
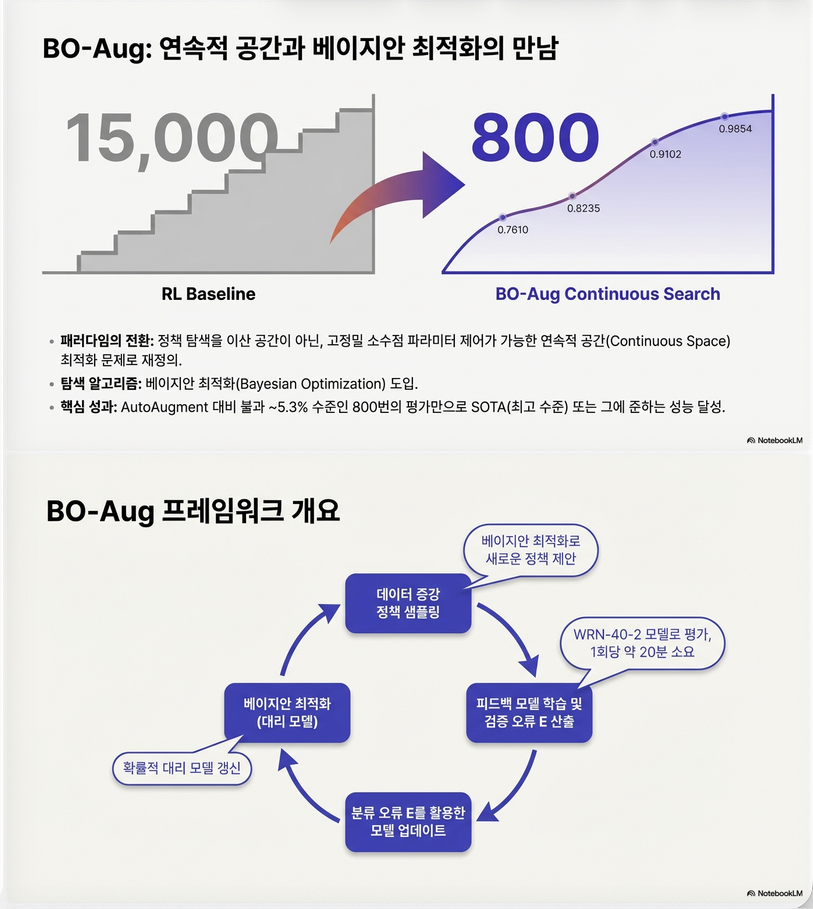





이 논문은 **데이터 증강(Data Augmentation) 정책을 Bayesian Optimization(BO)으로 자동 탐색하는 방법(BO-Aug)**을 제안합니다. 핵심은 AutoAugment보다 훨씬 적은 계산 비용으로 데이터 증강 정책을 자동으로 찾는 것입니다.
1. 연구 배경 및 문제
딥러닝에서 데이터 양 부족 → overfitting → 일반화 성능 저하 문제가 있습니다.
대표적인 해결책:
- regularization (dropout, batch norm)
- data augmentation (이미지 변형으로 데이터 증가)
하지만 데이터 증강 정책 설계는 사람이 직접 해야 하는 경우가 많음
예
- rotation
- shear
- brightness
- translation
- color
문제:
- 어떤 변형을 써야 할지 전문가 경험 필요
- 조합이 매우 많음
- 최적 policy 찾는 비용이 매우 큼
예: AutoAugment
- RL 기반 정책 탐색
- 15,000번 모델 학습 필요
→ 계산 비용 매우 큼
따라서 논문 질문:
적은 비용으로 자동 data augmentation policy를 찾을 수 있을까?
2. 핵심 아이디어: BO-Aug
논문이 제안한 방법
BO-Aug (Bayesian Optimization Augmentation)
핵심:
Data Augmentation policy search
↓
Bayesian Optimization
↓
좋은 policy 샘플링
↓
모델 학습 후 validation error 측정
↓
BO surrogate model 업데이트논문 Figure 1 (p.3) 구조:
Sample DA policy
↓
Train model with policy
↓
Get validation error
↓
Update BO surrogate
↓
Next policy3. Data Augmentation Policy 구조
논문에서 policy 구조는 AutoAugment와 유사합니다.
3.1 Policy 구조
policy = 3개의 sub-policy
각 sub-policy:
operation1
operation2
probability
magnitude즉
policy = 3 sub-policies
sub-policy = 2 operations예 (논문 p.8)
Sub-policy:
(Color, p=0.76, m=1.6)
(TranslateX, p=0.54, m=7.3)3.2 Transformation 종류
논문 Table 1 (p.7)
대표적인 이미지 변환:
| Operation | 설명 |
|---|---|
| ShearX/Y | 기울이기 |
| TranslateX/Y | 이동 |
| Rotate | 회전 |
| Solarize | threshold inversion |
| Posterize | bit depth 감소 |
| Contrast | 대비 조정 |
| Color | 색상 변화 |
| Brightness | 밝기 |
| Sharpness | 선명도 |
| Equalize | 히스토그램 균등화 |
| Invert | 색 반전 |
총 14개 연산
4. Search Space 정의
policy를 벡터로 표현합니다.
sub-policy
p_sub = [opers, p1, m1, p2, m2]설명
| 변수 | 의미 |
|---|---|
| opers | operation pair |
| p1 | op1 probability |
| m1 | op1 magnitude |
| p2 | op2 probability |
| m2 | op2 magnitude |
policy vector
policy = 3 sub-policy
따라서
p ∈ 즉
policy = 15차원 continuous vector이게 중요한 차이입니다.
AutoAugment는 discrete search
BO-Aug는 continuous optimization
5. Optimization 문제 정의
논문 식 (1):
설명
| 기호 | 의미 |
|---|---|
| p | augmentation policy |
| m | classification model |
| d | dataset |
| u(p,d) | policy 적용 dataset |
| f | validation error |
즉
policy → dataset augmentation → model train → errorerror 최소 policy 찾기
6. Bayesian Optimization 적용
BO는 다음 구성요소를 사용합니다.
6.1 Surrogate model
논문에서 사용:
Gaussian Process (GP)
GP 모델:
f(x) ~ GP(μ(x), k(x,x'))kernel:
Matern kernel또한
- hyperparameter는
- MCMC로 sampling
6.2 Acquisition function
논문 사용:
Expected Improvement (EI)
식 (p.10)
의미
| 항 | 의미 |
|---|---|
| μ(x) | GP mean |
| σ(x) | GP std |
| v* | 현재 best value |
EI는
현재 best보다 개선 가능성을 계산합니다.
6.3 BO iteration
Algorithm (p.10)
for t = 1..T
1. EI 최대 policy 선택
2. policy 적용 모델 학습
3. validation error 측정
4. GP 업데이트7. Search Cost 비교
논문 핵심 장점
| 방법 | real evaluation |
|---|---|
| AutoAugment | 15,000 |
| BO-Aug | 800 |
즉
BO-Aug = 1/20 cost8. 실험
Dataset
| dataset |
|---|
| CIFAR-10 |
| CIFAR-100 |
| SVHN |
또한
Reduced CIFAR-10 (4000 images)
Reduced SVHN (1000 images)policy search는 reduced dataset에서 수행.
9. 실험 결과
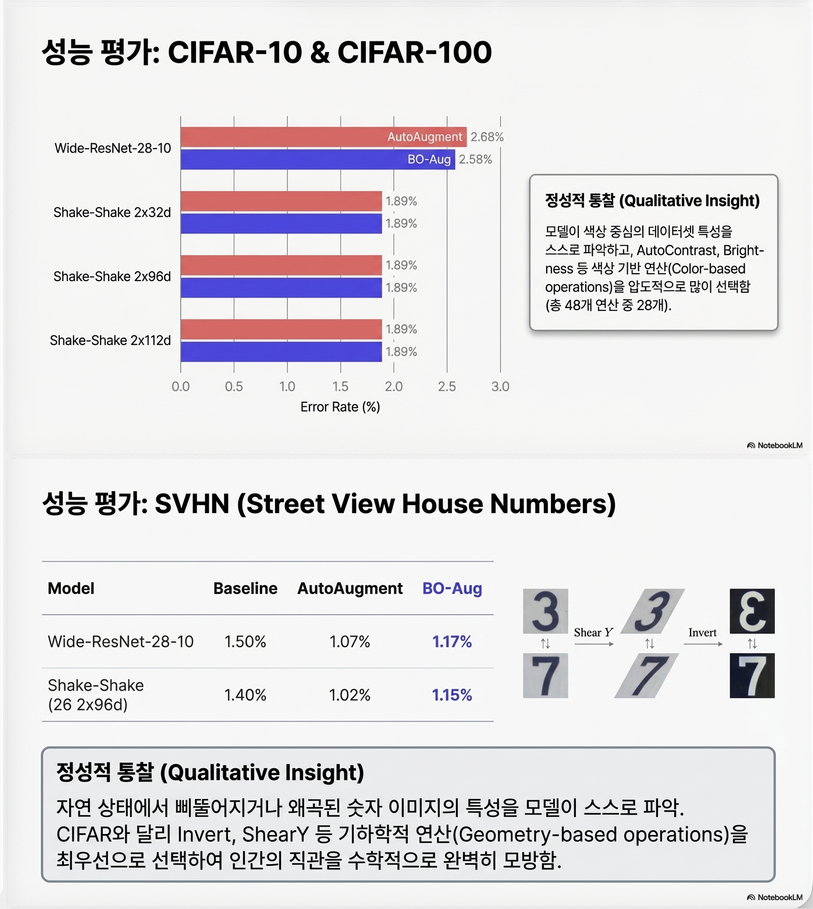
CIFAR-10
| Model | Baseline | AutoAug | BO-Aug |
|---|---|---|---|
| WRN-28-10 | 3.87 | 2.68 | 2.58 |
| ShakeShake | 3.55 | 2.47 | 2.43 |
CIFAR-100
| Model | AutoAug | BO-Aug |
|---|---|---|
| WRN | 17.09 | 16.58 |
SVHN
| Model | AutoAug | BO-Aug |
|---|---|---|
| WRN | 1.07 | 1.17 |
→ 거의 동일 성능
10. 중요한 발견
1. 작은 데이터에서 효과 큼
Reduced dataset에서 개선이 큼
이유:
Data augmentation 효과
≈ 데이터 부족할수록 큼2. Policy Transfer 가능
놀랍게도
policy(CIFAR10)
→ CIFAR100에서도 효과또
policy(WideResNet)
→ ShakeShake에서도 사용 가능즉
policy generalization 존재11. 논문의 핵심 기여
(1) BO 기반 augmentation policy search
- AutoAugment보다 효율적
(2) continuous search space
AutoAugment: discrete RL search
BO-Aug: continuous optimization
(3) low search cost
800 evaluations vs 15000 evaluations(4) policy transferability
- dataset
- model architecture
12. 한줄 정리
이 논문은
Bayesian Optimization을 이용해 데이터 증강 정책을 자동으로 탐색하여 AutoAugment보다 훨씬 적은 계산 비용으로 유사한 성능을 달성한 방법 (BO-Aug)을 제안한 연구입니다.
논문의 **방법론(Methodology)**은 크게 다음 세 단계로 구성됩니다.
- Data Augmentation Policy Search Space 설계
- Bayesian Optimization 기반 Policy 탐색 알고리즘
- Policy 평가 및 반복 업데이트
아래에서 논문의 방법론을 수식, 알고리즘 흐름, 설계 의도까지 포함하여 설명하겠습니다.
1. 문제 정의 (Optimization Formulation)
논문은 data augmentation policy 탐색 문제를 다음과 같은 black-box optimization 문제로 정의합니다.
여기서
| 기호 | 의미 |
|---|---|
| p | data augmentation policy |
| P | policy search space |
| d | dataset |
| m | image classification model |
| u(p,d) | policy를 dataset에 적용하여 augmentation 수행 |
| validation classification error |
즉 전체 과정은
policy p
↓
dataset augmentation
↓
model training
↓
validation error이 validation error를 최소화하는 policy를 찾는 문제입니다.
2. Data Augmentation Policy 설계
2.1 Policy 구조
논문은 AutoAugment와 동일한 policy 구조를 사용합니다.
policy 구성
policy
├ sub-policy 1
├ sub-policy 2
└ sub-policy 3각 sub-policy
operation 1
operation 2각 operation에는
- probability
- magnitude
가 존재합니다.
Sub-policy 구조
| 변수 | 의미 |
|---|---|
| opers | operation pair |
| p_1 | op1 probability |
| m_1 | op1 magnitude |
| p_2 | op2 probability |
| m_2 | op2 magnitude |
Policy vector
policy = 3 sub-policy
따라서
즉 15차원 continuous vector optimization 문제가 됩니다.
3. Data Augmentation Operation Space
논문에서는 **Python Imaging Library(PIL)**의 14개 변환을 사용합니다.
대표적인 operation
| Operation | 설명 |
|---|---|
| ShearX/Y | 기울이기 |
| TranslateX/Y | 이미지 이동 |
| Rotate | 회전 |
| Solarize | threshold inversion |
| Posterize | bit depth reduction |
| Contrast | 대비 조정 |
| Color | 색상 변경 |
| Brightness | 밝기 변경 |
| Sharpness | 선명도 변경 |
| AutoContrast | contrast 자동 조정 |
| Equalize | histogram equalization |
| Invert | 색 반전 |
각 operation에는
probability ∈ [0,1]
magnitude ∈ [0,9]가 존재합니다.
4. Policy Search Algorithm: Bayesian Optimization
Policy 탐색은 **Bayesian Optimization (BO)**을 사용합니다.
BO는 expensive black-box function optimization에 적합합니다.
특징
- gradient 필요 없음
- evaluation cost 최소화
- exploration + exploitation 균형
4.1 Bayesian Optimization 구조
BO는 다음 반복 구조를 가집니다.
1. surrogate model 학습
2. acquisition function 최대화
3. candidate policy 선택
4. 실제 모델 평가
5. 데이터 업데이트논문에서는
policy → 모델 학습 → validation error이 real evaluation입니다.
5. Surrogate Model
논문에서는 **Gaussian Process (GP)**를 사용합니다.
GP는 다음 형태입니다.
여기서
| 요소 | 의미 |
|---|---|
| μ(x) | mean function |
| k(x,x′) | kernel function |
논문 설정
mean function = 0
kernel = Matern kernelGP는 policy 공간에서
policy → expected error를 예측합니다.
6. GP Hyperparameter 학습
논문에서는
MCMC sampling으로 kernel hyperparameter를 추정합니다.
hyperparameter
- length-scale
- variance
추정 과정
sample hyperparameter
↓
여러 surrogate model 생성
↓
평균 모델 사용7. Acquisition Function
논문에서는 **Expected Improvement (EI)**를 사용합니다.
EI 식
여기서
| 변수 | 의미 |
|---|---|
| 현재 best value | |
| μ(x) | GP mean |
| σ(x) | GP std |
| Φ | normal CDF |
| φ | normal PDF |
의미: 현재 best보다 improvement 가능성
8. Policy Evaluation
BO가 선택한 policy는 실제 모델을 학습해서 평가합니다.
논문 설정
feedback model
Wide ResNet 40-2과정
policy 적용
↓
training dataset augmentation
↓
model training
↓
validation error 계산이 error가 BO feedback입니다.
9. BO-Aug 전체 알고리즘
논문 Algorithm 1을 정리하면 다음과 같습니다.
BO-Aug Algorithm
for T = 1..8
1. policy 초기화 (random)
for iteration = 1..100
1. GP surrogate 업데이트
2. acquisition function (EI) 최대 policy 선택
3. policy로 model training
4. validation error 계산
5. observation set 업데이트
최적 policy 저장최종 결과
8 policy runs
↓
총 24 sub-policies10. Computational Cost
AutoAugment: 15,000 evaluations
BO-Aug: 800 evaluations
즉, 약 20배 비용 감소입니다.
11. 전체 방법론 구조
최종 구조를 정리하면
Data Augmentation Policy Search
1. Policy representation
↓
2. Continuous search space (R^15)
↓
3. Bayesian Optimization
↓
4. Gaussian Process surrogate
↓
5. Expected Improvement acquisition
↓
6. Model training evaluation
↓
7. Policy update12. 방법론 핵심 아이디어
이 논문의 핵심 방법론은 다음 세 가지입니다.
(1) discrete → continuous search
AutoAugment
discrete RL searchBO-Aug
continuous BO search(2) expensive evaluation 최소화
BO는
sample-efficient optimization(3) transferable policy
policy를
dataset
architecture간에 재사용 가능
AutoAugment (Google Brain, 2019)
AutoAugment는 이미지 분류에서 데이터 증강(data augmentation) 정책을 자동으로 학습하는 방법입니다.
핵심 아이디어는 다음과 같습니다.
사람이 augmentation rule을 설계하는 대신, 강화학습(RL)을 이용하여 augmentation policy를 자동 탐색한다.
대표 논문
- AutoAugment: Learning Augmentation Policies from Data (Cubuk et al., 2019)
이 방법은 이후 RandAugment, TrivialAugment, Faster AutoAugment 등의 연구로 이어졌습니다.
1. 연구 배경
딥러닝에서 데이터 증강은 매우 중요한 역할을 합니다.
예를 들어 이미지 분류에서 흔히 사용하는 변환은 다음과 같습니다.
- Rotate (회전)
- Translate (이동)
- Shear (기울이기)
- Color adjustment
- Brightness
- Cutout
하지만 문제는 다음입니다.
문제
augmentation policy는 보통 사람이 설계합니다.
예:
RandomCrop
HorizontalFlip
ColorJitter하지만
- 어떤 transformation을 써야 하는지
- magnitude를 얼마로 해야 하는지
- 확률을 얼마로 해야 하는지
이것을 수동으로 설계해야 합니다.
2. AutoAugment 핵심 아이디어
AutoAugment는 다음 문제를 풉니다.
최적 data augmentation policy 찾기이를 search problem으로 정의합니다.
augmentation policy
↓
model training
↓
validation accuracy즉
policy → 성능을 평가하면서 최적 policy를 탐색합니다.
3. Augmentation Policy 구조
AutoAugment에서 policy는 다음 구조를 가집니다.
Policy
policy
├ sub-policy 1
├ sub-policy 2
├ sub-policy 3
├ sub-policy 4
└ sub-policy 5보통 5개의 sub-policy로 구성됩니다.
Sub-policy 구조
각 sub-policy는 두 개의 operation으로 구성됩니다.
sub-policy
op1 (probability, magnitude)
op2 (probability, magnitude)예
Rotate (p=0.6, magnitude=20°)
Color (p=0.8, magnitude=0.5)즉 한 sub-policy는
2 operations
2 probabilities
2 magnitudes4. Augmentation Operation 종류
AutoAugment는 다음 변환을 사용합니다.
| Operation | 설명 |
|---|---|
| ShearX | x축 shear |
| ShearY | y축 shear |
| TranslateX | x 이동 |
| TranslateY | y 이동 |
| Rotate | 회전 |
| Color | 색상 조정 |
| Posterize | bit reduction |
| Solarize | threshold inversion |
| Contrast | 대비 조정 |
| Sharpness | 선명도 |
| Brightness | 밝기 |
| AutoContrast | contrast 자동 조정 |
| Equalize | histogram equalization |
| Invert | 색 반전 |
총 16개 transformation 정도 사용됩니다.
5. Policy Search 방법 (Reinforcement Learning)
AutoAugment는 Reinforcement Learning controller를 사용합니다.
구조
Controller (RNN)
↓
augmentation policy 생성
↓
child model training
↓
validation accuracy
↓
reward이 과정을 반복합니다.
6. RL Search 과정
전체 과정은 다음과 같습니다.
Step 1
controller가 augmentation policy 생성
예
Rotate(p=0.6, m=20)
Color(p=0.7, m=0.5)Step 2
child network training
dataset
+ augmentation policy
↓
CNN trainingStep 3
validation accuracy 계산
accuracy = rewardStep 4
controller 업데이트
policy gradientStep 5
다시 policy 생성
이 과정을 반복합니다.
7. AutoAugment 알고리즘 구조
전체 구조
RNN Controller
↓
Sample policy
↓
Train child model
↓
Validation accuracy
↓
Reward
↓
Update controller8. Search Cost 문제
AutoAugment의 가장 큰 문제는 계산 비용입니다.
논문 기준
policy evaluation ≈ CNN training즉
1 policy = 1 CNN training그리고 논문에서는
15000 policies를 평가합니다.
즉
15000 model trainings이 필요합니다.
그래서 논문에서는
500 GPU-days정도의 비용이 필요했습니다.
9. AutoAugment 결과
CIFAR-10 기준
| Method | Error |
|---|---|
| Baseline | 3.87 |
| Cutout | 3.08 |
| AutoAugment | 2.68 |
ImageNet에서도 큰 성능 향상을 보였습니다.
10. AutoAugment의 한계
1. 계산 비용 매우 큼
15000 model trainings2. discrete search
operation magnitude가 discrete입니다.
3. dataset마다 search 필요
CIFAR policy ≠ ImageNet policy
11. 후속 연구
AutoAugment 이후 많은 연구가 등장했습니다.
| 방법 | 특징 |
|---|---|
| Fast AutoAugment | density matching |
| RandAugment | search 제거 |
| TrivialAugment | 단일 operation |
| BO-Aug | Bayesian optimization |
| Faster AutoAugment | gradient search |
12. RandAugment (AutoAugment 개선)
RandAugment는 다음 단순화합니다.
AutoAugment
operation
probability
magnitudeRandAugment
N = number of ops
M = magnitude즉 2개 hyperparameter만 사용
13. AutoAugment의 중요한 의미
AutoAugment는 처음으로
data augmentation
→ learned policy를 제안했습니다.
즉
augmentation = hyperparameter가 아니라
augmentation = learnable policy로 바뀌었습니다.
14. BO-Aug와의 차이 (중요)
| 항목 | AutoAugment | BO-Aug |
|---|---|---|
| search | RL | Bayesian optimization |
| search space | discrete | continuous |
| evaluation | 15000 | 800 |
| compute cost | 매우 큼 | 낮음 |
BO-Aug에서 Bayesian Optimization의 핵심은 Gaussian Process(GP) surrogate model입니다. 여기서는 다음 세 가지를 체계적으로 설명하겠습니다.
- Gaussian Process (GP) 개념
- GP regression 수식 (posterior)
- GP hyperparameter 학습
- MCMC sampling으로 hyperparameter 추정하는 이유
- BO-Aug에서 실제 사용 방식
1. Gaussian Process (GP) 개념
Gaussian Process는 함수 자체에 대한 확률 모델입니다.
보통 regression에서는
여기서
- f(x) = unknown function
- 우리는 이 함수를 확률분포로 모델링합니다.
GP에서는
즉
함수 값들의 집합이 multivariate Gaussian distribution을 따른다.
GP 직관
예를 들어 어떤 함수 f(x)를 모른다고 가정합니다.
GP는 다음과 같이 생각합니다.
가능한 함수들f1(x)
f2(x)
f3(x)
f4(x)
...즉, function distribution입니다.
GP 구성요소
GP는 두 가지로 정의됩니다.
(1) mean function
m(x) = E[f(x)]
보통 m(x)=0 으로 둡니다.
(2) kernel (covariance)
k(x,x’)
두 input 사이 유사도를 의미합니다.
예
- 가까운 x → 비슷한 y
- 먼 x → 다른 y
GP 의미
입력: x
출력: f(x)
하지만 f(x)은 deterministic이 아니라 Gaussian distribution입니다.
2. GP Regression
우리는 데이터 를 관측했다고 가정합니다.
Prior
먼저 prior
Joint distribution
training + test point
는 다음 분포를 가집니다.
Posterior
조건부 분포를 계산하면
Posterior mean
Posterior variance
의미
mean: GP가 예측한 값
variance: 불확실성입니다.
3. Kernel (Covariance Function)
Kernel은 함수 smoothness를 결정합니다.
대표적인 kernel
RBF kernel
hyperparameter
| parameter | 의미 |
|---|---|
| l | length-scale |
| variance |
Matern kernel
BO-Aug에서 사용
특징
RBF보다 rough한 함수 모델링 가능4. GP Hyperparameter
Kernel에는 hyperparameter가 있습니다.
예
| parameter | 의미 |
|---|---|
| length-scale l | smoothness |
| signal variance | amplitude |
| noise variance | observation noise |
이 값들이 GP 성능을 크게 좌우합니다.
5. Hyperparameter Learning
보통 GP hyperparameter는 입니다.
이를 데이터로부터 학습합니다.
Marginal likelihood
GP에서는 다음 likelihood를 사용합니다.
log likelihood
일반적인 방법
hyperparameter는 보통 MLE 또는 gradient optimization 으로 찾습니다.
6. BO-Aug에서 MCMC Sampling
논문에서는 MCMC로 hyperparameter를 sampling합니다.
왜냐하면 hyperparameter uncertainty를 반영하기 위해서입니다.
Bayesian Treatment
우리는 posterior를 구하고 싶습니다.
Bayes rule:
하지만
는 analytic solution이 없습니다.
그래서 MCMC sampling을 사용합니다.
7. MCMC Sampling
MCMC는 다음 분포에서 sampling합니다.
대표적인 알고리즘
- Metropolis-Hastings
- Gibbs
- Hamiltonian Monte Carlo
GP에서 사용 방법
BO-Aug에서는 다음 절차를 사용합니다.
1. hyperparameter prior 설정
2. MCMC로 hyperparameter sampling
3. 여러 GP 모델 생성
4. 평균 surrogate model 사용즉
8. MCMC 사용 이유
MLE 대신 MCMC를 사용하는 이유
(1) hyperparameter uncertainty 반영
MLE: single θ
MCMC: distribution of θ
(2) BO exploration 향상
hyperparameter uncertainty → prediction variance 증가 → exploration 향상
(3) overfitting 감소
MLE는 local optimum 문제 발생 가능
9. BO-Aug에서 GP 역할
BO-Aug에서 GP는 다음을 모델링합니다.
augmentation policy p
↓
validation error즉, f(p)를 GP로 근사합니다.
BO iteration
policy → error데이터:
GP는 policy space 전체에서 error surface를 예측합니다.
10. Acquisition Function 계산
GP는 μ(x), σ(x)를 제공합니다.
이 값을 사용해 Expected Improvement EI(x)를 계산합니다.
11. 전체 BO + GP 구조
최종 pipeline
policy p
↓
GP surrogate
↓
μ(p), σ(p)
↓
acquisition function
↓
next policy 선택12. BO-Aug 핵심 구조
policy search space
↓
Gaussian Process surrogate
↓
hyperparameter sampling (MCMC)
↓
Expected Improvement
↓
policy evaluation
답글 남기기