


다음은 **EMNLP 2025 논문 “Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors”**에 대한 핵심 정리입니다.
연구 동기
LLM 입력에는 종종 **오타(typo)**가 포함되며, 모델은 때때로 이를 내부적으로 보정해 올바른 의미를 복원합니다.
그러나 경우에 따라 오타는 모델의 성능 저하를 유발합니다.
이 연구는:
어떤 뉴런(neurons)과 어떤 어텐션 헤드(attention heads)가 오타를 감지·보정하는지 밝혀내는 것이 목표입니다.
주요 연구 질문
- LLM은 오타를 로컬 컨텍스트 기반으로 고칠 수 있는가?
- 더 긴 글로벌 컨텍스트를 이용해 의미를 회복하는가?
- 오타 처리에 관여하는 특정 뉴런/헤드가 존재하는가?
- 그들은 원래 오타 외의 일반 언어 기능도 담당하는가?
실험 설정 개요
Task
- **단어 정의(word-definition)**를 보고 해당 단어를 맞추는 워드 아이덴티피케이션 태스크 사용
- “a young swan” → “cygnet”
이는 모델의 어휘 지식을 직접 측정하기 위함입니다.
오타 데이터 생성 방법
- 중요도 높은 토큰들에 대해
- 임의 문자 1개 삽입(insertion typo)
예:
young → youneg
swan → s5wan토큰화를 혼동시키는 효과가 큼.
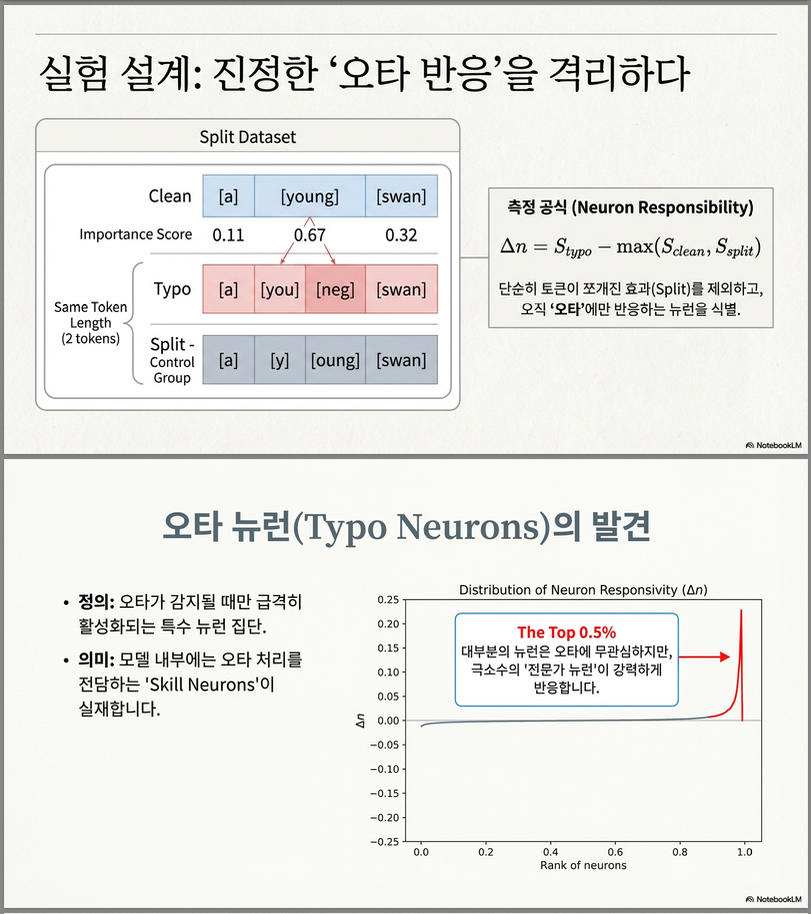
“Split Dataset” 개념
오타 토큰화 때문에 clean vs typo 비교가 어려움:
- young → you / neg (2 토큰)
따라서 오타는 없지만 토큰 수만 동일하게 split한 버전을 만들어 비교합니다.
예비결과: 성능 영향
오타 수를 늘릴수록 정확도↓
단, 모델 크기가 클수록 견고성↑.
Typo Neurons (오타 뉴런)
식별 방법
- clean vs typo vs split 데이터에서
- 뉴런 활성값 평균 비교
- typo 시 특이적으로 활성되는 뉴런을 상위 K개 추출
정의식은 Δn (responsibility score)
분포 관찰
- 초기(early) 레이어 또는 후기(late) 레이어에 많이 등장
- 모델 종류마다 차이
- 그러나 중간(middle) 레이어는 공통적으로 핵심적 역할 수행
- 글로벌 문맥 기반 typo-fixing
중요한 발견
early 또는 late 중 한 곳의 typo neuron만 있어도 typo-fix가 가능
Neuron Ablation (삭제 실험)
- typo neuron을 0으로 마스킹할 경우
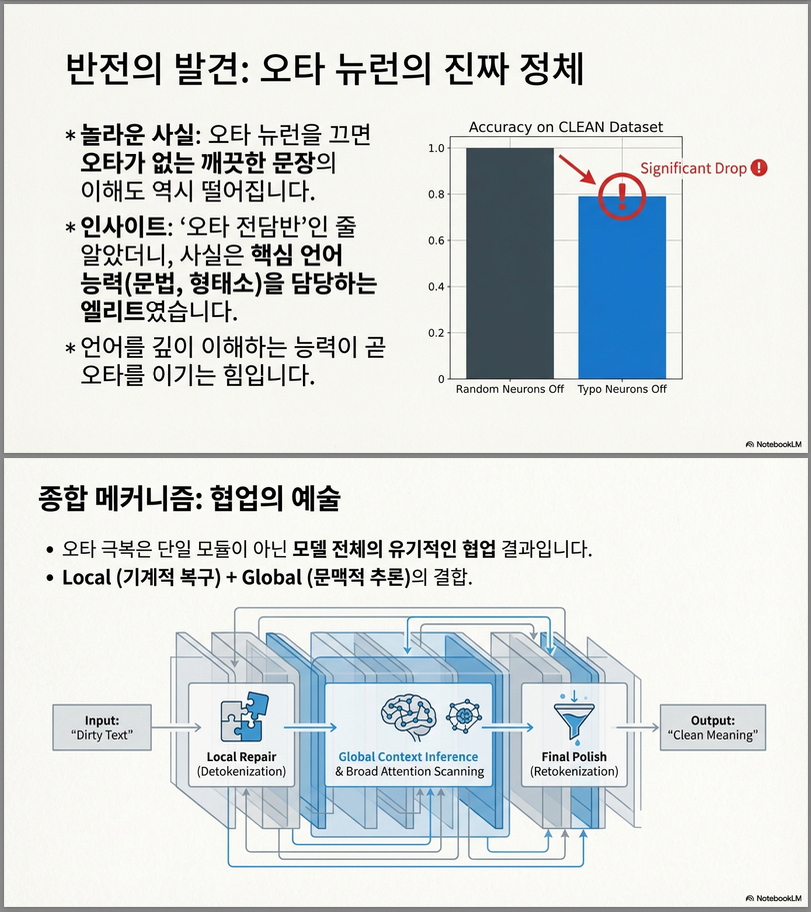
- 오타 처리 성능 크게 하락
- 랜덤 뉴런 제거는 영향 거의 없음
또한 clean 데이터에서도 성능 감소 →
typo neuron은 문법·형태 정보 처리에도 관여.
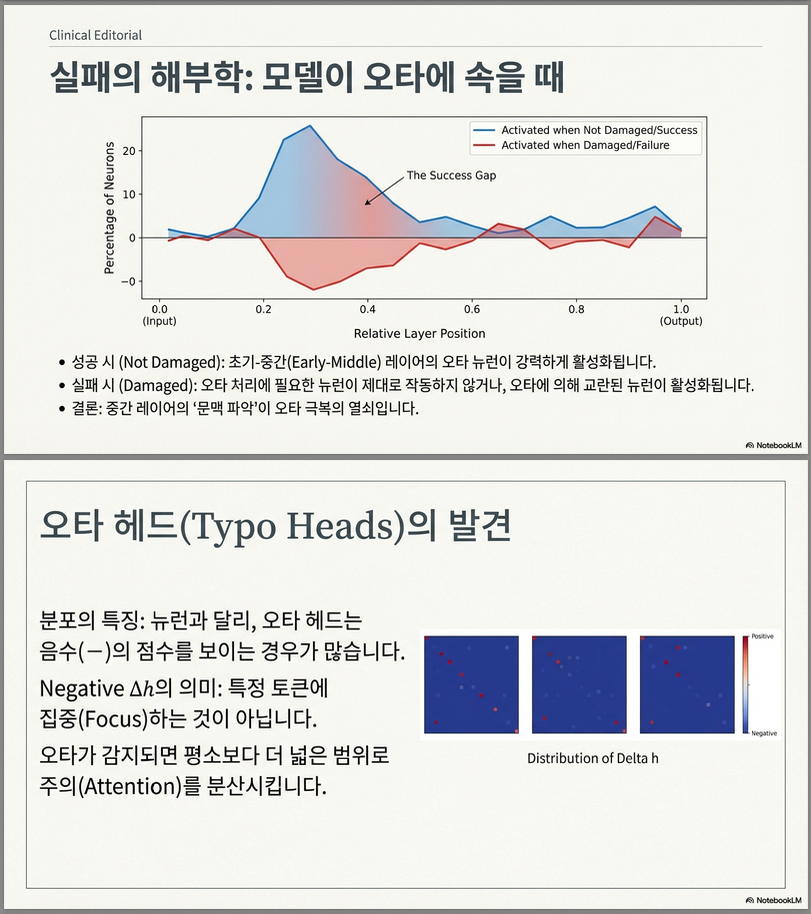
Typo Heads (오타 헤드)
아이디어
오타는 subword 병합 / 문맥 확인 과정에서 수정 가능하므로 self-attention heads도 관여할 것.
식별 방법
attention row vs uniform의 KL divergence 비교
→ 콘텍스트를 넓게 보는지 여부 판단
정의식 Δh 사용.
결과
- 많은 헤드가 typo 처리 시, 특정 토큰 집중이 아니라, 넓은 문맥(global) 을 고르게 참조함
- 큰 모델일수록 미묘하게 동작해 Δh ~ 0에 가까움
Head Ablation 결과
- 큰 모델에서는 typo head 제거해도 → 다수 헤드가 공동 보정하므로 영향 제한적
- 작은 모델에서는 → 소수 헤드에 의존 → ablation 영향 큼
Layer 역할 요약 (Lad et al. 2024 기반)
| 구간 | 역할 | Typo 관련 |
|---|---|---|
| Early | Detokenization (로컬) | 문자 단위 결합 |
| Middle | Feature engineering (글로벌) | 의미적 복원 핵심 |
| Late | Retokenization / Sharpening | 노이즈 제거 |
본 연구의 주요 결론
LLM들은 오타를 다음 방식으로 보정한다:
1) 로컬 컨텍스트 기반
- early 또는 late 층 typo neuron
- subword 복원
2) 글로벌 컨텍스트 기반
- 중간층 typo neuron
- 문맥적 의미 복원 핵심
3) Typo heads
- 특정 토큰에 집중하지 않고
- 주변 전체를 훑으며 오류 보정
4) 일반 문법·형태소 처리 기능과 공유
- typo neuron/head들은 오타 전용 장치가 아님
의미 및 시사점
- 모델의 typo-robustness를 강화하려면 → local + global context 둘 다 강화 필요
- typo-fixing 능력 개선은 → 일반 문법/문맥 인식 향상에도 도움
한계점
- 한 종류의 typo(insertion)만 사용
- 하나의 task만 사용
- 몇 가지 모델군(Gemma, Llama3, Qwen)만 실험
- ablation 해석 어려움: damaged neuron/heads 구분 불명확
한 줄 요약
오타는 LLM 내부에서 특정 뉴런과 헤드의 활성 패턴을 유발하며, 초기/후기 레이어는 로컬, 중간 레이어는 글로벌 의미 복원을 수행한다. 또한 이 구성요소들은 오타 외 일반 문법 처리에도 관여한다.
논문의 **방법론(Methodology)**을 핵심만 구조적으로 정리합니다.
연구 목표의 관점에서 본 방법론 흐름
이 논문의 방법론은 다음 5단계 파이프라인으로 구성됩니다:
| 단계 | 목적 | 핵심 요소 |
|---|---|---|
| 1 | 오타 없는 데이터 구성 | WordNet 기반 단어 정의 → 정답 단어 예측 |
| 2 | 오타 포함 데이터 생성 | 중요 토큰 선정 후 문자 삽입(insertion typo) |
| 3 | Tokenization 효과 분리 | Split Dataset 생성 (오타는 없지만 토큰 수 동일) |
| 4 | Typo Neuron 탐지 | clean / typo / split 간 뉴런 활성도 비교 |
| 5 | Typo Head 탐지 | KL divergence 기반 attention 패턴 비교 |
아래에서 각 단계를 상세히 풀이합니다.
1. Clean Dataset 생성 (Word Identification Task)
- WordNet에서 단어 정의(word-definition) → 정답 단어 형태의 62,643쌍을 수집
- 예: “a young swan” → “cygnet”
- LLM이 정답을 맞출 수 있는 샘플만 선택
- 확률 상위 5,000개(혹은 Llama3에는 1,000개)
목적 → 오타가 정확도 하락을 일으키는지 명확히 관찰하려면, 모델이 원래는 정답을 맞출 수 있는 샘플로 구성되어야 함.
2. Typo Dataset 생성 (삽입형 오타)
- 입력 정의문에서 중요 토큰 t개 선택
- 중요도는 gradient 기반 토큰 중요도(backprop)
- 각 토큰에 문자 1개 삽입
- 예: young → youneg, swan → s5wan
- 오타 유형은 **삽입(insertion)**으로 통일
이유 → randomness를 줄이고 typo가 semantic 정보 손실 + tokenization 변환의 원인이 되도록 설계
3. Split Dataset 생성 (tokenization 영향 분리)
오타가 생기면 토크나이저는 한 단어를 여러 서브워드로 나눔:
young → you / neg (토큰 2개)그러면 활성화값 차이가 tokenization 때문인지 typo 때문인지 구분 불가
따라서 split dataset 생성:
young → y / oung (2개)
(오타는 없지만 토큰 수 동일)역할 → typo dataset vs clean dataset 비교 시 token 수 차이 노이즈 제거
4. Typo Neuron 식별 (Δn score)
각 뉴런 n의 타입별 활성도 평균을 계산:
| Dataset | 의미 |
|---|---|
| clean | 오타 없음 |
| typo | 오타 포함 |
| split | 토큰 수는 같지만 오타 없음 |
핵심 지표:
→ typo일 때 특이적으로 더 활성되는 뉴런을 typo neuron이라 규정
→ Δn이 큰 상위 0.5% 뉴런 추출
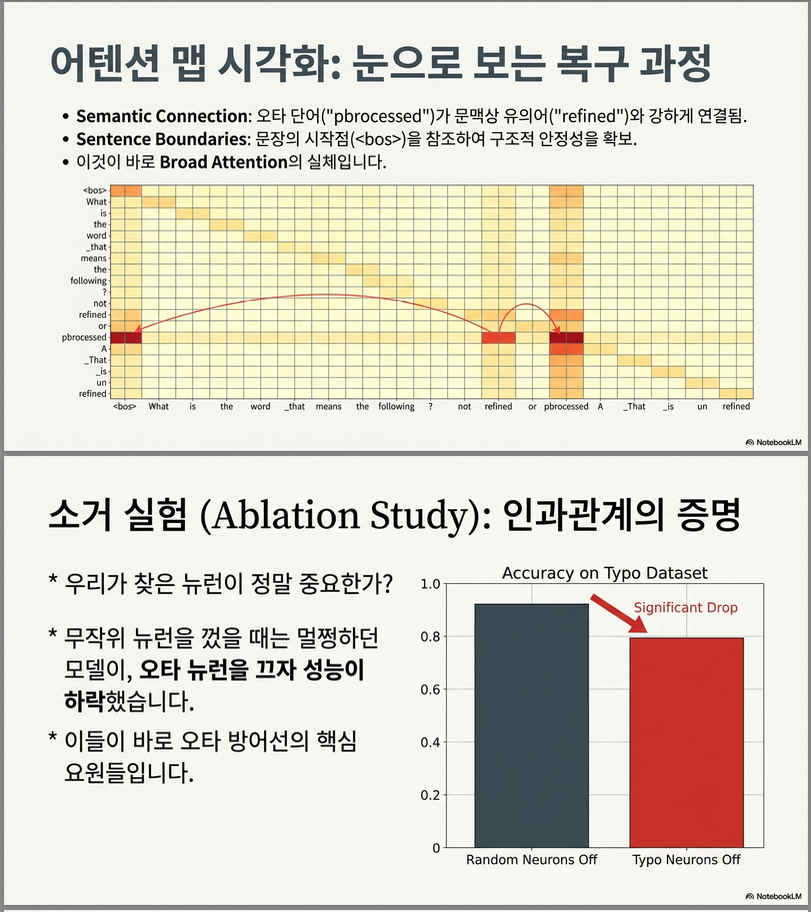
검증 (Ablation)
- typo neurons를 0으로 마스킹 → 오타 정답률 크게 감소 → 랜덤 뉴런 제거는 영향 미미
– 결론
→ typo neuron은 실질적으로 typo-fixing 과정에 기여
→ clean 데이터 성능도 떨어짐 → 일반 문법·형태소 처리에도 관여
5. Typo Head 탐지 (Δh score)
Self-attention head의 행을 확률분포로 보고
→ uniform distribution과의 KL divergence로 집중 정도를 계산
문제점: token 수 증가하면 KL divergence 값 증가
→ log₂(m)로 정규화하여 해결
head 책임 점수:
- Δh가 크게 음수 → 특정 토큰 집중이 아니라 넓게 분산된 글로벌 주의
- 절댓값 큰 상위 1.5% heads → typo heads
검증 (Ablation)
- 작은 모델: typo head 제거 → 정답률 급감
- 큰 모델: 영향 완화 (다수 head가 협력 → redundancy)
– 결론
→ 작은 모델: 특정 head가 typo-fixing의 핵심
→ 큰 모델: 협력 분산적 typo-fixing
방법론의 핵심 요약 그림
┌───────────────┐
│ Clean dataset │
└───────────────┘
│
┌───────────────┴───────────────┐
▼ ▼
Typo dataset Split dataset
| |
└─────────── 비교 · 정량화 ───────┘
|
┌────────────┴────────────┐
▼ ▼
Δn (Feed-forward neurons) Δh (Attention heads)
| |
상위 0.5% typo neurons 상위 1.5% typo heads왜 이 방법론이 독창적인가?
| 기존 연구 | 본 논문 |
|---|---|
| 오타가 성능에 미치는 영향 보고 | 오타를 고치는 내부 회로를 규명 |
| 로컬 컨텍스트 위주 | 글로벌 컨텍스트까지 고려 |
| layer-level 분석 | neuron-level + head-level 분석 |
| “성능 감소” 관찰 | “어떻게 고치는가” 관찰 |
한 문장으로 요약
clean / typo / split 입력에서의 내부 활성값 차이를 정량화해, 오타를 감지·보정하는 뉴런과 헤드가 어디에 있고 어떻게 동작하는지 추적하는 방법론.
아래는 논문의 **실험 결과(Experimental Results)**를 정리한 내용입니다.
1) 오타에 대한 성능 변화 (Preliminary)
설정
- Word identification task
- 오타 개수
- 모델: Gemma 2 (2B/9B/27B), Llama 3(1B/3B/8B), Qwen 2.5(3B/7B/14B/32B)
결과
- 오타 수 증가 → 정확도 감소
- 모델 크기↑ → 오타 견고성↑
Larger models maintain higher accuracy even with many typos.
해석
- LLM은 typo robustness를 가지지만 완전하지 않음
- Robustness는 parameter scale과 양의 상관
2) Typo Neuron 분포 결과
Δn 기반 typo neuron 식별
- 상위 0.5% 뉴런을 typo neuron으로 정의
- 대부분 뉴런은 Δn ≈ 0
- 소수 뉴런만 매우 큰 Δn
Few neurons have significantly larger scores than others.
레이어별 분포
공통점
- **Middle layers (0.2–0.8 구간)**에 typo neuron 집중
- 글로벌 문맥 기반 복원 핵심
모델별 차이
| 모델 | Early | Middle | Late |
|---|---|---|---|
| Gemma 2 | 많음 | 많음 | 적음 |
| Llama 3 | 적음 | 많음 | 많음 |
| Qwen 2.5 | 적음 | 많음 | 많음 |
Typo neurons in the middle layers are responsible for typo-fixing considering global contexts.
많은 오타 (t=16) 실험
- Δn 최대값 증가 → typo neuron 더 강하게 활성
- 대형 모델(27B, 32B)은 neuron 수 거의 증가하지 않음 → 이미 충분히 robust
Typo neurons remain highly consistent even when the number of typos changes.
NDCG 결과도 매우 높음 → typo neuron은 안정적으로 존재
3) Neuron Ablation 결과
설정
- typo neuron 0.5% 제거
- 랜덤 뉴런 제거와 비교
결과 (Gemma 2 예)
| 모델 | Clean | Typo |
|---|---|---|
| Random neuron 제거 | 거의 변화 없음 | 거의 변화 없음 |
| Typo neuron 제거 | 성능 감소 | 더 크게 감소 |
Ablating typo neurons significantly reduces performance on typo inputs.
중요한 관찰
- clean 데이터에서도 성능 감소 → typo neuron은 일반 문법·형태소 처리 기능도 담당
4) 성공 vs 실패 샘플 비교
오타가 성공적으로 복원된 경우 vs 실패한 경우 비교:
- 성공 케이스:
- Early-middle layer typo neuron 활성↑
- 실패 케이스:
- 일부 early layer 뉴런이 잘못 활성
- 2B 모델은 middle-middle 과도 활성
Early-middle layers appear important when typos do not damage inference.
해석
- typo-fixing의 핵심은 중간 레이어
- early/late는 로컬 보정
- middle은 글로벌 의미 복원
5) Typo Head 실험 결과
Δh 분포
- Δh 대부분 음수
- 의미:
- 특정 토큰 집중이 아니라
- 넓은 문맥을 고르게 참조
Heads recognize and fix typos by observing wider contexts.
모델 크기 효과
- 모델 크기↑ → Δh ≈ 0인 head 증가
- 큰 모델일수록 분산적 처리
6) Head Ablation 결과
Gemma 2 결과 요약
| 모델 | Random head 제거 | Typo head 제거 |
|---|---|---|
| 2B | 약간 감소 | 크게 감소 |
| 9B | 감소 | 유사 감소 |
| 27B | 큰 감소 | 비슷한 감소 |
Many heads cooperate in larger models.
해석
- 작은 모델 → 소수 head 의존
- 큰 모델 → 다수 head 협력적 typo-fixing
7) 전체 실험에서 도출된 핵심 결론
Typo-fixing은 2축 구조
(1) Local Context 기반
- Early or Late layers
- Detokenization / Retokenization
(2) Global Context 기반
- Middle layers
- Feature Engineering
뉴런과 헤드의 역할 차이
| 요소 | 역할 |
|---|---|
| Typo Neuron | 오타 감지 + 의미 복원 |
| Typo Head | 문맥 확산적 탐색 |
| 둘 다 | 일반 문법/형태 처리에도 기여 |
8) 종합 해석 (Mechanistic 관점)
이 실험은 다음을 보여줍니다:
- 오타는 단순 token-level noise가 아님
- 중간 레이어에서 의미적 재구성 발생
- 큰 모델은 redundancy 기반 robustness
- typo neuron은 “전용 회로”가 아니라 → general language skill neuron과 overlap
한 줄 요약
LLM은 오타를 단순 문자 복원이 아니라, 로컬 + 글로벌 문맥을 이용한 계층적 의미 재구성 과정으로 처리하며, 그 과정은 소수 뉴런과 다수 헤드의 협력 구조로 이루어진다.
답글 남기기