


아래는 EMNLP 2024 논문 “Neuron-Level Knowledge Attribution in Large Language Models” 의 핵심 내용을 정리한 설명입니다.
논문 개요
이 논문은 LLM 내부에서 특정 지식(facts)이 어떤 뉴런(neuron)에 저장되는지 정량적으로 찾아내는 뉴런 수준(neuron-level) attribution 방법을 제안합니다. 피쳐 단위(head, layer)보다 더 미세한 수준입니다.
기존 기법은
- 계산 비용이 크고 (causal tracing, integrated gradients)
- 뉴런 수준에서 적용이 어려우며
- FFN 이나 attention 한쪽에 치우치는 문제가 있습니다.
논문은 이를 해결하기 위해:
- log probability 증가량 기반의 정적(static) attribution score
- value neuron / query neuron 구분
- 다양한 지식 유형(언어, 수도, 국가, 색, 숫자, 월)에 대한 저장 위치 분석
을 수행합니다.
배경 (왜 뉴런 수준인가?)
이전 연구들(Geva et al., Dai et al.)은:
- FFN 뉴런이 개념적 key-value memory 역할을 하고
- 많은 factual association이 개별 뉴런(d=1024…11008)에 저장됨
을 밝혔습니다.
하지만 정확히 어떤 뉴런이 특정 예측에 영향을 주는지는 찾기 어려웠습니다.
주 원인:
- 기울기나 causal tracing은 너무 느림
- 정적 saliency(metric)들은 신뢰성 논란
- attention vs FFN 비교 없음
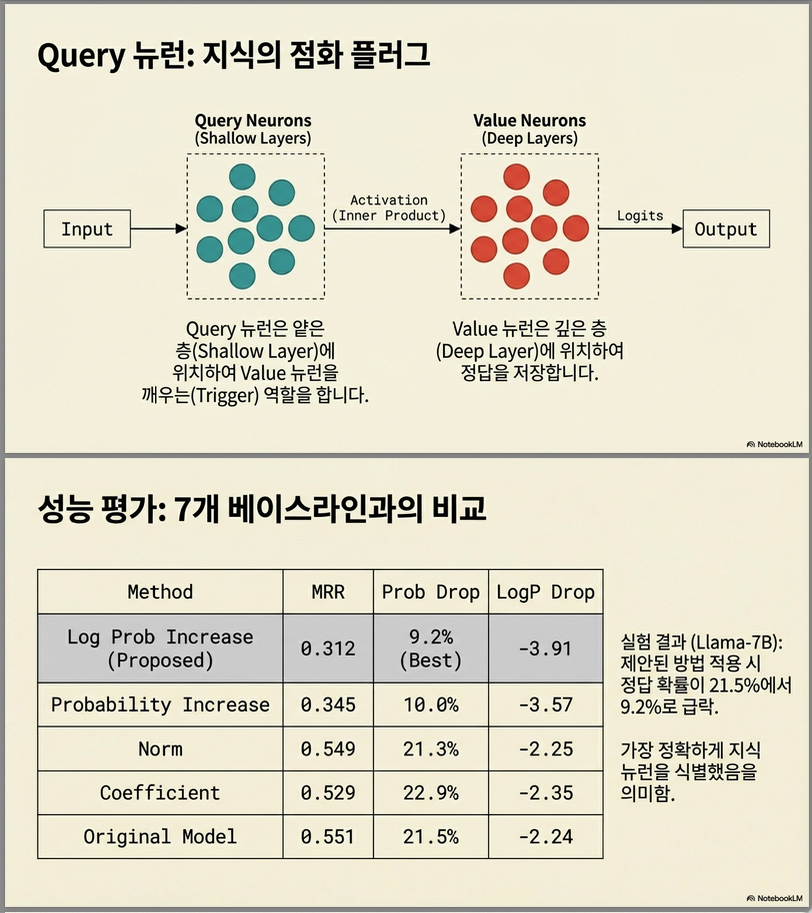
뉴런 정의 (Value neuron / Query neuron)
논문에서는 뉴런을 다음과 같이 정의합니다:
Value neuron
- FFN의 fc2 column vector
- 최종 출력으로 직접 더해지는 “subvalue”
- 특정 단어의 로짓(logit) 방향을 움직임
Query neuron
- value neuron이 활성화되도록 도와주는 upstream subkey 방향
- coefficient score(sigmoid 또는 GELU 이후 값)를 올리는 요소
즉,
- value neuron = 최종 예측에 직접 기여
- query neuron = value neuron을 켜는 트리거
제안된 핵심 기법
Value neuron 중요도 측정
log probability increase
즉,
- 해당 뉴런이 추가되었을 때 정답 토큰 확률이 얼마나 상승하는가?
이는
- 조합(additivity) 가능
- x(현재 residual stream)에 따라 효과가 다름
- medium-deep layer까지 발견 가능
의 장점이 있습니다.
Query neuron 중요도 측정
뉴런의 coefficient score는
로 계산됩니다.
따라서:
- residual 내부의 어떤 뉴런 벡터가 fc1 방향(subkey)과 내적이 큰지 계산하면 → “이 value neuron을 켜는” query neuron이 됩니다.
비교 실험 결과
제안 방법은 7개의 static method보다 성능 우위.
| metric | log prob inc(Ours) | baseline들 |
|---|---|---|
| MRR 감소 | 가장 큼 | 낮음 |
| 정답 확률 감소 | 가장 큼 | 낮음 |
| logp 감소 | 가장 큼 | 낮음 |
즉, 정말 중요한 뉴런을 찾아냄.
지식 저장 구조 분석 (6개 category)
분석된 지식 타입:
- language
- capital
- country
- color
- number
- month
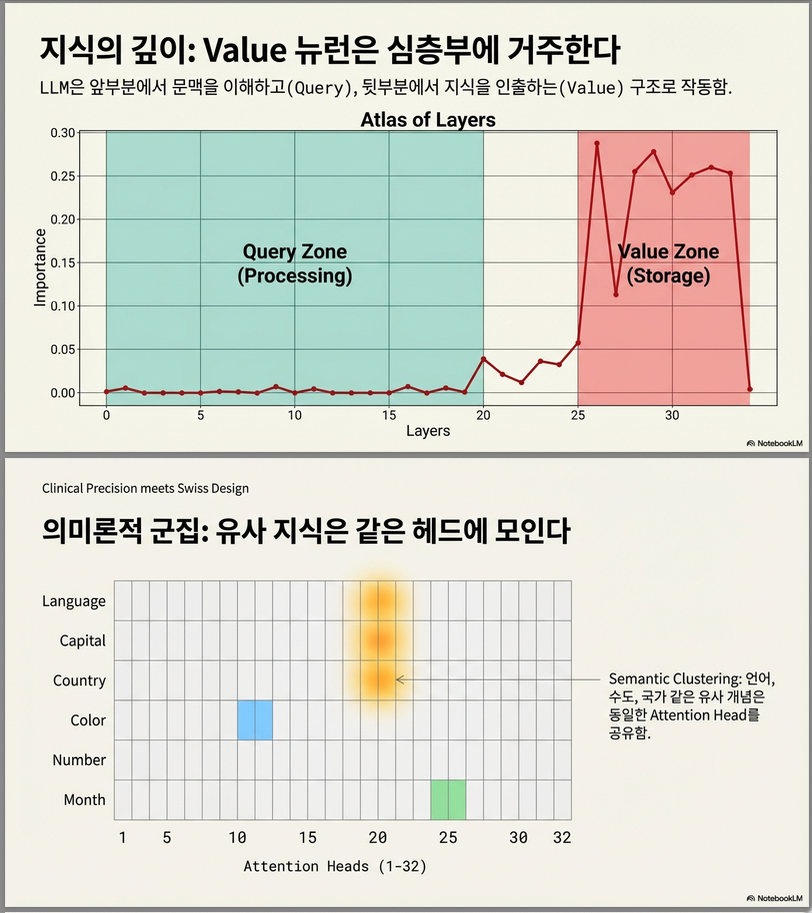
결론:
1) 중요한 value neuron은 모두 깊은 층에 존재
중후반 레이어 (Llama 기준 16~31)
2) 의미적으로 유사한 지식은 같은 head에서 발견
(country, capital, language)
3) semantic이 다른 정보는 다른 head
(color, number, month는 분리)
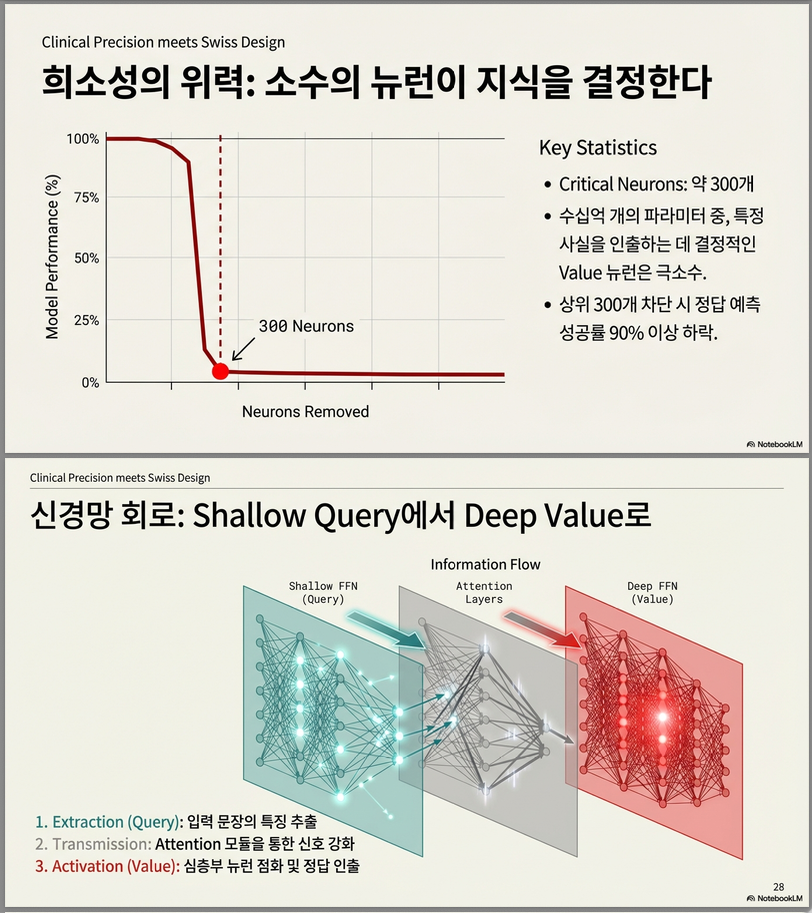
4) 300개의 value/query neuron만 바꾸어도 예측이 크게 변함
지식 저장의 집중성(core neurons)이 존재
Value neuron ↔ Query neuron 상호작용 흐름
논문은 하나의 원인 경로를 제시합니다:
- shallow/medium FFN query neurons → 의미 feature 추출
- medium-deep attention neurons → 의미 routing (토큰 간 관계)
- deep FFN value neurons → 최종 로짓 반영
즉:
FFN(shallow) → Attention(middle) → FFN(deep) routing 패턴
Interpretable neuron 관찰
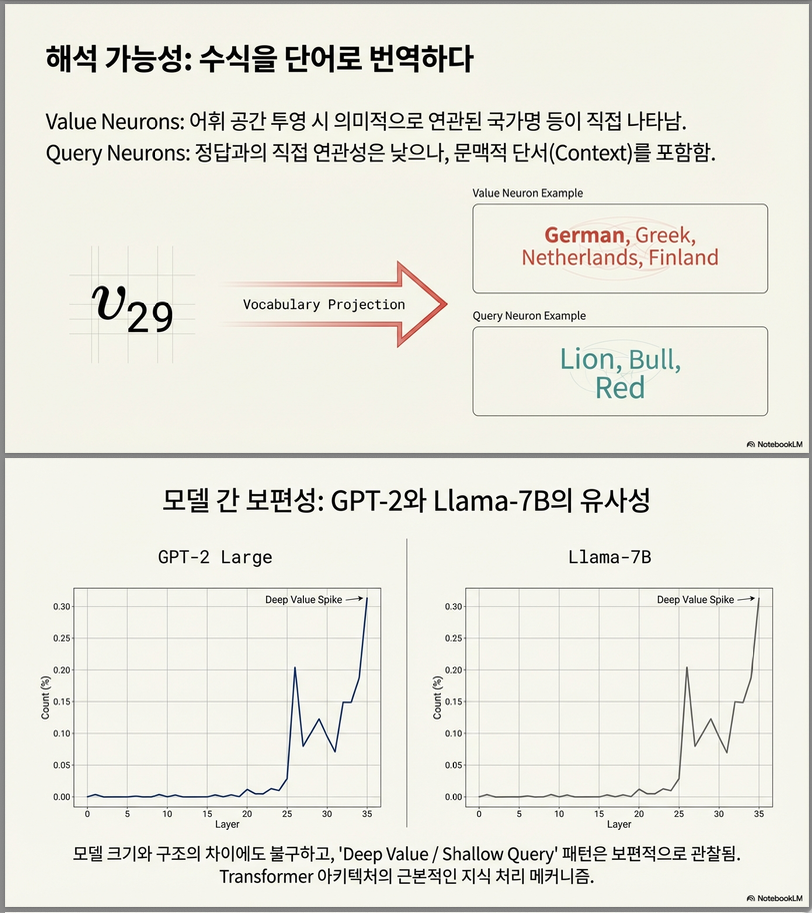
Value neuron 중 일부는 vocabulary projection에서
“Chile, Norway, Slovakia…” → 국가 개념
처럼 해석 가능.
하지만 query neuron은 해석성이 훨씬 낮았음.
→ 향후 연구 필요 포인트로 제시
기여 요약
- log probability increase 기반 neuron-level knowledge attribution 제안
- query neuron 탐지 기법 제안
- 지식 저장 패턴에 대한 layer/head/neuron 분석 제공
- 적은 수의 뉴런 수정만으로 큰 영향 가능 → future knowledge editing 기반
Limitation / Risk
- 분석된 지식 타입 6종 한정
- 모델 규모 제한 (GPT2-large, Llama-7B)
- static method만 비교
- 악의적 editing 가능성 존재
왜 재미있는 논문?
- 뉴런 수준의 지식 저장 위치를 통계적으로 찾음
- knowledge editing 연구의 기반
- mechanistic interpretability 방향성과 호환
- query/value phase 분리는 향후 회로(circuit) 분석과 연결
정리 문장
LLM의 factual knowledge는 소수의 deep FFN value neurons에 집중되어 있고,
shallow/medium FFN query neurons이 이를 활성화하며,
medium-deep attention heads가 semantic routing을 수행한다.
논문의 방법론(Methodology) 부분은 3장에서 제시되며, 핵심은 뉴런 단위에서 지식 기여도를 정적으로 측정하기 위한 새로운 점수(log probability increase) 기반의 분석 프레임워크를 제안하는 것입니다. 주요 구성은 다음과 같습니다.
3.1 Background
Transformer의 한 토큰 예측은 각 레이어의 attention + FFN 출력의 합으로 구성됩니다.
- FFN의 출력은 뉴런 단위로 분해 가능: 여기서 (subkey)와 (subvalue)가 뉴런의 key/value 역할을 합니다.
- Attention의 경우에도 각 head의 value-output 벡터를 뉴런 단위로 해석합니다.
즉, “뉴런(neuron)”은 FFN의 fc2 열 벡터 혹은 attention head 내의 value-output 벡터 단위로 정의됩니다 .
3.2 Distribution Change Caused by Neurons
어떤 뉴런 v 가 최종 출력 에 더해졌을 때
p(w|x+v) – p(w|x)
이 어떻게 변하는지 분석합니다.
이를 위해 before-softmax value (bs-value) 라는 개념을 정의:
즉 각 토큰 w 의 로짓 전 값입니다.
뉴런이 v 일 때,
bs(x+v) = bs(x) + bs(v)
이 성립하며, v 가 어떤 토큰의 확률을 높이는지/낮추는지는 이 벡터의 변화 방향으로 해석됩니다.
실험적으로 v 가 가장 높은 bs-value를 가진 토큰의 확률을 증폭시키는 경향을 보여줍니다.
또한, coefficient score의 부호와 크기가 확률 변화량에 직접적 영향을 줍니다 .
3.3 Importance Score for “Value Neurons”
이 분석을 기반으로 뉴런 중요도(importance) 를 “log probability increase” 로 정의합니다:
- : attention 또는 FFN 레이어의 특정 뉴런 벡터
- : unembedding matrix 를 곱해 softmax 한 결과
이 점수는
- 보존
- 문맥(x)에 따라 뉴런 효과가 달라지는 점 반영
- layer-level, neuron-level 모두 분석 가능
즉, 특정 뉴런이 최종 예측 확률을 얼마나 “증가시키는가”를 직접 측정하는 정적(static) 지표입니다 .
3.4 Importance Score for “Query Neurons”
value neuron이 활성화되는 원인을 찾기 위해 query neuron 탐지 방법을 제안합니다.
- FFN에서 coefficient
- 즉, residual 출력과 subkey의 내적이 높을수록 해당 value neuron이 활성화됨
- 따라서 query neuron은 subkey와 residual 내 뉴런 벡터의 내적이 큰 뉴런으로 정의됨
이 방법은 gradient를 사용하지 않고, inner product 기반 정적 계산으로 “어떤 뉴런이 어떤 value neuron을 켜는가”를 찾을 수 있게 합니다 .
요약 — 방법론 핵심 아이디어
| 구분 | 정의 | 계산식 | 특징 |
|---|---|---|---|
| Value neuron | 예측 확률에 직접 기여하는 뉴런 | 뉴런이 정답 토큰 확률을 얼마나 높이는가 | |
| Query neuron | Value neuron 활성화를 유도하는 뉴런 | 어떤 뉴런이 다른 뉴런을 켜는가 | |
| 전체 구조 | FFN(subkey/value) + Attention(value-output) | additive decomposition | log-prob 기반 정적 추론 가능 |
요약하자면, 본 논문은 gradient-free static attribution으로 LLM 내부 지식 저장을 분석하는 새로운 프레임워크를 제시하며,
“value neuron → query neuron”의 두 단계 연결을 통해 지식 저장 회로(knowledge circuit) 를 정량적으로 추적할 수 있게 했습니다 .
논문의 실험 결과(4장) 부분은 제안한 뉴런 수준 지식 귀속(neuron-level attribution) 방법의 정확성, 효율성, 그리고 LLM 내부 지식 저장 패턴 분석을 중심으로 구성되어 있습니다. 아래에 핵심 실험 설계와 결과를 정리했습니다.
4.1 Comparison of Attribution Methods
(제안 방법 vs 기존 7개 정적 방법 비교)
실험 세팅
- 모델: GPT2-large (36층) / LLaMA-7B (32층)
- GPT2: 20 heads/layer, FFN 뉴런 5,120개
- LLaMA: 32 heads/layer, FFN 뉴런 11,008개
- 데이터셋: TriviaQA에서 6종류의 fact 쿼리–정답 쌍
- language, capital, country, color, number, month
- 정답 토큰이 top-10 예측 안에 드는 문장만 사용
- GPT2-large 1,350문장 / LLaMA-7B 3,141문장
비교된 8가지 방법
| 약어 | Attribution 계산식 | 핵심 아이디어 |
|---|---|---|
| a) ours | **log p(w | m v + A + h) − log p(w |
| b) log p (w | m v) | direct logit attribution (DLA) |
| c) p 증가량 | p(w | m v + A + h) − p(w |
| d) ∥v∥ | 뉴런 벡터 norm | |
| e) ∣m∣ | coefficient score | |
| f) 1 / rank(w) | vocabulary ranking score | |
| g) ∣m∣ × ∥v∥ | Geva et al. (2022) | |
| h) ∣m∣ × 1 / rank(w) | 가중 ranking score |
평가 지표
- MRR (Mean Reciprocal Rank)
- 정답 토큰 확률(prob)
- log probability (logp)
모든 방법으로 상위 10 개의 FFN 뉴런을 선택해 해당 뉴런의 출력을 0으로 만들고 예측 성능 감소 측정.
주요 결과 (Table 2)
| 모델 | MRR | Prob(%) | Logp | 설명 |
|---|---|---|---|---|
| Baseline | GPT2 0.361 / LLaMA 0.551 | 7.1 / 21.5 | −3.15 / −2.24 | 원래 성능 |
| Ours (log prob inc.) | 0.201 / 0.312 | 3.4 / 9.2 | −4.06 / −3.91 | 가장 큰 성능 감소 → 가장 정확히 중요 뉴런 탐지 |
| 다음 우수 | b,c,h | 0.214 ~ 0.389 / 0.339 ~ 0.389 | prob 3.6 ~ 13.0 / 10.0 ~ 13.0 | 일부 기여 있음 |
| 나머지 | d,e,g,f | 감소 미미 |
➡ log probability increase 가 두 모델 모두에서 가장 큰 감소율을 보임 → 가장 정확하게 ‘중요 뉴런’을 탐지 .
추가 분석 결과
- log prob increase 곡선은 중간 ~ 깊은 레이어에서 거의 선형적 증가 → 두 영역 모두 탐지 가능.
- probability increase 는 가장 깊은 레이어에 편향됨.
- 따라서 log prob increase 방법이 중간 및 깊은 층의 뉴런 모두 식별할 수 있음.
4.2 Exploration on Different Knowledge Types
(6종 지식의 저장 패턴 분석)
Layer-Level 결과
- Attention & FFN 모두 지식 저장 기능 존재.
- 모든 중요 뉴런은 깊은 층(23 ~ 31 layer) 에 집중.
- 의미적으로 유사한 지식 (language, capital, country) → 비슷한 레이어 및 head 공유.
- 의미가 다른 지식 (color, month, number) → 서로 다른 레이어에 분산.
예: LLaMA 에서 language/capital/country 모두 a23 층 집중 .
Head-Level 결과
- GPT2: a₆³⁰, a₁⁷²⁶ 등이 language/country 지식 공유.
- LLaMA: a₁²²³, a₃¹¹⁹ 등이 공통 head.
- 상위 1% head 만 제거해도 MRR ≈ −40 ~ −50% 감소 → 소수 head 에 지식 집중.
- 의미 무관 지식 (color, month) 은 거의 영향 없음.
Neuron-Level 결과
| 측정 | Attention | FFN |
|---|---|---|
| 전체 합 score | 6 ~ 7 | 2 ~ 6 |
| 상위 200 뉴런 | 전체의 거의 동일 score 합 보유 | 상위 100 뉴런으로 충분 |
- Top 300 뉴런 정도만 조작해도 모델 정답 확률 99% 이상 감소 → 지식이 소수 핵심 뉴런에 집중.
Query ↔ Value 뉴런 상호 관계
- Query FFN 뉴런(얕은 층) → Attention value 뉴런(중간) → FFN value 뉴런(깊은 층) 순서로 정보 흐름.
- query 레이어는 중간 attention 층 (a19, a22, a26 등) 이 중요.
- query 뉴런 1000개만 제거해도 확률 90 % 이상 감소 → 정확한 query 뉴런 탐지 성공.
Interpretable 뉴런 예시
- GPT2 f29-3771 → “Chile, Finland, Norway” 등 국가 단어 로짓 강화.
- LLaMA a12²³-70 → “German, Greek, Netherlands…”
- Query 뉴런은 Value 보다 해석성 낮음 → 향후 연구 필요.
정리 — 주요 실험 결론
| 항목 | 결과 요약 |
|---|---|
| 성능 비교 | log prob increase 가 모든 지표에서 최고 성능 |
| 층별 분포 | 깊은 층 (20 이후) 에 중요 뉴런 집중 |
| 모듈 간 역할 | Attention + FFN 모두 지식 저장 기여 |
| 지식 패턴 | semantic 유사 지식 → 공유 head/layer |
| Query ↔ Value 흐름 | FFN (shallow) → Attention (mid) → FFN (deep) |
| 해석 가능성 | 일부 value 뉴런은 vocabulary 공간에서 명확히 해석 가능 |
| 의의 | 향후 knowledge editing 및 mechanistic interpretability 연구의 핵심 기초 |
요약하자면,
log probability increase 기반 방법은 가장 효율적이며,
소수의 deep FFN value neurons 이 핵심 지식을 저장하고,
shallow FFN query neurons 과 medium attention neurons 이 이를 활성화하는 “지식 회로(circuit)” 를 형성한다는 결론에 도달했습니다 .
답글 남기기