
|---|---|
| Greedy | 59.48 |
| Ours | 59.21 |
의미
reasoning 개선 ≠ general capability 손상practical deployment 가능.
8. Domain-Specific Neuron Analysis (흥미로운 결과)
논문에서 가장 mechanistic한 부분.
발견
수학 영역별 뉴런 존재:
- Geometry neuron
- Algebra neuron
- Number theory neuron 등
실험
특정 domain 뉴런 억제:
→ 해당 domain accuracy만 크게 감소예:
- Geometry neuron 제거 → geometry 성능만 크게 감소.
추가 evidence
vocabulary projection 결과:
| Domain | 연결 token |
|---|---|
| Geometry | volume, sphere, radius |
| Algebra | vector, distance |
| CP | percentage, sum |
의미
neuron = domain knowledge module(knowledge neuron hypothesis 강화)
9. Hyperparameter Ablation
threshold 영향
- threshold ↑ → 성능 증가
- 너무 높으면 성능 감소 (critical neuron 제거됨)
scaling factor 영향
- 적당한 scaling → 성능 증가
- 너무 크면 성능 감소 (activation sensitivity)
* 실험 결과 핵심 정리
논문이 실험으로 보여준 것
reasoning neuron 존재
- activation signature 존재
causal importance
- 제거하면 reasoning 붕괴
steering 가능
- activation scaling으로 성능 개선
domain modularity 존재
- domain-specific neuron
답글 남기기