




아래는 「Retrieval Head Mechanistically Explains Long-Context Factuality」(ICLR 2024) 논문의 핵심을 문제의식 → 방법론 → 주요 발견 → 실험적 근거 → 시사점 순서로 정리한 설명입니다.
1. 문제의식
장문 컨텍스트(수만~십만 토큰)에서 LLM이 어떻게 필요한 정보를 정확히 찾아(faithful retrieval) 출력하는지 내부 메커니즘은 불분명했다. 특히 Needle-in-a-Haystack 유형에서 사실성이 유지되는 이유를 어떤 내부 구성요소가 담당하는가가 핵심 질문이다.
2. 핵심 가설
Transformer의 소수의 특정 attention head가 입력의 특정 토큰을 **조건부 복사(copy-paste)**하여 출력으로 직접 전달하는 역할을 하며, 이것이 장문 사실성의 원인이라는 가설을 제시한다. 이들을 Retrieval Head라 명명.
3. 방법론: Retrieval Head 탐지
3.1 Needle-in-a-Haystack 설정
- 질문 q와 정답 k(needle)를 긴 문맥 x(haystack)에 임의 위치로 삽입.
- q는 모델의 내부 지식으로 답할 수 없도록 설계 → 정답 생성은 반드시 문맥에서의 복사를 요구.
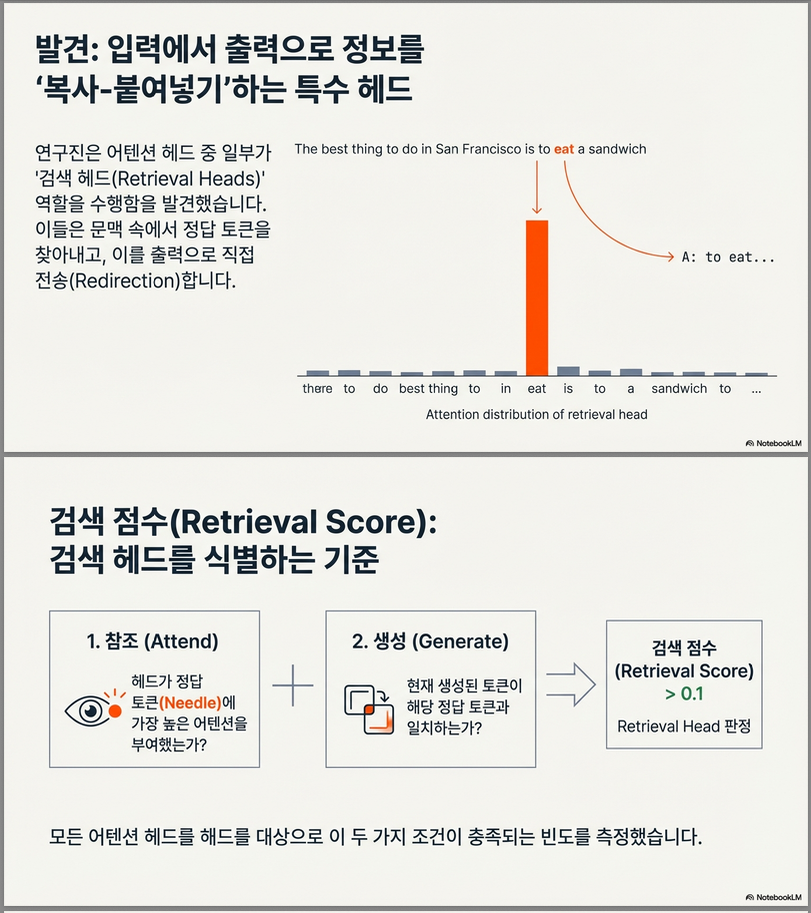
3.2 Retrieval Score 정의
- 자동회귀 디코딩 중, 특정 head가
- 생성 토큰 w가 needle에 속하고,
- 그 head가 가장 강하게 주목한 입력 토큰이 같은 토큰 w이며 needle 구간에 있을 때
- 이를 copy-paste 이벤트로 카운트.
- Retrieval score = (복사된 needle 토큰 수) / (needle 토큰 수).
- 다양한 길이/삽입 깊이/샘플을 평균해 head별 점수를 산출.
4. 주요 발견 (정성·정량)
(A) 보편적이지만 희소
- LLaMA, Yi, Qwen, Mistral, Mixtral 등 모든 모델에서 발견.
- 전체 head의 **~3–6% (대략 <5%)**만 retrieval 역할 수행.
(B) 내재적(intrinsic)
- 베이스 모델에 이미 존재.
- 장문 컨텍스트 지속 사전학습, SFT/RLHF, MoE 업사이클링 이후에도 동일한 head 집합이 유지됨(가족 내 상관계수 >0.8).
(C) 동적 활성
- 일부 강한 head는 거의 모든 문맥에서 활성.
- 다수의 약한 head는 토큰/문맥 의존적으로 부분 활성 → 상호 보완.
(D) 인과적(causal)
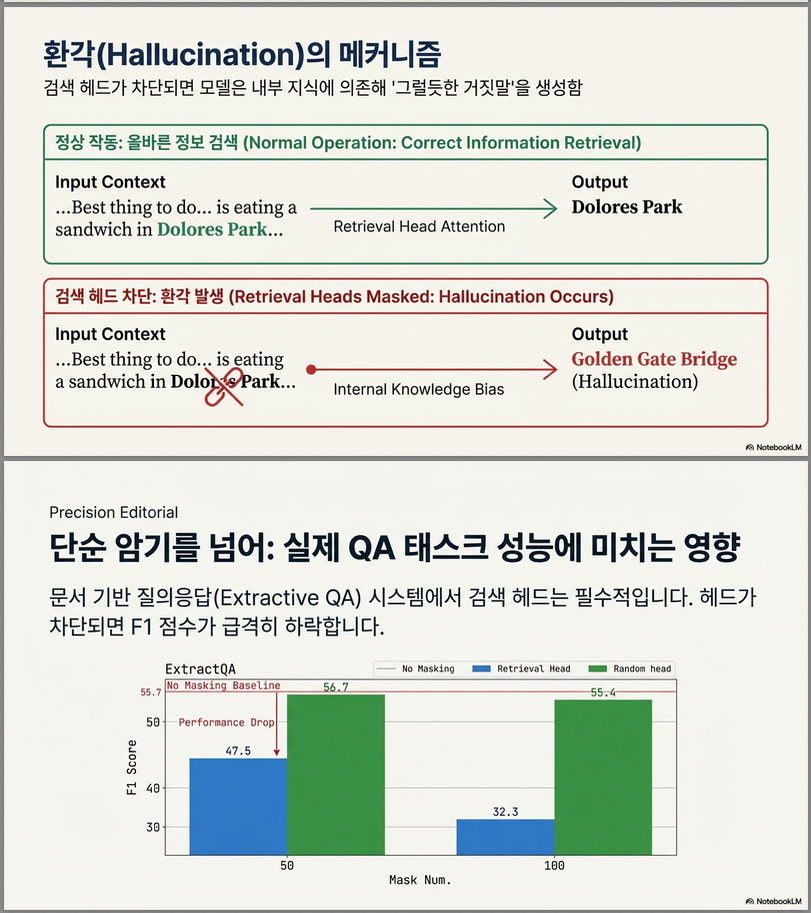
- Retrieval head를 마스킹하면:
- Needle 성능 급락, 불완전 회수 → 환각으로 진행.
- 무작위 head 마스킹은 영향 미미.
- 동일 수의 head를 제거해도 retrieval head 제거만 치명적.
5. 다운스트림 영향
5.1 사실성(Needle)
- Retrieval head 활성 여부가 정답 회수 vs 환각을 결정.
5.2 Extractive QA
- 문서 기반 QA에서 F1 큰 폭 감소(retrieval head 마스킹 시), 랜덤 마스킹은 영향 적음.
5.3 Chain-of-Thought(CoT)
- CoT가 필요한 추론에서 성능 크게 하락.
- 이유: 다음 추론 단계가 이전 입력/중간 정보 참조를 요구 → retrieval head 의존.
- Answer-only 프롬프트(내재 지식 중심)는 영향 상대적으로 작음.
6. 해석 및 논의
- Attention은 알고리즘, FFN은 지식 저장이라는 관점에서,
- Retrieval head는 조건부 검색/복사 알고리즘을 담당.
- Induction head와 유사하되, 패턴 유도가 아니라 정보 회수에 특화.
- Full attention의 필요성: 로컬/선형/SSM 계열은 Needle 통과가 어려움 → retrieval head가 전체 KV 접근을 필요로 함.
7. 실용적 시사점
- 환각 감소: Retrieval head의 활성/보존이 핵심.
- KV 캐시 압축: 전체 head 중 극소수만 retrieval에 중요 → 비-retrieval head의 KV를 공격적으로 압축/제거하는 설계 가능성.
- 장문 모델 설계: 길이 확장보다 retrieval head 보존/강화가 성능 유지의 관건.
8. 한계 및 후속 과제
- Retrieval 외 다른 알고리즘성 head(예: 프로그램 추론)의 체계적 분류는 미완.
- Retrieval head를 학습 단계에서 직접 강화/분리하는 방법은 향후 연구.
요약 한 줄
장문 사실성은 “많은 head”가 아니라 소수의 Retrieval Head가 입력을 정확히 복사해오는 인과적 메커니즘에 의해 설명된다.
아래는 논문의 방법론(Methodology)을 정의 → 지표 → 알고리즘 → 실험 설계 순서로 정리한 것입니다.
1. 문제 설정: Retrieval Head를 어떻게 “정의”할 것인가
논문의 핵심은 **“입력 문맥의 특정 토큰을 출력으로 복사해 오는 역할을 수행하는 attention head”**를 식별하는 것이다.
이를 위해 저자들은 copy–paste 행위를 명시적으로 관찰 가능한 사건(event)으로 정의하고, 이를 빈도화하여 head별 점수로 환원한다.
2. 평가 태스크: Needle-in-a-Haystack
목적
- 모델의 내부 지식이 아니라,
- 입력 문맥에서의 정보 회수(retrieval) 능력만을 강제.
구성
- 질문 q: 문맥과 무관한 질문
- 정답(needle) k: 짧은 문장/구
- 문맥(haystack) x: 매우 긴 텍스트
- k를 x의 임의 위치 구간 에 삽입
제약
- q는 모델의 사전 지식으로 답할 수 없도록 수동 검증
- 따라서 정답 생성은 반드시 문맥에서의 복사를 필요로 함
3. Retrieval Score: 핵심 지표 정의
3.1 Copy–Paste 이벤트 정의
자동회귀 디코딩 시, 특정 attention head h에 대해:
- 현재 생성 토큰: w
- 해당 head의 attention 분포:
- 가장 큰 attention 위치:
Copy–Paste로 간주되는 조건
- → 생성 토큰이 needle에 포함
- → 해당 head가 가장 강하게 주목한 입력 토큰이 needle 구간의 동일한 토큰
이 두 조건을 만족하면, head h가 해당 토큰을 retrieval했다고 판단.
3.2 Retrieval Score 수식
- : head h가 copy–paste한 needle 토큰들의 집합
- k: needle 토큰 집합
해석
- 0.0 : 전혀 retrieval하지 않음
- 0.1 : needle 토큰의 10%를 복사
- 1.0 : needle 전체를 복사
→ token-level recall에 해당
4. Retrieval Head 탐지 알고리즘
4.1 실험 스케일
각 모델에 대해:
- 문맥 길이: 1K–50K, 균일 샘플링
- 각 길이마다:
- needle 삽입 깊이 10개 (문두–문미 균등)
- 서로 다른 (q, k, x) 샘플 3세트
- 총 ≈600 retrieval 테스트 / 모델
4.2 Head 분류 기준
- 모든 테스트에서 head별 RetrievalScore 평균 계산
- 임계값 τ = 0.1
- 즉, 전체 retrieval 상황의 ≥10%에서 copy–paste 수행 시
- 해당 head를 Retrieval Head로 분류
이 기준으로 전체 head의 약 3–6%만 선택됨
5. Activation Frequency (보조 지표)
RetrievalScore는 “얼마나 많이 복사했는가”를 나타내지만,
**“얼마나 자주 활성되는가”**는 별도의 개념이다.
정의
해석
- 높은 ActivationFreq + 낮은 RetrievalScore → 특정 토큰/문맥에서만 부분적으로 작동
- 높은 ActivationFreq + 높은 RetrievalScore → 거의 모든 문맥에서 강력한 retrieval 수행
→ Retrieval Head의 context sensitivity 분석에 사용
6. 인과성 검증: Head Masking 실험
방법
- Attention head 단위로 출력 기여를 마스킹
- 비교 조건:
- Top-K Retrieval Heads 제거
- 무작위 K개 Head 제거
관찰
- (1)에서만 Needle 성능 급락 및 hallucination 발생
- (2)는 성능 거의 유지
→ Retrieval Head가 단순 상관이 아닌 인과적 구성요소임을 입증
7. 다운스트림 적용 실험 설계
- Extractive QA: 최신 뉴스 기반, 내부 지식 배제
- CoT Reasoning: GSM8K, MMLU, MuSiQue
- Answer-only vs CoT 비교
- 동일한 masking 전략 적용 → retrieval 의존성 분석
8. 방법론 요약 (한 문장)
이 논문의 방법론은 **“needle 강제 복사 과제 + token-level copy-paste 정의 + head 단위 통계 + 인과적 마스킹”**을 결합하여, 장문 사실성을 담당하는 attention head를 정확히 식별·검증하는 절차로 구성된다.
아래는 본 논문의 **실험 결과(Experimental Results)**를 핵심 주장별로 정리한 요약이다. 각 결과는 정량 지표 + 인과 실험 + 사례 분석로 구성된다.
1. Retrieval Head는 보편적이며 희소하다
관찰
- 모든 실험 대상 모델(LLaMA, Yi, Qwen, Mistral, Mixtral)에서 Retrieval Head가 일관되게 발견됨.
- 전체 attention head 중:
- **약 3–6%**만 RetrievalScore ≥ 0.1
- 나머지 대부분은 retrieval과 무관
정량 근거
- Figure 3 (도넛 차트):
- RetrievalScore ∈ [0.5, 1.0] head는 <5%
- RetrievalScore = 0인 head가 45–73%
의미
- 장문 retrieval 능력은 “모든 head의 집단 효과”가 아니라 극소수 head에 기능적으로 집중되어 있음.
2. Retrieval Head는 **모델에 내재적(intrinsic)**이다
실험 설정
- Base 모델 vs 파생 모델 비교:
- Context length extension (LLaMA-2 7B → 80K)
- Chat fine-tuning (Qwen → Qwen-Chat)
- Sparse upcycling (Mistral → Mixtral)
결과
- Retrieval head 위치(레이어–헤드 ID)가 거의 동일
- Base–Variant 간 RetrievalScore 분포의 Pearson 상관계수 > 0.8
- 서로 다른 모델 패밀리 간 상관계수는 < 0.1
의미
- Retrieval Head는:
- 장문 pretraining의 부산물이 아님
- 대규모 base pretraining 단계에서 이미 형성
- 이후 fine-tuning은 이를 재사용할 뿐
3. Retrieval Head는 동적으로 활성화된다
분석 지표
- RetrievalScore: 평균적으로 몇 토큰을 복사하는가
- Activation Frequency: retrieval이 한 번이라도 발생하는 비율
결과
- 일부 강한 head:
- ActivationFreq ≈ 1
- 거의 모든 문맥에서 작동
- 다수의 약한 head:
- 특정 토큰/문맥에서만 부분적으로 작동
해석
- Retrieval은 단일 head가 아닌,
- 여러 head의 분산적·보완적 협업으로 수행됨
- 일부 head 제거 시:
- 부분 회수(incomplete retrieval) 발생
4. Retrieval Head는 인과적으로 필수다 (Masking 실험)
Needle-in-a-Haystack
- Top-K Retrieval Head 제거:
- 성능 급락 (K ≈ 전체 head의 5%만 제거해도 정확도 <50%)
- 오류 양상:
- 부분 회수 (세부 정보 누락)
- 완전 환각
- Random Head 제거:
- 성능 거의 유지
핵심 결과
- 동일 개수의 head를 제거해도
- 어떤 head냐가 성능을 결정
- Retrieval Head는 단순 상관이 아니라 인과적 구성요소
5. Extractive QA 성능에 결정적 영향
설정
- 최신 뉴스 기반 문서 QA
- 내부 지식 사용 불가하도록 설계
결과 (Figure 8)
- Retrieval Head 마스킹:
- F1 하락 9.2% ~ 23.1%
- Random Head 마스킹:
- 변화 거의 없음
의미
- 실제 문서 기반 QA에서
- Retrieval Head가 사실성의 핵심 병목
6. Chain-of-Thought(CoT) 추론에 미치는 영향
비교 조건
- Answer-only prompting
- Chain-of-Thought prompting
결과 (Figure 10)
- Answer-only:
- Retrieval Head 마스킹 영향 미미
- CoT:
- Retrieval Head 마스킹 시
- GSM8K / MMLU / MuSiQue 성능 급락
- Retrieval Head 마스킹 시
오류 분석 (Figure 11)
- 모델이 문제 조건의 일부를 “보지 못함”
- 잘못된 수치, 조건 누락, 논리 비약 발생
해석
- CoT는:
- 단순 계산이 아니라
- 이전 입력·중간 상태를 반복 참조
- → Retrieval Head 없이는 reasoning chain이 붕괴
7. 오류 유형 분석 (정성)
논문은 retrieval 실패를 세 가지로 분류:
- Incomplete Retrieval
- 일부 토큰만 회수 (예: “sandwich”는 있으나 “Dolores Park” 누락)
- Hallucination
- Retrieval Head 비활성화 시
- 문두 토큰(attention sink)에 집중 → 완전 환각
- Wrong Extraction
- Retrieval Head는 활성화되었으나
- 잘못된 위치에 주의
8. 실험 결과의 종합 결론
장문 LLM의 사실성, 문서 기반 QA, CoT 추론 성능은
전체 attention 구조가 아니라 소수의 Retrieval Head에 의해 좌우된다.
답글 남기기