



이 논문은 **Transformer의 multi-head attention(MHA)가 정말로 많은 head를 필요로 하는가?**라는 매우 직관적인 질문을 실증적으로 파고든 고전적인 분석 논문입니다.
아래에서 문제의식 → 방법론 → 실험 결과 → 핵심 해석 → 이후 연구에 미친 영향 순서로 정리해 드릴게요.
(논문: Are Sixteen Heads Really Better than One?, NeurIPS 2019)
1. 문제의식 (Motivation)
Transformer에서 multi-head attention은 다음과 같은 이유로 도입되었습니다.
- 서로 다른 attention head가 → 다른 위치, 다른 관계, 다른 정보 유형에 집중할 수 있다
- 이론적으로는 single-head attention보다 표현력이 더 강하다
하지만 저자들은 다음 질문을 던집니다.
❓ 학습이 끝난 뒤(test time)에, 정말 모든 attention head가 필요한가?
❓ 혹시 대부분의 head는 중복(redundant) 아닌가?
2. 핵심 아이디어 요약
이 논문의 핵심은 “학습된 모델을 건드리지 않고, test time에 attention head를 제거해보자” 입니다.
- 재학습 없음
- head masking / pruning
- 성능이 얼마나 떨어지는지(혹은 안 떨어지는지) 관찰
3. 실험 설정 (Experimental Setup)
사용 모델
- Transformer (WMT14 En→Fr)
- 6 layers
- layer당 16 heads
- BLEU 평가
- BERT-base (MNLI)
- 12 layers
- layer당 12 heads
- Accuracy 평가
4. 실험 1: Head 하나씩 제거하기 (Single-head Ablation)
방법
- 특정 head h의 출력을 0으로 마스킹
- 나머지는 그대로 둠
- 성능 변화 측정
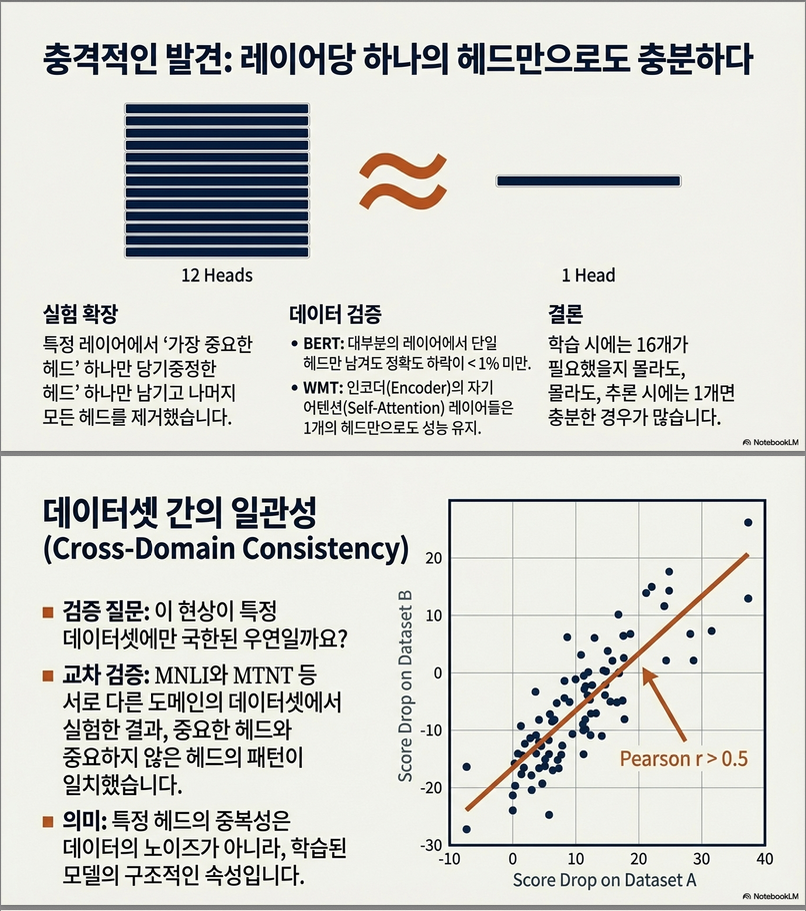
결과 (Figure 1, Table 1)
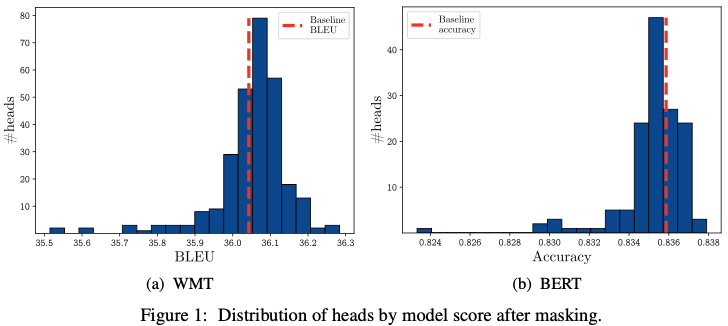
- 대부분의 head를 제거해도 성능 변화 거의 없음
- 어떤 경우에는:
- head 제거 후 성능이 오히려 상승
- WMT encoder self-attention 기준:
- 96개 head 중 단 8개만 유의미한 영향
📌 결론 1
학습이 끝난 모델에서는 대부분의 attention head가 redundant하다.
5. 실험 2: 한 layer에서 head 하나만 남기기
질문
그렇다면 layer당 head는 1개면 충분한가?
방법
- 한 layer에서 가장 좋은 head 1개만 남기고 나머지 제거
- layer별로 반복
결과 (Table 2, Table 3)
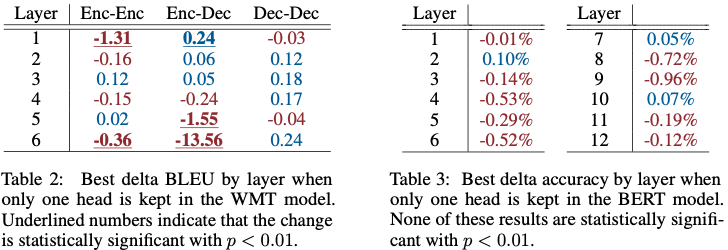
BERT
- 모든 layer에서
- head 1개만 남겨도 성능 저하 없음 (통계적으로 유의미하지 않음)
WMT
- 대부분 layer는 괜찮음
- 하지만 encoder–decoder attention의 마지막 layer는 예외
- 1개만 남기면 BLEU –13.5 이상 하락
📌 결론 2
Self-attention은 head 1개로도 충분한 경우가 많지만,
encoder–decoder attention은 genuinely multi-head가 필요하다.
6. 실험 3: 다른 데이터셋에서도 중요한 head는 같은가?
방법
- In-domain / Out-of-domain 데이터셋 비교
- WMT ↔ MTNT
- MNLI matched ↔ mismatched
결과 (Figure 2)
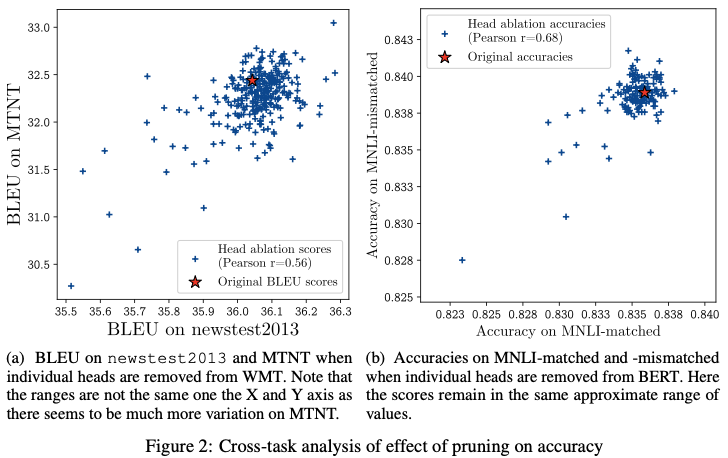
- head 중요도 상관계수:
- WMT: r ≈ 0.56
- BERT: r ≈ 0.68
📌 결론 3
중요한 head는 데이터셋이 바뀌어도 비교적 안정적이다.
7. 실험 4: 전체 모델에서 점진적 pruning
핵심 기법:
Head Importance Score
논문에서 제안한 head 중요도:
- : head on/off mask
- 의미: → 이 head를 제거했을 때 loss가 얼마나 민감하게 반응하는가
(Taylor pruning / Molchanov et al. 방식과 동일한 철학)
결과 (Figure 3)

- BERT
- head 40%까지 제거해도 성능 거의 유지
- WMT
- 약 20%까지 안전
- 그 이후에는 급격한 성능 붕괴
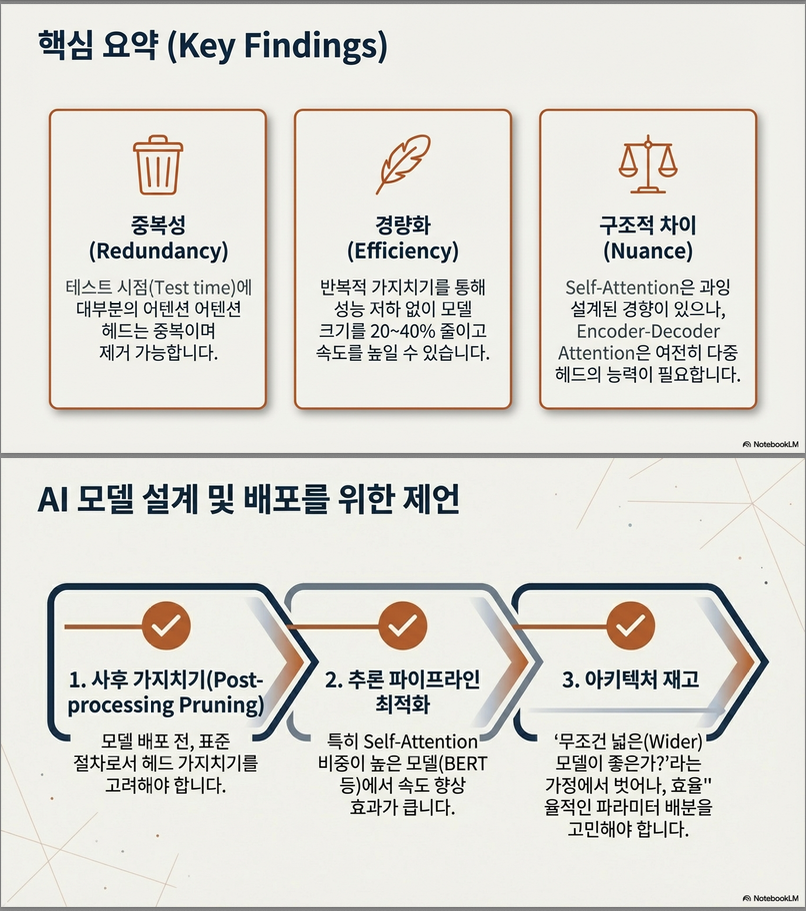
📌 결론 4
MHA는 “전부 redundant”는 아니지만,
상당 부분은 제거 가능하다.
8. 효율성 측면 (Efficiency)
결과 (Table 4)
- BERT에서 50% head 실제 삭제(pruning) 시
- inference speed:
- batch size 클수록 효과 큼
- 최대 +17.5% 속도 향상
📌 결론 5
Attention head pruning은 실제 시스템 관점에서도 의미가 있다.
9. 언제 multi-head가 정말 필요한가?
분석 (Figure 4)
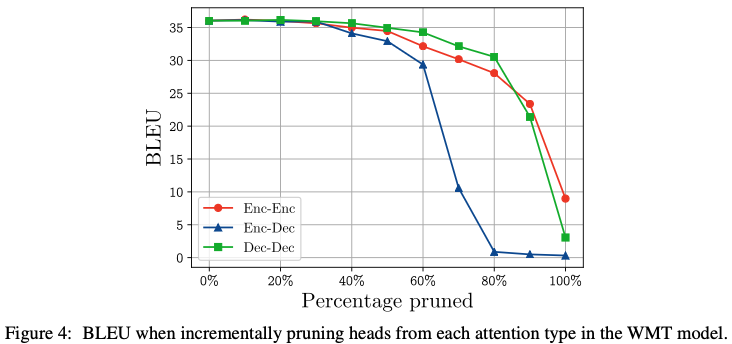
- Encoder–Decoder Attention
- pruning에 매우 취약
- Self-Attention (Encoder / Decoder)
- 훨씬 robust
📌 해석
cross-sequence alignment(번역)는 다양한 시각이 필요
→ multi-head의 본래 목적이 잘 드러나는 지점
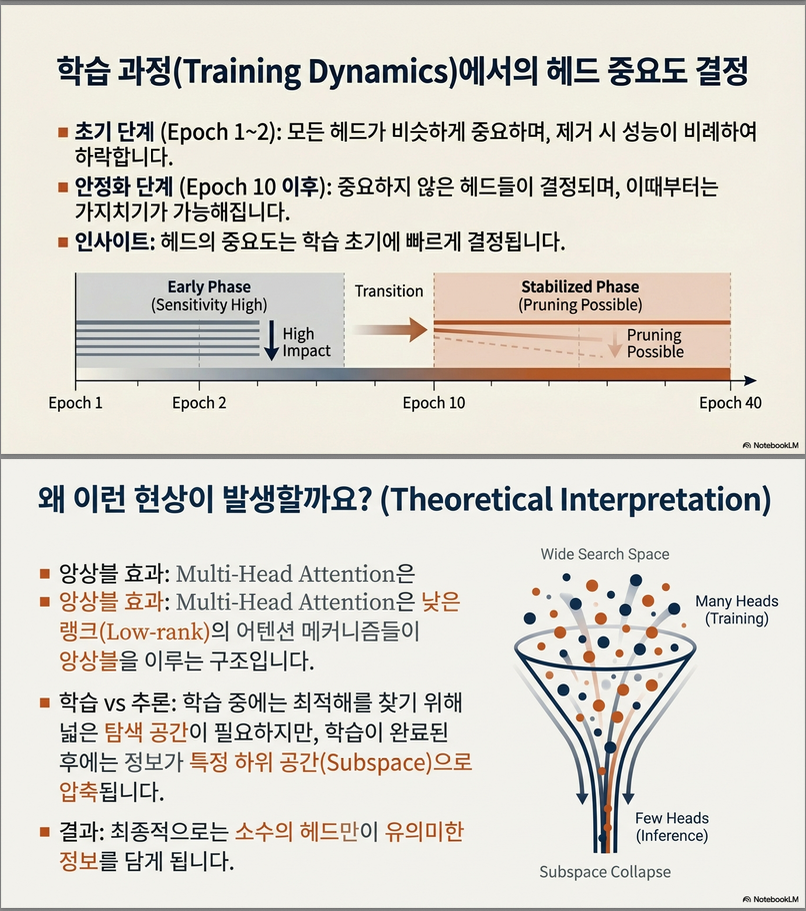
10. 학습 중 head 중요도 변화 (Training Dynamics)
실험 (Figure 5, IWSLT)
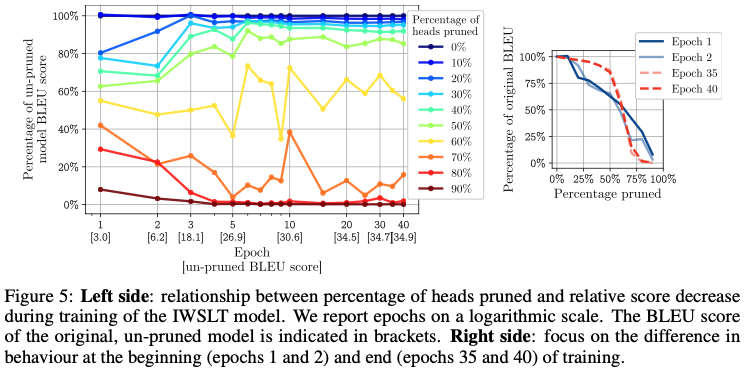
- 초기 epoch
- 모든 head가 거의 동일하게 중요
- 학습 후반
- 일부 head만 중요해짐
- 나머지는 pruning 가능
📌 핵심 통찰
Multi-head attention의 이점은
표현력 자체보다 “학습 과정의 안정성 / 탐색 공간 확장”에 있다.
11. 이 논문의 핵심 메시지 (한 줄 요약)
Multi-head attention은 학습에는 중요하지만,
학습이 끝난 뒤에는 대부분의 head가 필요 없다.
12. 이후 연구에 끼친 영향
이 논문은 이후 다음 흐름의 출발점이 됩니다.
- Voita et al. 2019: Specialized heads
- Head/Neuron pruning
- Sparse attention
- “왜 head가 필요한가?” → “언제, 어디서 필요한가?”
- 최근에는:
- Layer-wise / head-wise adaptive steering
- Circuit / SAE 기반 head 선택
- Inference-time intervention
아래에서는 논문의 Head Importance Score for Pruning(§4.1)을
정의 → 수식 유도 → 직관 → 기존 pruning 기법과의 관계 → 한계 순서로 정리합니다.
1. 왜 Head Importance Score가 필요한가?
앞선 실험(§3)에서는
- 한 번에 하나의 head만 제거하거나
- 한 layer 내부에서만 비교했습니다.
하지만 실제로는:
- 여러 layer의 여러 head를 동시에 제거해야 하고
- 모든 조합을 탐색하는 것은 조합 폭발로 불가능합니다.
👉 그래서 저자들은
**“이 head를 꺼버리면 loss가 얼마나 민감하게 반응할까?”**라는 기준으로
head를 정렬하고 greedy pruning을 수행합니다.
2. Head Importance Score 정의
각 attention head h에 대해, 마스크 변수 를 도입합니다.
여기서 head 중요도는 다음과 같이 정의됩니다:
- : loss
- : head on/off 스위치
- : 절댓값 (매우 중요!)
- 기대값은 **학습 데이터(또는 일부)**에 대해 계산
3. 수식 전개 (핵심 유도)
체인 룰을 적용하면:
따라서 최종 형태는:
4. 직관적 해석 (왜 이게 합리적인가?)
이 score는 다음 질문에 답합니다:
“이 head의 출력 방향으로 조금만 움직여도
loss가 크게 변하는가?”
- : → 이 head가 실제로 무엇을 출력하고 있는지
- : → loss가 어느 방향으로 민감한지
📌 둘의 내적(inner product):
- 크면 클수록 → 이 head는 loss에 직접적이고 강한 영향
📌 절댓값을 쓰는 이유
- 어떤 데이터에서는 positive, 어떤 데이터에서는 negative일 수 있음
- 평균을 그대로 쓰면 서로 상쇄(cancellation) 발생
- → “영향의 크기” 자체를 보고 싶기 때문에
5. 기존 Pruning 기법과의 관계
논문에서 명시적으로 밝히듯, 이 방식은:
Molchanov et al. (2017)의 Taylor-based pruning과 동일한 계열
즉,
- 1차 Taylor expansion:
- 여기서:
- 구조 단위 = attention head (structured pruning)
📌 차이점:
- weight-level pruning ❌
- head-level structured pruning ⭕
6. 실제 계산 방법 (Practical Details)
- Forward + Backward 1회면 충분
- 추가 학습 없음
- layer별로 score를 L2-normalization
- (layer마다 scale이 달라지는 문제 방지)
👉 즉, 훈련 비용과 거의 동일한 수준
7. 이 Score로 무엇을 했는가?
이 를 기준으로:
- 모든 head를 중요도 순으로 정렬
- 중요도 낮은 head부터
- 전체 모델에서 점진적으로 pruning
- 성능 곡선 관찰 (Figure 3)
결과:
- BERT: ~40%
- WMT: ~20% 까지 거의 성능 손실 없음
8. 중요한 한계 (이 논문이 솔직한 지점)
이 score는:
- ❌ head 간 상호작용(interaction) 고려 안 함
- ❌ pruning 후 재적응(retraining) 없음
- ❌ inference-time에서만 유효
즉,
*“이 head가 혼자 중요하냐”*는 잘 측정하지만
*“이 head가 다른 head와 함께 있을 때의 역할”*은 모름
→ 이후 연구들이:
- group pruning
- joint optimization
- learnable gates 로 확장됨
한 줄 요약
Head Importance Score는
“이 attention head를 끄면 loss가 얼마나 흔들리는가”를
1차 Taylor 근사로 측정한,
계산 효율적인 구조적 pruning 지표다.
논문 §4.1의 를 실제로 어떻게 계산하는지를 수식/코드로 “바로 구현 가능한 수준”으로 정리.
0) 목표: 논문 Head Importance Score를 “배치 평균”으로 계산
논문 정의는 (마스크 에 대한 loss 민감도)
MHA 출력이 형태이므로 체인룰로
따라서 최종 계산식:
여기서 는 head h의 출력 벡터(토큰별)이고, 내적은 head 출력 텐서와 그라디언트 텐서의 원소별 곱을 전부 합(sum) 하는 것과 같습니다.
1) 텐서 관점: 무엇을 “어디에 대해 합치나?”
일반적으로 한 레이어의 head 출력은 다음 중 하나 형태로 잡습니다.
(A) per-head 출력이 이미 분리되어 있는 경우
(배치 B, 시퀀스 길이 T, head dim )
그라디언트도 동일 shape:
그럼 한 배치에서 head h의 중요도 샘플은
그리고 데이터셋 평균으로:
(B) head들이 합쳐진 출력만 있는 경우
많은 구현은 head를 concat한 뒤 projection합니다.
이 경우 head slice로 자릅니다:
- head h의 구간: [h :(h+1)]
2) “실제 계산”의 핵심: forward에서 저장, backward에서 받기
PyTorch에서는 보통 두 가지 방식이 있습니다.
- 모듈에 hook 걸어서 (권장)
- 코드 수정해서 per-head 텐서를 반환받기
논문은 “forward+backward 한 번으로 된다”고 했고(훈련과 동일 수준 비용), 실제로는 hook 방식이 가장 깔끔합니다. 또한 논문은 절댓값이 상쇄를 막는 데 중요하다고 강조합니다.
답글 남기기