[카테고리:] RAG
-
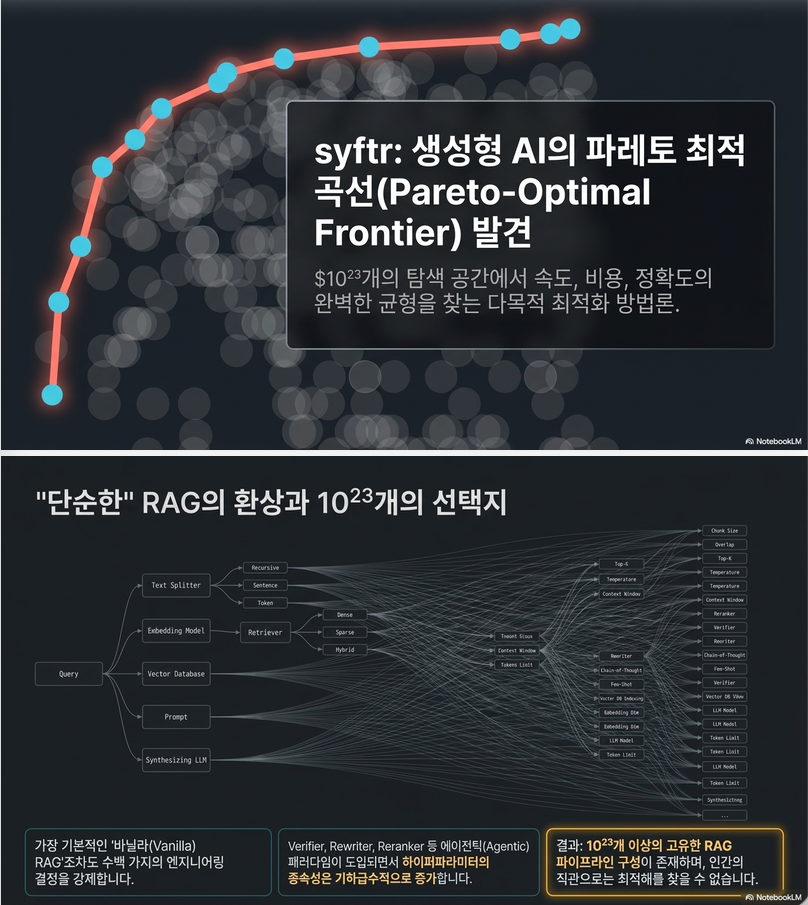
syftr: Pareto-Optimal Generative AI (AutoML 2025)
이 논문은 RAG(Retrieval-Augmented Generation) 시스템을 AutoML 관점에서 자동 설계하는 최초의 Multi-Objective Bayesian Optimization 프레임워크라고 볼 수 있습니다. 핵심 목표는: “주어진 데이터셋에서 정확도(Accuracy)와 비용(Cost)의 Pareto-optimal RAG flow를 자동으로 찾자”입니다. 1. 문제 정의 기존 RAG 구축 시 다음과 같은 선택들이 존재합니다. 예를 들어: 이들을 조합하면 수백~수천 개의 RAG flow가 생성됩니다. 논문에서는 총 1023개의 RAG Flow를 탐색…
-

* When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories (ACL 2023)
이 논문은 LLM의 파라메트릭 메모리(parametric memory) 와 검색 기반 비파라메트릭 메모리(non-parametric memory) 의 역할을 체계적으로 비교·분석한 ACL 2023 논문입니다. 핵심 질문은 다음입니다: “LLM은 언제 자체 기억만으로 충분하고, 언제 retrieval(RAG)이 반드시 필요한가?” 논문은 특히 long-tail factual knowledge 에 주목합니다. 즉, 자주 등장하지 않는 희귀 엔티티 정보에 대해 LLM이 얼마나 취약한지를 분석합니다. 1. 논문의 핵심 아이디어…
-

xRAG: Extreme Context Compression for Retrieval-Augmented Generation with One Token (NeurIPS 2024)
xRAG 논문 핵심 아이디어 이 논문의 핵심은 다음 한 문장으로 요약할 수 있습니다. 검색된 문서를 텍스트로 LLM에 넣지 말고, retrieval embedding 하나만 “문서 토큰 1개”처럼 넣자. 즉, 기존 RAG는: 를 입력으로 사용했지만, xRAG는: 만 사용합니다. 문제의식 기존 RAG의 가장 큰 문제는: 라는 점입니다. 예를 들어: 이면 대부분의 계산량이 retrieval context 처리에 사용됩니다. 기존…
-

PISCO: Pretty Simple Compression for Retrieval-Augmented Generation (Findings of ACL 2025)
이 논문은 RAG(Retrieval-Augmented Generation)에서 문서를 매우 강하게 압축하면서도 QA 성능 손실을 거의 없애는 soft compression 방법을 제안한 논문입니다. 핵심 메시지는 다음과 같습니다. 기존 soft compression은 압축률은 높지만 QA 정확도가 크게 떨어졌고, 대규모 pretraining + labeled QA 데이터가 필요했다.PISCO는 pretraining 없이, 단순한 sequence-level distillation만으로x16 압축에서도 원본 LLM과 거의 동일한 QA 성능을 달성한다. 1. 문제 배경…