LLM 논문에 관한 블로그입니다.
-
이 사랑 통역 되나요 촬영지-에노시마
📍 이사랑통역되나요 속 그곳, 에노시마 섬 여행기 도쿄 근교에서 만나는 바다와 로맨스 드라마〈이사랑통역되나요〉를 보다가 눈길을 사로잡은 장소가 있었어요. 바로 가나가와현 후지사와시에 위치한 ‘에노시마 섬’. 바다를 배경으로 한 잔잔한 분위기와 감성적인 풍경 덕분에 “여긴 꼭 가보고 싶다”라는 생각이 들더라고요.그래서 오늘은 방송 속 장면을 떠올리며, 에노시마 섬 여행 정보를 정리해봤어요. 🌊 에노시마 섬은 어떤 곳일까? 에노시마는 도쿄에서…
-
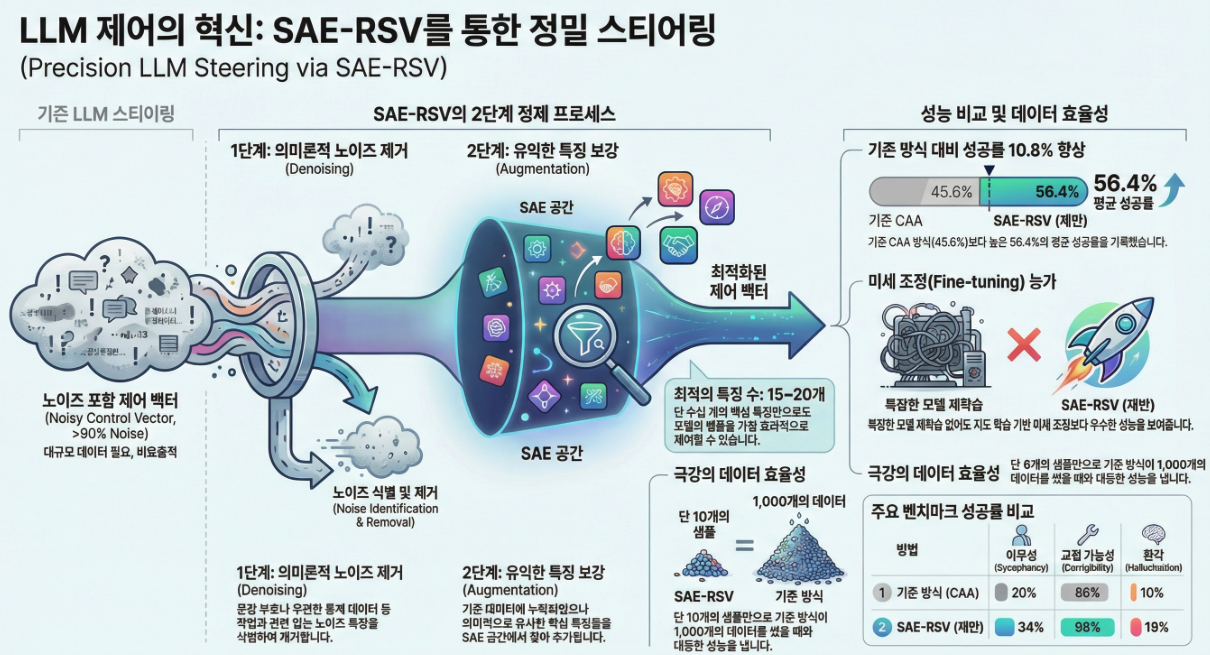
** Enhancing LLM Steering through Sparse Autoencoder-based Vector Refininement (Arxiv 2025)
아래에서는 「Enhancing LLM Steering through Sparse Autoencoder-based Vector Refininement (SAE-RSV)」 논문의 관련연구, 방법론, 실험 결과를 핵심만 구조적으로 정리해 설명합니다. 1. 관련연구 (Related Work) (1) Steering / Difference-in-Means 계열 (2) Sparse Autoencoder(SAE) 기반 Steering (3) 본 논문의 포지션 2. 방법론 (Methodology) 논문은 **SAE-RSV (Sparse Autoencoder-based Refinement of Steering Vector)**라는 2-단계 정제 프레임워크를 제안합니다. (1) 기본 Steering…
-

* Latent Inter-User Difference Modeling for LLM Personalization (EMNLP 2025)
아래에서는 **EMNLP 2025 논문 “Latent Inter-User Difference Modeling for LLM Personalization”**을 중심으로 관련 연구, 방법론, 실험 결과를 연구 흐름 관점에서 정리해 설명합니다. (설명은 논문 전체 내용을 종합한 요약입니다) 1. 관련 연구 (Related Work) (1) LLM 개인화의 주류: Memory-Retrieval Paradigm (2) Inter-User Difference를 명시적으로 다룬 연구 (3) Latent-Space Personalization –> 이 논문의 핵심 포지션 “Inter-user difference는…
-

** Personalized Text Generation with Contrastive Activation Steering (ACL 2025)
아래에서는 ACL 2025 논문 Personalized Text Generation with Contrastive Activation Steering(Zhang et al., 2025)을 기준으로 관련 연구, 방법론, 실험 결과를 구조적으로 정리해 설명합니다. 설명은 논문 본문(Sections 1, 3, 4, 5)과 표·그림(Table 1–3, Figure 1–5 등)을 종합한 것입니다. 1. 관련 연구 (Related Work) 1.1 Personalized Text Generation 기존 개인화 텍스트 생성 연구는 크게 두 계열로 나뉩니다.…
-

* LLMs + Persona-Plug = Personalized LLMs (ACL 2025)
아래에서는 **ACL 2025 논문 「LLMs + Persona-Plug = Personalized LLMs」**의 관련 연구, 방법론, 실험 결과를 논문의 구조와 저자들의 주장에 맞춰 체계적으로 정리합니다. 설명은 왜 기존 접근이 한계가 있었는지 → 무엇을 새로 제안했는지 → 실험으로 무엇이 검증되었는지의 흐름으로 구성했습니다. 1. 관련 연구 (Related Work) 논문은 LLM 개인화(personalization) 접근을 크게 두 계열로 정리합니다. 1.1 Fine-tuned Personalized LLMs…
-
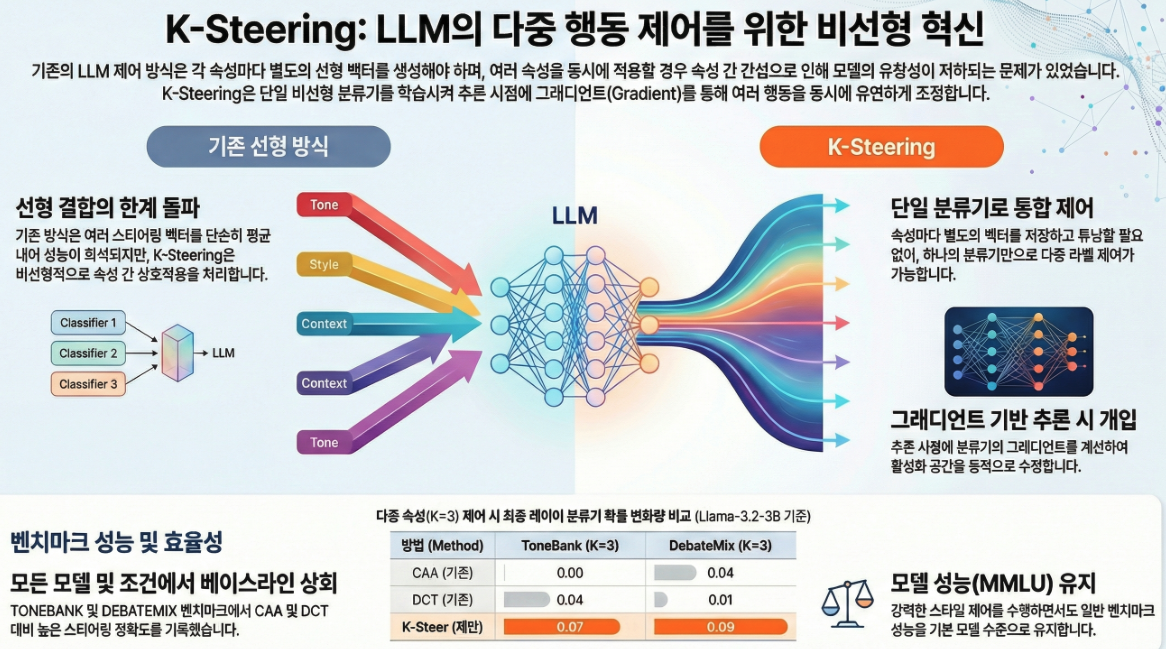
* Beyond Linear Steering: Unified Multi-Attribute Control for Language Models (EMNLP 2025 Findings)
논문 “Beyond Linear Steering: Unified Multi-Attribute Control for Language Models” (EMNLP 2025 Findings) 은 LLM의 복수 속성(behavioral attribute) 제어를 위한 새로운 비선형 스티어링 방법인 K-Steering 을 제안한 연구입니다. 아래에 주요 내용을 정리했습니다. 1. 연구 배경 기존의 Activation Steering (예: CAA, ITI, RepE 등)은 LLM의 은닉 표현(activation)을 선형 벡터로 조작하여 특정 속성(예: 공격성, 공손함, 진실성 등)을 제어하지만, 예: “공손하면서 유머러스한 톤”처럼 복합적인 조합은 단순…
-

** LogitLens4LLMs: Extending Logit Lens Analysis to Modern Large Language Models (arXiv 2025)
아래는 **arXiv 2025 논문 *“LogitLens4LLMs: Extending Logit Lens Analysis to Modern Large Language Models”***에 대한 설명입니다. 설명은 배경 → 방법론 → 시스템 설계 → 시각화 및 결과 → 기여와 한계 순으로 정리했습니다. 1. 연구 배경과 문제의식 Logit Lens는 중간 layer의 hidden state를 최종 LM head로 바로 투사하여, “이 layer에서 이미 어떤 토큰을 예측하고 있는가?”를 관찰하는 대표적인 mechanistic interpretability 기법입니다.…
-
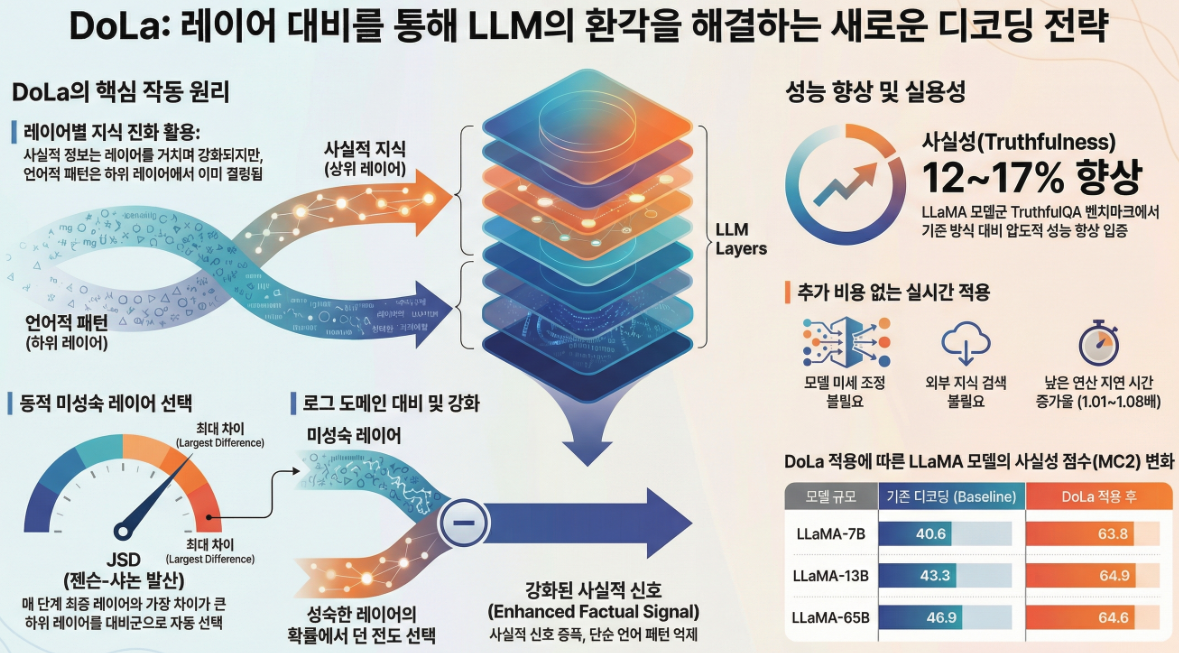
** DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models (ICLR 2024)
다음은 ICLR 2024 논문 “DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models”에 대한 체계적인 설명입니다. 1. 문제의식 (Why DoLa?) 대규모 언어모델(LLM)은 유창하지만 **사실과 다른 내용(hallucination)**을 자주 생성합니다.기존 대응 방식들은 다음과 같은 한계를 가집니다. 👉 이 논문의 핵심 질문은 다음입니다. “이미 학습된 하나의 LLM 내부 구조만 활용해서, 추론 시점(inference-time)에 사실성을 높일 수 없을까?” 2. 핵심…
-
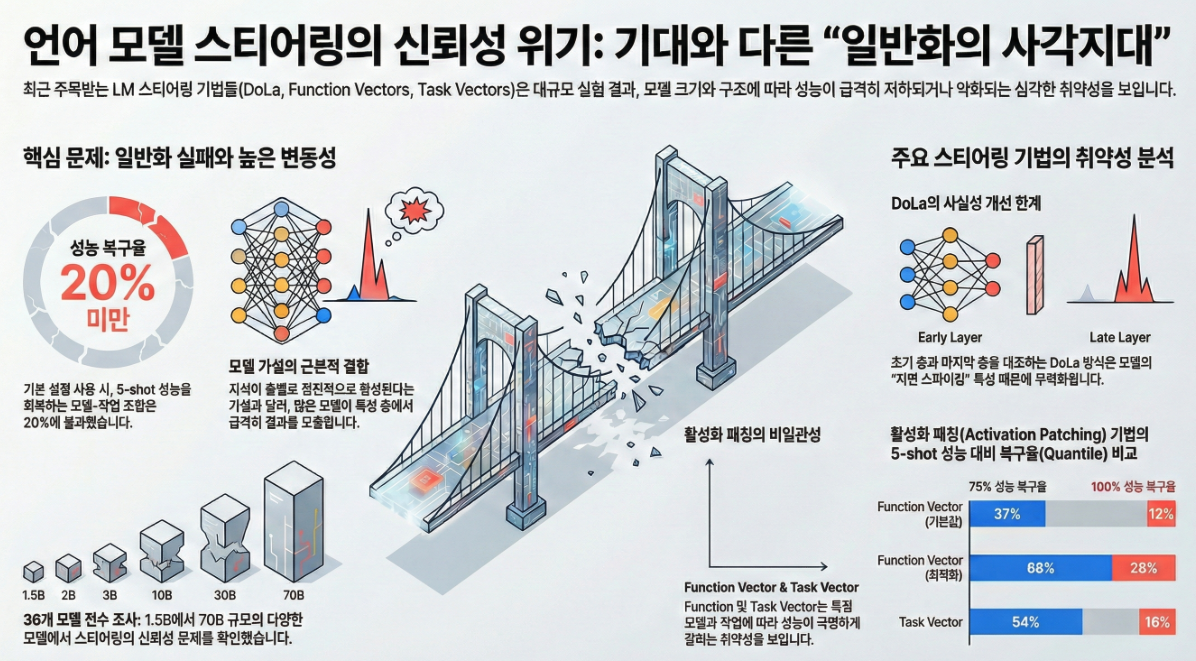
** Steering off Course: Reliability Challenges in Steering Language Models (ACL 2025)
다음은 ACL 2025 논문 “Steering off Course: Reliability Challenges in Steering Language Models”의 핵심 내용 요약입니다. 1. 연구 배경 및 동기 LM Steering의 등장 문제의식 2. 연구 목표와 실험 구성 목표 주요 실험 세팅 실험 요소 설명 모델 패밀리 LLaMA, Qwen, OLMo, Pythia, Mistral 등 평가 데이터셋 TruthfulQA, FACTOR (사실성 평가) ICL(Task Vector) 11개의 언어 및 사실성…
-

** Word Embeddings Are Steers for Language Models (ACL 2024)
다음은 ACL 2024 논문 **”Word Embeddings Are Steers for Language Models”**의 주요 내용을 정리한 설명입니다. 1. 연구 배경 대규모 언어모델(LLM)은 학습 과정에서 자동으로 word embedding을 학습합니다.기존 연구들은 주로 단어 수준에서의 의미적 관계(유사도, 유추 관계 등)에 집중했지만,이 논문은 word embedding이 모델의 생성 스타일(generation style)을 조정하는 역할을 한다는 새로운 시각을 제시합니다. 여기서 연구자들은 **출력 단어 임베딩 공간(output embedding space)**이…
-
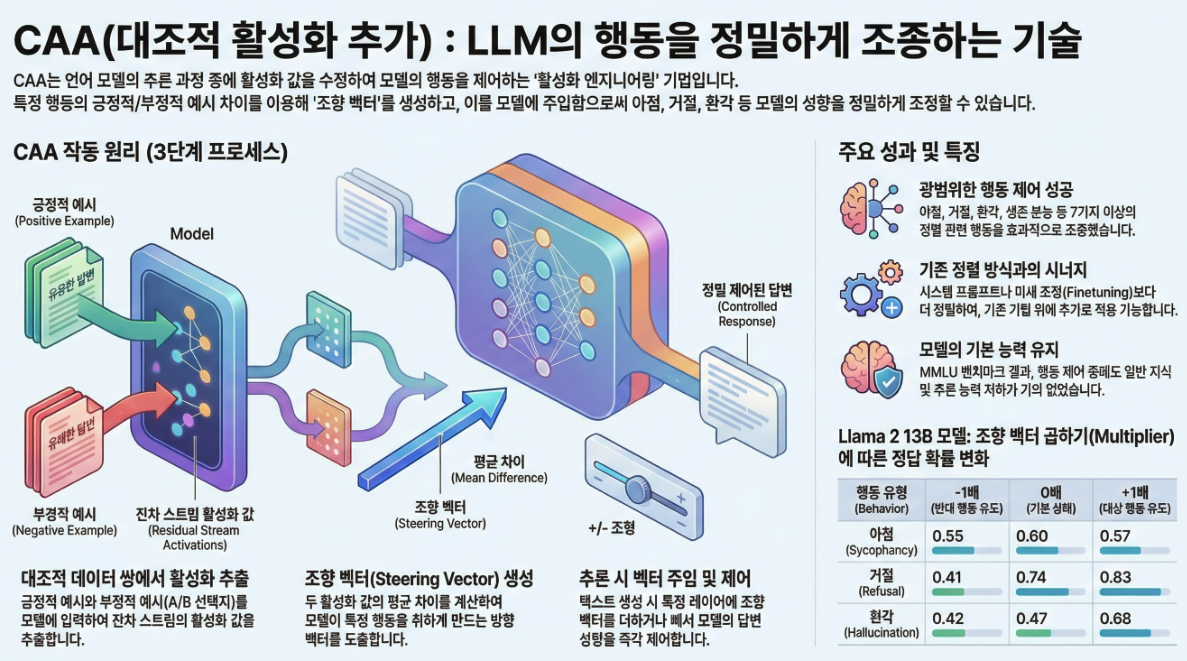
*** Steering Llama 2 via Contrastive Activation Addition (ACL 2024)
논문 **”Steering Llama 2 via Contrastive Activation Addition” (ACL 2024)**의 주요 내용을 요약하면 아래와 같습니다: 📌 개요 (Abstract & Motivation) 🔁 예시: 아첨(sycophancy) vector를 추가하면 모델이 사용자에게 무조건 동조하는 답변을 하게 되고, 빼면 더 사실 중심의 대답을 하게 됩니다. 🧪 방법론: Contrastive Activation Addition (CAA) 1. Steering Vector 생성 데이터 구성: (같은 질문 + 서로 다른…
-
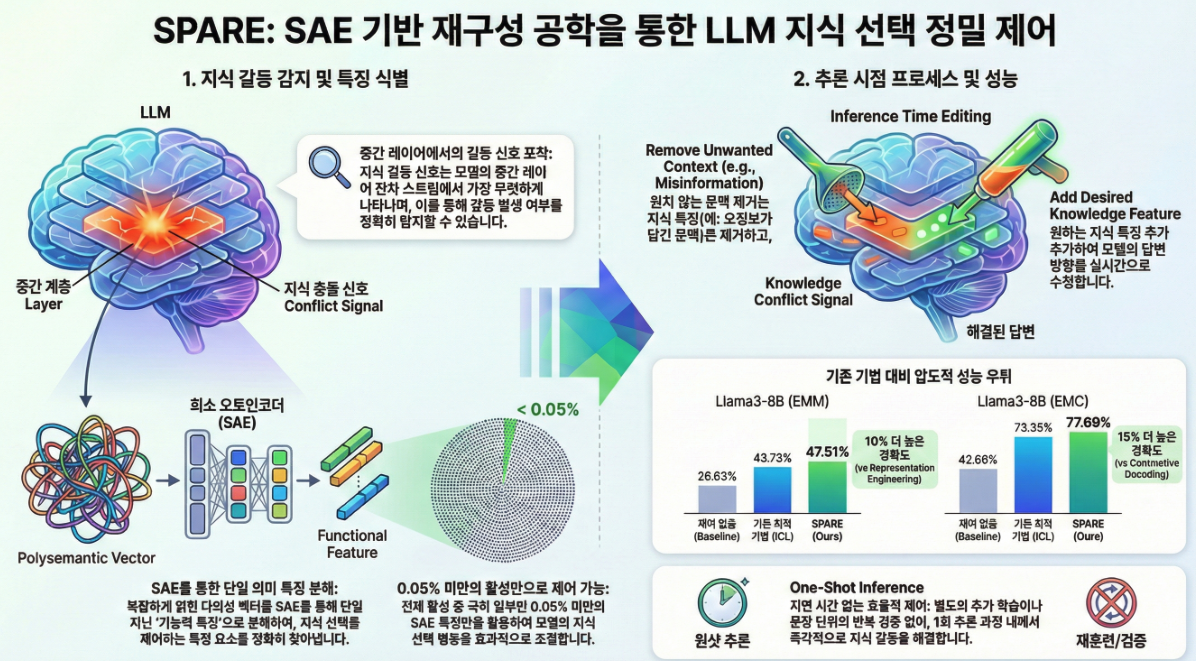
*** Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering (NAACL 2025)
논문 **“Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering” (NAACL 2025)**은대형 언어모델(LLM)이 내부 파라미터(기억된 지식, parametric knowledge)와 입력 문맥(contextual knowledge) 간의 지식 충돌(knowledge conflict) 상황에서 어떤 지식을 사용할지 조절하는 방법을 제안한 연구입니다. 핵심 내용은 다음과 같습니다. 1. 문제 배경: Knowledge Conflict LLMs는 내부적으로 방대한 사실 지식을 학습하지만,새로운 컨텍스트(예: 검색 결과, 최신 정보)가 주어지면 기존 지식과 충돌할 수…
-
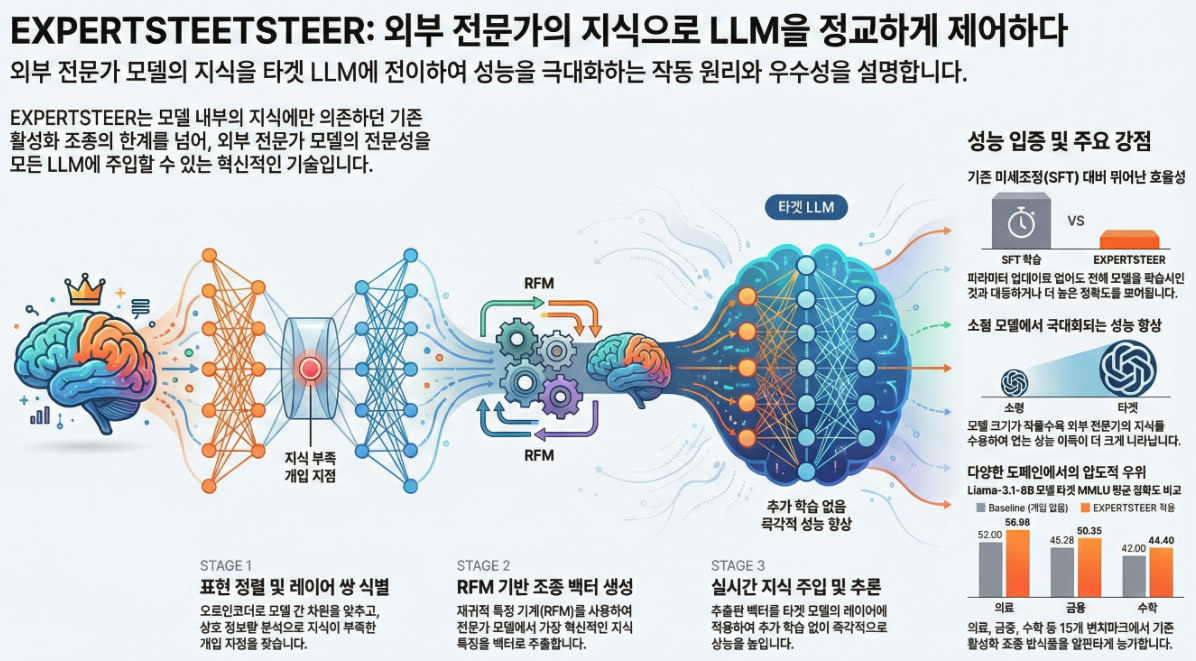
EXPERTSTEER: Intervening in LLMs through Expert Knowledge (arXiv:2505.12313)
아래는 논문 “EXPERTSTEER: Intervening in LLMs through Expert Knowledge”(arXiv:2505.12313) 의 전체 구조, 핵심 아이디어, 방법론, 수식적 의미, 실험 내용 및 분석을 체계적으로 정리한 설명입니다. ⭐ 논문 핵심 기여 요약 EXPERTSTEER는 외부 Expert 모델이 가진 전문 지식을 임의의 Target LLM에 activation steering으로 전달하는 최초의 일반적 방법입니다. 기존 activation steering은 항상 자기 모델이 생성한 steering vector만 사용했기 때문에: 이 논문은 Auto-encoder 기반 차원 정렬…
-
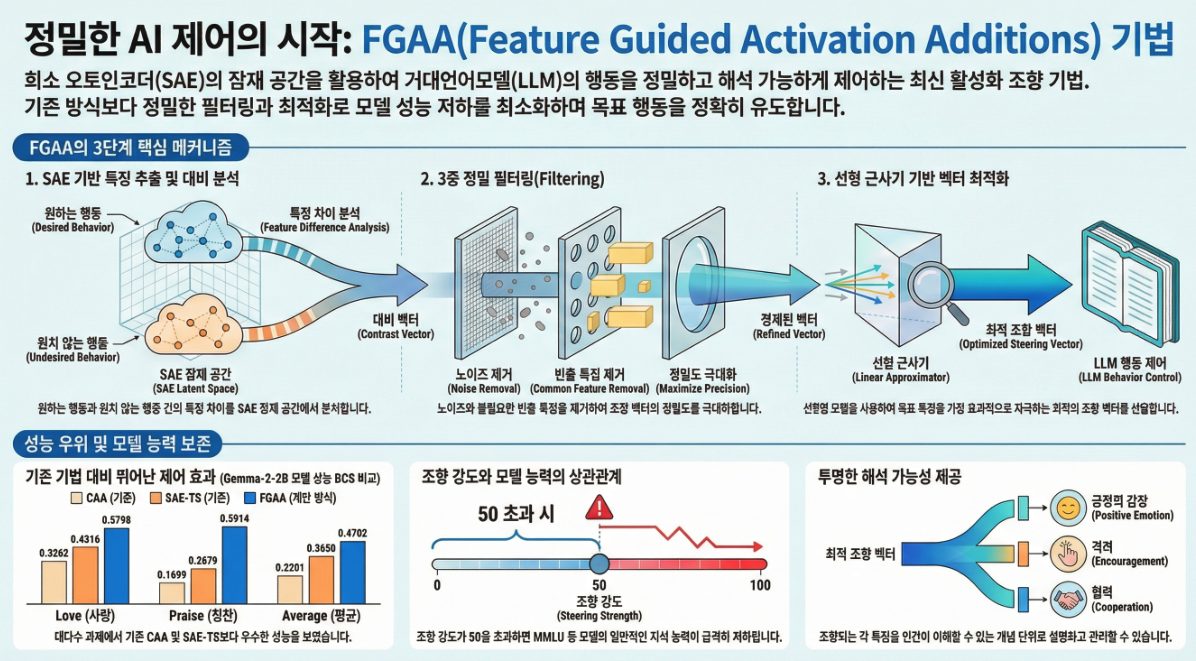
Interpretable Steering of Large Language Models with Feature Guided Activation Additions (FGAA) (ICLR 2025 Building Trust Workshop)
아래는 ICLR 2025 Building Trust Workshop에 게재된“Interpretable Steering of Large Language Models with Feature Guided Activation Additions (FGAA)” 논문의 전체 구조와 핵심 내용을 체계적으로 정리한 설명입니다. 📌 1. 논문의 핵심 문제의식 LLM의 행동을 원하는 방향으로 제어하는 것은 매우 중요한 난제이다.기존 접근 방식은 크게 다음 두 가지 문제가 있었다: ✦ (1) Fine-tuning ✦ (2) Prompt 기반 제어 ✦ (3)…
-

** Improving Instruction-Following in Language Models Through Activation Steering (ICLR 2025)
아래는 ICLR 2025 논문 “Improving Instruction-Following in Language Models Through Activation Steering”의 핵심 내용을 정리한 상세 설명입니다. 📌 연구 문제 LLM들은 지식을 잘 알고 있음에도 사용자가 제시한 세부 지시(instruction)를 완전히 준수하지 못한다는 문제가 존재합니다.예) 연구 질문: LLM 내부에는 “지시를 따르도록 만드는 방향성(벡터)”이 존재하며, 이를 활성화 스티어링으로 조정해 inference 시 지시 준수도를 높일 수 있을까? 🔧 핵심 아이디어: Activation Steering…
-
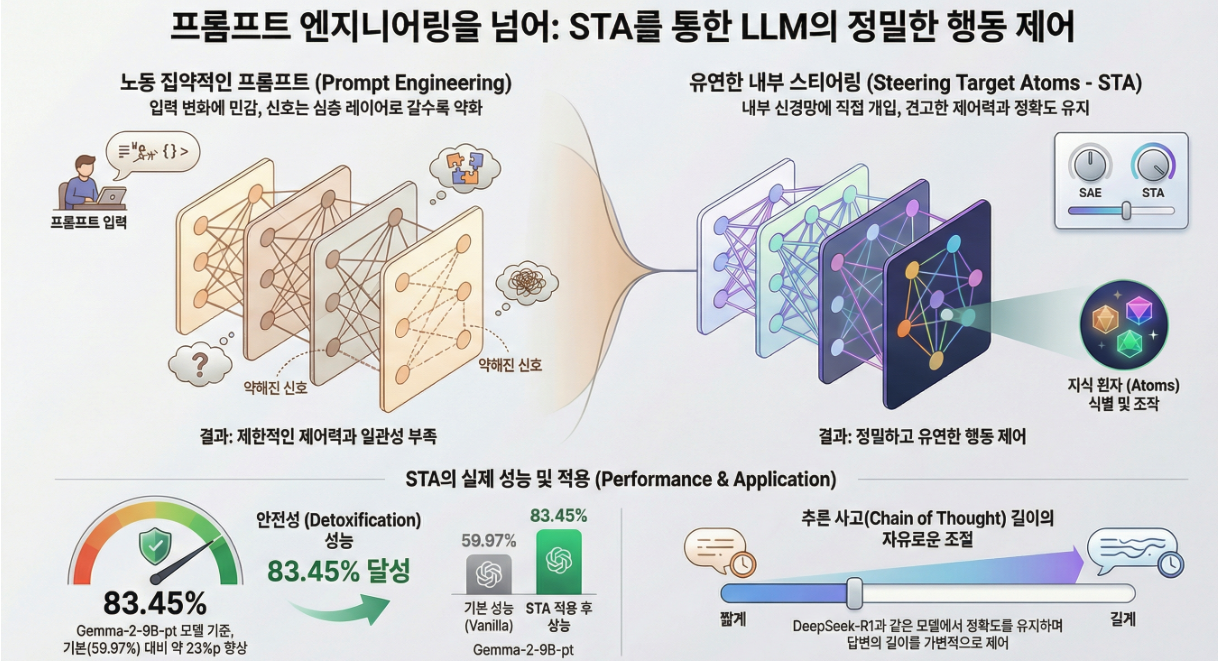
*** Beyond Prompt Engineering: Robust Behavior Control in LLMs via Steering Target Atoms (ACL 2025)
논문 **“Beyond Prompt Engineering: Robust Behavior Control in LLMs via Steering Target Atoms” (ACL 2025)**은 대형 언어모델(LLM)의 행동 제어(behavior control) 문제를 다루며, 기존의 *프롬프트 엔지니어링(prompt engineering)*의 한계를 극복하기 위해 Steering Target Atoms (STA) 라는 새로운 방법을 제안합니다. 연구 배경 제안 방법: Steering Target Atoms (STA) 1. SAE 기반 표현 분해 모델의 은닉 상태 hh 를 SAE를 통해 고차원, 희소…
-
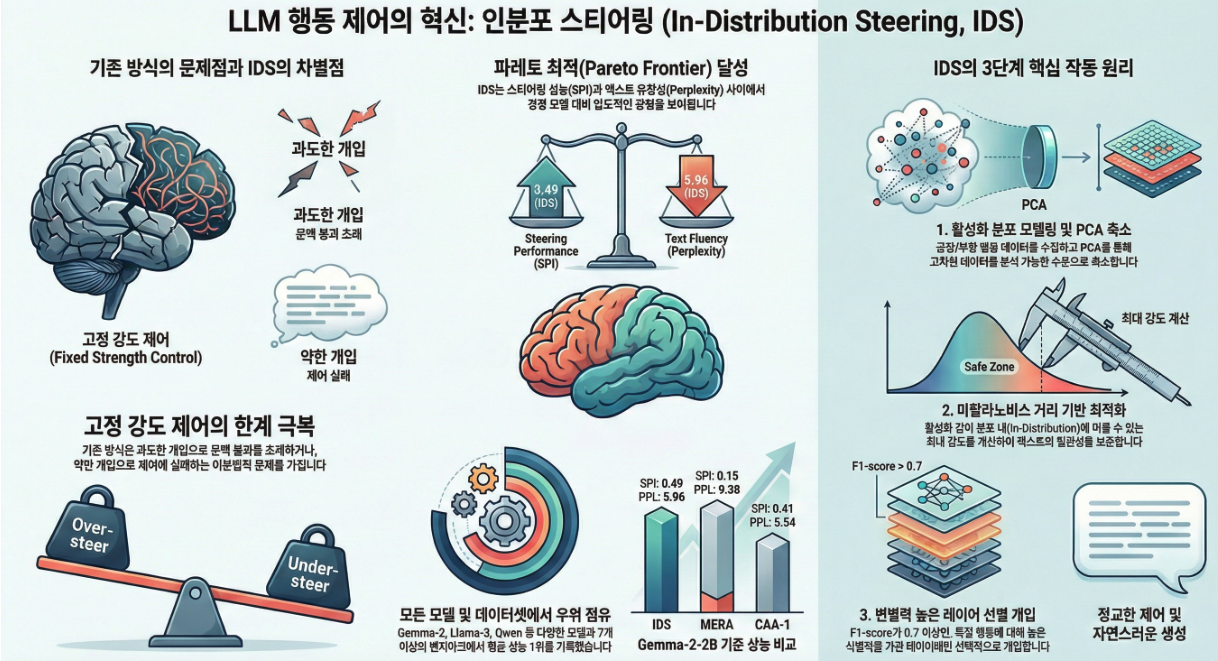
*** In-Distribution Steering: Balancing Control and Coherence in Language Model Generation (arxiv 2025)
아래는 논문 **“In-Distribution Steering: Balancing Control and Coherence in Language Model Generation (2025)”**에 대한 설명입니다. 📌 논문 핵심 요약 **IDS(In-Distribution Steering)**는 기존 Activation Steering 기법(CAA, MERA)의 가장 큰 한계를 해결하는 방법입니다: “스티어링 강도 α를 고정하지 말고, 입력이 target-behavior distribution 안에 머물 수 있을 만큼만 동적으로 조절하자.” ⇒ 즉, 과소 스티어링 ↔ 과도 스티어링(activation collapse) 사이에서 최적 지점을 자동…
-

*** Semantics-Adaptive Activation Intervention for LLMs via Dynamic Steering Vectors (SADI) (ICLR 2025)
아래는 ICLR 2025 논문 “Semantics-Adaptive Activation Intervention for LLMs via Dynamic Steering Vectors (SADI)” 의 전체 구조와 핵심 기여를 종합적으로 정리한 설명입니다. 📌 1. 논문의 문제의식 — “고정된 Steering Vector의 한계” Activation Engineering(activation steering)은 최근 LLM 행동을 제어하기 위한 중요한 기법입니다.하지만 기존 방법들은 다음과 같은 한계를 가짐: ① 고정된 steering vector 사용 ② 입력 의미와 steering 방향 불일치 →…
-
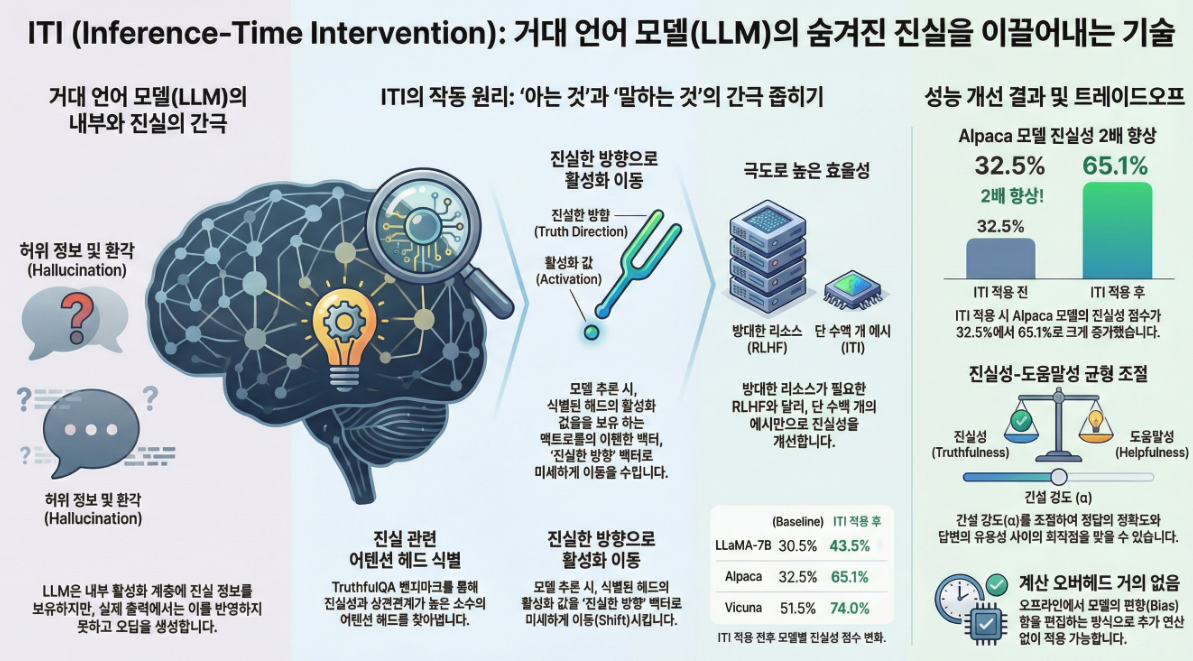
*** Inference-Time Intervention: Eliciting Truthful Answers from a Language Model」 (NeurIPS 2023)
1. 문제의식: 모델은 “알지만 말하지 않는다” 이 논문의 출발점은 Generation–Discrimination Gap (G-D gap) 입니다. LLaMA-7B + TruthfulQA에서: 👉 모델 내부에는 ‘진실 여부’ 정보가 존재하지만, decoding 과정에서 그것이 제대로 반영되지 않는다는 강한 증거를 제시합니다 2. 핵심 아이디어: Inference-Time Intervention (ITI) 한 줄 요약 “진실과 강하게 상관된 attention head의 activation을, inference 중에 살짝 밀어준다.” 중요한 점 3. 방법론 핵심 구조 3.1…