


xRAG 논문 핵심 아이디어
이 논문의 핵심은 다음 한 문장으로 요약할 수 있습니다.
검색된 문서를 텍스트로 LLM에 넣지 말고, retrieval embedding 하나만 “문서 토큰 1개”처럼 넣자.
즉, 기존 RAG는:
[질문] + [검색 문서 전체 텍스트]를 입력으로 사용했지만, xRAG는:
[질문] + [문서 embedding을 projector로 변환한 token 1개]만 사용합니다.
문제의식
기존 RAG의 가장 큰 문제는:
- retrieval document가 길다
- inference FLOPs 증가
- context window 초과 가능
- latency 증가
라는 점입니다.
예를 들어:
질문: 10 tokens
문서: 170~200 tokens이면 대부분의 계산량이 retrieval context 처리에 사용됩니다.
기존 Context Compression의 한계
논문은 기존 압축 방법을 크게 두 가지로 분류합니다.
1. Soft Prompt 계열
예:
- Gist
- AutoCompressor
- ICAE
방법:
- 문서를 latent memory slot으로 압축
문제:
- token마다 hidden state 저장 필요
- RAG의 수백만 문서에 적용하기 어려움
2. Hard Prompt 계열
예:
- LLMLingua
- RECOMP
방법:
- 중요 token만 남김
문제:
- compression ratio 한계
- 여전히 text token 처리 필요
xRAG의 핵심 관찰
논문이 매우 중요한 관찰을 합니다.
Dense retriever embedding은 이미 문서 의미를 상당 부분 담고 있다.
즉:
document -> sentence embedding은 retrieval 용도로만 쓰고 있었지만,
실제로는 semantic information이 매우 풍부하다는 것입니다.
논문은 이를:
retrieval modality라고 재정의합니다.
즉 embedding 자체를 하나의 modality feature처럼 취급합니다.
이는 vision-language 모델에서:
image encoder output -> LLM하는 방식과 유사합니다.
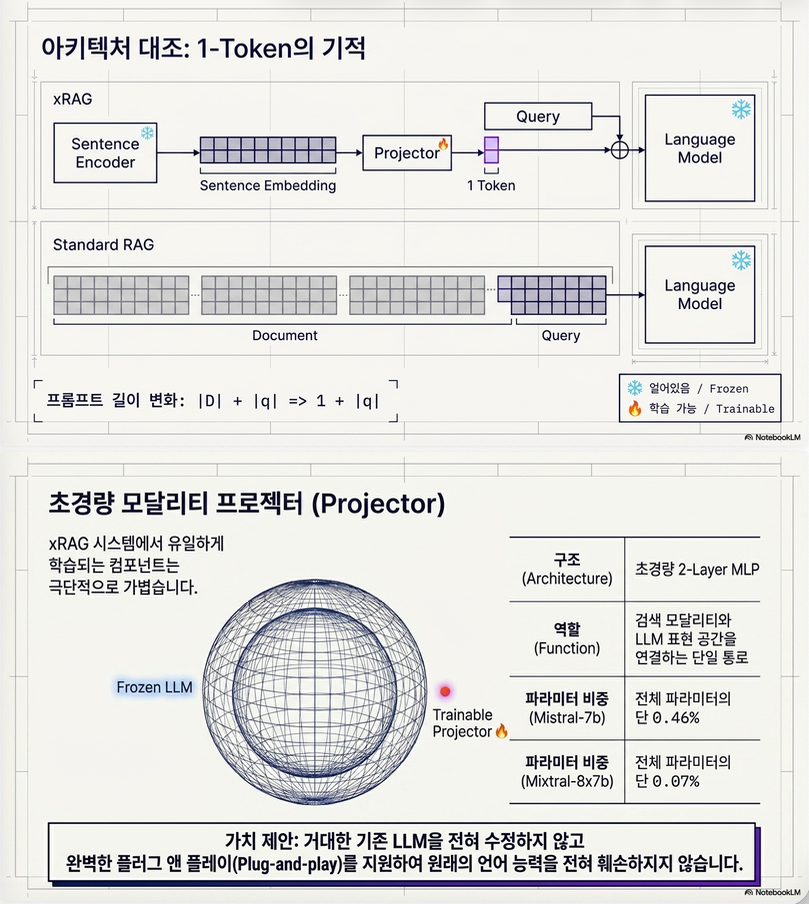
xRAG Architecture
논문의 핵심 구조는 다음과 같습니다.
기존 RAG
Document Text
↓
Tokenizer
↓
LLM input tokensxRAG
Document
↓
Sentence Encoder
↓
Dense Embedding E
↓
Projector W
↓
LLM hidden space token즉:
W(E) ⊕ Emb(q)를 입력으로 사용합니다.
여기서:
E: retriever embeddingW: modality projector (2-layer MLP)q: query
입니다.
Compression Ratio
논문에서 매우 인상적인 부분입니다.
기존:
평균 document length ≈ 175 tokensxRAG:
1 token즉:
175:1 compression입니다.
Appendix에서는:
x178 compression이라고 표현합니다.
가장 중요한 부분: 어떻게 LLM이 embedding을 이해하게 만드는가?
이게 논문의 핵심 난제입니다.
LLM은 원래 text token만 이해합니다.
그런데 xRAG는 dense embedding 하나를 넣습니다.
따라서:
retrieval embedding ↔ LLM representationalignment가 필요합니다.
이를 위해 논문은 2-stage training을 사용합니다.
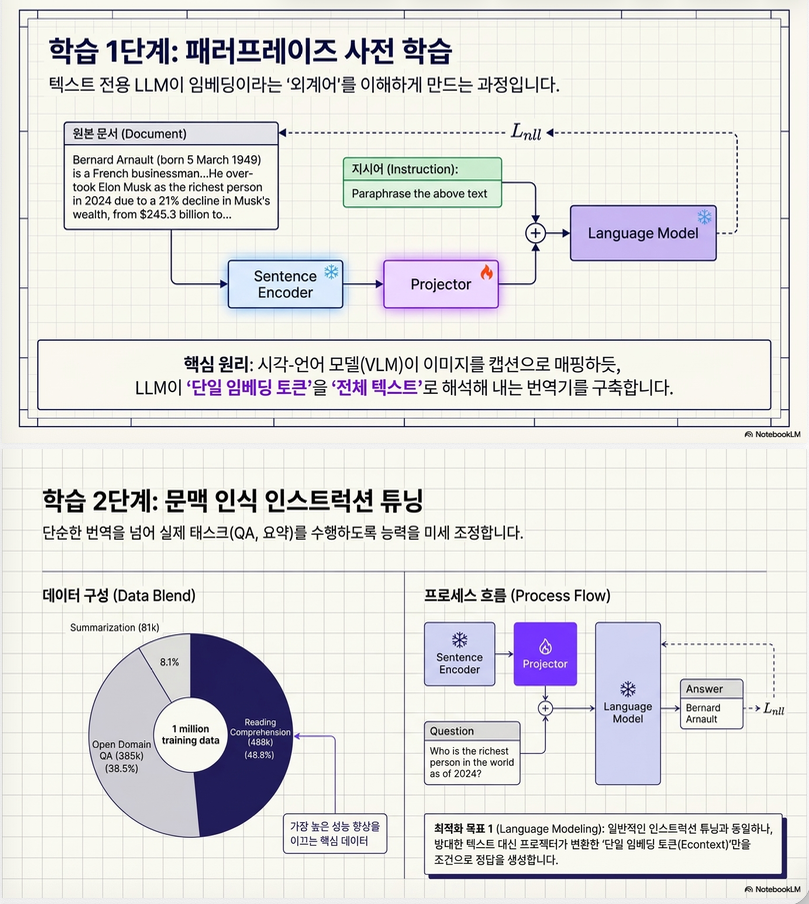
Stage 1: Paraphrase Pretraining
핵심 아이디어:
embedding이 문서를 복원하도록 학습예시:
[X] The above text could be paraphrased as: [D]여기서:
[X]: projected embedding[D]: 원래 문서
입니다.
즉:
embedding -> document reconstruction을 수행합니다.
loss는 standard next-token LM loss:
입니다.
직관
이 단계의 의미:
LLM이 embedding을 읽는 법 학습입니다.
vision-language model에서:
image embedding -> caption generation과 매우 유사합니다.
Stage 2: Context-aware Instruction Tuning
이제 embedding을 downstream QA에 활용하도록 학습합니다.
입력:
W(Econtext) + Question출력:
Answerloss:
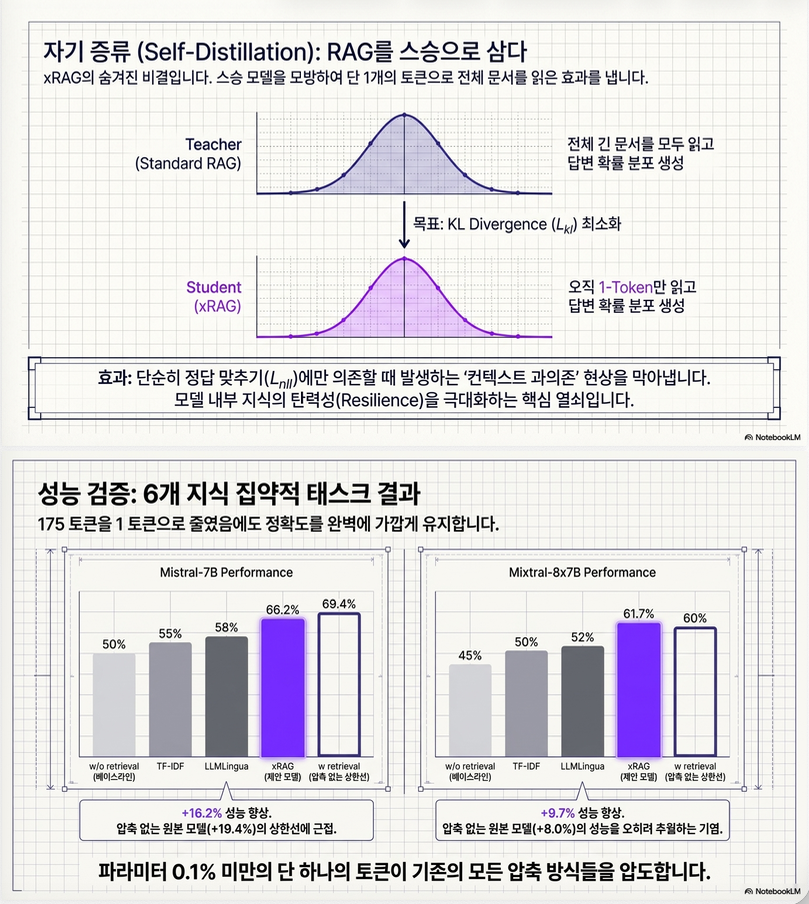
Self-Distillation (매우 중요)
논문에서 상당히 중요한 요소입니다.
Teacher:
full RAGStudent:
xRAG입니다.
즉:
RAG output distribution
≈
xRAG output distribution이 되도록 KL divergence를 최소화합니다.
최종 loss:
왜 Self-Distillation이 중요한가?
논문의 매우 중요한 insight입니다.
일반 RAG는 noisy retrieval에 취약합니다.
즉 잘못된 문서가 들어오면:
LLM이 문서를 과신합니다.
반면 xRAG는:
embedding 수준의 compressed semantic signal만 받기 때문에:
- internal parametric knowledge 유지
- noisy document에 덜 overfit
하는 경향이 있습니다.
실험 결과
주요 결과
xRAG는:
- 평균 10% 이상 성능 향상
- 1 token compression
- 기존 compression 방법 압도
를 보여줍니다.
성능 비교
Mistral-7B
| Method | Avg |
|---|---|
| No Retrieval | 36.54 |
| RAG | 43.63 |
| xRAG | 42.46 |
즉:
거의 full RAG 수준 유지합니다.
Mixtral-8x7B
흥미롭게도:
| Method | Avg |
|---|---|
| RAG | 46.22 |
| xRAG | 46.91 |
즉:
xRAG > full RAG입니다.
논문은 이유를:
retrieval noise robustness로 설명합니다.
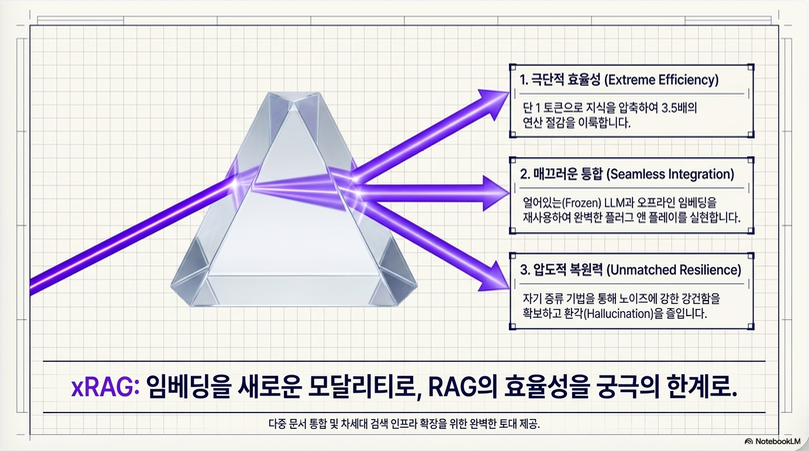
계산량 감소
매우 중요한 결과:
| Metric | Improvement |
|---|---|
| CUDA Time | 1.64x faster |
| FLOPs | 3.53x reduction |
즉:
retrieval token processing cost 제거 효과가 큽니다.왜 reasoning task에서는 약한가?
논문에서 솔직하게 인정하는 부분입니다.
xRAG는:
- TriviaQA 같은 factual QA는 매우 잘함
- HotpotQA 같은 reasoning task는 상대적으로 약함
이유는:
single dense embedding이:
- entity relation
- multi-hop structure
- compositional reasoning
을 충분히 표현하기 어렵기 때문입니다.
즉:
semantic compression ≠ reasoning preservation입니다.
이 논문의 가장 중요한 학술적 의미
이 논문의 진짜 contribution은 단순 compression이 아닙니다.
핵심은:
Retrieval embedding 자체를 “LLM 입력 modality”로 재해석했다.
는 점입니다.
즉:
retriever embedding
=
compressed retrieval modality라는 새로운 관점을 제시합니다.
이는 이후:
- embedding-native RAG
- latent retrieval
- token-free retrieval augmentation
- multi-vector latent reasoning
계열 연구로 이어질 가능성이 큽니다.
논문의 한계
논문 한계도 명확합니다.
1. reasoning 약함
특히:
- multi-hop
- compositional QA
성능 저하.
2. document reconstruction 불완전
embedding 하나로는:
- exact wording
- fine-grained detail
보존 어려움.
3. top-1 retrieval만 사용
multiple document fusion은 미지원.
4. retriever quality heavily dependent
embedding quality가 매우 중요합니다.
xRAG 방법론 상세 설명
xRAG의 핵심 목표는 다음입니다.
retrieval document 전체를 text token으로 넣지 않고,
retriever embedding 하나만으로 문서 정보를 LLM에 전달하자.
즉 기존 RAG:
[Question] + [Retrieved Document Tokens]를
[Question] + [Document Embedding Token]으로 대체합니다.
전체 구조
논문의 전체 파이프라인은 다음과 같습니다.
Document
↓
Sentence Encoder
↓
Dense Embedding E
↓
Projector W
↓
LLM hidden representation token
↓
LLM generation핵심은:
retrieval embedding → LLM token spacealignment입니다.
1. Retrieval Formulation
논문은 retrieval corpus를 다음처럼 정의합니다.
여기서:
- : document text
- : sentence embedding
입니다.
sentence embedding은:
로 계산합니다.
즉:
Sentence Encoder가 retrieval encoder 역할을 합니다.
논문에서는:
- SFR embedding model 사용
- Wikipedia 37M passages 사용
합니다.
2. 기존 RAG vs xRAG
기존 RAG
입력:
즉:
document tokens + query tokens를 embedding layer에 넣습니다.
문제:
- sequence length 증가
- quadratic attention cost 증가
xRAG
xRAG는 문서를 token화하지 않습니다.
대신:
를 사용합니다.
여기서:
- E: retrieval embedding
- W: projector
- Emb(q): query token embeddings
입니다.
즉:
document token sequence
→
single dense vector token으로 압축합니다.
핵심 아이디어: Retrieval Embedding을 “Modality”로 본다
이 논문의 가장 중요한 conceptual contribution입니다.
기존 dense retrieval에서는:
embedding = retrieval index feature였습니다.
하지만 xRAG는:
embedding = semantic modality representation라고 봅니다.
즉 vision-language model에서:
image embedding → projector → LLM하듯이,
xRAG는:
retrieval embedding → projector → LLM을 수행합니다.
3. Projector W
xRAG에서 유일하게 학습되는 모듈입니다.
논문은:
2-layer MLP를 사용합니다.
즉:
W(E) = MLP(E)
입니다.
왜 projector가 필요한가?
retrieval embedding space와
LLM embedding space는 완전히 다릅니다.
즉:
retriever latent space
≠
LLM token embedding space입니다.
따라서 projector가:
semantic alignment bridge역할을 합니다.
매우 중요한 설계 철학
논문은:
- retriever frozen
- LLM frozen
- projector만 train
합니다.
이유:
1. Plug-and-play 유지
RAG는 원래:
- retrieval system 교체 가능
- datastore 재사용 가능
해야 합니다.
2. Offline embedding 재사용
이미 구축된 vector DB 사용 가능.
3. catastrophic forgetting 방지
LLM full finetuning을 하지 않음.
4. Two-Stage Training
논문의 핵심입니다.
Stage 1: Paraphrase Pretraining
목적
LLM이 retrieval embedding을 이해하게 만드는 단계.
즉:
embedding ↔ text semantic alignment학습.
입력 형태
논문 예시:
[X] The above text could be paraphrased as: [D]여기서:
- [X]: projected embedding
- [D]: 원문 document
입니다.
실제 의미
모델은:
embedding 하나를 보고
원문 document를 복원해야 합니다.
즉 latent inversion에 가깝습니다.
학습 objective
즉 autoregressive LM loss입니다.
직관
이 단계는 사실상:
retrieval embedding captioning입니다.
vision-language alignment와 매우 유사합니다.
왜 “paraphrase”인가?
논문이 reconstruction이 아니라 paraphrase를 사용하는 이유는:
embedding은 exact wording보다 semantic meaning 보존하기 때문입니다.
즉:
semantic equivalence learning을 목표로 합니다.
5. Stage 2: Context-aware Instruction Tuning
Stage 1만으로는 downstream QA를 못합니다.
따라서:
embedding-conditioned QA를 instruction tuning합니다.
데이터 구성
논문은 약 1M 데이터 사용:
- Reading comprehension
- QA
- Summarization
입력
출력
LM loss
핵심 의미
이 단계는:
compressed retrieval feature를
실제 reasoning/QA에 사용하는 법을 학습합니다.
6. Self-Distillation (매우 중요)
논문에서 사실상 핵심 contribution 중 하나입니다.
문제
compressed embedding만 사용하면:
retrieval information loss가 발생합니다.
특히:
- noisy retrieval
- ambiguous retrieval
에서 문제 발생.
해결
Teacher:
full RAGStudent:
xRAGObjective
xRAG output distribution이
RAG distribution을 mimic하도록 학습.
최종 loss:
왜 Self-Distillation이 중요한가?
논문 분석 결과:
- self-distillation 제거 시 성능 급락
- resilience rate 감소
합니다.
핵심 효과
RAG teacher는:
full document semantics를 제공합니다.
xRAG student는:
compressed embedding representation만 봅니다.
따라서 self-distillation은:
compressed latent representation에
RAG behavior를 주입하는 역할입니다.
7. 왜 xRAG가 Robust한가?
논문의 흥미로운 분석입니다.
일반 RAG는:
retrieved text를 과신합니다.
즉 잘못된 문서가 오면 hallucination 증가.
xRAG는 왜 강한가?
xRAG는:
compressed semantic signal만 사용하므로:
- noisy detail 제거
- internal LM knowledge 유지
효과가 있습니다.
Resilience Rate
논문은 새로운 metric 제안:
Resilience Rate
retrieval 이후에도:
- 원래 맞던 문제 계속 맞는 비율
Boost Rate
retrieval 때문에:
- 틀리던 문제를 맞게 된 비율
xRAG는:
- 높은 resilience
- 적당한 boost
특성을 보입니다.
8. 계산 복잡도 감소 원리
기존 transformer attention:
O(n^2)
문서 길이 L 증가 시 매우 비쌉니다.
기존 RAG
n = |q| + |D|
xRAG
n = |q| + 1
즉 retrieval cost 거의 제거.
결과
논문 결과:
| Metric | Improvement |
|---|---|
| CUDA Time | 1.64x |
| FLOPs | 3.53x |
9. xRAG의 본질
이 논문은 단순 compression 논문이 아닙니다.
실제로는:
retrieval embedding을
LLM-native latent token으로 변환하는 논문입니다.
즉:
Text Retrieval
→
Latent Retrieval패러다임 전환에 가깝습니다.
이 논문의 중요한 한계
1. Single-vector bottleneck
embedding 하나에:
- reasoning chain
- compositional relation
압축 어려움.
2. Multi-hop 약함
HotpotQA 성능 저하.
3. Fine-grained detail 손실
exact wording 보존 어려움.
연구적으로 매우 중요한 확장 방향
논문 마지막에서도 언급합니다.
1. Multi-vector xRAG
1 embedding
→
k embeddings2. Retrieval-space reasoning
embedding 위에서 reasoning.
3. Embedding-native RAG
token을 거치지 않는 retrieval augmentation.
답글 남기기