
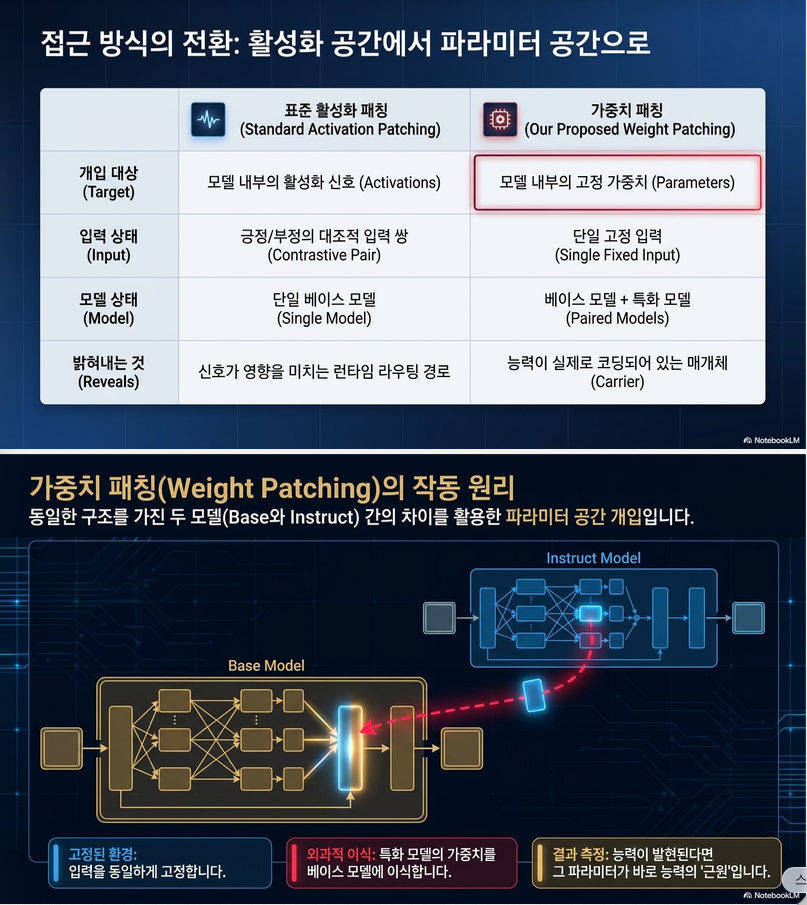





이 논문의 핵심 아이디어는 다음 한 문장으로 요약할 수 있습니다.
기존 Mechanistic Interpretability가 “어디에서 신호가 보이는가?”(activation)를 찾았다면, 이 논문은 “그 능력이 실제로 어느 파라미터에 저장되어 있는가?”(weight)를 찾으려 한다.
1. 왜 새로운 방법이 필요한가?
기존 Circuit Discovery 계열:
- Activation Patching
- Path Patching
- Attribution Patching
- ACDC
- EAP
등은 모두 activation 공간에서 동작한다.
예를 들어:
Instruction
↓
Neuron A
↓
Head B
↓
Head C
↓
OutputActivation Patching을 하면
- Head C를 patch했더니 성능이 회복됨
→ Head C가 중요하다고 판단
하지만 실제로는
- 정보는 Neuron A에 저장
- Head C는 단순 전달
일 수도 있다.
즉, “Activation 중요성 ≠ Parameter 저장 위치“라는 문제가 있다.
2. 논문의 핵심 아이디어
Activation Patching
기존:
와 를 준비하고 clean activation을 corrupted run에 삽입
한다.
Weight Patching
이 논문:
입력은 고정.
대신 Instruction-tuned 모델의 weight를 Base 모델에 삽입한다.
즉,
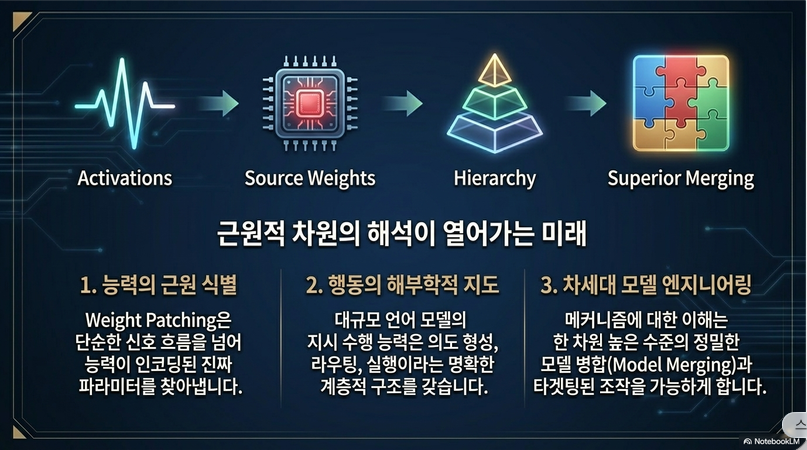
예:
Base Llama-3.2-3B와Llama-3.2-3B-Instruct가 있다고 하자.어떤 neuron 하나의 weight만 교체
했더니
Instruction-following 능력이 일부 복구된다.
→ 그 neuron이 instruction-following 능력을 저장하고 있을 가능성이 높다.
이것이 Weight Patching이다.
3. 전체 프레임워크
논문의 파이프라인은 그림 3 (p.4)이다.
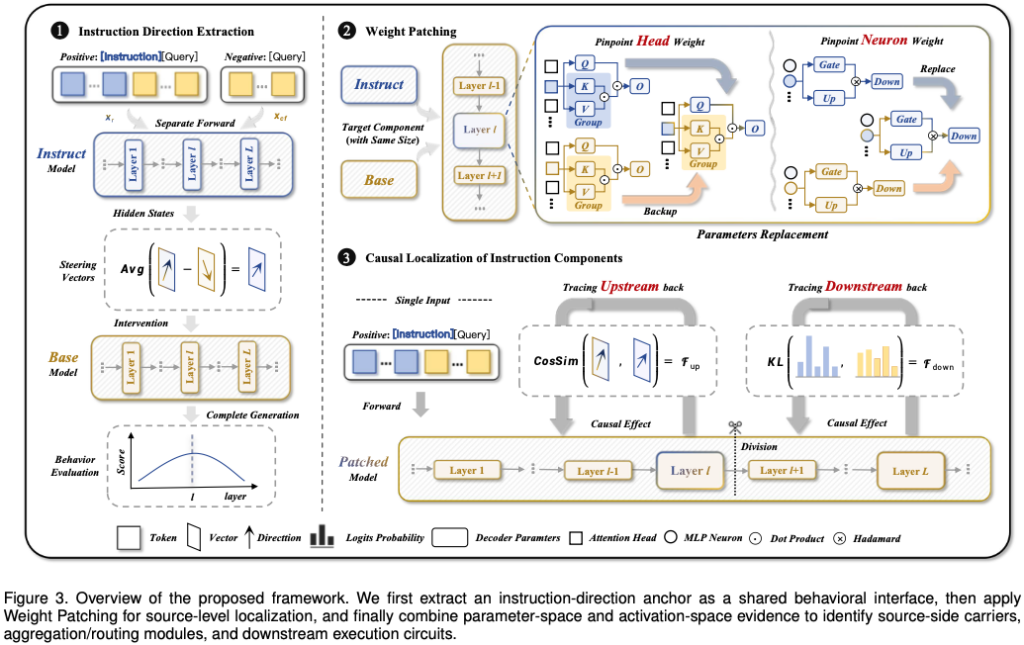
3단계:
Step 1
Instruction Direction 추출
↓
Step 2
Weight Patching
↓
Step 3
Activation Patching과 결합
↓
Hierarchy 복원
Source Carrier
↓
Aggregation Head
↓
Execution Neuron4. 가장 중요한 부분: Vector Anchor
이 논문의 가장 큰 기술적 기여
문제
Instruction Following은 출력이 자유생성이다.
예:
Write in ALL CAPS출력은 수백 가지가 가능.
따라서, token probability만으로는 instruction-following 여부를 측정하기 어렵다.
해결
Instruction Vector를 만든다.
Dataset:
- : instruction 있음
- : instruction 제거
예:
Write in all caps.
Apple is good.vs
Apple is good.Layer l에서 residual 차이 평균
이 벡터가 Instruction Direction이다.
5. Anchor Utility
특정 layer를 anchor로 선택
Anchor representation 와 instruction vector v 사이 cosine similarity 계산
즉, 모델 내부가 얼마나 instruction-following 상태인지 측정.
6. Weight Patching 수식
Component
c =
- Attention Head
- MLP Neuron
Weight patching 모델:
=
즉, component c의 weight만 instruction model 것으로 교체.
Score
해석:
E_w(c)=0.8 이면 Base→Instruct 차이의 80%를 그 component 하나만으로 복구했다는 의미.
7. 어떤 weight를 교체하는가?
이 부분이 흥미롭다.
Attention Head
전체 Q,K,V,O를 교체하지 않는다.
논문은 만 교체.
이유:
Llama 계열은 GQA 사용. K,V가 공유되므로 head 단위 교체가 애매하다.
MLP Neuron
Neuron j
즉, 하나의 feature detector 전체를 교체.
8. First-order Weight Attribution
가장 중요한 기술적 기여 중 하나
문제:
Llama 3B의 MLP neuron의 수는 수십만 개.
Exact Weight Patching 불가능.
Taylor 근사 사용
즉, 형태.
최종 score:
사실상 Activation Patching의 Attribution Patching을 Parameter 공간으로 옮긴 것.
9. Activation Patching과의 결합
논문의 가장 흥미로운 결과
Weight Patching
찾는 것:
누가 instruction 정보를 저장하는가?Activation Patching
찾는 것:
누가 instruction 정보를 전달하는가?결과:
WP
↓
초기 layer neuron
AP
↓
중간 layer head
즉
Neuron
↓
Head
↓
Neuron구조 발견.
10. 최종 Mechanistic Story
논문이 제안하는 hierarchy
(1) Source Carriers
초기층 MLP neuron:
Instruction 정보 저장
(2) Aggregation/Routing
중간층 attention head:
Instruction token 읽고 전달
(3) Execution
후반층 neuron:
실제 출력 형식 생성
예:
ALL CAPS형태 구현
11. 기존 연구와의 관계
매우 흥미로운 점은 이 논문이 사실상
Activation-space
- Activation Patching
- Attribution Patching
- EAP
- EAP-IG
- ACDC
의 대칭 개념을
Parameter-space
로 확장했다는 점이다.
| Activation World | Weight World |
|---|---|
| Activation Patching | Weight Patching |
| Attribution Patching | Weight Attribution |
| Important Head | Source Carrier |
| Circuit Discovery | Parameter Localization |
12. 연구적 의미
Mechanistic Interpretability 관점에서 가장 중요한 메시지
기존:
“어디가 중요하다?” (AP, EAP)
이 논문:
“그 중요성이 어디에 저장되어 있는가?” (WP)
조합이 가능하다.
예를 들면:
- EAP-IG로 aggregation head 발견
- 해당 head의 upstream source neuron 탐색
- Weight Patching으로 source neuron 검증
- SAE feature와 매핑
- Steering feature 선정
이라는 새로운 Circuit Discovery 파이프라인을 만들 수 있다.
이는 현재의 activation-centric mechanistic interpretability를 parameter-centric mechanistic interpretability로 확장하는 방향이라고 볼 수 있다.
논문의 실험 결과는 크게 6가지로 나눌 수 있습니다.
1. Vector Anchor가 실제로 Instruction Following을 표현하는가?
먼저 저자들은 Instruction Vector가 실제 행동을 표현하는지 검증합니다.
실험:
- Llama-3.2-3B Base
- 추출한 task vector를 layer별로 주입(steering)
- IFEval 성능 회복률 측정
결과(Fig.5):

| Task | Peak Layer |
|---|---|
| No Comma | 약 22 |
| Title | 약 18 |
| Multiple Sections | 약 15 |
| Quotation | 약 16 |
| Number Highlighted Sections | 약 26 |
| English Capital | 약 28 |
공통점:
- 초기층(0~10)은 효과 거의 없음
- 중후반층(15~30)에서 큰 회복
즉,
Instruction-following state는 초기 lexical layer가 아니라
중후반 residual representation에서 형성됨.
2. Activation Patching vs Weight Patching
논문의 핵심 결과.
English Capital task 기준.
Activation Patching
중요 component:
- 중간층 attention head
- 중간층 neuron
집중
Fig.6(a)

Weight Patching
중요 component:
- 초기층 neuron
집중
Fig.6(b)
저자 해석
AP가 찾는 것:
information bottleneck
aggregation
routingWP가 찾는 것:
parameter storage
source carrier즉, 같은 circuit이 아니라
서로 다른 역할의 component를 찾고 있다는 주장.
3. AP와 WP의 overlap
Fig.7 결과.

흥미롭게도 AP Top Component와 WP Top Component의 overlap이 매우 작음.
특히 Head는 거의 겹치지 않음.
즉, “중요 activation”과 “중요 weight”는 다른 위치에 존재.
이 논문의 가장 중요한 실험적 발견 중 하나.
4. Hierarchy Validation
저자들은 정말
Source Neuron
↓
Aggregation Head
↓
Execution Neuron구조인지 검증한다.
(Fig.8)
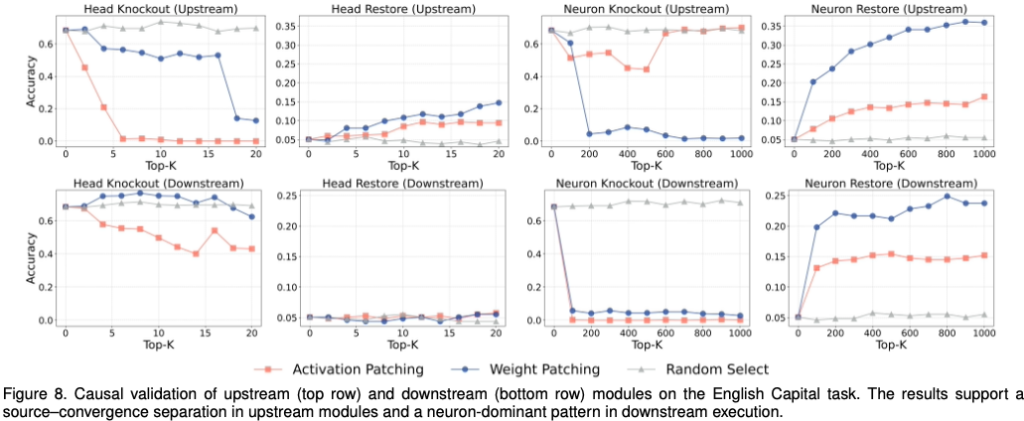
Upstream Head
AP로 찾은 Head 제거
↓
성능 급락
하지만 복구는 거의 안 됨
Ablation: Strong
Restore: Weak의미:
해당 Head는 정보 저장이 아니라 정보 전달.
Upstream Neuron
WP로 찾은 Neuron 제거
↓
성능 급락
복구도 큼
Ablation: Strong
Restore: Strong의미:
실제로 능력이 저장된 위치.
이 결과가 Weight Patching의 정당성을 뒷받침.
5. Upstream Supplier Tracing
논문의 매우 흥미로운 결과.
Table 1.
저자들은 AP가 찾은 Head의 upstream neuron을 역추적.
그리고 WP가 찾은 neuron과 비교.
Llama-3.2-3B
| Task | Max overlap |
|---|---|
| English Capital | 0.775 |
| Quotation | 0.705 |
| No Comma | 0.445 |
| Avg | 0.542 |
Llama-3.1-8B
평균: 0.572
Llama-2-13B
평균: 0.543
의미:
WP가 찾은 neuron이 정말 AP head의 upstream supplier일 가능성이 높음.
즉
WP neuron
↓
AP head관계가 존재.
6. Fine-Grained Neuron Analysis
Fig.9 결과.

Upstream Neuron
특징:
Threshold effect
100개 제거 → 거의 영향 없음
110개 제거 → 갑자기 붕괴즉, 분산 저장(distributed representation).
Downstream Neuron
특징:
Additive effect
10개 제거
20개 제거
30개 제거거의 선형 감소.
즉, 실제 실행(execution) 역할.
7. SwiGLU 내부 분석
Fig.10.

MLP neuron을
- Gate
- Up
- Down
으로 분리.
Localization 성능
Gate + Up > Gate > DownRestoration 성능
Gate + Up > Up > Gate > Down결론:
Instruction-following 정보는 Down projection보다 Gate/Up 쪽에 더 강하게 저장.
이는 매우 흥미로운 발견.
8. Head 분석
Fig.11.

중요 Head가 실제로 instruction token을 읽는지 확인.
결과:
Instruction-tuned 모델의 중요 Head는 랜덤 Head보다
instruction 영역에 훨씬 높은 attention.
즉, 이 Head들은 memory storage가 아니라 routing head.
9. Cross-task Generalization
6개 IFEval task 전체 분석.
- No Comma
- Title
- Multiple Sections
- Quotation
- Number Highlighted Sections
- English Capital
모두 동일 패턴.
공통 구조
Source Neuron
↓
Aggregation Head
↓
Execution Neuron즉, 특정 task만의 현상이 아님.
10. 가장 중요한 결과: Model Merging
사실 논문 후반부의 가장 강한 결과는 이것입니다.
WP score를 Model Merging에 사용.
전문가 모델:
- WizardLM
- WizardMath
- CodeAlpaca
기존:
Task Arithmetic
TIES
DARE
WIDEN은
모든 parameter를 거의 동일하게 취급.
제안:
WP score가 큰 component만 해당 expert 비중 증가.
수식:
결과:
4개 merging 조합 모두에서 평균 성능 최고.
저자들은 이를
Weight Patching이 단순 interpretability 기법이 아니라
실제
Mechanism-aware Model Merging에도 활용 가능함을 보여주는 외부 검증(external validation)으로 해석.
논문의 핵심 실험 결론
이 논문이 실험적으로 주장하는 것은 다음 세 줄입니다.
1. Instruction-following 정보는
초기층 MLP neuron에 저장된다.
2. 중간층 attention head는
저장이 아니라 aggregation/routing 역할을 한다.
3. 후반층 neuron은
실제 출력을 생성하는 execution 역할을 한다.즉 기존 EAP/Activation Patching이 발견하던 “중요한 head”가 반드시 능력을 저장한 곳은 아니며, 능력의 실제 저장 위치(source-level carrier)는 shallow MLP neuron일 가능성이 높다는 것이 이 논문의 핵심 실험 결과입니다.
답글 남기기