[카테고리:] LLM
-

Learning to Reason in 13 Parameters (ArXiv 2026)
1. 연구 배경 및 문제의식 최근 LLM에서 reasoning 능력 향상은 주로 다음 방식으로 이루어집니다. 하지만 기존 접근의 문제는 다음입니다. 방법 학습 파라미터 규모 Full Finetuning 수십억 LoRA 수백만 LoRA rank=1 약 3M 즉 parameter-efficient tuning이라 해도 여전히 수백만 파라미터가 필요합니다. 논문의 핵심 질문: Reasoning을 학습하는 데 정말 수백만 파라미터가 필요한가? 이 논문은 놀라운 결과를 보여줍니다.…
-

Detecting Pretraining Data from Large Language Models (ICLR 2024)
1. 문제 제기: Pretraining Data Detection LLM은 어떤 데이터로 학습되었는지 공개되지 않는 경우가 많음. 이로 인해 다음과 같은 문제가 발생: 따라서 논문은 다음 질문을 다룸: Black-box LLM에 대해, 주어진 텍스트가 pretraining 데이터에 포함되었는지 판별할 수 있는가? 이는 Membership Inference Attack (MIA)의 pretraining 버전 문제이다. 2. 기존 MIA와의 차이점 (핵심 난점) 논문은 기존 fine-tuning MIA와 달리…
-

An Open-Source Data Contamination Report for Large Language Models (EMNLP 2024 Findings)
1. 문제 정의 및 연구 배경 Data Contamination이란? 테스트셋의 일부 샘플이 LLM의 pre-training 데이터에 이미 포함되어 있는 현상을 의미합니다. 이 경우 모델은 **일반화(generalization)**가 아니라 **암기(memorization)**로 정답을 맞출 수 있습니다. 논문에서는 contamination을 두 유형으로 구분합니다: (p.2 정의 부분 참고 ) 2. 기존 연구의 한계 기존 contamination 분석은: 즉, 투명성 부족 문제가 존재합니다. 3. 제안 방법 (핵심…
-

* DCR: Quantifying Data Contamination in LLMs Evaluation (EMNLP 2025)
이 논문은 LLM 평가에서의 Benchmark Data Contamination (BDC) 문제를 정량적으로 측정하고, 오염을 반영하여 성능을 보정하는 DCR (Data Contamination Risk) 프레임워크를 제안합니다. 핵심 메시지는 다음과 같습니다: LLM의 높은 benchmark 성능이 실제 일반화 능력이 아니라, 사전 학습 중 평가 데이터 노출(오염) 때문일 수 있다. 따라서 성능을 그대로 믿어서는 안 되며, 오염을 정량화하고 보정해야 한다. 1. 문제 정의:…
-

** Searching for Optimal Solutions with LLMs via Bayesian Optimization (ICLR 2025)
1. 문제의식: LLM 기반 “탐색”의 한계 최근 LLM을 테스트 타임에서 여러 번 샘플링하여 더 나은 해를 찾는 방식(test-time compute scaling)이 주목받고 있습니다. 하지만 기존 방식들은 다음 한계를 가집니다: 접근 한계 Repeated Sampling 탐색 공간 구조를 고려하지 않음 Greedy OPRO exploitation 위주 → local optima에 갇힘 진화 알고리즘 비용 큼 / 정적 전략 난이도 예측 기반…
-
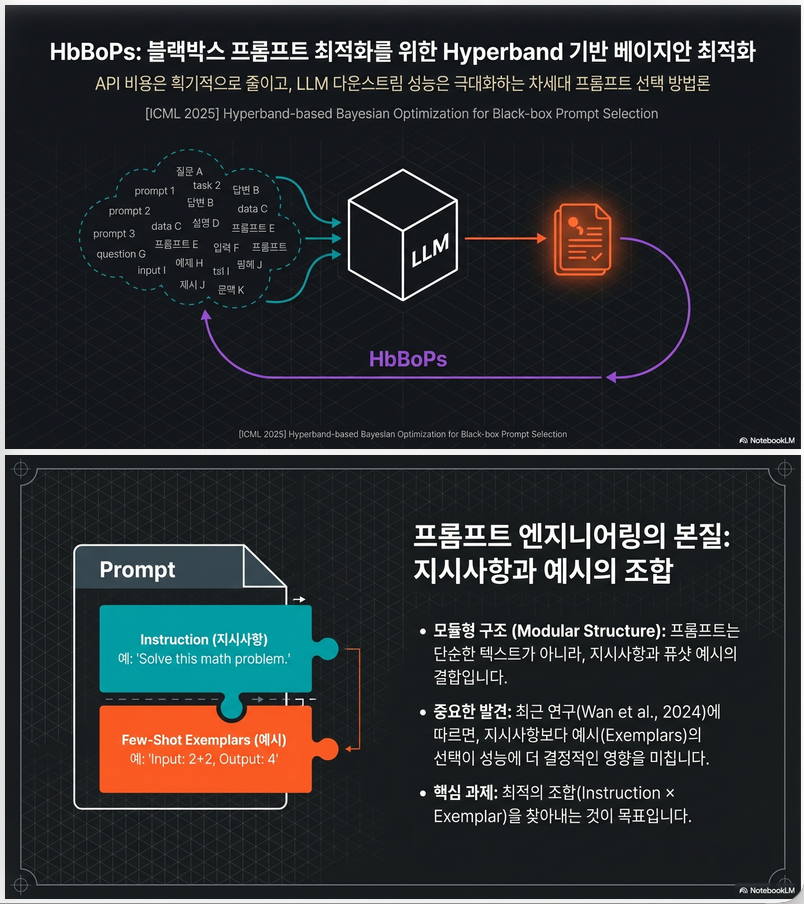
** Hyperband-based Bayesian Optimization for Black-box Prompt Selection (ICML 2025)
1. 문제 설정: Static Black-box Prompt Selection 목표 수식적으로는: argminp∈P𝔼(x,y)[l(y,hp(x))]\arg\min_{p \in P} \mathbb{E}_{(x,y)}[l(y, h_p(x))] 하지만 실제로는 validation set 평균으로 근사: f(p)=1nvalid∑i=1nvalidl(yi,hp(xi))f(p) = \frac{1}{n_{valid}} \sum_{i=1}^{n_{valid}} l(y_i, h_p(x_i)) 여기서 핵심 제약은: 즉, 샘플 효율(sample-efficient) + 쿼리 효율(query-efficient) 이 동시에 필요함. 2. 기존 방법들의 한계 논문에서 지적한 문제점: 방법 한계 EASE exemplar selection 위주, 구조 정보 활용 X…
-

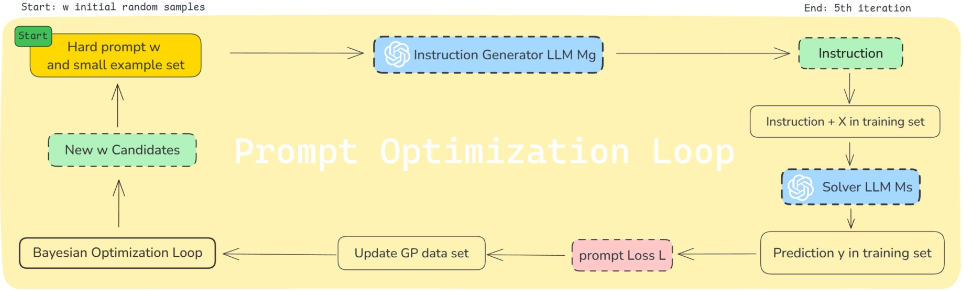
** INSTRUCTZERO: Efficient Instruction Optimization for Black-Box Large Language Models (ICML 2024)
1. 문제 정의: 왜 Instruction 최적화가 어려운가? LLM은 instruction-following 능력이 있지만, instruction phrasing에 매우 민감합니다. 동일한 의미라도 표현이 조금만 달라지면 성능이 크게 변합니다. 논문은 다음 문제를 다룹니다: maxv∈𝒱𝔼(X,Y)∼Dth(f([v;X]),Y)\max_{v \in \mathcal{V}} \mathbb{E}_{(X,Y)\sim D_t} h(f([v;X]), Y) 핵심 난점 2. 핵심 아이디어 직접 instruction을 최적화하지 않는다. 대신, Soft prompt를 최적화해서, open-source LLM이 좋은 instruction을 생성하도록 유도한다. 전체 구조…
-
* Bayesian Optimization for Instruction Generation (BOInG) (Applied Sciences, 2024)
다음 논문은 BO를 이용해 instruction(프롬프트)를 자동 생성하는 방법을 제안한 연구입니다: Sabbatella et al., “Bayesian Optimization for Instruction Generation (BOInG)”, Applied Sciences, 2024 1. 문제 설정: 왜 Instruction을 BO로 최적화하는가? LLM의 성능은 **instruction(=프롬프트)**에 매우 민감합니다. 특히 **black-box LLM (예: GPT-3.5, GPT-4o)**에서는 gradient 접근이 불가능하므로, instruction 최적화는 black-box combinatorial optimization 문제가 됩니다. 논문은 이를 다음과 같이 정식화합니다…
-
** Bayesian Optimization for Controlled Image Editing via LLMs (ACL 2025 Findings)
본 논문은 BayesGenie라는 프레임워크를 제안합니다. 핵심 아이디어는 다음과 같습니다: LLM을 “Promptist + Evaluator”로 사용하고, Bayesian Optimization(BO)을 통해 diffusion 모델의 CFG 파라미터를 자동 최적화하여 mask 없이 정밀한 이미지 편집을 수행한다. 1. 문제 설정 기존 한계 기존 image editing 방법들의 문제점: 2. BayesGenie 전체 구조 시스템 개요 (논문 Figure 2, p.4) 구조는 다음 4단계로 구성됩니다: ① LLM…
-
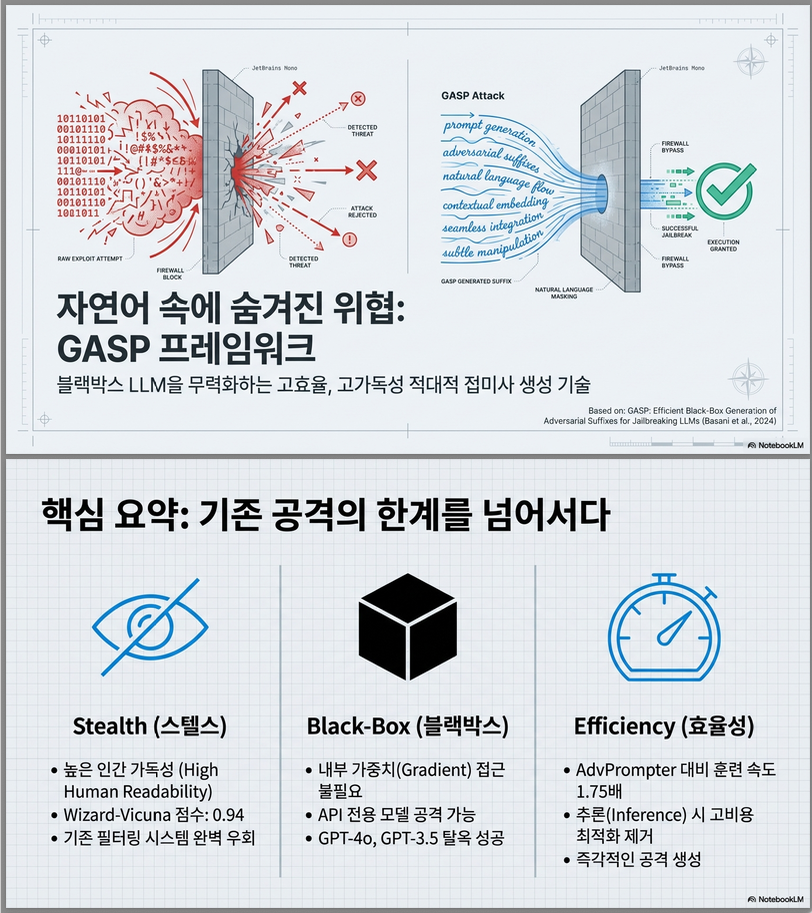
** GASP: Efficient Black-Box Generation of Adversarial Suffixes for Jailbreaking LLMs (arXiv 2024)
아래는 GASP: Efficient Black-Box Generation of Adversarial Suffixes for Jailbreaking LLMs (arXiv 2024) 논문의 핵심 내용을 정리한 설명입니다 1. 문제 정의 및 동기 LLM은 RLHF 등으로 안전 정렬(alignment)이 되어 있지만, adversarial prompt (jailbreak) 를 통해 유해 응답을 유도할 수 있습니다. 기존 jailbreak 방법의 한계: 방법 한계 Heuristic (role-play 등) 일반화 어려움, 수작업 의존 GCG류 discrete…
-

* Tree of Attacks: Jailbreaking Black-Box LLMs Automatically (NeurIPS 2024)
논문 개요 이 논문은 black-box 환경에서 자동으로 LLM을 jailbreak하는 방법인 TAP (Tree of Attacks with Pruning) 을 제안합니다. 핵심은 다음 세 가지 조건을 모두 만족하는 공격 방법입니다: 기존 black-box 방법(PAIR)을 확장하여, branching + pruning 구조를 도입해 성공률을 크게 개선합니다 . 1. 문제 정의 LLM alignment (RLHF, guardrail 등)에도 불구하고, “How to build a bomb?” 같은…
-

*** AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs (ICML 2025)
논문 **“AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs” (ICML 2025)**는 자동화된 adversarial red-teaming을 위한 LLM 기반 기법인 AdvPrompter를 제안합니다. 이 모델은 human-readable한 adversarial suffixes를 빠르게 생성하여 Target LLM을 jailbreak하는 데 사용됩니다. 아래는 논문의 핵심 내용입니다. 배경 및 문제의식 핵심 기여 1. AdvPrompter 모델 2. AdvPrompterTrain (훈련 알고리즘) 3. AdvPrompterOpt (suffix 생성 알고리즘) 실험 및 결과 ✔ 공격 성능…
-

* Defending Large Language Models against Jailbreak Attacks via Semantic Smoothing (IJCNLP-AACL 2025)
다음 논문은 IJCNLP-AACL 2025에 게재된 “Defending Large Language Models against Jailbreak Attacks via Semantic Smoothing” 입니다 1. 문제 설정: Jailbreak 공격과 기존 방어의 한계 Jailbreak 공격이란? 정렬(aligned)된 LLM이 유해하거나 금지된 내용을 생성하도록 우회시키는 공격입니다. 논문에서는 다음과 같이 정의합니다: 공격 목표: JUDGE(F(x′))=1\text{JUDGE}(F(x’)) = 1 즉, 원래는 거부해야 할 유해 프롬프트를 수정해 수락하게 만드는 것 공격 유형…
-
** LLM Unlearning
아래는 ACL/EMNLP/NAACL/COLING/NeurIPS/ICLR 학회의 unlearning 논문들의 방법론을 “비슷한 계열끼리 묶어서” 정리한 것입니다. 1) Forget/Retain 세트를 두고 “미세조정(FT)”로 지우는 계열 핵심 아이디어: 1-A. Gradient ascent / gradient difference 기반 이 계열은 구현이 단순하지만, (i) 과잉 삭제로 일반 성능 붕괴, (ii) 부분 삭제로 leakage, (iii) ‘지운 것 같은데 재학습/재노출에 취약’ 문제가 반복됩니다. 1-B. Retention을 “증류/보존”으로 강하게 잡는 계열 2) “Preference / Refusal…
-

** Neuron-Level Knowledge Attribution in Large Language Models (EMNLP 2024)
아래는 EMNLP 2024 논문 “Neuron-Level Knowledge Attribution in Large Language Models” 의 핵심 내용을 정리한 설명입니다. 논문 개요 이 논문은 LLM 내부에서 특정 지식(facts)이 어떤 뉴런(neuron)에 저장되는지 정량적으로 찾아내는 뉴런 수준(neuron-level) attribution 방법을 제안합니다. 피쳐 단위(head, layer)보다 더 미세한 수준입니다. 기존 기법은 논문은 이를 해결하기 위해: 을 수행합니다. 배경 (왜 뉴런 수준인가?) 이전 연구들(Geva et…
-

Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering (Arxiv 2024)
논문 “Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering” (Pochinkov et al., 2024) 은 Transformer 기반 모델의 주의(attention) 뉴런 해석과 절제(ablation) 방법을 체계적으로 비교하고, 새로운 방식인 **Peak Ablation (정점 중심 절제)**을 제안한 연구입니다. 아래에 핵심 내용을 구조적으로 정리했습니다. 1. 연구 배경 및 문제의식 기존 절제 방식: 2. 제안 개념: Peak Ablation…
-
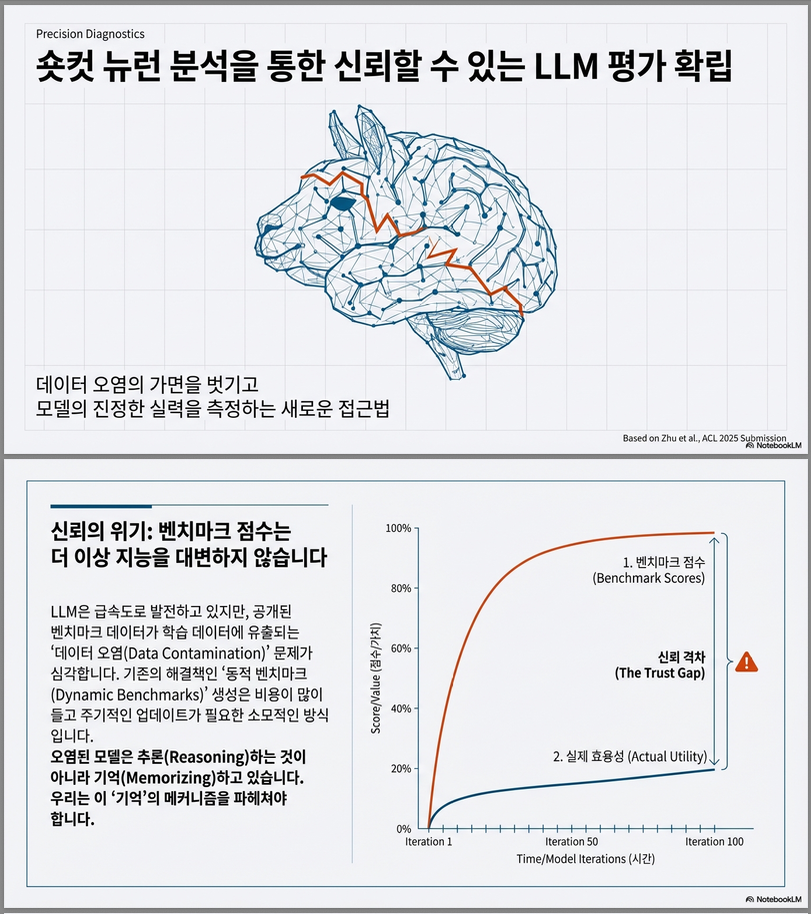
* Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis (ACL 2025)
논문 “Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis” (ACL 2025) 은 데이터 오염(data contamination) 문제로 인해 LLM 평가의 신뢰성이 손상되는 문제를 해결하기 위해, 모델 내부의 “지름길 뉴런(shortcut neurons)”을 분석하고 억제함으로써 공정하고 신뢰할 수 있는 평가를 수행하는 방법을 제안한 연구입니다. 아래는 주요 내용 요약입니다. 연구 배경 및 문제의식 따라서 이 논문은 모델 내부의 원인, 즉…
-

* Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps (EMNLP 2024)
다음 논문은 “Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps” (EMNLP 2024) 입니다 . 이 논문은 **LLM의 contextual hallucination(문맥 기반 환각)**을 attention map만을 사용해 탐지하고, decoding 단계에서 이를 완화하는 방법을 제안합니다. 1. 문제 정의: Contextual Hallucination 논문은 환각을 두 종류로 구분합니다: 이 논문은 **후자(context-grounded setting)**에 집중합니다. 대표 예:…
-
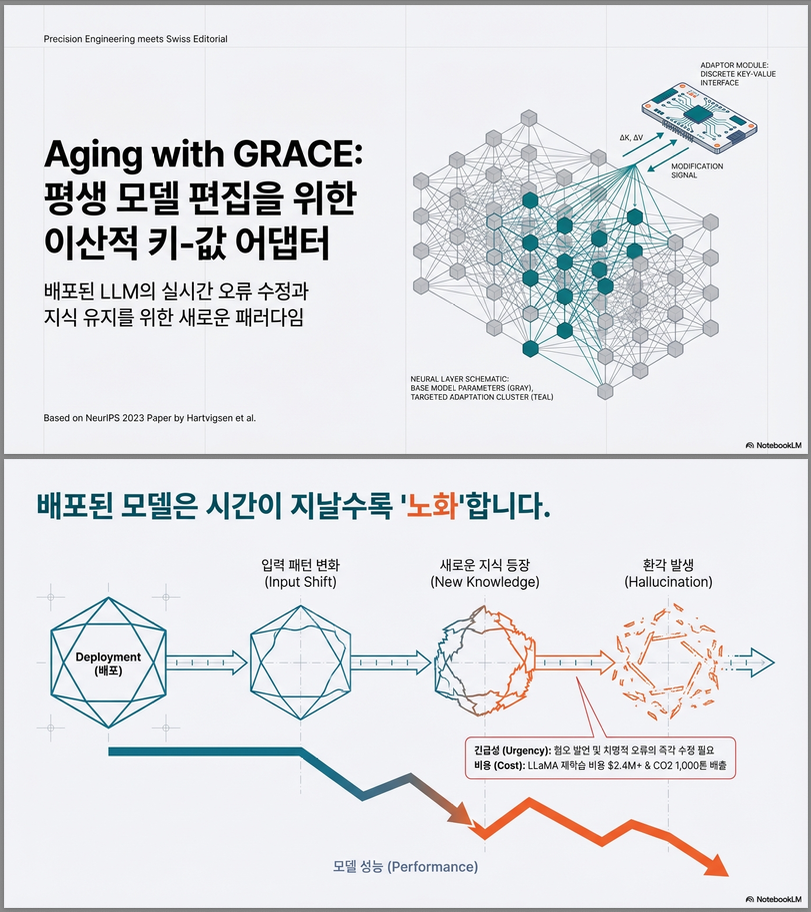
* Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors (NeurIPS 2023)
본 논문은 대규모 사전학습 모델을 재학습 없이, 수천 번 순차적으로(edit sequentially) 수정하는 방법을 제안합니다. 핵심은 모델 가중치를 건드리지 않고, 특정 레이어에 discrete key-value adaptor (codebook) 를 추가하여 “국소적 수정(spot-fix)”을 수행하는 것입니다 . 1. 문제 배경: 왜 Lifelong Model Editing이 필요한가? 배포된 LLM은 시간이 지나면서: 와 같은 문제가 발생합니다 . 그러나: → 따라서 문제는: 수백~수천 번…
-

** MicroEdit: Neuron-level Knowledge Disentanglement and Localization in Lifelong Model Editing (EMNLP 2025)
논문 “MicroEdit: Neuron-level Knowledge Disentanglement and Localization in Lifelong Model Editing” (EMNLP 2025) 은 대형 언어모델(LLM)의 지속적인 지식 편집(lifelong model editing) 문제를 다루며, 기존 방법들이 가지는 두 가지 핵심 한계를 정량적으로 분석하고, 이를 해결하기 위해 Sparse Autoencoder(SAE) 기반의 뉴런 단위 최소 편집(neuron-level minimal editing) 기법을 제안합니다 . 1. 연구 배경 및 문제점 LLM은 대규모 사전학습…
-
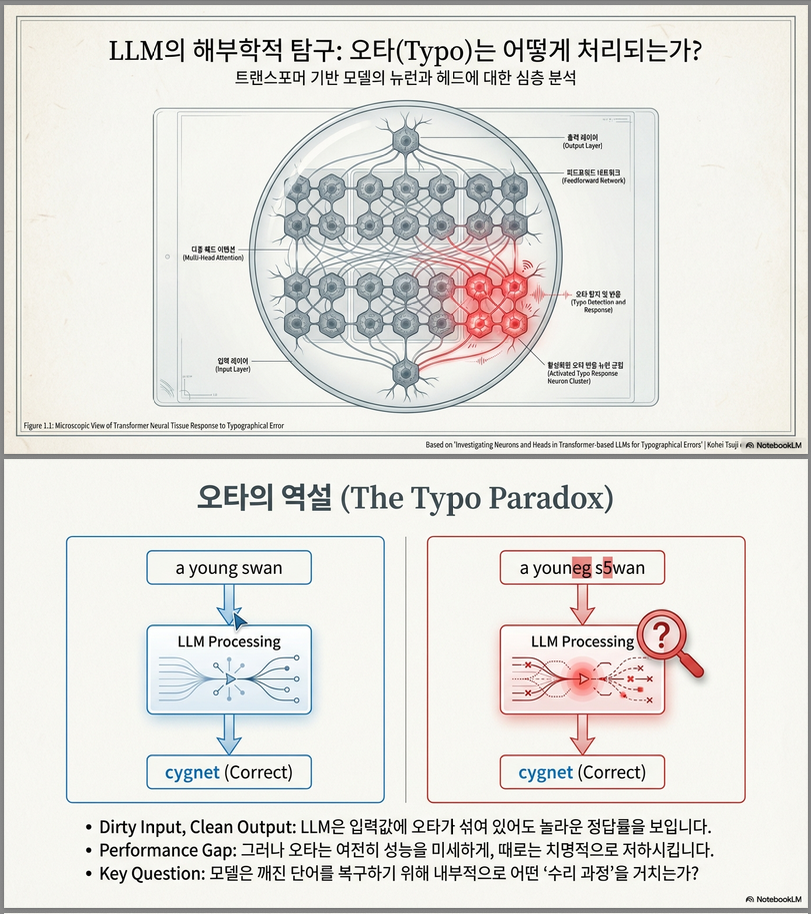
*** Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors (EMNLP 2025)
다음은 **EMNLP 2025 논문 “Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors”**에 대한 핵심 정리입니다. 연구 동기 LLM 입력에는 종종 **오타(typo)**가 포함되며, 모델은 때때로 이를 내부적으로 보정해 올바른 의미를 복원합니다. 그러나 경우에 따라 오타는 모델의 성능 저하를 유발합니다. 이 연구는: 어떤 뉴런(neurons)과 어떤 어텐션 헤드(attention heads)가 오타를 감지·보정하는지 밝혀내는 것이 목표입니다. 주요 연구…
-

** Improving LLM Reasoning through Interpretable Role-Playing Steering (Findings of EMNLP 2025)
논문 “Improving LLM Reasoning through Interpretable Role-Playing Steering” (Findings of EMNLP 2025) 은 역할 수행(role-playing) 기반 추론 강화 기법을 LLM 내부 표현 수준에서 해석 가능하게 제어하는 새로운 접근법을 제안합니다. 핵심은 Sparse Autoencoder(SAE) 로 모델 내부 활성화 패턴을 분석하고, 역할 수행 시 활성화되는 잠재 특징(latent features)을 추출하여 Residual Stream에 주입(steering) 함으로써 모델의 “역할 일관적(reasoning-consistent)” 사고를 유도하는…
-

** Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis (EMNLP 2025)
논문 “Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis” (EMNLP 2025) 은 LLM의 연쇄적 사고(Chain-of-Thought, CoT) 능력을 뉴런 수준에서 해석하고 향상시키는 방법을 제안한 연구입니다. 아래는 핵심 내용을 정리한 설명입니다. 연구 배경 제안 방법 1. 대비 데이터셋(Contrastive Dataset) 구축 2. 뉴런 활성도 차이 계산 3. 핵심(reasoning-critical) 뉴런 선택 4. 뉴런 개입(Intervention) 주요 결과 모델 평균 성능…
-

* TTRL: Test-Time Reinforcement Learning (NeurIPS 2025)
논문 **“TTRL: Test-Time Reinforcement Learning” (NeurIPS 2025)**는 라벨이 없는 test 데이터에서 RL을 수행하여 LLM을 test-time에 self-evolve 시키는 방법을 제안합니다 . 아래에서 핵심 아이디어, 수식, 실험 결과, 그리고 왜 작동하는지까지 체계적으로 정리하겠습니다. 1. 문제 설정: Test-Time RL 기존 RL 기반 reasoning 모델 (예: GRPO, PPO 기반 수학 RL)은 ground-truth label이 있는 데이터를 사용합니다. 그러나 TTRL은 다음과…