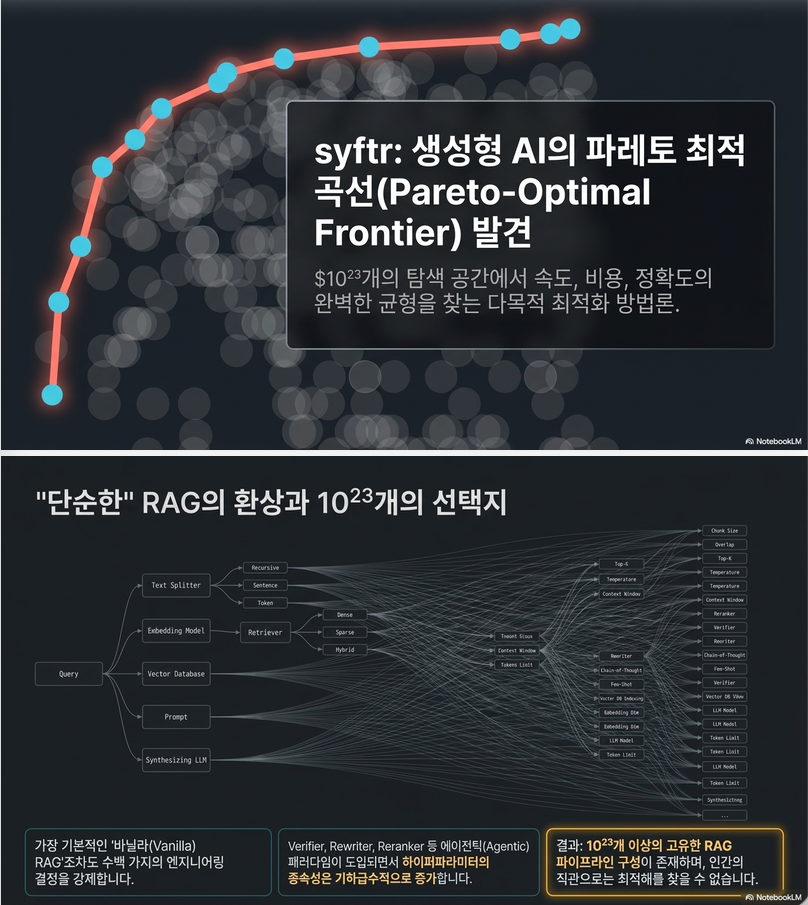




이 논문은 RAG(Retrieval-Augmented Generation) 시스템을 AutoML 관점에서 자동 설계하는 최초의 Multi-Objective Bayesian Optimization 프레임워크라고 볼 수 있습니다.
핵심 목표는:
“주어진 데이터셋에서 정확도(Accuracy)와 비용(Cost)의 Pareto-optimal RAG flow를 자동으로 찾자”입니다.
1. 문제 정의
기존 RAG 구축 시 다음과 같은 선택들이 존재합니다.
- Embedding model
- Retriever
- Splitter
- Re-ranker
- HyDE
- Prompt template
- LLM
- Agent 종류
예를 들어:
Embedding
├─ bge-small
├─ bge-large
└─ gte-large
Retriever
├─ Dense
├─ Sparse
└─ Hybrid
LLM
├─ GPT-4o-mini
├─ Gemini Flash
├─ Claude Haiku
└─ o3-mini이들을 조합하면 수백~수천 개의 RAG flow가 생성됩니다.
논문에서는 총 1023개의 RAG Flow를 탐색 대상으로 정의합니다.
2. 전체 아이디어
기존 AutoRAG는
Module A 최적화
→ Module B 최적화
→ Module C 최적화처럼 Greedy 방식입니다.
문제는:
좋은 Retriever
+
좋은 LLM이 항상 좋은 전체 Flow가 되는 것은 아닙니다.
즉, Module interaction이 존재합니다.
따라서 syftr는 전체 Flow를 하나의 Search Space로 보고 최적화합니다.
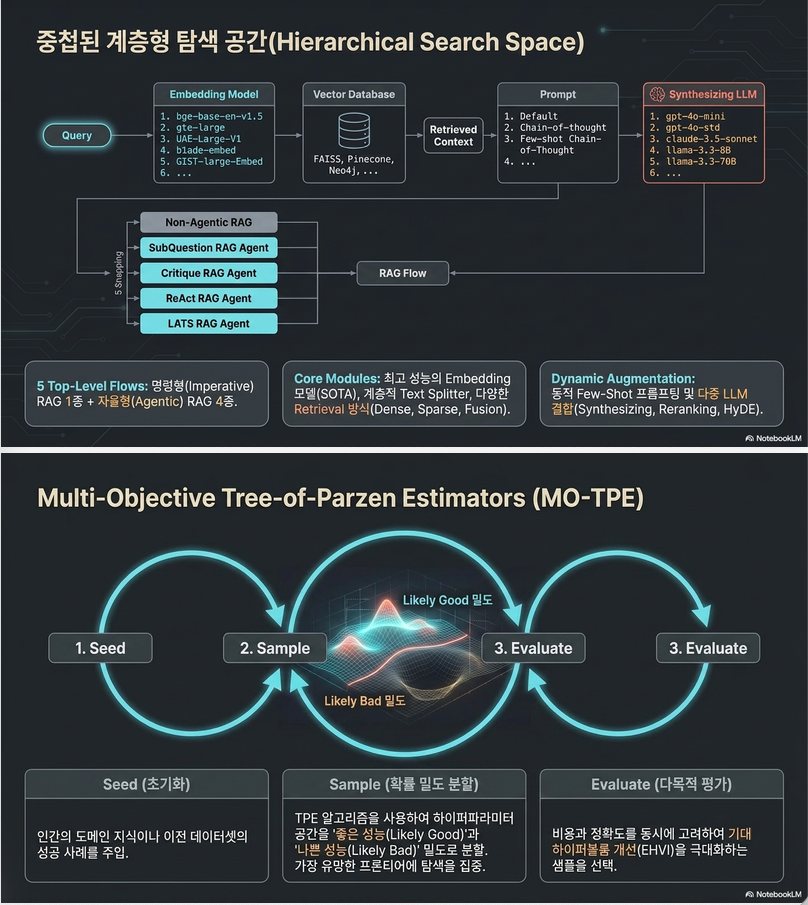
3. Search Space
논문 Figure 3이 핵심입니다.
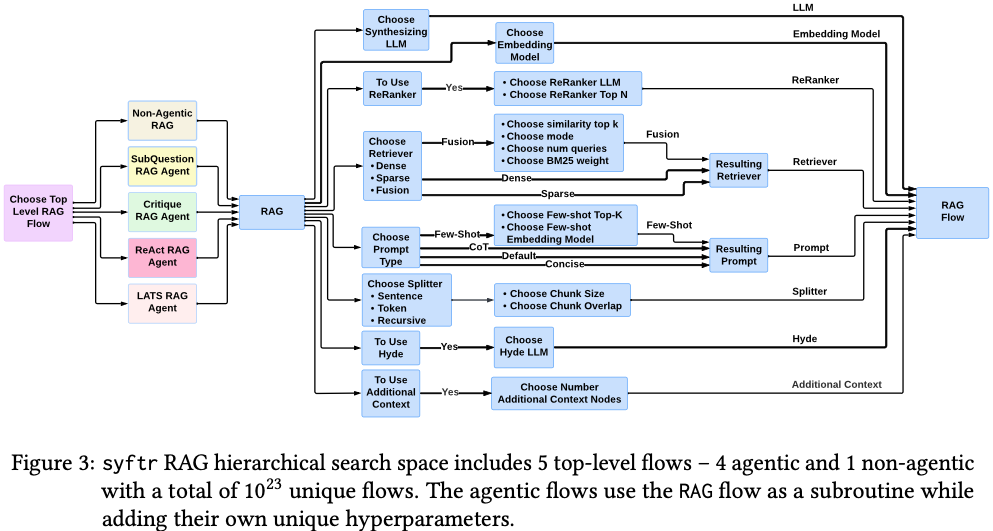
상위 레벨:
1. RAG
2. ReAct RAG Agent
3. Critique RAG Agent
4. SubQuestion Agent
5. LATS Agent3.1 Agent 종류
(1) Vanilla RAG
Query
↓
Retrieve
↓
LLM
↓
Answer(2) ReAct Agent
Reason
↓
Act(Retrieve)
↓
Reason
↓
Act반복
(3) Critique Agent
Answer
↓
Critique
↓
Revise(4) SubQuestion Agent
Question
↓
Sub-question decomposition
↓
RAG
↓
Merge(5) LATS
Language Agent Tree Search
Tree Search
+ Planning
+ Reflection가장 복잡한 Agent
4. Search Variable
Appendix A1 기준 탐색 변수들.
Retriever
Dense
Sparse
FusionHyperparameter
top-k
num-queries
bm25-weightSplitter
Sentence
Recursive
TokenHyperparameter
chunk size
chunk overlapPrompt
Default
Concise
CoT
Few-shotReRanker
사용 여부
reranker LLM
top-kHyDE
사용 여부
HyDE LLMLLM
Small:
GPT-4o-mini
Gemini Flash
Claude Haiku
o3-miniLarge:
GPT-4o
Gemini Pro
Claude Sonnet
Llama-3.3-70B등을 탐색합니다.
5. 핵심 방법론: MO-TPE
논문의 핵심 기여는
Multi-Objective Tree-of-Parzen Estimator
(MO-TPE) 사용입니다.
5.1 일반 TPE
일반 BO는 f(x)를 직접 모델링합니다.
하지만 TPE는 좋은 영역 l(x), 나쁜 영역 g(x)를 모델링합니다.
관측 결과를 상위 γ% Good set과 나머지 Bad set으로 나눕니다.
Density Estimation
l(x) = p(x | good)
g(x) = p(x | bad)학습
새 후보는
maximize l(x)/g(x)로 선택
즉,
좋은 영역에 가까우면서
나쁜 영역에서는 드문점을 찾습니다.
5.2 왜 TPE인가?
RAG Search Space는
if Agent = ReAct
max_iter 존재
if Agent = RAG
max_iter 없음같은 Conditional Hyperparameter 구조입니다.
GP 기반 BO는 이런 공간이 어렵습니다.
반면 TPE는 Tree Structured Space를 자연스럽게 처리 가능합니다.
5.3 Multi-objective 확장
최적화 목표:
Accuracy ↑
Cost ↓단일 objective가 아닙니다.
따라서 MO-TPE를 사용합니다.
Weighted Scalarization
논문은 Ozaki et al.의 MO-TPE를 사용합니다.
각 objective를
y = w1 Accuracy
+ w2 (-Cost)형태로 scalarization 합니다.
다양한 weight를 사용하면
Accuracy 중심
Cost 중심
균형형해를 모두 탐색하게 됩니다.
5.4 Expected Hypervolume Improvement (EHVI)
이 부분이 중요합니다.
Pareto Optimization에서 목표는 Pareto Frontier 확대입니다.
Hypervolume
현재 Pareto Set이 차지하는 면적
HV(P)를 정의
새 점 x 추가 후
HV(P ∪ {x})증가량
ΔHV를 계산
Expected Hypervolume Improvement
EHVI(x) = E[ΔHV]MO-TPE는 EHVI가 큰 점을 다음 샘플로 선택합니다.
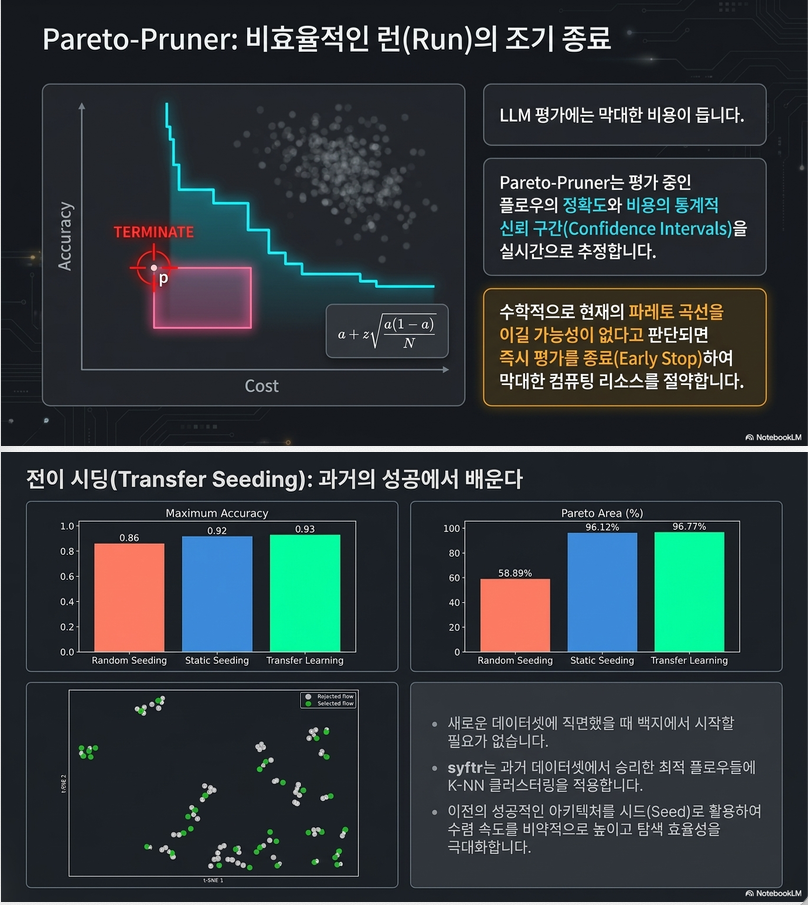
6. Pareto-Pruner (논문의 가장 독창적인 기여)
저자가 강조하는 핵심 기여입니다.
문제
Flow 하나 평가하려면, 1000개 QA를 모두 돌려야 합니다.
매우 비쌉니다.
예:
100개 QA 평가 후
Accuracy = 20%
Cost = 매우 비쌈이면 이미 망한 Flow일 수 있습니다.
아이디어
중간 평가 결과만으로 앞으로 잘될 가능성을 추정
Accuracy Confidence Interval
정확도 a에 대해
a ± z√(a(1-a)/N)사용
Cost Confidence Interval
비용
c ± zσc/√L사용
Bounding Box
Figure 4.
accuracy
↑
│
│
p
●
│
│
─────────────┼────→ costupper-left corner
p를 계산Pruning Rule
만약
p 조차 현재 Pareto frontier 아래라면절대 Pareto-optimal 될 수 없음 판단즉시 중단
Early Stop이는
BO + Multi-objective와 Successive Halving을 결합한 느낌의 방법입니다.7. Warm Start / Transfer Seeding
BO 시작 전에 초기 Trial을 넣어줍니다.
Static Seed
대표 RAG 설정
GPT4o-mini
+
BGE-small등
Random Seed
무작위
Transfer Seed
이전 데이터셋에서 좋았던 Flow 사용
이를 통해 Cold Start 문제를 완화합니다.
8. 실험 결과
주요 결과
syftr가 찾은 Pareto-optimal Flow는
기본 LlamaIndex 설정 대비
동일 비용
+6% accuracy 향상또는
동일 정확도
37% cost 감소 달성. 흥미로운 관찰
1. Agent는 생각보다 자주 Pareto-optimal이 아님
많은 경우
Non-agentic RAG가 Pareto frontier에 존재이유:
Agent = 비싸고 느림2. GPT-4o-mini가 매우 강력
여러 데이터셋에서
GPT-4o-mini가 Pareto frontier에 자주 등장3. HyDE / ReRanking
항상 좋은 것이 아님
데이터셋 의존적
4. FinanceBench
o3-mini가 강세수치 추론 때문으로 분석
논문의 학술적 의의
이 논문은 RAG 연구라기보다
“Generative AI Pipeline AutoML”
논문입니다.
기존:
AutoML
→ ML Pipeline
NAS
→ Neural Architecture
AutoRAG
→ Greedy Module Search에서 한 단계 나아가
Agent + RAG + LLM + Prompt전체를 대상으로
Pareto-optimal search를 수행했다는 점이 핵심입니다.
특히 연구적으로는:
- Hierarchical RAG Search Space 정의
- MO-TPE 기반 Pareto Search
- Pareto-Pruner를 이용한 Early Stopping
- Agentic / Non-agentic Flow 통합 최적화
가 주요 기여입니다.
방법론 자체보다 Pareto-Pruner가 가장 흥미로운 기여라고 봅니다. MO-TPE는 기존 기법 활용에 가깝지만, 평가 비용이 매우 큰 RAG AutoML 환경에서 “현재 Pareto frontier를 이용해 trial을 조기 종료” 하는 아이디어는 실용성이 높고, 향후 Agent workflow optimization이나 Prompt optimization에도 쉽게 확장 가능합니다.
답글 남기기