

이 논문은 최근 SAE(Sparse Autoencoder) 중심의 mechanistic interpretability 연구에 대해 상당히 흥미로운 문제 제기를 합니다.
핵심 질문은:
“LLM 내부의 의미(concept)를 표현하는 진짜 단위(unit)는 무엇인가?”
입니다.
기존에는
- Neuron
- SAE feature
- Residual stream direction
등이 주로 사용되었는데,
저자들은
“실제로는 여러 neuron들이 조합(composition)되어 하나의 개념을 표현한다”
고 주장하며,
MLP activation을 SNMF(Semi-Nonnegative Matrix Factorization)로 분해하여 neuron group 기반 feature를 찾는 방법을 제안합니다.
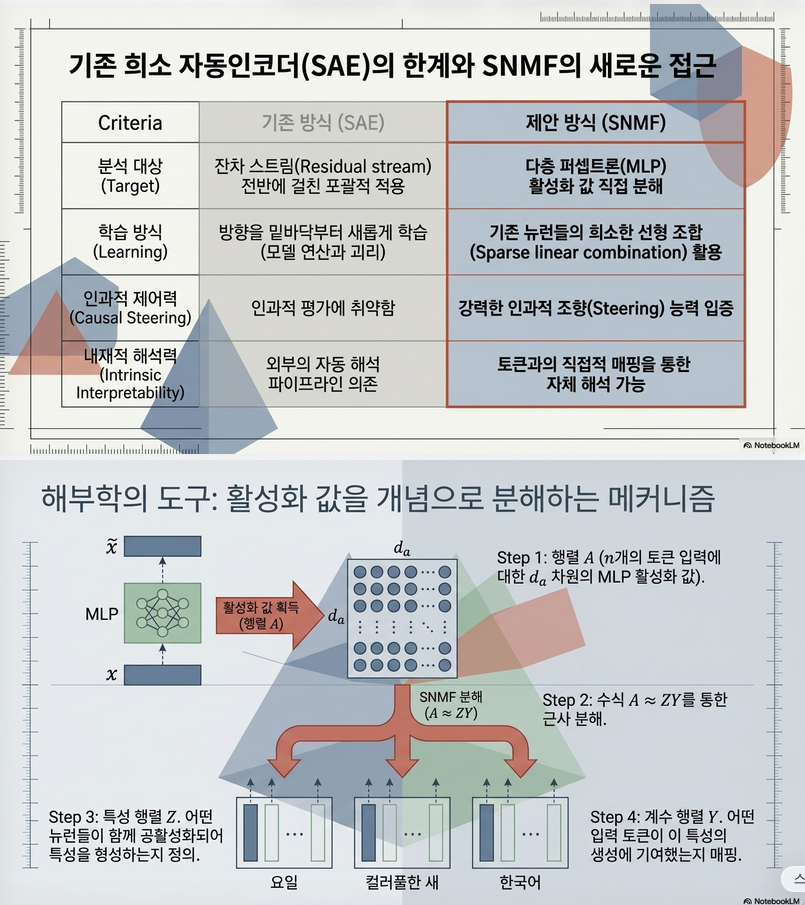
1. 논문의 핵심 아이디어
기존 SAE:
즉, Residual Stream에서 를 받아 새로운 feature basis를 학습합니다.
문제는:
- feature가 실제 model 내부 계산과 직접 연결되지 않음
- residual space에 새 방향을 생성
- causal steering 성능이 생각보다 높지 않음
이라는 점입니다.
저자들은 반대로 생각합니다.
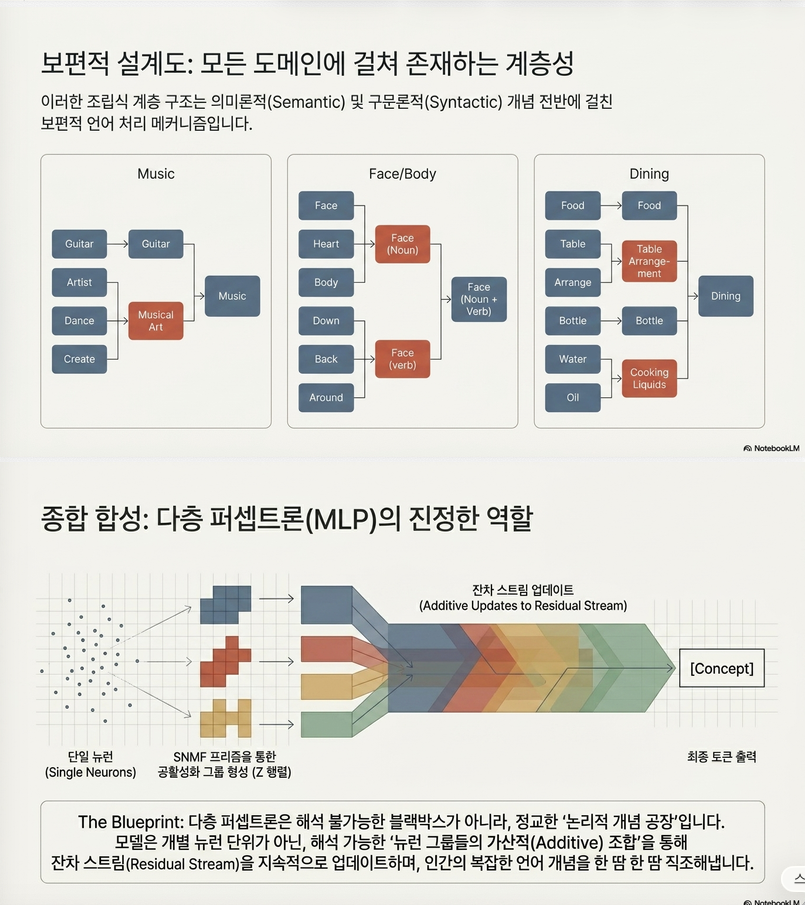
MLP는 원래
이고
는 neuron activation입니다.
즉,
입니다.
여기서 는 neuron i가 residual stream에 보내는 방향입니다.
따라서 “concept”는 사실 같은 neuron 집합이 동시에 활성화될 때 발생한다고 볼 수 있습니다.
그래서 논문의 목표는
를 찾는 것입니다.
2. 방법론
Step 1. MLP Activation 수집
어떤 layer의 MLP에서 n개의 token을 통과시킵니다.
각 token에 대해 를 저장합니다.
그러면 을 얻습니다.
입니다.
예를 들어, Llama-3.1 8B, Layer 18, MLP width = 14336 이라면
입니다.
Step 2. SNMF 수행
저자들의 핵심 제안입니다.
로 분해합니다.
, 이며
입니다.
Z의 의미
Z의 각 column 가 하나의 MLP feature입니다.
예:
이면 Neuron 3과 Neuron 5가 함께 활성화되는 패턴입니다.
즉, feature는 입니다.
Y의 의미
는 “j번째 token에서 i번째 feature가 얼마나 사용되었는가”를 의미합니다.
즉, feature ↔ token 대응관계를 제공합니다.
이것이 SAE보다 중요한 장점입니다.
Step 3. Residual Space Feature 생성
Neuron Group을 실제 residual stream 방향으로 변환합니다.
각 neuron은 라는 output vector를 가집니다.
따라서 로 정의합니다.
입니다.
이제 f 는 steering 가능한 feature direction이 됩니다.
3. SNMF 최적화
목표 함수:
subject to 입니다.
초기화:
Optimization:
Ding et al. (2010)의 Multiplicative Update(MU) 사용
류의 NMF update를 반복합니다.
Step 4. Sparse Neuron Group 만들기
그대로 두면 모든 neuron이 feature에 참여할 수 있습니다.
그래서 Winner-Take-All(WTA) 적용
에서 상위 p%만 남깁니다.
나머지는 0.
즉, “, 유지” 같은 방식입니다.
왜 SNMF인가?
일반 NMF:
제약
하지만 neuron activation은
- positive
- negative
둘 다 존재합니다.
그래서 Z는 자유롭게 두고
Y 만 nonnegative로 제한합니다.
이를 Semi-NMF라고 합니다.
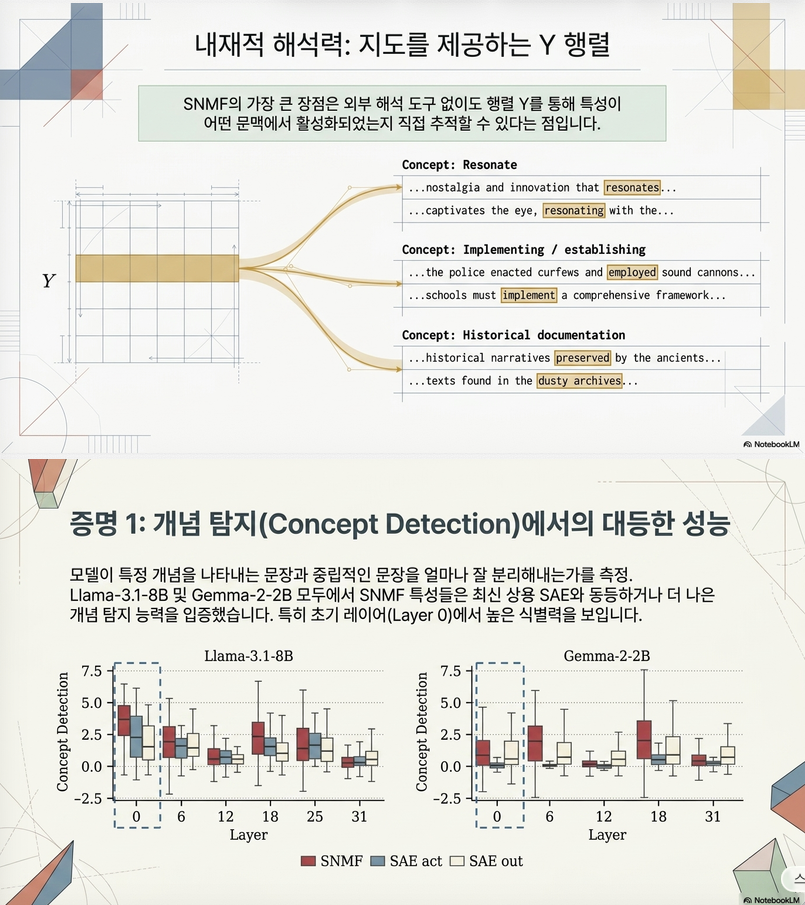
4. Feature Labeling
SNMF의 가장 큰 장점입니다.
SAE는 feature를 설명하려면 activation dataset을 별도로 뒤져야 합니다.
SNMF는 Y가 이미 있음.
즉, 가 큰 token들을 바로 찾을 수 있습니다.
예:
Feature 37
상위 activation:
- resonate
- resonating
- resonate more strongly
↓
GPT-4o-mini
“concept = resonance” 라고 라벨링.
5. Concept Detection 평가
기존 SAE 논문들이 자주 사용하는 평가입니다.
방법
Feature 설명 생성
예:
Historical documentation
GPT가
Positive sentence 생성
- ancient texts preserved …
- historical archives …
Negative sentence 생성
- weather is sunny …
- the dog runs …
Feature와 activation의 cosine similarity 측정
결과:
SNMF ≈ SAE out
SAE act 수준.
즉, 해석 가능성은 적어도 SAE와 비슷합니다.
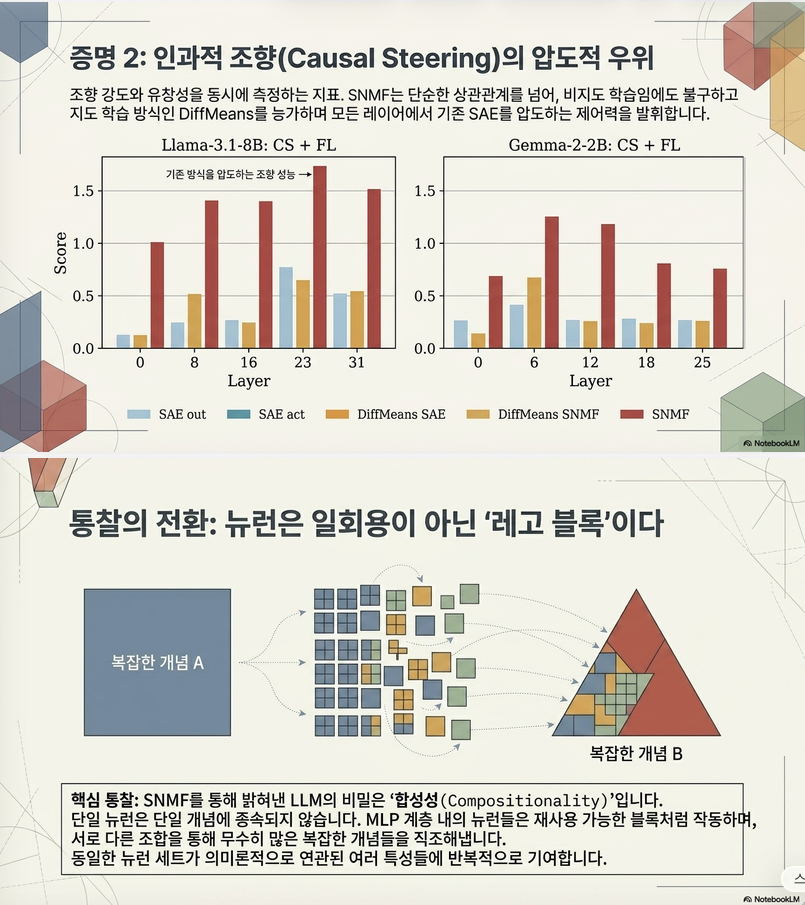
6. Concept Steering 평가
논문의 핵심 실험입니다.
Prompt:
I think that …
feature를 주입
형태로 steering.
평가:
GPT-4o-mini judge
- Concept score
- Fluency score
측정.
결과
SNMF
SAE act
SAE out
수준.
심지어 DiffMeans(강력한 supervised baseline)과 비슷하거나 더 좋음.
이는 SNMF feature가 실제 causal feature에 더 가깝다는 의미입니다.
7. 가장 흥미로운 부분: Neuron Compositionality
여기서 논문의 기여가 드러납니다.
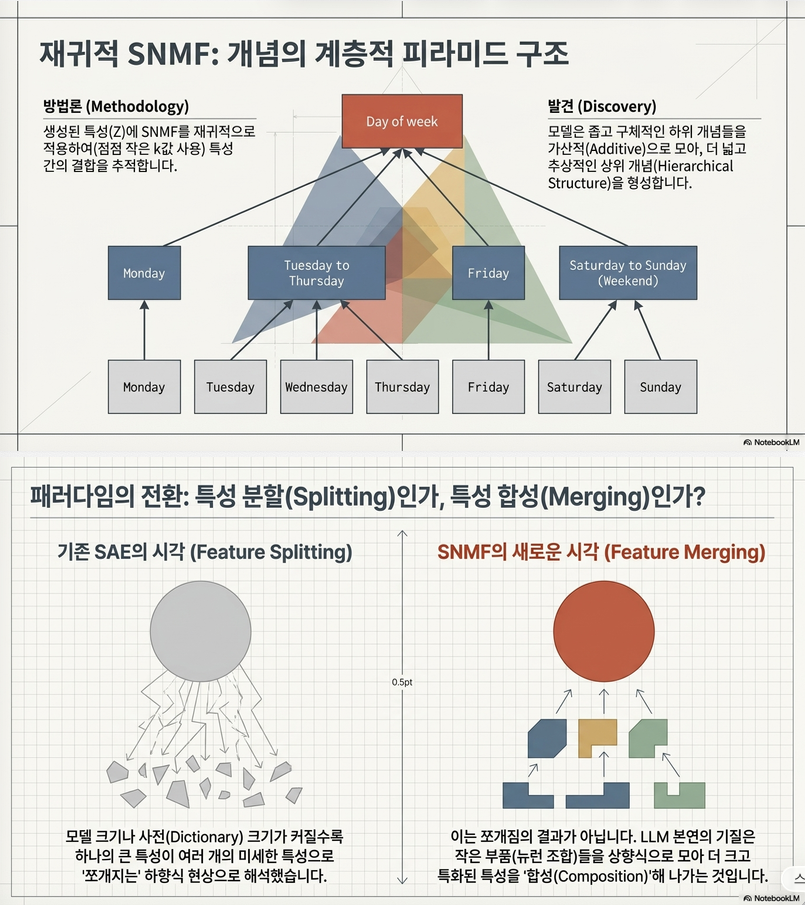
저자들은 SNMF를 재귀적으로 적용합니다.
1단계
Monday
Tuesday
Wednesday
Sunday
feature 발견
2단계
다시 SNMF
↓
Tuesday~Thursday
Weekend
발견
3단계
다시 SNMF
↓
Day of Week
발견.
즉
Monday
Tuesday
Wednesday
↓
Weekday
↓
Day of Week계층 구조가 자동으로 생성됩니다.
논문 Figure 4가 이를 보여줍니다.
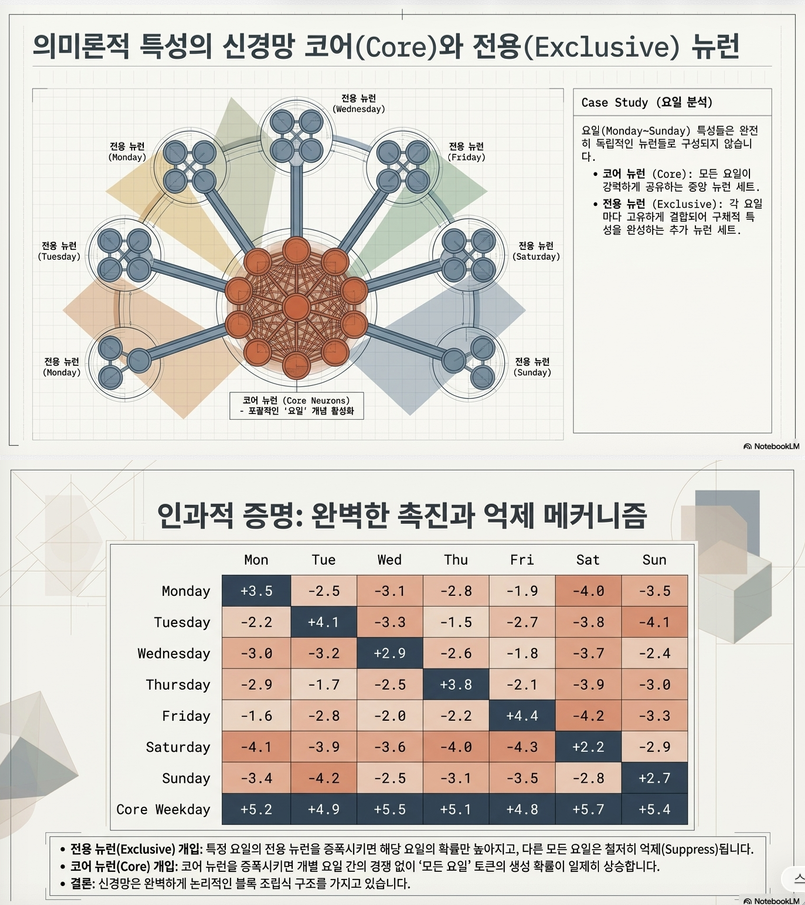
Shared Neuron 분석
행렬 구성
여기서 는 top neuron만 남긴 binary matrix.
그러면 는 feature i와 feature j가 공유하는 neuron 수.
결과:
Monday~Sunday feature들이 공통 neuron 집합을 공유.
추가 neuron이 붙으면서
Monday
Tuesday
…
를 구분.
Causal Validation
공통 neuron만 증폭
↓
모든 weekday token logit 증가
Sunday 전용 neuron 증폭
↓
Sunday 증가
Monday~Saturday 감소
즉,
공통 neuron = weekday 개념
전용 neuron = specific day 개념
이라는 것을 인과적으로 검증했습니다.
SAE 연구와의 관계
이 논문은 SAE의 “feature splitting” 현상에 대한 새로운 해석을 제시합니다.
기존:
SAE가 너무 많은 feature를 만들었다.
저자 주장:
실제 모델 자체가 계층적 neuron composition을 사용한다.
즉,
Programming
├─ Python
├─ Javascript
└─ Java같은 구조가 실제 존재하며
SAE splitting은 이를 반영한 것일 수 있다는 주장입니다.
답글 남기기