





이 논문은 최근 Sparse Feature Circuit 계열(SAE, Transcoder, Edge Pruning, EAP) 연구들을 모두 조합하여 70B 규모 LLM까지 회로(circuit)를 추출할 수 있는 scalable framework를 제안한 논문입니다.
새로운 알고리즘을 실제 구현하여 대규모 실험으로 검증했다기보다는 기존 연구들을 조합한 프레임워크 제안 성격이 강합니다. 특히 일부 실험 수치(70B까지의 결과 등)는 공개 코드나 재현성 정보가 부족하여 실제 구현 여부를 신중하게 해석할 필요가 있습니다. (방법 자체는 충분히 흥미롭습니다.)
1. 연구 배경
기존 Circuit Discovery 방법들은 모두 비슷한 문제를 갖고 있습니다.
| 방법 | 문제 |
|---|---|
| Activation Patching | 너무 느림 |
| ACDC | edge 수가 너무 많아짐 |
| EAP | edge attribution 계산량 큼 |
| Sparse Feature Circuit | feature 수가 많아지면 graph가 폭발 |
예를 들어
- feature가 10,000개
- edge 후보가 layer마다 수백만 개
이면, 회로 탐색(search)이 거의 O(2ⁿ) 수준으로 증가합니다.
그래서 “회로를 한 번에 찾지 말고 계층적으로(hierarchical) 찾자”가 이 논문의 핵심입니다.
2. 전체 Framework
논문의 HAGD(Hierarchical Attribution Graph Decomposition)는 총 4단계입니다.
LLM
↓
Cross-layer Transcoder
↓
Sparse Features
↓
Attribution Graph
↓
Hierarchical Graph
↓
GNN Search
↓
Causal Validation
↓
Sparse Circuit즉,
SAE + Attribution Graph + Graph Clustering + GNN Search
를 하나의 framework로 합친 것입니다. (논문 Figure 1)
3. Step 1 : Cross-layer Transcoder
기존 SAE는
hidden
↓
feature
↓
hidden만 학습합니다.
하지만 이 논문은
layer l feature
↓
layer l+1 feature까지 예측하도록 합니다.
즉
feature(l)
↓
predict feature(l+1)입니다.
수식
Encoder:
Decoder:
기존 SAE와 동일합니다.
추가되는 것은
입니다.
즉, layer 간 feature dependency를 학습합니다.
최종 Loss
논문에서 사용하는 loss는
입니다.
세 가지 항으로 구성됩니다.
(1) Reconstruction
기존 SAE
(2) Cross-layer prediction
다음 layer feature 예측
(3) Sparsity
L1 penalty
이 부분은 사실 Sparse Transcoder 논문과 거의 동일한 아이디어입니다.
4. Step 2 : Attribution Graph 생성
다음으로 feature 간 edge를 만듭니다.
논문에서는 gradient × activation을 사용합니다.
입니다.
이것은 Integrated Gradient가 아니라 Gradient × Activation 형태입니다.
즉,
edge weight는
feature i
↓
feature j가 얼마나 영향을 주는가입니다.
결과
모든 feature가 vertex
모든 attribution이 edge가 됩니다.
즉,
feature1
↓
feature8
↓
feature12같은 거대한 graph가 만들어집니다.
5. Step 3 : Hierarchical Graph Decomposition (핵심)
이 부분이 논문의 핵심입니다.
기존에는 10000 feature를 바로 탐색했습니다.
논문은 먼저 clustering합니다.
예를 들면
10000 feature
↓
500 clusters
↓
100 clusters
↓
20 clusters
↓
5 clusters입니다.
즉, multi-resolution graph를 만듭니다.
Spectral Clustering
논문은 Normalized Laplacian
을 사용합니다.
이후 eigenvector를 계산하여 feature를 cluster로 묶습니다.
왜 좋은가?
원래 10000 feature 검색은 어렵습니다.
하지만 20 cluster만 먼저 선택하면 검색 공간이 크게 줄어듭니다.
이후 선택된 cluster 안에서만 다시 탐색합니다.
즉,
coarse
↓
fine
↓
finer순서입니다.
Complexity
논문은 기존 을 으로 줄였다고 주장합니다.
이것이 논문의 가장 큰 기여입니다.
다만 이 복잡도는 이론적 분석이며, 실제 모든 상황에서 엄밀히 보장되는 것은 아닙니다.
6. Step 4 : GNN Search
Hierarchical Graph가 생기면 어떤 cluster가 circuit인지 GNN이 예측합니다.
사용한 모델은 Graph Attention Network(GAT)입니다.
각 node는 를 가지며
message passing 를 수행합니다.
attention은 입니다.
즉, 중요한 cluster를 우선 방문합니다.
7. Causal Validation
발견된 circuit이 진짜인지 확인합니다.
Necessity:
feature를 제거했을 때 성능이 떨어져야 합니다.
Sufficiency:
이 0.9 이상이면 충분한 circuit으로 인정합니다.
8. 실험
논문은
- GPT-2
- Pythia
- Llama
를 대상으로 평가했다고 보고합니다.
Transcoder는 RedPajama 1억 토큰으로 layer별 학습합니다.
Dictionary는 hidden dimension의 8배 크기입니다.
예를 들면
Llama-70B
hidden=8192
↓
dictionary=65536입니다.
9. Algorithmic Task 결과
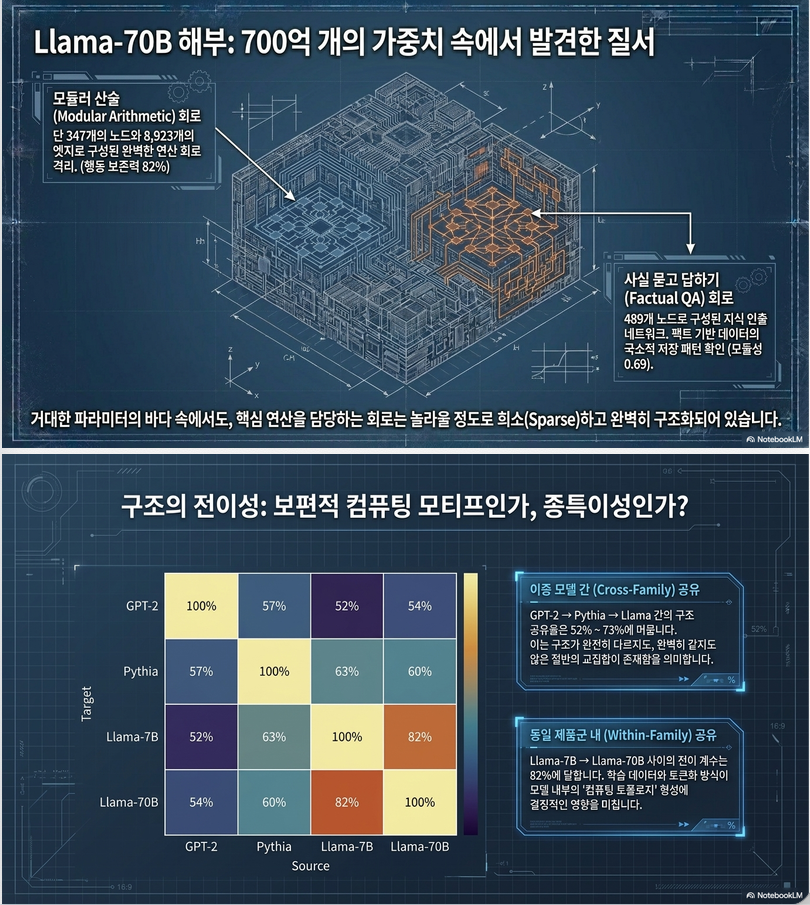
(1) Modular Arithmetic
| Model | Preservation | Nodes |
|---|---|---|
| GPT2 Small | 0.97 | 49 |
| GPT2 Medium | 0.94 | 71 |
| Pythia 1.4B | 0.91 | 124 |
| Pythia 2.8B | 0.89 | 156 |
| Llama7B | 0.87 | 198 |
| Llama70B | 0.82 | 347 |
주요 결과는 다음과 같습니다.
- 70B에서도 circuit 추출이 가능하다고 주장
- Circuit 크기는 모델 규모에 따라 증가하지만 비교적 완만하게 증가
- ACDC는 Pythia-1.4B에서 OOM(메모리 부족)으로 실패
- Hierarchical 방법은 끝까지 수행되었다고 보고합니다.
10. Natural Language Task
평가 데이터셋
- WinoGrande
- HellaSwag
- Factual QA
결과를 요약하면
| Task | Preservation |
|---|---|
| WinoGrande | 0.81~0.86 |
| HellaSwag | 0.74~0.79 |
| Factual QA | 0.81~0.88 |
관찰 결과는 다음과 같습니다.
- 언어 과제는 알고리즘 과제보다 더 큰 circuit이 필요
- Modularity가 더 낮아 분산된 계산 구조를 보임
- **Factual QA는 가장 높은 modularity(0.69~0.78)**를 보여 사실 기억이 비교적 국소적인 회로에 저장될 가능성을 시사합니다.
11. Cross-Architecture Transfer
흥미로운 실험입니다.
GPT2에서 찾은 circuit이 Llama에도 존재하는가?
Transfer coefficient는
입니다.
대표 결과는
| Transfer | Coefficient |
|---|---|
| GPT2→Pythia | 0.71 |
| GPT2→Llama | 0.68 |
| Pythia→Llama | 0.73 |
| Llama7→70B | 0.82 |
즉,
- 같은 모델 계열(Llama-7B→70B)이 가장 높은 유사도(0.82)
- 수학적 알고리즘 회로가 자연어 회로보다 더 잘 전이됨을 보고합니다.
12. Ablation Study
| 제거한 요소 | 영향 |
|---|---|
| Hierarchy 제거 | 속도 저하, 정확도 소폭 감소 |
| GNN 제거 | 품질과 효율 모두 소폭 감소 |
| Cross-layer 제거 | 성능 저하가 가장 큼 |
| Validation 제거 | 품질 변화는 거의 없지만 계산 시간 단축 |
즉, 저자들은 Cross-layer Transcoder가 가장 큰 성능 기여를 한다고 해석합니다.
13. 이 논문의 한계
저자들도 여러 한계를 명시합니다.
- Attention 회로를 다루지 않습니다. MLP 기반 feature만 분석합니다.
- **Transcoder 재구성 오차(15~20%)**가 남아 있으며, 이 “dark matter”에 중요한 계산이 포함될 수 있습니다.
- GNN 학습에 ground-truth circuit이 필요합니다. 작은 모델의 exhaustive search나 전문가 라벨링에 의존합니다.
- Llama-70B에서 347개 노드, 8,923개 edge 수준의 회로는 사람이 해석하기에는 여전히 너무 큽니다.
- 검증이 ablation 기반이라 회로 발견과 검증이 동일한 개입 방식에 의존하는 순환성(circularity) 문제가 있습니다.
14. 이 논문의 의의와 연구 관점에서의 평가
Sparse Feature Circuits, CircuitLasso, Data-driven Circuit Discovery, Transcoder, RelP, EAP-IG 계열과 비교하면 다음과 같이 위치를 정리할 수 있습니다.
| 논문 | 핵심 아이디어 | 특징 |
|---|---|---|
| Sparse Feature Circuits | Sparse feature graph | Feature 수준 causal circuit |
| Transcoders | Neuron → Feature 변환 | Monosemantic feature 생성 |
| CircuitLasso | 선형 구조 방정식 기반 회로 학습 | Corrupted 입력 불필요 |
| Data-driven Circuit Discovery | Data 기반 edge 최적화 | Patching 최소화 |
| HAGD (본 논문) | Hierarchical graph search | Scalability 개선에 초점 |
즉, 새로운 attribution 방법이나 circuit 정의를 제안했다기보다, 기존 Sparse Feature Circuit 파이프라인 위에 “계층적 그래프 탐색”을 추가해 대규모 모델까지 확장하려는 시스템적 접근으로 볼 수 있습니다. 또한 논문에 제시된 대규모 실험은 재현성 정보가 제한적이므로, 결과 수치 자체보다는 “계층적 회로 탐색”이라는 아이디어를 연구 아이디어로 받아들이는 것이 적절해 보입니다.
답글 남기기