





이 논문은 최근 Sparse Autoencoder(SAE) 연구에서 **가장 중요한 문제인 “dictionary를 크게 만들면 오히려 feature quality가 나빠지는 현상”**을 해결하려는 논문입니다.
1. 연구 배경
기존 SAE는 dictionary size를 크게 만들수록 reconstruction은 좋아집니다.
예를 들어,
4k feature
↓
16k feature
↓
65k featuredictionary를 계속 늘리면 activation reconstruction error는 감소합니다.
하지만 interpretability에서는 문제가 생깁니다.
논문에서는 이를 크게 3가지 pathology로 설명합니다.
(1) Feature Splitting
원래 Punctuation 하나의 feature였는데
dictionary가 커지면 Comma, Period, Question mark, Colon 처럼 쪼개집니다.
즉,
General feature
↓
Many specific features가 됩니다.
문제는 원래 존재하던 Punctuation feature가 사라집니다.
(2) Feature Absorption
이것이 최근 SAE 연구에서 가장 큰 문제입니다.
예를 들어,
원래 feature Female name이 있었다고 합시다.
dictionary가 커지면 Lily, Sue, Mary 같은 feature가 새로 생깁니다.
그러면 원래 Female names feature가 Female except Lily 처럼 변합니다.
즉,
Female
↓
Female except Lily가 됩니다.
논문에서는 이를 Hole이라고 부릅니다.
즉 parent feature에 구멍이 생깁니다.
(3) Feature Composition
반대로 Red, Triangle을
Red Triangle 하나의 latent로 합쳐버리는 현상입니다.즉, Color, Shape가 Color × Shape feature로 합쳐집니다.
왜 이런 문제가 생길까?
핵심은 sparsity입니다.
SAE objective는
입니다.
Sparse objective는 가능하면 적은 latent를 사용 하도록 만듭니다.
그러다 보니 General feature를 유지하는 것보다
Specific feature를 사용하는 것이 더 sparse하기 때문에
Feature Splitting과 Absorption이 발생합니다.
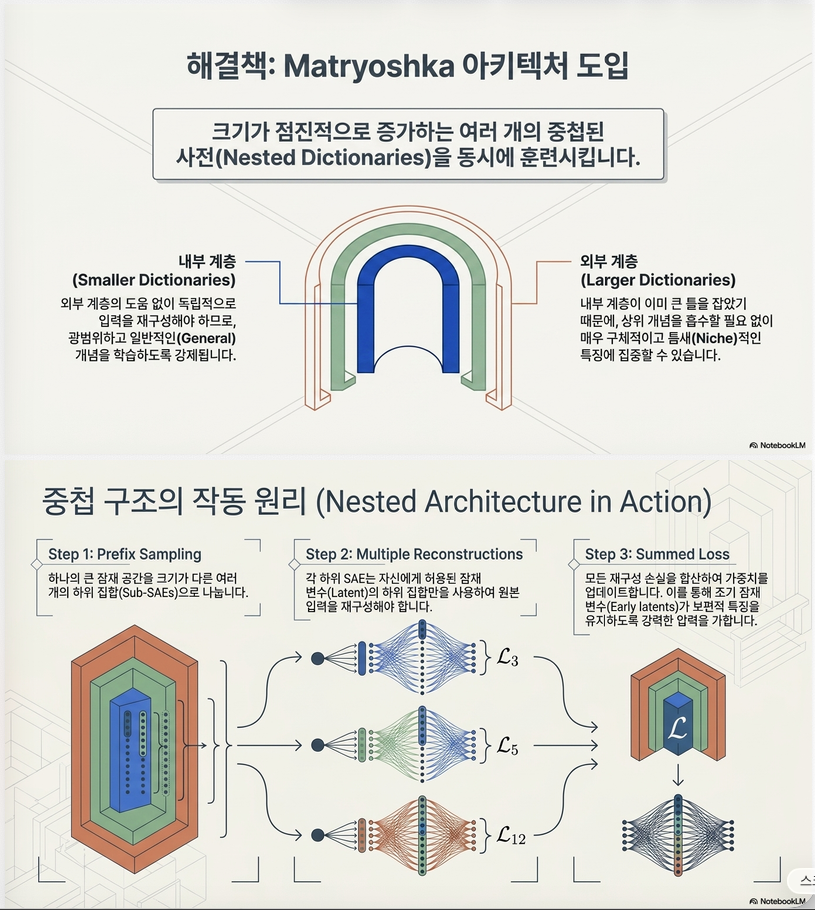
2. 논문의 핵심 아이디어
논문의 아이디어는 매우 단순합니다.
“처음 latent들은 반드시 general feature를 유지하도록 강제하자.”
이를 위해 Matryoshka(러시아 인형) 구조를 사용합니다.
기존 SAE:
65k latent 하나만 reconstruction합니다.반면 Matryoshka SAE는
2048
↓
6144
↓
14336
↓
30720
↓
65536이 모두 reconstruction을 해야 합니다.
즉,
2048 latent만 사용해서 reconstruction
+ 6144 latent만 사용
+ 14336 latent만 사용
+ ...
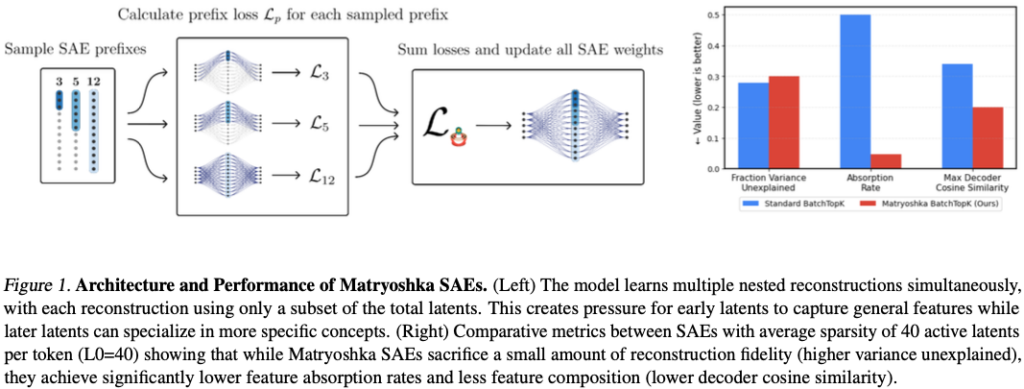
+ 65536 latent 사용을 동시에 학습합니다. (논문 Figure 1)
3. Architecture
Encoder는 기존과 동일합니다.
Decoder는 prefix만 사용합니다.
예를 들어,
latent
1
2
3
4
...
65536이 있을 때
첫 번째 decoder는 1~2048만 사용합니다.
두 번째 decoder는 1~6144 사용합니다.
세 번째는 1~14336 사용합니다.
즉,
입니다.
4. Loss Function (가장 중요)
기존 SAE:
Matryoshka SAE는 모든 prefix reconstruction을 더합니다.
즉,
2048 latent reconstruction
+ 6144 latent reconstruction
+ 14336 latent reconstruction
+ 30720 latent reconstruction
+ 65536 latent reconstruction을 동시에 최소화합니다.
왜 효과가 있는가?
2048 latent만으로 reconstruction해야 하므로
초기 latent들은 가장 일반적인 정보를 저장할 수밖에 없습니다.
나머지 latent들은 세부적인 feature를 저장합니다.
즉,
General
↓
Specific
↓
More specific계층이 자연스럽게 형성됩니다.
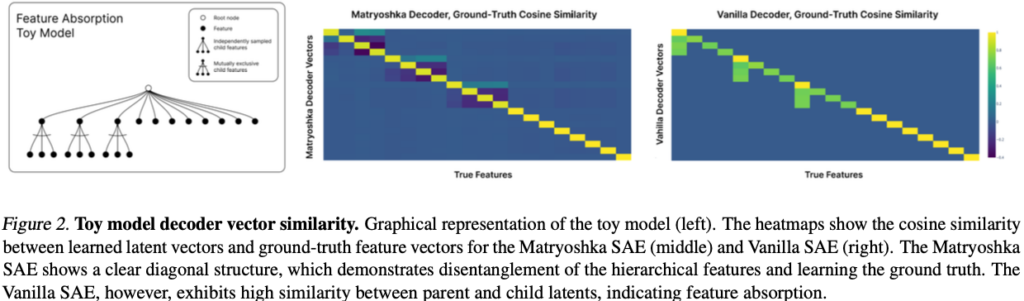
5. Toy Model 실험
논문은 먼저 hierarchical feature toy model을 만듭니다.
예를 들어,
Animal
↓
Dog
↓
Golden Retriever같은 tree입니다.
Child가 나타나면 Parent도 항상 존재합니다.
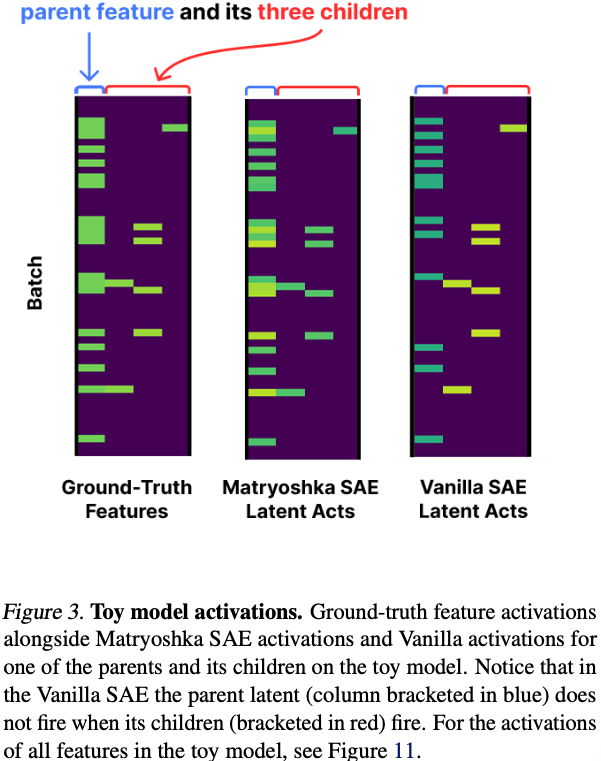
Vanilla SAE
Parent latent가 Dog가 등장하면 꺼져버립니다.
즉, Animal except Dog이 됩니다.
Feature absorption입니다.
Matryoshka SAE
Parent는 항상 살아 있습니다.
Animal
↓
Dog
↓
Golden Retriever모두 독립적으로 유지됩니다.
Figure 2와 Figure 3에서 decoder cosine similarity와 activation을 통해 이를 시각적으로 보여줍니다.
6. TinyStories 실험
4-layer Transformer에서 feature가 dictionary size에 따라 어떻게 변하는지 추적했습니다.
대표 사례는 Female words feature입니다.
300 latent SAE
she, her, girl, Lily, Sue 모두 하나의 feature입니다.1000 latent SAE
갑자기 Female words가 Female except Lily로 바뀝니다.
대신 Lily feature가 따로 생깁니다.
즉,
Female
↓
Female except Lily
+
Lily가 됩니다.
Figure 4에서 이 현상을 강조합니다.
Matryoshka SAE
반면 Female, Lily, Sue가 모두 유지됩니다.
Parent feature에 hole이 생기지 않습니다.
7. Gemma-2-2B 대규모 실험
논문은 실제 LLM에서도 검증했습니다.
학습 설정
- Model: Gemma-2-2B
- Layer: Residual stream 12
- Dictionary: 65,536
- Prefix: {2048, 6144, 14336, 30720, 65536}
- Dataset: The Pile 500M tokens
- BatchTopK 활성화 사용
- 평균 활성 latent(L0): 20, 40, 80, 160, 320
8. 실험 결과
(1) Reconstruction
재구성 품질은 약간 감소합니다.
예를 들어 L0=40에서
- BatchTopK SAE: 약 72% variance explained
- Matryoshka SAE: 약 70% variance explained
즉 reconstruction은 소폭 손해를 봅니다.
(2) Downstream LLM Loss
흥미롭게도 reconstructed activation을 LLM에 다시 넣어 계산한 cross-entropy loss는 큰 차이가 없었습니다.
즉 activation reconstruction은 조금 나빠졌지만,
LLM이 사용하는 의미 있는 정보는 거의 동일하게 보존되었습니다.
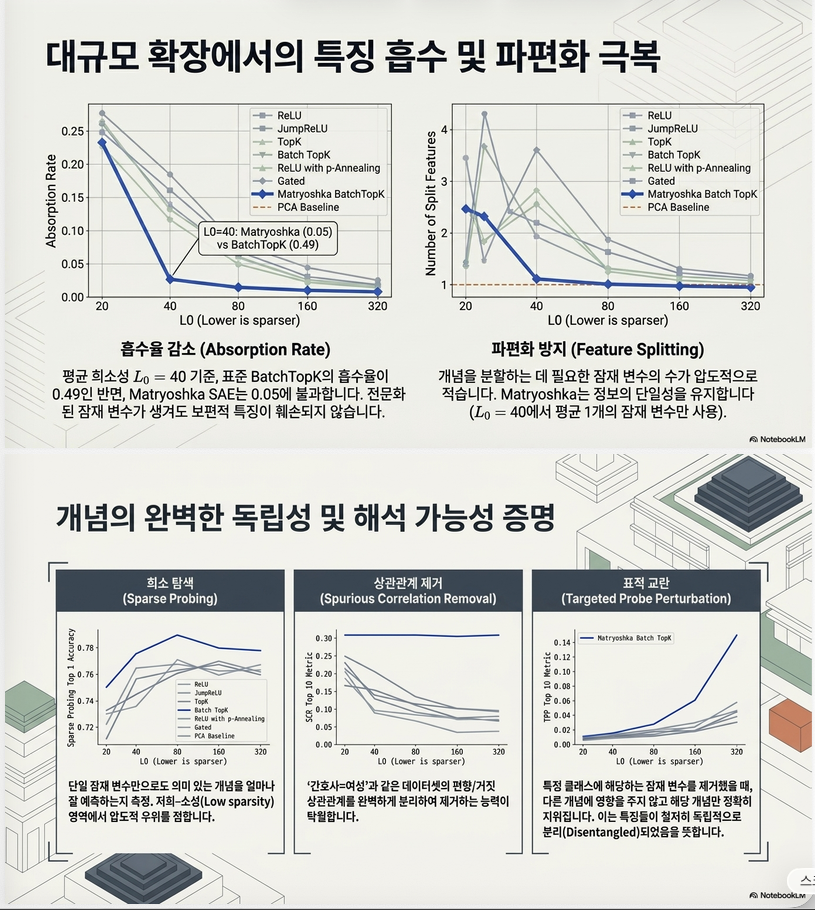
(3) Feature Absorption
가장 큰 개선입니다.
L0=40에서
- BatchTopK: 흡수율 ≈ 0.49
- Matryoshka: 흡수율 ≈ 0.05
약 10배 가까운 감소입니다.
(4) Feature Splitting
BatchTopK에서는 하나의 first-letter 개념을 표현하는 데 평균 약 3개의 latent가 필요했지만,
Matryoshka에서는 거의 1개의 latent로 표현되었습니다.
즉 feature splitting도 크게 감소했습니다.
(5) Sparse Probing
35개의 binary probing task에서 평가했습니다.
Matryoshka SAE는
- 특히 낮은 L0(20~80) 영역에서 최고 성능을 보였고,
- 모든 L0에서 기존 BatchTopK보다 우수한 sparse probing 성능을 달성했습니다.
(6) SCR (Spurious Correlation Removal)
Matryoshka SAE는 가장 높은 SCR 성능을 기록했습니다.
이는 gender와 profession 같은 spurious correlation을 더 잘 분리한다는 의미입니다.
(7) TPP (Targeted Probe Perturbation)
TPP에서도 최고 성능을 보였습니다.
즉 특정 feature를 제거했을 때 원하는 개념만 선택적으로 영향을 받는, 더 잘 disentangle된 표현을 학습했습니다.
(8) Feature Composition
Decoder cosine similarity를 비교한 결과,
Matryoshka SAE는 평균 최대 cosine similarity가 현저히 낮았습니다.
이는 서로 다른 latent들이 비슷한 정보를 중복 표현하는 일이 줄어들어 feature composition이 감소했음을 의미합니다.
(9) Automatic Interpretability
GPT-4o-mini 기반 자동 해석 평가에서,
Matryoshka SAE는 기존 BatchTopK와 동등하거나 더 나은 수준의 해석 가능성을 보였습니다.
(10) Dictionary Scaling
Dictionary 크기를
- 4K
- 16K
- 65K
로 늘리면서 비교한 결과가 특히 인상적입니다.
기존 SAE들은 dictionary가 커질수록 feature absorption, composition, probing 성능 등이 악화되는 경향을 보였지만,
Matryoshka SAE는 대부분의 지표에서 성능이 유지되거나 오히려 향상되었습니다. 이는 “dictionary를 크게 만들면 interpretability가 나빠진다”는 기존 문제를 상당 부분 완화할 수 있음을 보여줍니다.
답글 남기기