




1. 핵심 문제의식 (Problem Setting)
기존 Activation Steering의 한계
- LLM 제어 방법:
- Prompt engineering
- Fine-tuning
- Activation steering (vector injection) ← 최근 핵심
- 하지만 주요 문제:
- coherency degradation (문장 붕괴) 발생
- 특히 out-of-distribution 방향으로 steering 시 급격히 붕괴
중요한 관찰
- Coherency 붕괴는:
- Perplexity, MMLU 등으로 잘 감지되지 않음
- 즉, “모델은 겉보기 성능은 유지하지만 실제 생성 품질은 붕괴”
2. 핵심 아이디어 (Core Insight)
문제의 원인
기존 방식:
- residual stream에 steering vector 추가
문제:
- residual stream = 모든 정보가 aggregation된 공간
- knowledge
- syntax
- persona
- reasoning
- → steering 시 off-target noise까지 증폭됨
제안: “Where to steer”
기존 연구:
- how to steer (CAA, ActAdd)
- when to steer (dynamic steering)
이 논문:
“어디에 steering 해야 하는가?”
3. 핵심 발견: Style Modulation Heads
발견 내용
- 특정 attention layer에서
- **극소수의 head (단 3개)**가
- persona/style을 담당
→ 이를
Style Modulation Heads (SMH)라고 정의
특징
| 속성 | 설명 |
|---|---|
| sparsity | 매우 적은 head만 사용 |
| generality | 다양한 persona 공통적으로 관여 |
| disentanglement | factual/knowledge와 분리됨 |
| function | style / persona modulation |
예시 (논문 결과)
- Qwen2.5:
- layer 20
- heads 3, 5, 28
- Llama3:
- layer 14
- heads 24, 30, 32
4. 방법론 (Methodology)
4.1 Steering Vector (기본 구조)
difference-in-means 방식:
- T: target prompt
- N: neutral prompt
4.2 기존 방식
문제: residual stream에 적용
4.3 제안 방식
Head-level intervention
단, 선별된 head만 적용 (SMH)
4.4 Head Contribution Score
각 head의 중요도:
- 방향 + 크기 모두 반영
- 높은 score → persona 생성 핵심 head
5. 주요 실험 결과
5.1 Coherency 붕괴 분석
핵심 결과
- positive steering → 빠른 붕괴
- negative steering → 상대적으로 안정
–> 비대칭성 존재
5.2 기존 metric의 한계
| Metric | 결과 |
|---|---|
| MMLU | 거의 변화 없음 |
| PPL | coherency와 불일치 |
| IFEval | 초기 붕괴 감지 실패 |
–> coherency는 독립적인 metric 필요
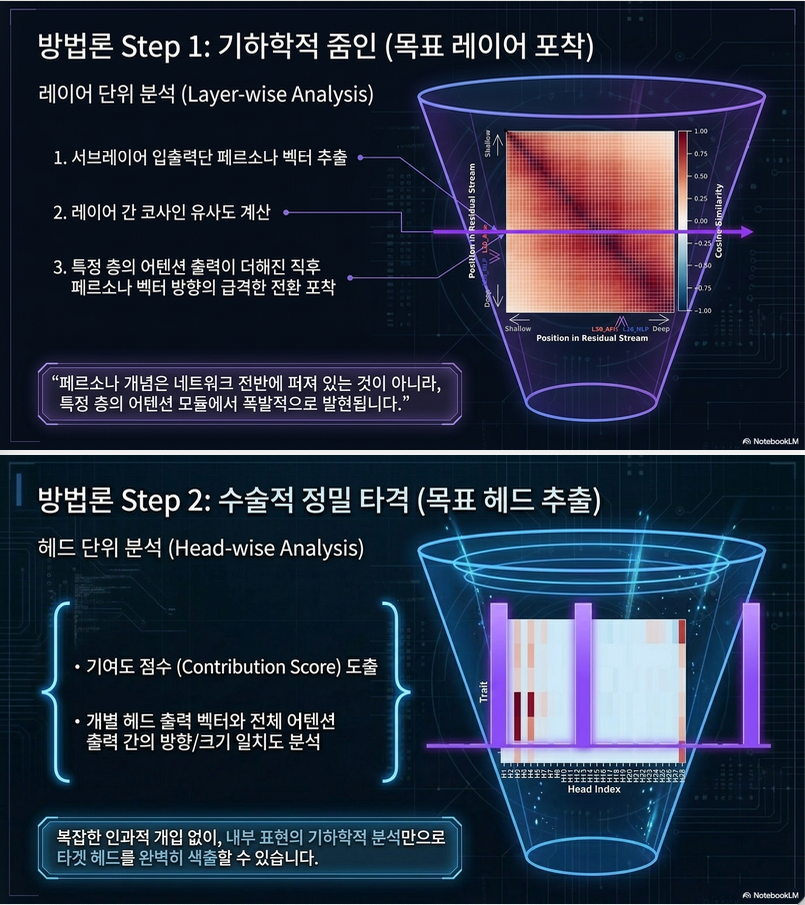
5.3 Layer-wise 분석
- 특정 layer에서 persona direction이 “형성”
- 이후 layer에서는 유지
–> persona는 late-layer attention에서 생성
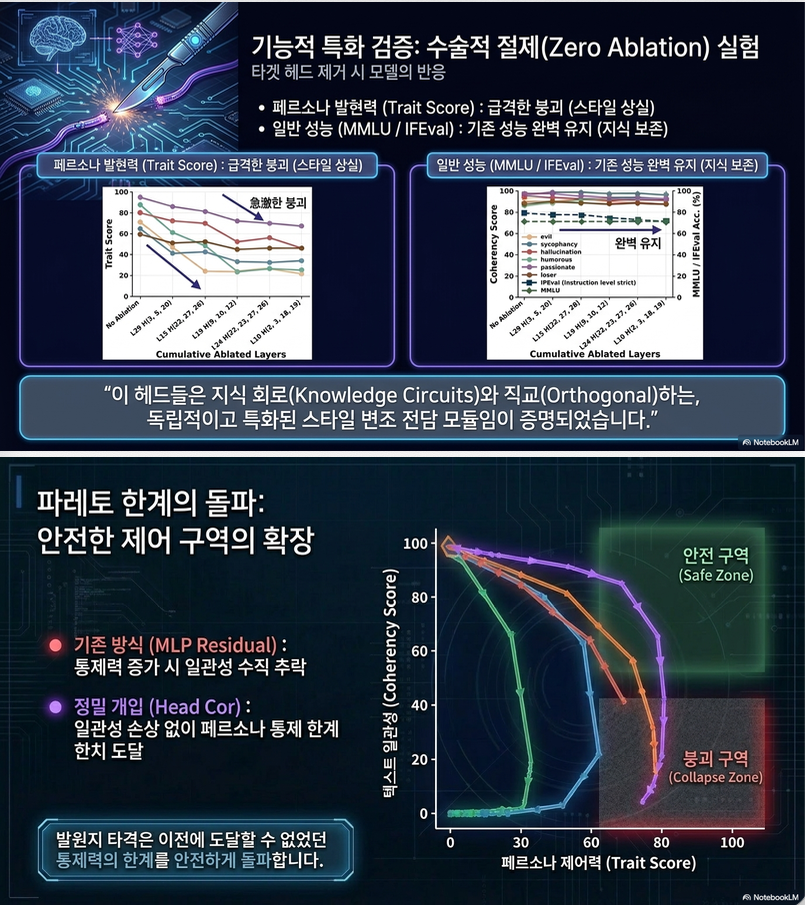
5.4 Head-level 분석
- 극소수 head만 high contribution
- 해당 head만 steering해도 효과 유지
5.5 Ablation 결과
- SMH 제거 → persona 급격히 감소
- 하지만:
- MMLU
- coherency
–> 거의 영향 없음
→ functional modularity 증명
6. 핵심 성능 비교 (가장 중요)
Steering 위치 비교
| 방법 | 성능 |
|---|---|
| MLP residual | 최악 |
| Attn residual | △ |
| Attn output | △ |
| Head Cor (SMH) | 최고 |
Pareto 관점
- x축: coherency
- y축: trait score
–> SMH가 Pareto frontier 최상단
정량 결과
- Qwen:
- 12개 중 11개 최고
- Llama:
- 12개 중 9개 최고
7. 핵심 기여 (Technical Contributions)
① 새로운 관점
- how / when → where to steer
② 구조적 발견
- persona = 특정 attention head에 국한됨
③ 방법론
- head-level selective steering
④ 효과
- coherency collapse 대폭 감소
- trait control 유지
8. 해석 (Mechanistic Insight)
이 논문의 가장 중요한 메시지:
Residual stream = entangled space
- 모든 정보 혼합
- steering → noise amplification
Attention head = functional module
- 특정 기능 담당
- disentangled
결론:
“LLM 제어는 global이 아니라 local하게 해야 한다”
9. 한계 및 확장 가능성
한계
- persona 중심 분석
- reasoning / safety circuit은 더 복잡
10. 한 줄 요약
Persona control은 residual stream이 아니라, 극소수 attention head에서 발생하며, 이 head만 조작하면 coherency 붕괴 없이 정밀 제어가 가능하다.
논문의 **방법론(Methodology)**을 핵심 수식 + 절차 중심으로 정리하면 다음과 같습니다.
1. 전체 프레임워크 개요
방법론은 크게 3단계로 구성됩니다:
Pipeline
- Steering vector 추출 (difference-in-means)
- Persona 생성 위치 localization (layer → head)
- Style Modulation Head에만 selective intervention
2. Steering Vector 추출
2.1 Difference-in-Means
특정 persona 방향 벡터:
- T: target prompts (persona 유도)
- N: neutral prompts (persona 억제)
- : layer ℓ의 hidden state 평균
2.2 Activation Addition (baseline)
기존 방식:
- α: steering strength
문제:
- residual stream 전체에 영향 → noise amplification
3. Persona Localization (핵심 단계)
3.1 Layer-wise 분석
방법
- 다음 위치에서 vector 추출:
- Attention input
- Attention output
- MLP input/output
- 각 layer 간 cosine similarity 계산
핵심 관찰
- 특정 layer 이후:
- persona direction이 stable
- 해당 layer:
- persona emergence point
–> Qwen:
- layer 20
3.2 Sub-layer 비교
각 위치에서 steering 적용:
- Attn output
- MLP output
결과:
- persona는 attention output에서만 강하게 증폭됨
결론:
persona는 attention module에서 생성됨
4. Head-level 분석
4.1 Head decomposition
Attention:
- : i번째 head output
4.2 Head-wise persona vector
각 head별 vector:
4.3 Head Contribution Score
핵심 정의:
의미:
- 해당 head가 전체 persona 방향에 얼마나 기여하는지
- dot product → 방향 + 크기 반영
4.4 Style Modulation Head 선택
- 상위 k개 head 선택 (예: 3개)
- 공통적으로 높은 score
–> SMH 정의
5. Steering 방법 (핵심 기여)
5.1 기존 방식 (global)
5.2 제안 방식 (local)
Head-level intervention
단,
–> 나머지 head는 untouched
5.3 Steering 위치 비교
논문에서 비교한 5가지:
| 위치 | 설명 |
|---|---|
| MLP residual | MLP 이후 residual |
| Attn residual | Attention 이후 residual |
| Attn output | Attention output |
| Head Cor | SMH만 |
| Head Cor+Anti | + 반대 방향 head |
6. 평가 방법
6.1 LLM-as-a-Judge
두 metric:
- Trait score (persona 표현 정도)
- Coherency score (문장 품질)
→ GPT-4.1-mini 사용
6.2 Pareto 평가
- x: coherency
- y: trait
Score 정의
- coherency ≥ τ 영역에서
- 평균 trait score
7. Ablation (Causal Verification)
방법
- SMH를 zero ablation
결과
- trait score 급감
- coherency 거의 유지
의미:
SMH = persona-specific module
(knowledge / reasoning과 분리됨)
8. 전체 알고리즘 (요약)
Algorithm
Step 1: Vector extraction
for x in dataset:
h_T += h_l(x | target prompt)
h_N += h_l(x | neutral prompt)
f = mean(h_T) - mean(h_N)Step 2: Layer selection
for each layer l:
compute cosine similarity
select layer where direction stabilizesStep 3: Head scoring
for head i:
s_i = dot(f(o_i), f(MHA))
select top-k headsStep 4: Steering
for token t:
for head i in SMH:
o_i += alpha * f(o_i)9. 핵심 차별점
| 기존 | 제안 |
|---|---|
| residual-level | head-level |
| global intervention | localized intervention |
| noisy | disentangled |
| coherency 붕괴 | 안정적 |
10. 한 줄 정리
“persona vector는 residual에 넣는 것이 아니라, persona를 실제로 생성하는 head에만 넣어야 한다.”
논문의 **실험 결과 (Section 3 ~ 5)**를 핵심 메시지 중심으로 정리합니다.
1. Coherency Degradation 분석 (가장 중요한 실험)
1.1 핵심 현상
- Steering strength 증가 시:
- trait score ↑
- coherency ↓ (붕괴)
특히:
Positive steering (trait 강화)
- 매우 빠르게 붕괴
- OOD 방향일수록 심각
Negative steering (trait 억제)
- 상대적으로 완만한 붕괴
–> 비대칭성 존재
1.2 Figure 2 해석
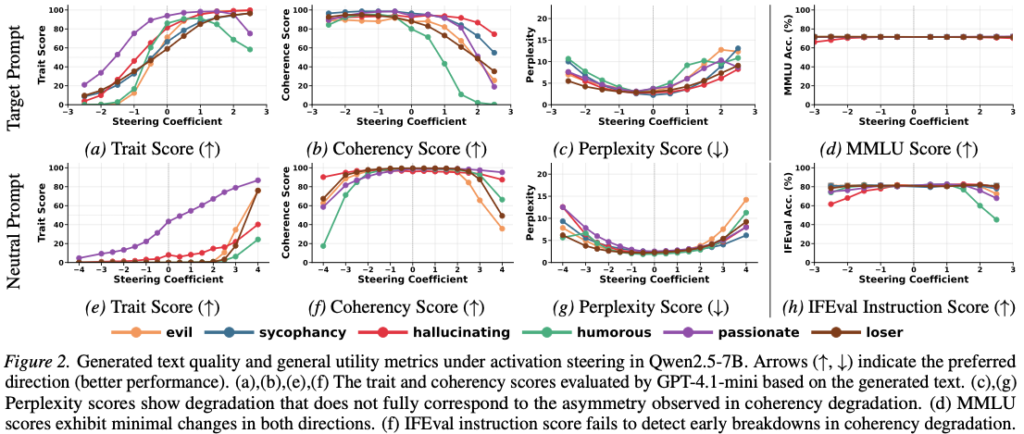
- Trait score:
- α 증가 → 지속 상승
- Coherency:
- 일정 threshold 이후 급락
- Perplexity:
- coherency와 mismatch
- MMLU:
- 거의 변화 없음
결론:
“모델은 지식은 유지하지만 문장은 망가진다”
1.3 중요한 발견
| Metric | Coherency 붕괴 감지 |
|---|---|
| MMLU | X |
| PPL | X |
| IFEval | X |
| Coherency (LLM judge) | O |
–> 기존 평가 체계의 한계
2. Persona 생성 위치 분석 (Layer-wise 결과)
2.1 핵심 결과
- persona direction:
- 특정 layer에서 급격히 형성
- 이후 layer에서 유지
–> Qwen:
- Layer 20
2.2 Figure 3 해석
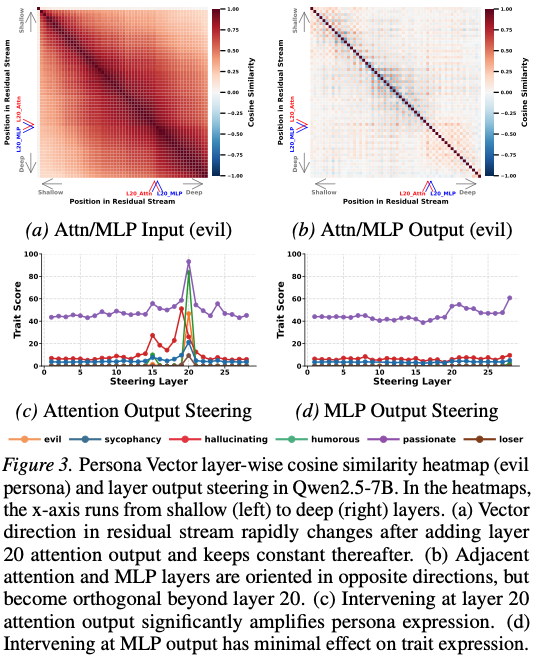
- early layer:
- direction 변화 큼
- 특정 layer 이후:
- direction stable
2.3 Steering 효과 비교
| 위치 | 결과 |
|---|---|
| Attention output | 강한 persona 증폭 |
| MLP output | 거의 영향 없음 |
결론:
persona는 attention에서 생성됨
3. Head-level 분석 결과
3.1 핵심 발견
- 대부분 head:
- contribution 거의 없음
- 일부 head:
- 매우 높은 contribution
–> sparse 구조
3.2 주요 head
- Qwen:
- heads 3, 5, 28 (layer 20)
- Llama:
- heads 24, 30, 32 (layer 14)
3.3 Figure 4 해석
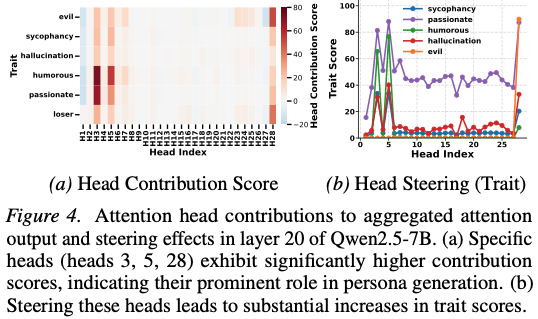
- head contribution score 분포:
- long-tail
- top head:
- 대부분 persona 설명
3.4 Head-level steering 결과
- 특정 head만 조작해도:
- trait score 크게 증가
–> 결론:
persona는 일부 head에 localized
4. Ablation 실험 (Causal 검증)
4.1 방법
- Style Modulation Head 제거 (zero ablation)
4.2 결과
Trait score
- 급격히 감소
Coherency
- 거의 변화 없음
MMLU / IFEval
- 유지
–> Figure 5 결과
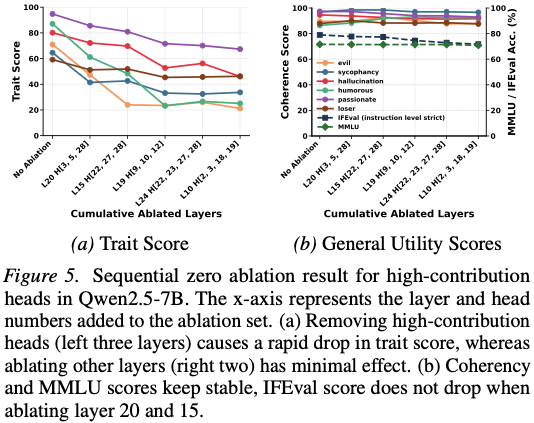
4.3 해석
persona 기능은 다른 기능과 분리된 모듈
즉:
- persona circuit ≠ knowledge circuit
- persona circuit ≠ reasoning circuit
5. Steering 위치 비교 (핵심 실험)
5.1 비교 대상
- MLP residual
- Attn residual
- Attn output
- Head Cor
- Head Cor+Anti
5.2 Figure 6 (Pareto frontier)
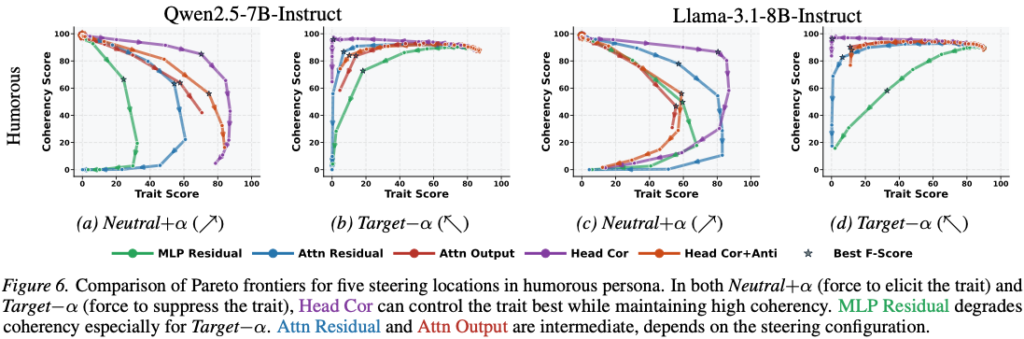
Neutral + α (trait 유도)
- Head Cor:
- 가장 우상단
- → best trade-off
Target − α (trait 억제)
- Head Cor:
- 가장 효과적 suppression + coherency 유지
5.3 핵심 결과
| 방법 | 결과 |
|---|---|
| MLP residual | coherency 붕괴 심함 |
| Attn residual | △ |
| Attn output | △ |
| Head Cor | 대부분 최고 |
| Head Cor+Anti | △ |
5.4 정량 결과 (Table 1)
- Qwen:
- 12개 중 11개 최고
- Llama:
- 12개 중 9개 최고
6. General Capability 영향
6.1 결과
- Head Cor:
- MMLU 유지
- PPL 안정
- IFEval 유지
–> 성능 degradation 최소
6.2 예외
- harmful persona (evil 등):
- 일부 경우:
- Attn residual이 더 안정적
- 일부 경우:
–> 해석:
harmful behavior는 단순 style이 아니라 복잡한 circuit
7. 전체 실험 결과 요약
핵심 4가지
① Coherency collapse 존재
- 특히 OOD steering에서 심각
② 기존 metric 실패
- PPL, MMLU로 감지 불가
③ Persona는 localized
- 특정 layer + 소수 head
④ Head-level steering이 최적
- coherency 유지 + trait control
8. 가장 중요한 메시지
기존 방식
“vector를 잘 만들면 된다”
이 논문
“vector보다 중요한 것은 어디에 넣느냐이다”
9. 연구적으로 중요한 포인트
Mechanistic insight
- LLM 내부는:
- global distributed ❌
- sparse modular ⭕
Steering paradigm shift
- global steering → local intervention
10. 한 줄 결론
“LLM의 persona는 소수 attention head에서 생성되며, 이 head만 조작하면 coherency 붕괴 없이 안정적인 제어가 가능하다.”
답글 남기기