


이 논문은 activation patching(= causal tracing/interchange intervention)의 실험 설정(hyperparameter) 이 interpretability 결과를 얼마나 크게 바꾸는지를 체계적으로 분석한 논문입니다.
핵심 메시지는 다음과 같습니다.
“Activation patching 자체보다도,
어떤 corruption method를 쓰고 어떤 metric으로 측정하느냐가
localization/circuit discovery 결과를 크게 바꾼다.”
즉, 기존 mechanistic interpretability 논문들의 결과가 설정에 민감할 수 있으며, activation patching에도 “best practice”가 필요하다는 주장입니다.
1. Activation Patching이란?
논문은 activation patching을 다음처럼 정의합니다.
기본 아이디어:
- clean prompt:
"The Eiffel Tower is in"
- corrupted prompt:
"The Colosseum is in"
그리고 3번의 forward pass 수행:
- Clean run
- clean prompt 실행
- 특정 activation 저장(cache)
- Corrupted run
- corrupted prompt 실행
- Patched run
- corrupted prompt 실행 중
- 특정 activation만 clean activation으로 교체
만약 patch 후 다시 "Paris"를 출력한다면:
해당 activation/component가
factual recall에 causal하게 중요하다는 의미
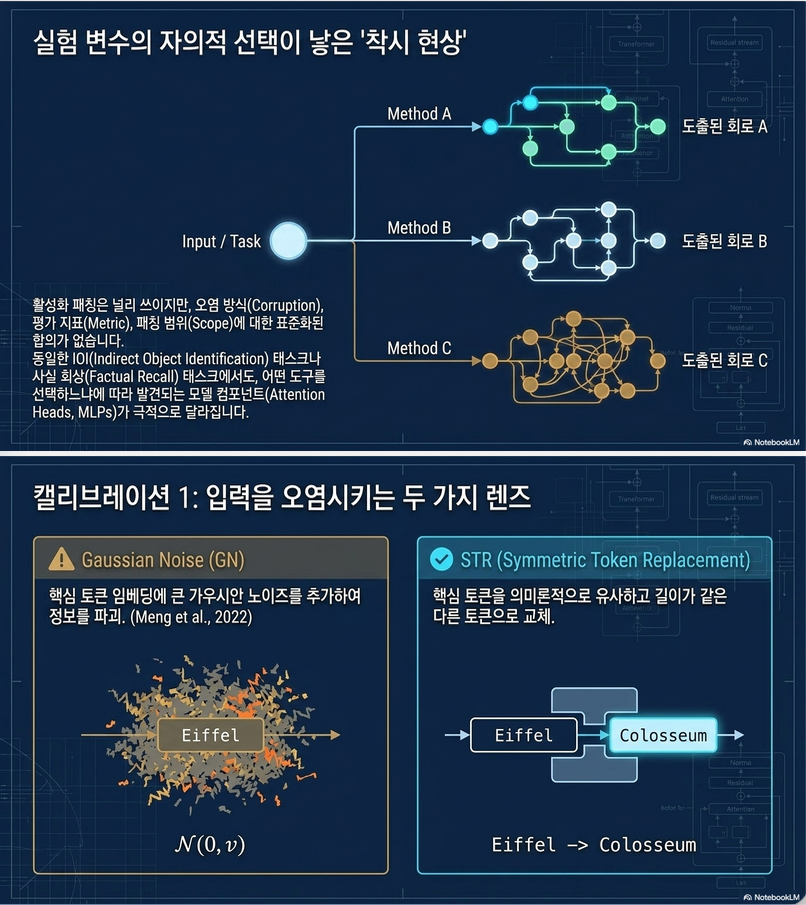
2. 논문의 핵심 문제의식
기존 activation patching 논문들은:
- corruption 방법이 다름
- metric이 다름
- sliding window patching 방식도 다름
그런데:
이런 설정 차이가 interpretability 결과를 바꾸는가?
를 체계적으로 조사한 논문이 없었다는 점이 핵심입니다.
3. 논문이 분석한 3가지 핵심 요소
논문은 activation patching의 자유도를 3개로 정리합니다.
(1) Corruption Method
A. Gaussian Noise (GN)
Meng et al. 2022 스타일
중요 token embedding에 Gaussian noise 추가:
예:
- subject token embedding perturbation
B. Symmetric Token Replacement (STR)
Wang et al. 2023 스타일
token 자체를 semantic replacement:
- Eiffel Tower → Colosseum
- Paris → Rome
핵심:
STR은 여전히 in-distribution prompt
이라는 점입니다.
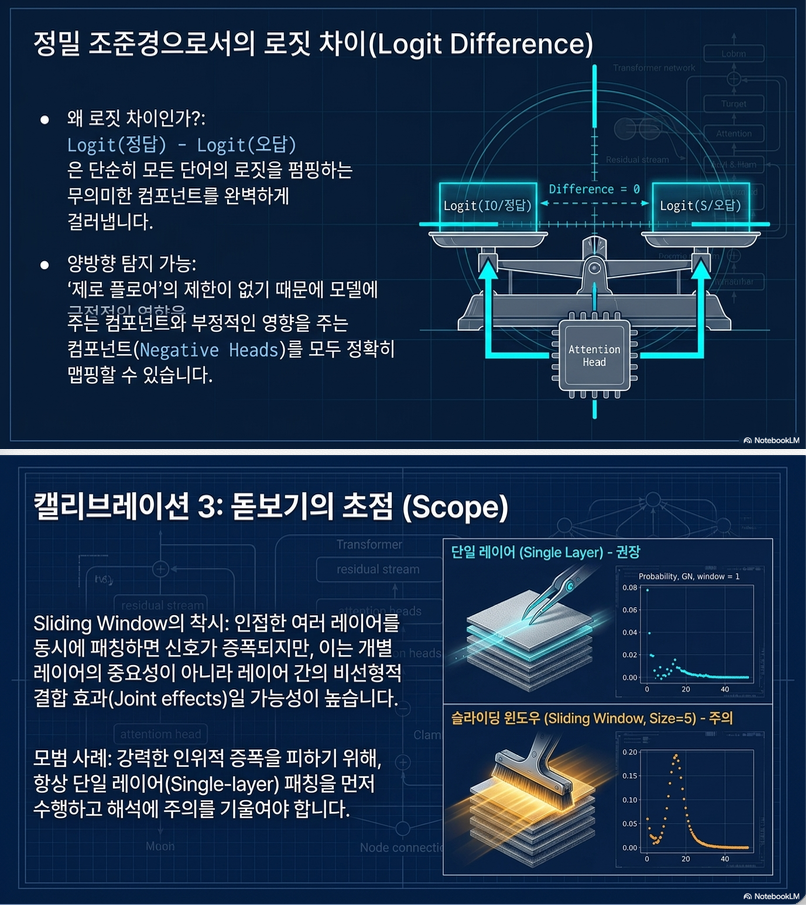
(2) Evaluation Metric
논문은 3가지 metric 비교:
A. Probability
정답 token probability:
P(r)
patch effect:
B. Logit Difference
가장 중요하게 추천하는 metric.
예:
- Paris vs Rome
patch effect:
C. KL Divergence
clean distribution과의 KL:
(3) Sliding Window Patching
Meng et al. 방식:
- layer 하나가 아니라
- 여러 adjacent layer를 동시에 patch
예:
- layer 14~18 같이 patch
4. 가장 중요한 결과 ①:
Corruption Method가 결과를 크게 바꿈
논문의 가장 강한 주장입니다.
실험: factual recall localization
질문:
factual information은 어느 MLP layer에서 처리되는가?
Meng et al. 2022:
- middle layer에 sharp peak 존재 주장
하지만 이 논문이 STR로 다시 실험하니:
- peak가 훨씬 약해짐
- localization 결과가 달라짐
Figure 2 결과가 핵심입니다.
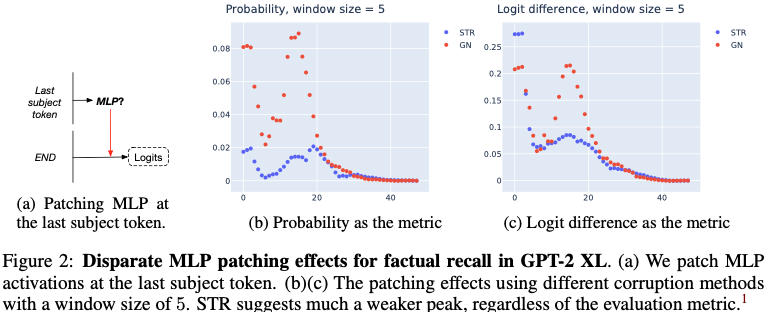
논문 표현:
- GN peak가 STR보다 2~5배 큼
즉:
“middle layer factual localization”
자체가 corruption method 의존적일 수 있음
5. 왜 GN이 문제인가?
(OOD behavior 문제)
논문의 핵심 conceptual contribution입니다.
저자들은 주장합니다:
Gaussian noise corruption은
모델을 out-of-distribution 상태로 보낸다.
핵심 직관
Embedding에 큰 noise를 넣으면:
이는 실제 학습 중 본 적 없는 representation.
즉:
- attention pattern 붕괴
- circuit behavior 붕괴
- internal mechanism distortion
가능.
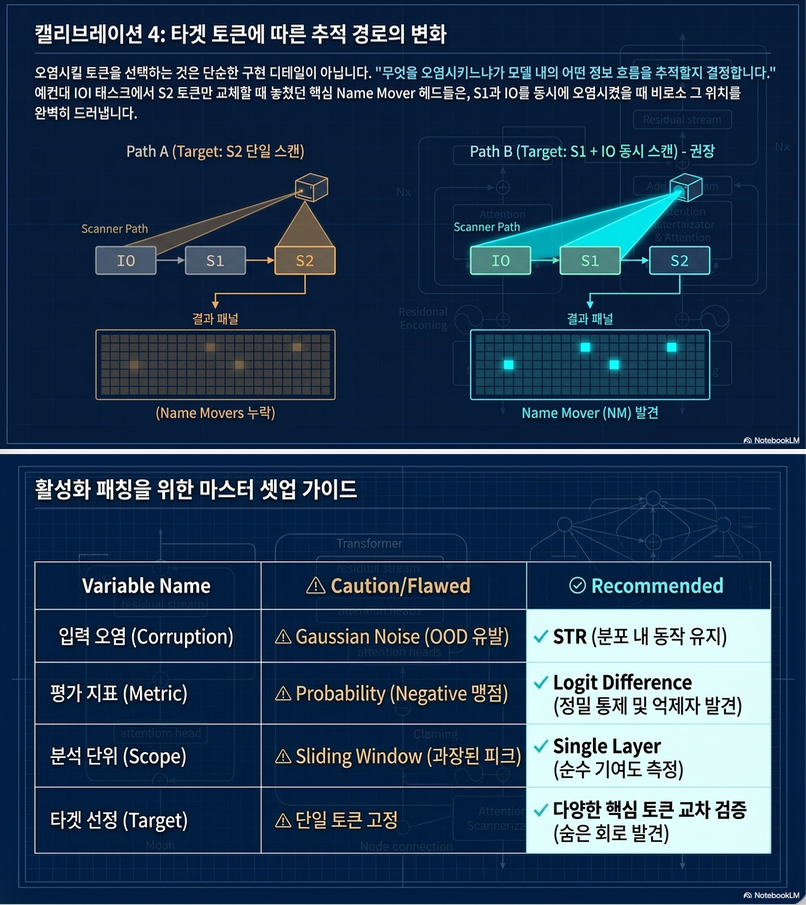
IOI circuit 실험
논문은 IOI(Indirect Object Identification) circuit으로 분석.
예:
John gave a book to Mary마지막 token prediction:
- Mary
Name Mover Head 분석
원래 clean prompt에서는:
- Name Mover head가 IO에 강하게 attention
하지만 GN corruption에서는:
- attention이 분산됨
- circuit behavior 붕괴
Figure 3이 핵심입니다.
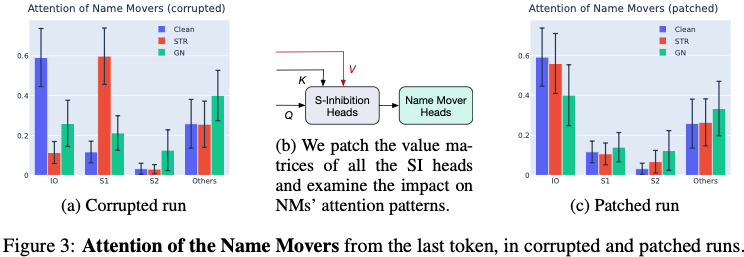
즉:
GN은 단순히 정보 제거가 아니라
모델 mechanism 자체를 망가뜨릴 수 있음
6. 가장 중요한 결과 ②:
Probability metric의 문제
논문은 probability metric도 비판합니다.
Negative head detection 실패
IOI circuit에는:
- 성능을 방해하는 negative head 존재
하지만 probability metric은 이를 놓칠 수 있음.
이유:
corrupted run에서:
이면:
최소값 자체가 작음.
즉 negative effect가 saturation됨.
Logit Difference의 장점
논문은 logit difference를 강하게 추천합니다.
이유:
- positive/negative component 모두 탐지 가능
- 특정 token pair 비교 가능
- irrelevant global effect 제거 가능
예:
를 사용하면:
- 모든 이름 token을 boost하는 head는 제거 가능
- IO-specific effect만 측정 가능
이 부분은 circuit analysis 관점에서 매우 중요합니다.
7. Sliding Window Patching의 문제
논문은 sliding window patching도 비판적으로 분석합니다.
결과:
- single-layer patching보다
- 훨씬 sharper localization 생성
Figure 5 핵심.

왜 문제가 되는가?
여러 layer를 동시에 patch하면:
- corrupted signal suppression
- nonlinear interaction
- cooperative computation
이 발생 가능.
즉:
실제로는 weak distributed computation인데
sharp localization처럼 보일 수 있음
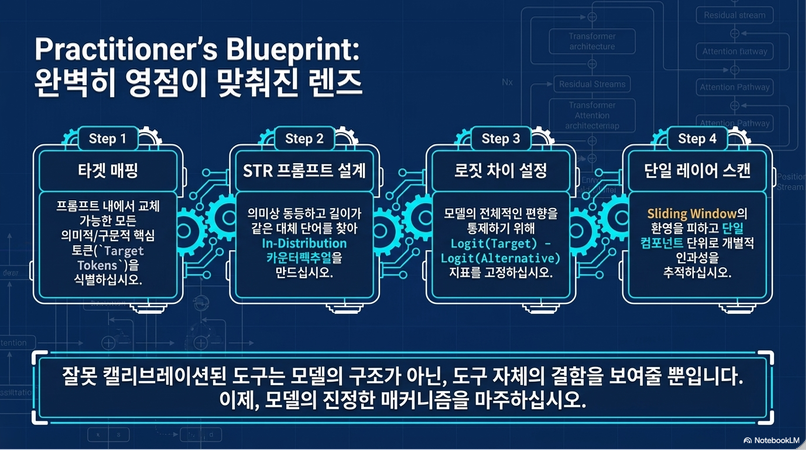
8. 논문의 최종 권장사항 (Best Practice)
논문의 핵심 결론입니다.
(1) STR 추천
논문은 STR를 권장.
이유:
- in-distribution prompt 유지
- internal mechanism preservation
- OOD artifact 감소
반면 GN은:
- OOD behavior 유발 가능
(2) Logit Difference 추천
이유:
- negative component 탐지 가능
- 더 fine-grained
- circuit-specific metric 구성 가능
(3) Single-layer patching 먼저 수행
Sliding window는:
- 과장된 localization 가능성 존재
따라서:
먼저 single-layer patching 수행 후
필요 시 window patching 사용 권장
9. 논문의 의의
이 논문은 단순 empirical paper가 아니라:
“activation patching methodology 자체의 validity”
를 문제 삼은 논문입니다.
특히 mechanistic interpretability 분야에서 중요한 메시지:
- localization 결과는 fragile할 수 있음
- corruption method가 causal conclusion 자체를 바꿀 수 있음
- interpretability도 evaluation methodology가 중요함
10. 논문의 한계
논문도 인정한 한계:
- mostly GPT-2/GPT-J 규모
- decoder-only LM 중심
- activation patching 자체의 근본 causal validity는 미해결
- STR도 semantic mismatch 가능
또한:
STR 역시 “minimal intervention”이 아닐 수 있음
이라는 후속 비판도 가능합니다.
12. 핵심 Takeaway
이 논문의 핵심을 한 문장으로 요약하면:
Activation patching 결과는
“모델 내부 메커니즘”뿐 아니라
“patching methodology”에도 크게 의존한다.
특히:
- GN corruption → OOD artifact 가능
- probability metric → negative circuit miss 가능
- sliding window → exaggerated localization 가능
이라는 점이 핵심 공헌입니다.
답글 남기기