




논문 “MicroEdit: Neuron-level Knowledge Disentanglement and Localization in Lifelong Model Editing” (EMNLP 2025) 은 대형 언어모델(LLM)의 지속적인 지식 편집(lifelong model editing) 문제를 다루며, 기존 방법들이 가지는 두 가지 핵심 한계를 정량적으로 분석하고, 이를 해결하기 위해 Sparse Autoencoder(SAE) 기반의 뉴런 단위 최소 편집(neuron-level minimal editing) 기법을 제안합니다 .
1. 연구 배경 및 문제점
LLM은 대규모 사전학습 과정에서 방대한 지식을 습득하지만, 세상의 변화에 따라 오래되거나 잘못된 지식을 그대로 유지하는 문제가 발생합니다.
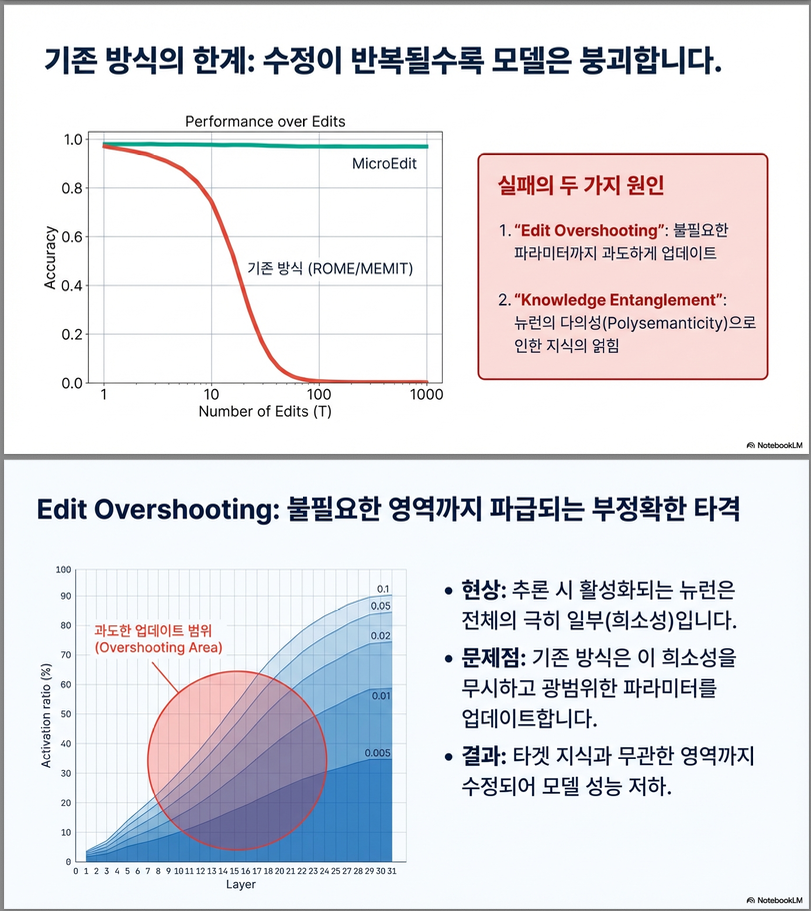
기존 편집 기법(예: ROME, MEMIT, MEND 등)은 단일 혹은 제한된 편집(single-shot editing) 에 초점을 맞추어, 지속적 편집(수천 번 이상)에서는 다음 두 가지 근본적 문제가 발생합니다:
- Edit Overshooting (과잉 편집)
- 특정 사실을 수정할 때, 관련 없는 매개변수까지 광범위하게 수정되어 비의도적 지식 손상이 발생.
- 대부분의 기존 방법은 전체 레이어를 업데이트하여 편집 범위가 지나치게 넓음.
- Knowledge Entanglement (지식 얽힘)
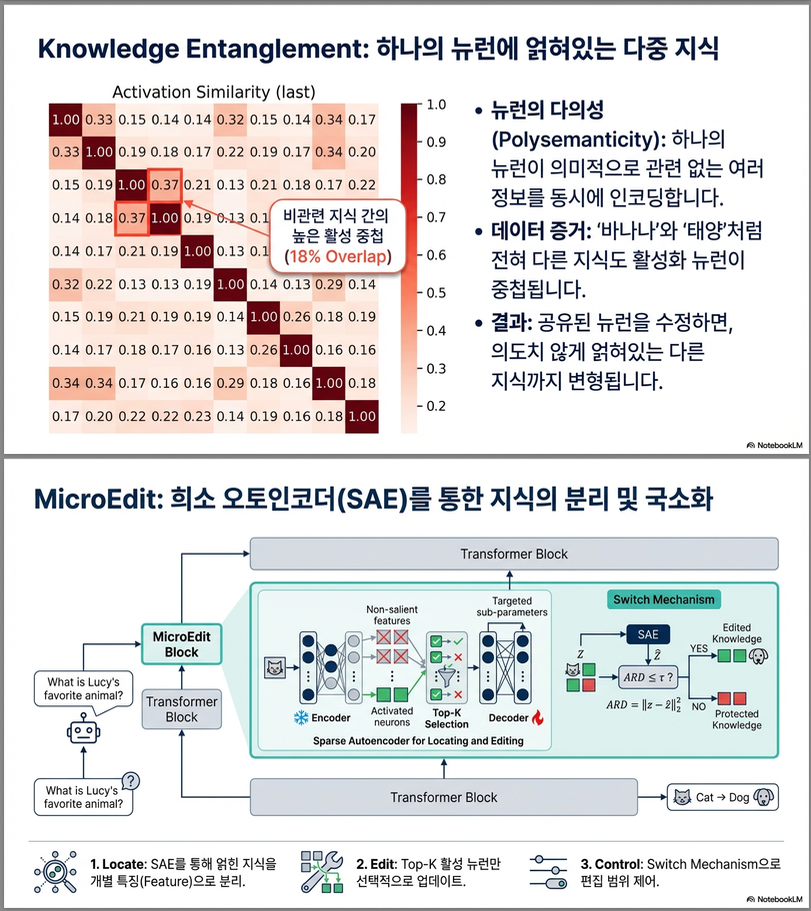
- LLM의 polysemantic neurons (다의적 뉴런) 이 여러 의미를 중첩적으로 표현하여, 하나의 사실을 수정하면 다른 사실이 의도치 않게 변형됨.
이 두 문제로 인해 장기적 연속 편집(lifelong editing) 시 모델 성능이 불안정하게 붕괴합니다 .
2. 제안 방법: MicroEdit
(1) 핵심 아이디어
MicroEdit은 Sparse Autoencoder(SAE) 를 활용하여:
- 뉴런 수준(neuron-level) 의 희소(sparse) 활성화를 통해 최소한의 파라미터만 수정
- Top-k 활성화를 통해 가장 관련된 뉴런만 업데이트
- Switch Mechanism 으로 편집 범위(in-scope) 와 비편집 범위(out-of-scope) 를 자동 구분
→ 결과적으로, 지식 disentanglement(분리) 와 localization(국소화) 를 동시에 달성함 .
3. 방법론 구성
(a) Sparse Autoencoder (SAE)
- 입력: LLM의 특정 레이어의 residual stream z
- 인코더:
- 디코더:
→ Top-k 활성 뉴런만 유지하여 희소한 뉴런 공간에서 편집 정보만 반영
→ 편집된 표현은 로,
한정된 서브스페이스 내에서만 변경 발생 (Edit Overshooting 방지).
(b) Switch Mechanism
- SAE의 재구성 오차를 기반으로 Average Reconstruction Distance (ARD) 계산:
- ARD가 임계값 τ보다 작으면 → 편집 적용 (in-scope) 그렇지 않으면 → 원래 표현 유지 (out-of-scope)
→ 편집이 필요한 지식만 SAE를 통과하여 수정되므로, 비편집 영역 안정성 확보 .
(c) Gradient Masking
- 디코더의 업데이트 시 활성 뉴런만 gradient 반영:
- 이를 통해 편집 영향이 국소적으로 제한됨.
4. 실험 결과
데이터셋 및 모델
- ZsRE (QA): 사실 기반 지식 수정
- SelfCheckGPT (Hallucination): 환각 수정
- 모델: LLaMA-3-8B, Mistral-7B
- 비교 기법: FT, FT-EWC, ROME, MEMIT, MEND, GRACE, WISE 등 .
주요 결과 요약
| 설정 | MicroEdit | 특징 |
|---|---|---|
| ZsRE (1k edits) | Rel. 0.87 / Gen. 0.65 / Loc. 1.00 | 높은 편집 성공률, 뛰어난 안정성 |
| SelfCheckGPT (600 edits) | Rel. ~1.1 / Loc. 1.00 | 가장 낮은 환각률 및 손상 최소화 |
| 5k edits | Avg 0.78 | 타 방법 대비 +12% 향상, 장기 안정성 유지 |
→ 특히, 5K 이상의 지속 편집에서도 GRACE/WISE 대비 성능 유지력이 탁월함 .
5. 추가 분석
- Top-k 값(k=192): 너무 작으면 정보 손실, 너무 크면 뉴런 중복 → k=192 최적
- 편집 레이어 위치: 후반부(layer 30 부근)가 가장 효과적 (사실 지식이 집중된 영역)
- ARD Threshold (≈ 0.55): in-scope / out-of-scope 분리를 가장 잘 달성
6. 관련 연구 및 위치
| 범주 | 대표 연구 | MicroEdit의 차별점 |
|---|---|---|
| Parameter Update 기반 | ROME, MEMIT, MEND | 파라미터 수정 범위가 광범위 |
| External Memory 기반 | GRACE, WISE | 저장 효율 높지만 Entanglement 존재 |
| SAE 기반 | STA (2025), LLaMA Scope (2024) | SAE의 interpretability 활용 |
| MicroEdit | Sparse Autoencoder + Switch | 뉴런 단위 편집, lifelong 안정성 확보 |
7. 한계 및 향후 연구
- SAE가 없는 모델에는 별도 학습 필요 → 추가 계산 비용 발생
- SAE 품질이 편집 성능에 직접적 영향을 미침
- 향후 방향: 일반화된 disentanglement 메커니즘 연구 및 SAE-less 구조 탐색 .
요약 정리
| 항목 | 내용 |
|---|---|
| 문제 정의 | LLM의 지속적 지식 편집 시 과잉 편집과 지식 얽힘 발생 |
| 핵심 아이디어 | Sparse Autoencoder로 뉴런 수준의 희소 편집 수행 |
| 주요 구성 | (1) SAE 편집 모듈 (2) Switch Mechanism (3) Gradient Masking |
| 성과 | 5K+ 편집에서도 안정적인 성능 유지 (Reliability ↑, Locality ↑) |
| 의의 | “Lifelong knowledge editing”을 위한 뉴런 단위 제어 기반 해법 제시 |
요약하자면, MicroEdit은 LLM 내부의 뉴런 표현을 분리(disentangle)하고 국소화(localize) 하여, 지속적 지식 편집에서의 안정성과 정밀도를 동시에 달성한 첫 SAE 기반 편집 프레임워크입니다.
MicroEdit 방법론 상세 설명
본 논문의 방법론은 “뉴런 단위 최소 개입(neuron-level minimal intervention)” 을 통해
Edit Overshooting 과 Knowledge Entanglement 를 동시에 완화하는 구조입니다 .
전체 구조는 다음의 3가지 핵심 구성요소로 이루어집니다:
- Sparse Autoencoder (SAE) 기반 편집
- Switch Mechanism (ARD 기반 in/out scope 분리)
- Gradient Masking + Two-stage Training
1. Lifelong Knowledge Editing 문제 설정
모델은 초기 파라미터 에서 시작하여,
T번의 순차적 편집을 거쳐 로 변환됩니다:
편집 목표는 다음과 같이 정의됩니다:
즉,
- 편집된 샘플에서는 정답을 바꿔야 하고
- 비관련 샘플에서는 원래 동작을 유지해야 함
이를 평가하기 위해 세 가지 지표 사용 :
- Reliability: 편집 성공률
- Generalization: 의미적으로 유사한 문장에서도 수정 유지
- Locality: unrelated knowledge 보존 정도
2. 핵심 아이디어: 왜 SAE인가?
기존 문제
- 전체 weight 수정 → Overshooting
- Polysemantic neuron → Entanglement
해결 전략
SAE의 두 가지 특성을 활용:
| SAE 특성 | MicroEdit에서의 역할 |
|---|---|
| Overcomplete hidden layer | 더 disentangled feature 표현 |
| Top-k sparse activation | 최소 뉴런만 활성 → 최소 수정 |
즉, 편집은 전체 모델이 아니라, 일부 뉴런 서브스페이스에서만 일어나야 한다
3. SAE 기반 편집 구조
(A) 삽입 위치
- LLM의 특정 layer l 의 residual stream z 를 hook
- Base LLM은 freeze
- SAE encoder는 freeze
- decoder만 학습
(B) Encoder 단계
입력 residual:
SAE 인코딩:
- Top-k만 남김
- 희소 activation 유지
- k개의 뉴런만 활성
→ 편집은 이 k개의 뉴런에만 의존
(C) Decoder 단계
재구성:
이때 representation 변화:
⚠ 중요:
- 편집은 decoder weight의 일부 row에만 영향
- 서브스페이스 내에서만 representation 변화
- Overshooting 자연적 방지
(D) Editing Loss
여기서:
즉,
- LLM → layer l까지 forward
- SAE로 representation 변형
- 나머지 LLM으로 출력 생성
- 원하는 target output과 cross entropy
4. Switch Mechanism (ARD 기반)
SAE는 완벽히 reconstruction하지 못합니다.
모든 입력을 SAE 통과시키면:
→ 비편집 지식도 왜곡됨
따라서, MicroEdit은 ARD (Average Reconstruction Distance) 를 도입:
inference 시:
의미:
- ARD 낮음 → SAE가 잘 reconstruction → in-scope knowledge
- ARD 높음 → unrelated → 원본 유지
→ Locality 유지 핵심 장치
5. Gradient Masking (Local Update 보장)
Full gradient:
Mask:
Update:
즉,
- 활성 뉴런에 해당하는 decoder row만 업데이트
- 나머지 weight는 완전히 freeze
→ Lifelong editing에서 안정성 확보
6. Two-Stage Training 전략
ARD와 editing objective를 동시에 최적화하면 학습 불안정
따라서 2단계 학습:
Stage 1 — Distance Regularization
- ARD gap을 키움
- in/out scope 분리 강화
Stage 2 — Joint Optimization
- 편집 성공률 확보
- ARD separation 유지
7. 전체 알고리즘 흐름
Editing 단계
- x 입력
- layer l까지 forward
- SAE encoder (Top-k)
- decoder reconstruction
- masked gradient로 decoder 업데이트
Inference 단계
- ARD 계산
- threshold 기반 switch
- edited representation 또는 original 사용
8. 왜 이 방법이 Lifelong Editing에 강한가?
| 기존 방법 | MicroEdit |
|---|---|
| weight 전체 수정 | 뉴런 subset만 수정 |
| entangled neuron 문제 존재 | SAE overcomplete로 disentangle |
| sequential edit 시 붕괴 | 서브스페이스 제한으로 안정성 유지 |
| memory expansion 필요 | 기존 모델 내부에서 해결 |
9. 구조적 해석 (Interpretability 관점)
MicroEdit는 사실상:
SAE feature subspace에서의 constrained low-rank representation steering
과 유사합니다.
- ROME → weight rank-1 update
- GRACE → external memory replacement
- MicroEdit → sparse feature basis steering
따라서 mechanistic interpretability와 매우 밀접한 접근입니다.
10. 핵심 요약
MicroEdit의 방법론은 다음 수식으로 요약 가능합니다:
그리고
즉,
편집은 sparse neuron subspace에서만 이루어진다.
MicroEdit 실험 결과 상세 분석
논문은 QA (ZsRE) 와 Hallucination (SelfCheckGPT) 두 설정에서
LLaMA-3-8B, Mistral-7B 모델을 대상으로 실험을 수행했습니다 .
핵심은:
장기적 연속 편집 (1K ~ 5K edits 이상)에서 얼마나 안정적으로 유지되는가
1. 실험 설정 요약
데이터셋
| 설정 | 데이터셋 | 목적 |
|---|---|---|
| QA | ZsRE | factual knowledge 수정 |
| Hallucination | SelfCheckGPT | 잘못된 문장 교정 |
평가 지표
- Reliability (Rel.): 편집 성공률
- Generalization (Gen.): 유사 질문에서도 수정 유지
- Locality (Loc.): unrelated knowledge 보존
2. ZsRE 결과 (QA 설정)
아래는 LLaMA-3-8B에서의 주요 결과입니다 .
(A) 1K edits
| Method | Rel | Gen | Loc | Avg |
|---|---|---|---|---|
| GRACE | 0.90 | 0.39 | 1.00 | 0.76 |
| WISE | 0.61 | 0.57 | 1.00 | 0.73 |
| MicroEdit | 0.87 | 0.65 | 1.00 | 0.84 |
해석:
- GRACE는 reliability는 높지만 generalization이 낮음
- WISE는 안정성은 좋으나 edit 성능 감소
- MicroEdit는 세 지표 모두 균형 잡힘
(B) 3K / 5K edits (Scaling Test)
| T | Method | Avg |
|---|---|---|
| 3000 | GRACE | 0.72 |
| 3000 | WISE | 0.64 |
| 3000 | MicroEdit | 0.81 |
| 5000 | GRACE | 0.66 |
| 5000 | WISE | 0.61 |
| 5000 | MicroEdit | 0.78 |
핵심 포인트:
- 5K edits에서 2등 대비 +12% 개선
- GRACE는 generalization 붕괴
- WISE는 edit 누적 시 성능 감소
- MicroEdit만 장기 안정성 유지
이 결과가 논문의 가장 강력한 기여입니다 .
3. SelfCheckGPT (Hallucination 설정)
Hallucination 교정은 더 어려운 문제입니다.
LLaMA-3-8B (600 edits)
| Method | Rel (PPL↓) | Loc |
|---|---|---|
| GRACE | 9.94 | 1.00 |
| WISE | 3.70 | 1.00 |
| MicroEdit | 2.26 | 1.00 |
–> MicroEdit가 가장 낮은 Perplexity (환각 감소 효과 큼)
Mistral-7B
MicroEdit 역시 안정적으로 유지:
- Rel ≈ 2.20
- Loc ≈ 1.00
ROME/MEMIT/MEND는 중간에 붕괴 발생.
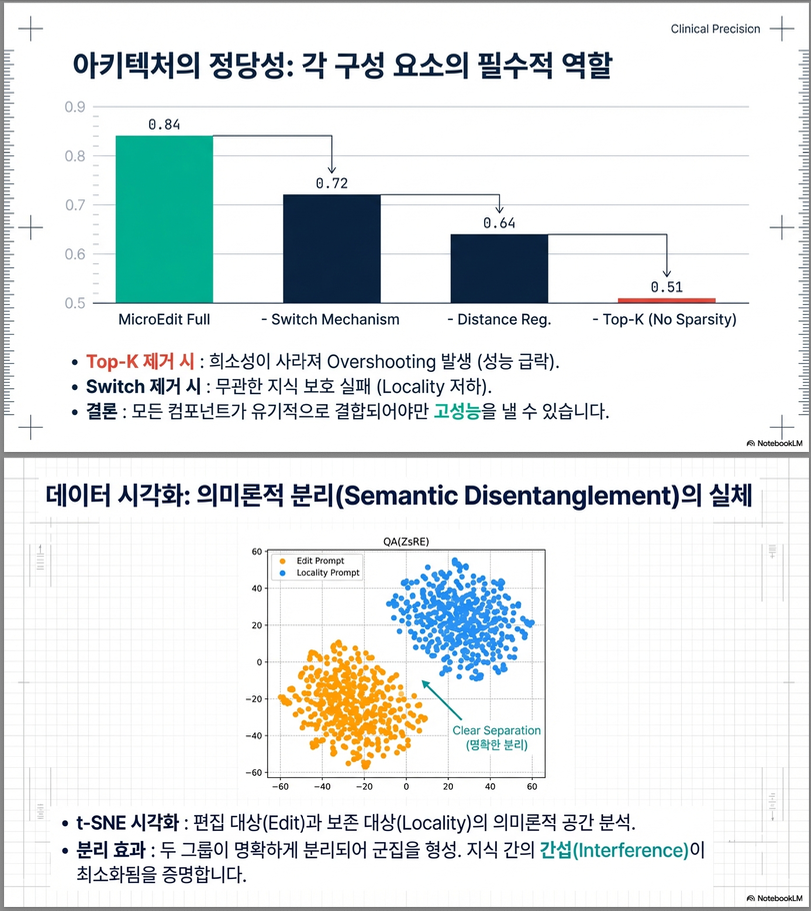
4. Ablation Study
Top-k 제거
| Setting | Avg |
|---|---|
| MicroEdit | 0.84 |
| – TopK | 0.51 |
→ Top-k가 핵심
→ sparsity 없으면 Overshooting 발생
Switch 제거
| Setting | Loc |
|---|---|
| With Switch | 1.00 |
| Without | 0.67 |
→ Switch가 locality 유지의 핵심
Distance Regularization 제거
성능 급감 → ARD 분리 실패
5. Layer 분석
후반부 레이어에서 편집이 가장 효과적 .
이유:
- 초기 레이어 → low-level syntax
- 중간 레이어 → semantic abstraction
- 후반 레이어 → factual memory 집중
6. Top-k 민감도 분석
- k 너무 작으면 정보 부족
- k 너무 크면 neuron sharing 증가 → Entanglement
논문에서는 k=192 (LLaMA) 가 최적 .
7. ARD Threshold 분석
최적 임계값 ≈ 0.55 .
- 너무 낮으면 편집 미적용
- 너무 높으면 unrelated knowledge 왜곡
8. 10K Editing 실험
| T=10K | Rel | Gen | Loc | Avg |
|---|---|---|---|---|
| MicroEdit | 0.72 | 0.47 | 1.00 | 0.73 |
성능은 감소하지만 여전히 usable 수준 유지.
저자 해석:
Polysemantic neuron은 완전히 제거 불가능 → 완전한 disentanglement는 어려움.
9. 전체 성능 패턴 비교
| Method | Single Edit | Long-term Stability | Locality | Generalization |
|---|---|---|---|---|
| FT | 높음 | 붕괴 | 낮음 | 낮음 |
| ROME | 높음 | 급격 붕괴 | 낮음 | 낮음 |
| MEND | 초기만 좋음 | 실패 | 낮음 | 낮음 |
| GRACE | 안정성 좋음 | generalization 약함 | 높음 | 낮음 |
| WISE | 균형적 | 점진적 감소 | 높음 | 중간 |
| MicroEdit | 높음 | 가장 안정적 | 높음 | 높음 |
10. 핵심 결론
MicroEdit 실험 결과는 다음을 입증합니다:
- Overshooting 억제 성공
- Entanglement 완화 성공
- 5K+ edits에서도 안정성 유지
- QA + Hallucination 모두에서 SOTA
특히,
기존 방법은 Reliability–Locality trade-off가 존재
MicroEdit는 이를 동시에 만족
한 줄 요약
MicroEdit는
“long-sequence knowledge editing에서 유일하게 안정적인 방법”
이라는 점이 실험적으로 확인되었습니다.
답글 남기기