





이 논문의 핵심 메시지는 매우 간단합니다.
기존 Circuit Discovery는 “task → 하나의 circuit”이라는 가정을 깔고 있는데, 실제 LLM은 같은 task도 여러 메커니즘으로 풀 수 있다.
따라서 기존 방법은 task circuit이 아니라 dataset-specific circuit을 찾고 있으며, 심지어 서로 다른 메커니즘을 하나의 circuit에 섞어버릴 수 있다.
이를 해결하기 위해 Data-driven Circuit Discovery (DCD) 를 제안한다.
1. 문제의식
기존 연구들
- IOI circuit (Wang et al., 2023)
- Induction circuit
- Entity Binding circuit
- Arithmetic circuit
- EAP
- EAP-IG
- ACDC
모두 다음 절차를 사용한다.
Task 정의
↓
Dataset 구축
↓
Circuit Discovery
↓
하나의 Circuit 획득즉, 이라는 가정을 한다.
논문은 이 가정을 두 개로 분해한다.
가정 1
하나의 task는 하나의 circuit으로 구현된다.
가정 2
연구자가 만든 dataset이 task 전체를 대표한다.
논문은 “두 가정 모두 실제로는 성립하지 않는다.”고 주장한다.
2. 기존 Circuit Discovery 수식
모델 계산 그래프
G=(N,E)
- node = attention head, MLP
- edge = causal connection
Circuit
기존 EAP/EAP-IG 계열은
각 edge에 대해 를 계산한다.
여기서 는 example 에서 edge 중요도.
Dataset 전체 importance
그 후, Top-k edge 선택
3. RQ1: 정말 Task Circuit을 찾고 있는가?
논문의 첫 번째 질문.
실험 대상
4개의 유명 task
1. IOI
Indirect Object Identification
Mary and John went ...
John gave an apple to ___정답: Mary
2. Entity Binding
Key → Box D
Rose → Box C
Box D contains ?정답: Key
3. Arithmetic
10 + 50 =정답: 60
4. Sequence Completion
Induction Head task
ABABAB A다음 token 예측
4. Dataset Variant 생성
같은 task인데 약간만 바꿈.
Complexity
IOI:
2-person
↓
3-personArithmetic:
a+b
↓
a+b+cSyntax
IOI:
active
↓
passiveEntity Binding, target position 변경
Domain
IOI:
Mary, John
↓
Person X, Person Y5. 결과: General Task Circuit이 아님
매 variant마다
EAP-IG로 circuit을 찾음.
만약 진짜 task circuit이라면
2-person IOI에서 찾은 circuit은3-person IOI
passive IOI
letter IOI에서도 잘 동작해야 한다.
하지만 실제 결과는 다름.
Faithfulness Drop
최대 감소
| Task | Drop |
|---|---|
| IOI | 33% |
| Entity Binding | 79% |
| Arithmetic | 24% |
| Sequence Completion | 19% |
예시:
2-person IOI circuit Faithfulness
자기 데이터셋 73%↓
3-person IOI 42%31% 감소
6. Edge Overlap도 낮음
논문은 Jaccard Similarity 계산.
결과:
평균 수준.
즉, 같은 task인데도 Top edge 절반 이상이 다름.
RQ1 결론
기존 방법은 Task Circuit이 아니라 을 찾는다.
7. RQ2: 서로 다른 Task를 섞으면?
더 흥미로운 실험.
Dataset:
Arithmetic + Entity Binding을 섞음.비율
0%
10%
20%
...
100%Entity Binding 비율 변화.
놀라운 결과
Arithmetic circuit과 Entity Binding circuit은 서로 거의 transfer 안됨.
하지만, 50:50으로 섞으면 하나의 circuit이 Arithmetic에도 Entity Binding에도 높은 faithfulness를 가짐.
예:
Circuit size = 5%, EB=0.5에서
Arithmetic 89.8%, Entity Binding 85.1% faithfulness.
즉, Arithmetic circuit + Entity Binding circuit을 하나의 circuit으로 합쳐도 faithfulness는 높게 나온다.
따라서, High Faithfulness ≠ Single Mechanism 이라는 결론.
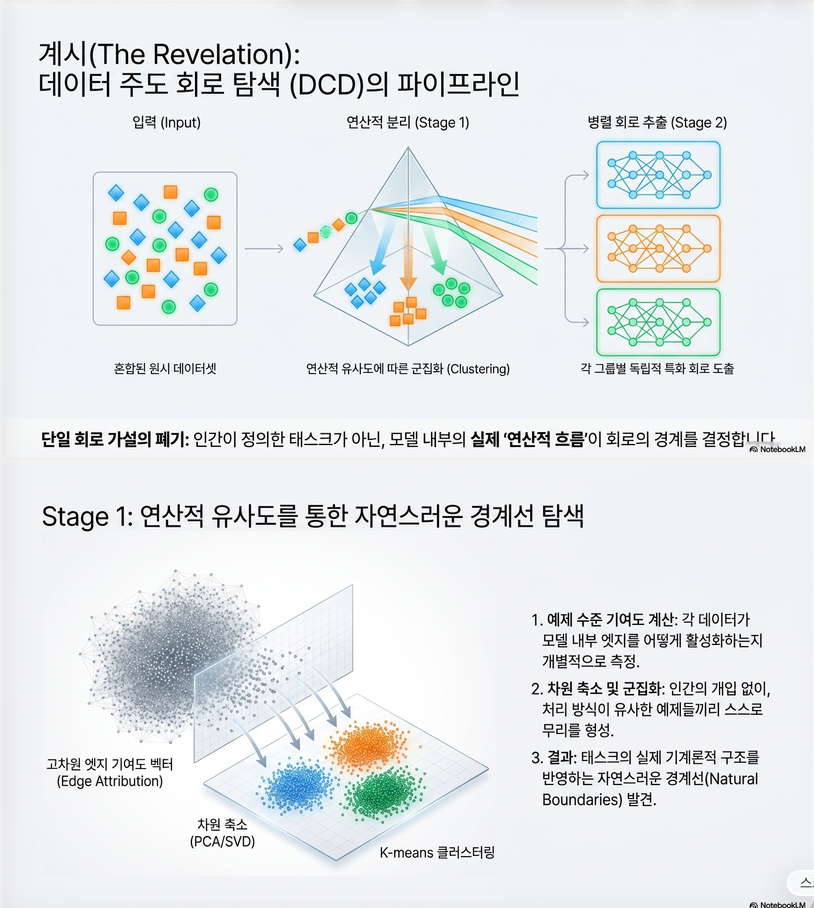
8. DCD 제안
논문의 핵심.
기존:
Dataset
↓
Circuit Discovery
↓
1 CircuitDCD:
Dataset
↓
Per-example Circuit(edge attribution vector)
↓
Clustering
↓
Circuit Discovery
↓
K Circuits9. DCD 알고리즘
Algorithm 1
Step 1
각 example마다
edge attribution vector 생성
여기서 EAP-IG를 사용.
Step 2
차원 축소 (PCA)
Step 3
클러스터링 (K-means)
K 선택
- Silhouette
- Gap statistic
- Elbow
Step 4
클러스터별 Circuit Discovery
최종 획득.
10. 평가 방식
DCD는 circuit이 여러 개.
그래서 Best-of-K Faithfulness 사용.
각 example에 대해
가장 잘 설명하는 circuit 선택.
11. 실험 결과
GPT-2
Circuit Size = 5%
DCD
86%
EAP-IG
64%
22%p 향상.
Qwen2.5, Llama3.1에서도 동일 경향.
특히, 희소한 회로 영역에서 가장 큰 차이.
12. DCD가 실제로 메커니즘을 분리했는가?
Figure 5가 중요.

GPT-2
All-task dataset
IOI + Sequence Completion 혼합.DCD 결과
7개 cluster 생성.
Cluster 구성
C2,C3,C4,C7 = IOI
C1,C5,C6 = Sequence Completion더 놀라운 점
IOI 내부도 분리.
2-person IOI, 3-person IOI, Letter IOI가 각각 다른 cluster.즉, DCD는 task 수준이 아니라 mechanism 수준으로 분해.
논문의 진짜 의미
이 논문은 새로운 circuit discovery 알고리즘이라기보다는,
“Task Circuit”이라는 개념 자체를 비판한 논문에 가깝습니다.
Mechanistic Interpretability 커뮤니티에서 상당히 중요한 주장입니다.
Edge attribution vector 설명
논문에서 사용하는 edge attribution vector는 DCD의 핵심 개념입니다.
1. 정의
Transformer의 계산 그래프를 G=(N,E)라고 하자.
- N: node (attention head, MLP 등)
- E: edge
예를 들어 GPT-2 Small에서는 수만 개, Llama-3-8B에서는 수백만 개의 edge가 존재한다.
각 입력 예제 에 대해 EAP-IG를 수행하면 모든 edge의 중요도를 얻을 수 있다.
여기서 이다.
이를 벡터로 모으면
가 된다.
이 벡터가 바로 edge attribution vector 이다.
2. 직관적 의미
기존 EAP-IG에서는
edge importance
↓
평균
↓
하나의 circuit을 만든다.
DCD에서는 평균을 내기 전에 각 example의 attribution을 보관한다.
예를 들어,
Example 1
10 + 50 =의 경우
Example 2
20 + 40 =의 경우
Example 3
Box D contains ?의 경우
그러면 이고, 는 매우 다를 것이다.
즉, “어떤 edge들을 사용했는가?”를 나타내는 fingerprint이다.
3. EAP-IG에서는 어떻게 계산되는가?
논문은 EAP-IG를 사용한다.
EAP-IG에서 edge 중요도는
형태이다.
여기서
- : 실제 activation
- : corrupted activation
- y: target logit
이다.
따라서 edge attribution vector는
즉, 모든 edge에 대한 EAP-IG score들의 집합이다.
4. DCD에서 사용하는 이유
논문의 핵심 아이디어는
비슷한 메커니즘을 쓰는 예제들은 비슷한 edge attribution vector를 가질 것이다.
이다.
예를 들어,
Arithmetic examples 들은 서로 가깝고
Entity Binding examples 들은 또 다른 영역에 모인다.
그래서 를 clustering하면
task label 없이도
Arithmetic mechanism
Entity Binding mechanism
Induction mechanism
...을 분리할 수 있다는 것이 DCD의 가설이다.
5. 왜 PCA를 하는가?
문제는 차원이 너무 크다.
GPT-2 Small:
Llama-3-8B:
수준이다.
그래서, 를 PCA로 로 축소한다.
그 후, K-means 수행.
답글 남기기