


다음 논문은 “Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps” (EMNLP 2024) 입니다 .
이 논문은 **LLM의 contextual hallucination(문맥 기반 환각)**을 attention map만을 사용해 탐지하고, decoding 단계에서 이를 완화하는 방법을 제안합니다.
1. 문제 정의: Contextual Hallucination
논문은 환각을 두 종류로 구분합니다:
- Close-book hallucination: 모델의 파라미터 지식이 틀린 경우
- Contextual hallucination (Open-book hallucination): → 입력 문맥에 정답 정보가 있음에도 불구하고 → 모델이 문맥과 불일치하는 내용을 생성하는 경우
이 논문은 **후자(context-grounded setting)**에 집중합니다.
대표 예:
- Summarization (CNN/DM, XSum)
- Document-based QA (Natural Questions)
LLaMA-2-7B-Chat은 문맥이 주어져도 약 절반 수준만 정확 (Table 1)
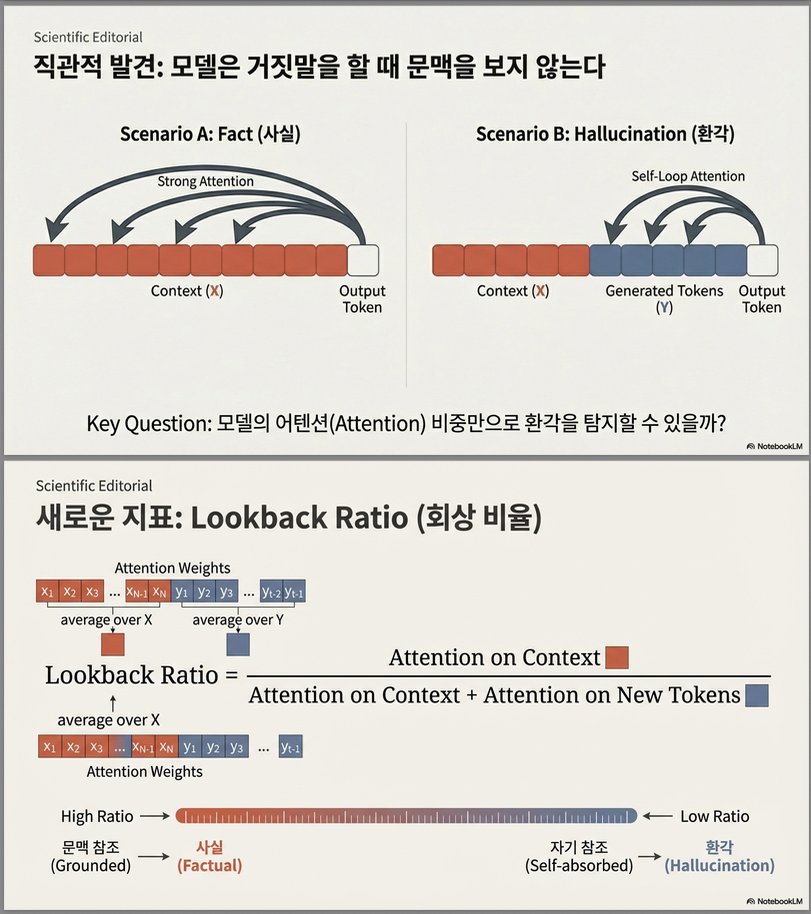
2. 핵심 아이디어: Lookback Ratio
논문의 핵심 가설:
모델이 hallucinate 할 때는
문맥(context)보다 **자기 생성 토큰(new tokens)**에 더 많이 attention을 둔다.
이를 정량화하기 위해 제안한 것이 Lookback Ratio입니다.
2.1 Lookback Ratio 정의
Transformer (L layers, H heads)에서
시간 step t에서 head h, layer l에 대해:
(1) Context attention 평균
(2) Generated token attention 평균
(3) Lookback Ratio
즉,
- 1에 가까우면 → context 중심
- 0에 가까우면 → self-generation 중심
2.2 Feature 구성
모든 layer/head의 LR을 concat:
Span 단위로 평균:
2.3 Classifier
Logistic regression:
- y=1: factual
- y=0: hallucinated
매우 단순한 linear classifier.
3. 실험 설정
데이터 생성
- CNN/DM (1000 examples)
- Natural Questions (2655 examples)
LLaMA-2-7B-Chat greedy decoding
→ GPT-4o로 span-level hallucination annotation
인간 검증:
- Summarization: 97% 일치
- QA: 94% 일치
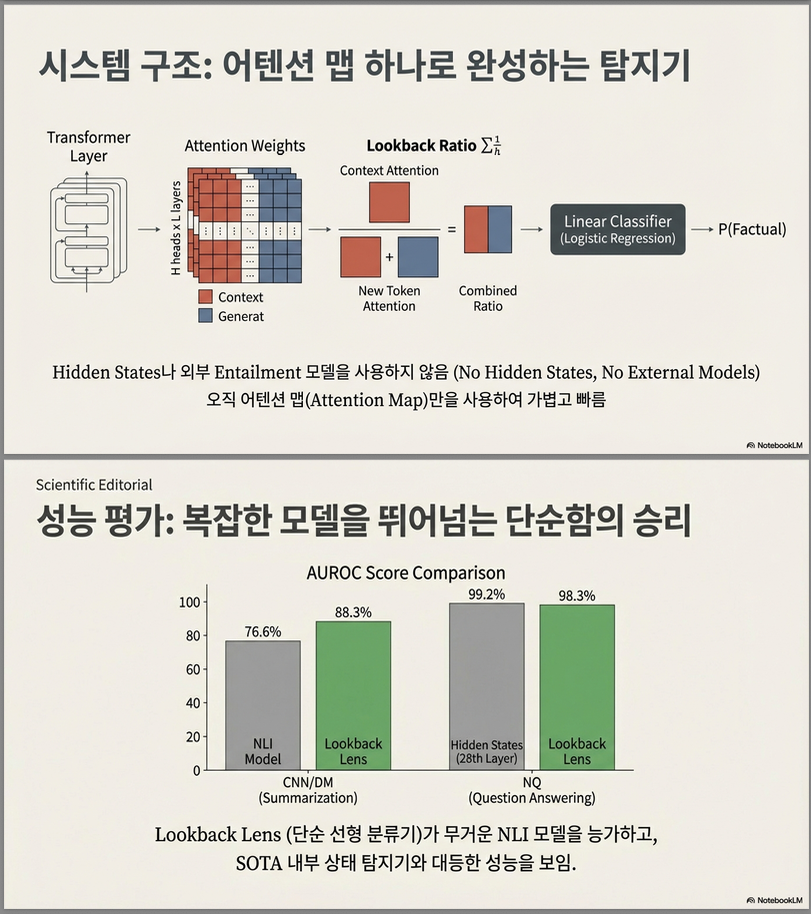
4. Detection 성능
Table 2 결과
비교 대상:
- Text-based NLI classifier
- Hidden-state 기반 classifier (28th layer 등)
- Attention map 기반 (Lookback Lens)
주요 결과:
- Lookback Lens ≈ hidden-state baseline 성능
- NLI 모델보다 우수
- Sliding window 설정에서 특히 강함
- Out-of-domain transfer에서 hidden-state보다 안정적
핵심 포인트:
Hidden state 기반 모델은 training set overfit 경향
Lookback ratio는 cross-task generalization이 좋음
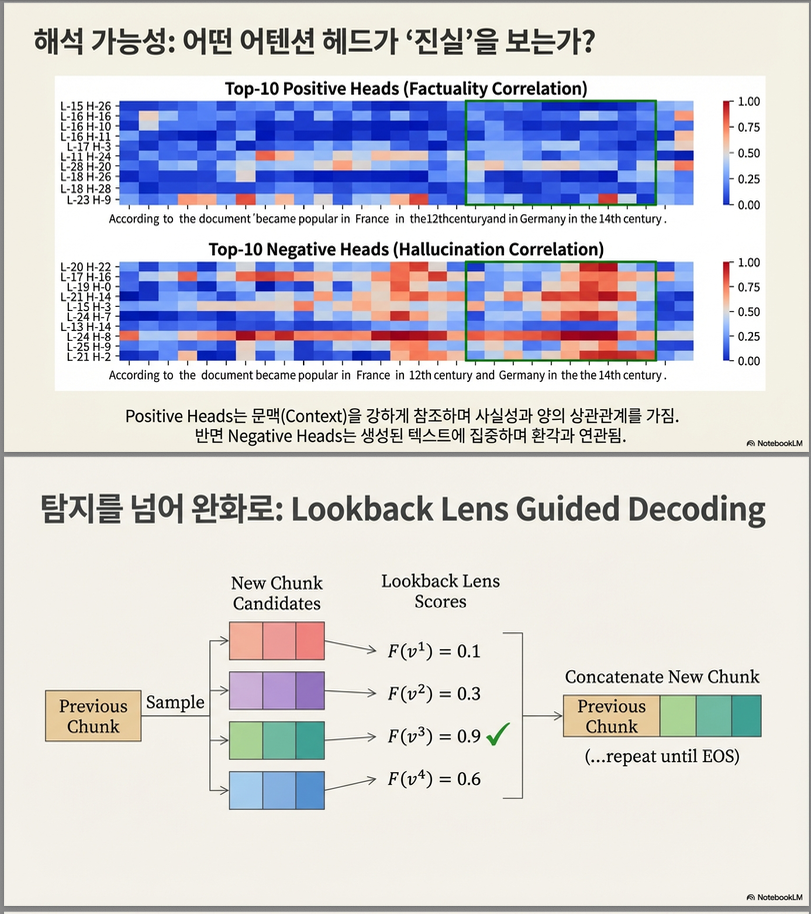
5. Mitigation: Lookback Lens Guided Decoding
Detection만 하지 않고 decoding에 통합.
5.1 방법
- 한 step에서 여러 chunk 후보 생성 (k=8)
- 각 chunk에 대해 lookback ratio 계산
- classifier 점수 F(v)
- 가장 factual할 확률이 높은 chunk 선택
Figure 2에 구조 설명
5.2 결과 (Table 3)
XSum:
- Greedy: 49.0% factual
- Lookback Lens: 58.6% → 9.6% 개선 → hallucination 18.8% 감소
NQ:
- +3% 개선
MT-bench (hallucination setting):
- hallucination 감소
- original quality 유지
중요 비교:
- SoTA NLI (731k 학습 데이터)와 유사 성능
- Lookback Lens는 1k 데이터만 사용
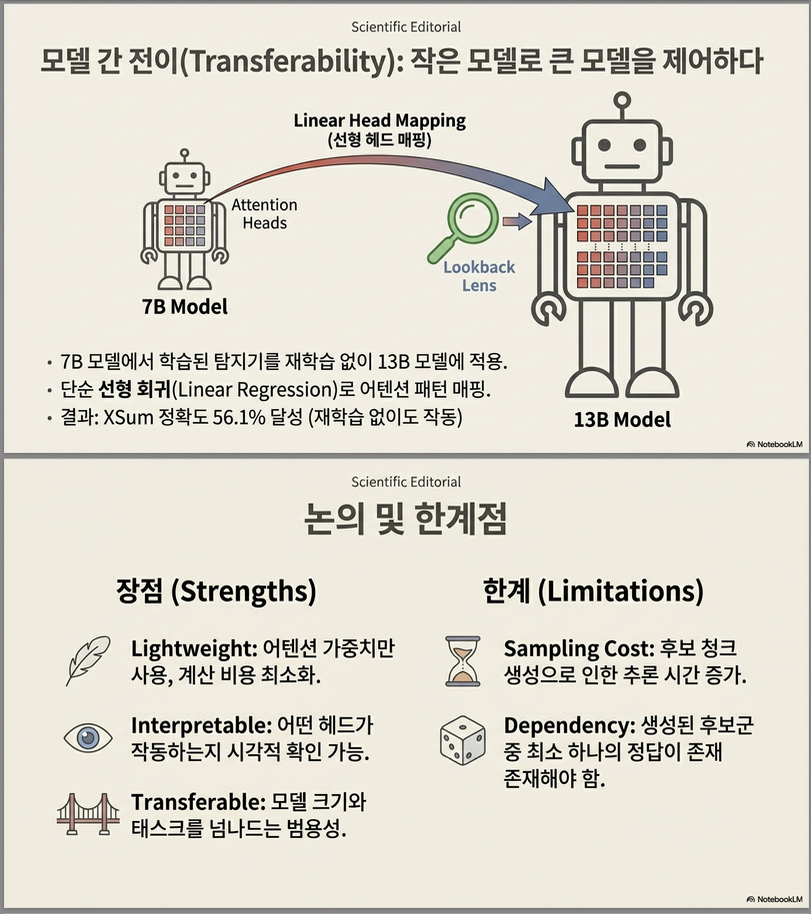
6. Cross-Model Transfer
매우 흥미로운 부분.
7B에서 학습한 classifier를
13B 모델에 적용.
문제:
- head 수 다름 (1024 vs 1600)
해결:
- Linear regression으로 head space mapping
- 13B lookback ratio → 7B head space로 projection
결과 (Table 4, 5) :
- Cross-model detection AUROC 높음
- Guided decoding도 성능 유지
즉:
Attention pattern 기반 feature는 model-agnostic한 구조 신호를 담고 있음
7. 분석 결과
7.1 Head 중요도 (Table 7)
- 일부 head만으로는 충분하지 않음
- Positive head + Negative head 모두 중요
해석:
- Positive head: context grounding
- Negative head: self-consistency 유지
균형이 중요.
7.2 Layer 분석 (Table 8)
- Middle layers (13–20)가 상대적으로 중요
- 그러나 모든 layer 사용이 최적
8. 질적 예시 (Figure 3)
Greedy:
$100m 수치 hallucination 발생
Lookback Lens:
- hallucinated chunk는 낮은 점수
- factual chunk 선택
실제 수치가 document에 존재하는 값으로 수정됨
9. 한계
- Correct chunk가 후보에 없으면 해결 불가
- Multi-candidate sampling → inference cost 증가
- 1~2k annotated data 필요
10. 이 논문의 학술적 의미
이 논문의 가장 중요한 기여는:
(1) Hidden state 없이 attention weight만 사용
- 매우 lightweight
- 해석 가능
(2) Detection + Mitigation 통합
(3) Cross-task, cross-model transfer 가능
(4) Attention map이 실제로
“문맥 grounding 정도”를 반영한다는 실증
11. Mechanistic Interpretability 관점
이 논문은 다음 방향과 연결됩니다:
- Attention head specialization
- Context grounding heads 존재 가능성
- Positive/negative head balance
한 줄 요약
Lookback Lens는 attention map 기반 lookback ratio를 이용해 contextual hallucination을 효과적으로 탐지하고, decoding 단계에서 이를 줄일 수 있으며, cross-model transfer까지 가능한 lightweight 방법이다.
다음은 Lookback Lens 논문의 **방법론(Methodology)**를 수식·설계 관점에서 구조적으로 정리한 것입니다 .
1. 문제 설정
입력:
- 문맥 토큰
- 생성 토큰
목표:
- 생성된 span이 **문맥에 근거(factual)**했는지
- 또는 contextual hallucination인지 판별
핵심 아이디어:
Hallucination은 모델이 문맥보다 자기 생성 토큰에 더 많이 attention을 둘 때 발생한다.
2. Lookback Ratio 정의
Transformer:
- L layers
- H heads
시점 t, layer l, head h
2.1 Context attention 평균
- : token 가 context token 에 주는 softmax attention weight
2.2 Generated token attention 평균
2.3 Lookback Ratio
해석:
- : 문맥 grounding 강함
- : self-generation dominance
3. Feature 구성
3.1 Head × Layer 벡터화
각 timestep에서:
3.2 Span 단위 집계
Span
→ 하나의 span representation
4. Hallucination Classifier
매우 단순한 logistic regression:
- y=1: factual
- y=0: hallucinated
중요 특징:
- hidden state 사용하지 않음
- token embedding 사용하지 않음
- attention weight만 사용
5. Span 정의 방식
(1) Predefined Span
- GPT-4o annotation으로 hallucinated span 명시
- clean supervision
(2) Sliding Window
- chunk size = 8
- hallucinated span과 겹치면 negative
실제 decoding 환경에 더 현실적
6. Detection Baseline 비교
비교 대상:
- Text-based NLI classifier
- Hidden-state 기반 classifier (layer 24, 28, 32)
- Attention block output
결과:
- Lookback Lens ≈ hidden-state
- NLI보다 우수
- Sliding window에서 특히 강함
- Cross-task generalization 우수
7. Mitigation: Lookback Lens Guided Decoding
Detection을 decoding에 통합.
7.1 문제
한 timestep에서:
- 모든 vocab token은 동일 attention pattern
- 따라서 1-step token choice 직접 조정 불가
7.2 해결 전략: Chunk-level selection
- 현재 partial generation 상태에서
- k개의 chunk 후보 생성
- 각 chunk에 대해 lookback ratio 계산
- classifier 점수 계산
- 가장 factual한 chunk 선택
이 과정을 EOS까지 반복
8. Cross-Model Transfer
문제:
- 7B: 1024 heads
- 13B: 1600 heads
- head alignment 없음
8.1 Head space mapping
훈련 데이터 D에 대해:
Linear regression:
→ 13B lookback ratio를 7B head space로 projection
이후 7B classifier 적용
9. Head 분석
- Top-k heads만 사용하면 성능 감소
- Positive head + Negative head 모두 필요
해석:
- Positive heads: context grounding
- Negative heads: generation consistency
10. Layer 분석
- Middle layers (13–20)가 상대적으로 중요
- 그러나 전체 layer 사용하는 것이 최적
11. 방법론의 본질
이 논문 방법론의 핵심은:
① Attention을 grounding proxy로 사용
② Ratio 기반 normalized metric 설계
③ 매우 단순한 linear classifier
④ Chunk-level guided decoding
⑤ Cross-model transferable feature
12. 이 방법의 이론적 의미
Hidden state 기반 접근과 차이:
| Hidden-state 기반 | Lookback Lens |
|---|---|
| Representation space 의존 | Attention structure 기반 |
| 모델 의존적 | 상대적으로 구조적 |
| Overfit 경향 | Generalizable |
즉,
Lookback ratio는 모델이 “어디를 보고 있는지”를 직접 측정하는 grounding signal입니다.
다음은 Lookback Lens 논문의 **실험 결과(Detection + Mitigation + Transfer + Ablation)**를 구조적으로 정리한 내용입니다 .
1. Hallucination Detection 성능
평가 설정
- Predefined Span
- Sliding Window (size=8)
- Task:
- QA (Natural Questions)
- Summarization (CNN/DM)
평가지표: AUROC
Table 2 핵심 결과
Predefined Span
| Method | QA→Sum Transfer | Sum→QA Transfer |
|---|---|---|
| Hidden state (28th layer) | 83.6 | 84.7 |
| Lookback Lens | 85.3 | 82.0 |
→ Hidden state 기반과 동등하거나 약간 우수
Sliding Window (현실적 설정)
| Method | QA→Sum Transfer | Sum→QA Transfer |
|---|---|---|
| Hidden state (28th layer) | 57.7 | 58.8 |
| Lookback Lens | 66.1 | 66.0 |
중요한 차이점
- Hidden-state 기반 모델은 sliding window에서 급격히 성능 저하
- Lookback Lens는 8~9% 이상 향상
NLI 기반 모델과 비교
- SoTA NLI보다 우수
- 텍스트 기반 entailment 접근보다 attention 구조 기반이 더 robust
Detection 실험 결론
- Attention map만으로 hidden-state 기반과 동등 성능
- Sliding window 설정에서 큰 우위
- Cross-task generalization 우수
2. Hallucination Mitigation (Guided Decoding)
Detection을 decoding에 통합.
설정:
- chunk size = 8
- candidate = 8
XSum (In-domain transfer)
| Method | Accuracy |
|---|---|
| Greedy | 49.0% |
| Lookback Lens | 58.6% |
→ +9.6% absolute improvement
→ hallucinated examples 510 → 414
→ 18.8% hallucination 감소
Natural Questions (Out-of-domain)
| Method | EM |
|---|---|
| Greedy | 71.2 |
| Lookback Lens | 74.2 |
→ +3%
MT-Bench (hallucination setting)
- hallucination 감소
- original quality 유지
→ hallucination만 줄이고 fluency/utility는 유지
중요한 비교
- SoTA NLI는 731k 학습 데이터
- Lookback Lens는 약 1k 데이터
→ 데이터 효율성 매우 높음
3. Cross-Model Transfer
7B → 13B transfer 실험
Detection (Table 4)
7B → 13B + Cross-task
| Setting | AUROC (Predefined) |
|---|---|
| QA→Sum | 73.5 |
| Sum→QA | 78.2 |
→ Cross-model에서도 비정상적으로 높은 AUROC
Guided Decoding (Table 5)
| Method | XSum | NQ |
|---|---|---|
| Greedy | 52.9 | 74.0 |
| Lookback Lens (7B→13B) | 56.1 | 76.4 |
→ Cross-model에서도 mitigation 효과 유지
의미
Attention 기반 feature는 모델 규모 변화에도 구조적 grounding 패턴을 반영
4. Ablation Study
4.1 Chunk Size 영향 (Table 6)
| Chunk | XSum | NQ |
|---|---|---|
| 4 | 53.2 | 75.4 |
| 8 | 58.6 | 74.2 |
| 16 | 57.7 | 74.3 |
→ chunk size에 크게 민감하지 않음
4.2 Head 중요도 (Table 7)
- Top-10 heads만 사용 → 성능 급감
- Top-100 heads → 거의 full recovery
- Positive head만 사용 → 부족
- Negative head만 사용 → 부족
해석
- Context-grounding head + Self-consistency head 균형 필요
4.3 Layer 중요도 (Table 8)
- Middle layers (13–20) 상대적으로 중요
- 하지만 전체 layer 사용하는 것이 최적
→ grounding signal이 layer 전반에 분산
5. Qualitative Example (Figure 3)
Greedy:
“$100m (£64m)” hallucination
Lookback Lens:
- 잘못된 chunk에 낮은 점수
- 올바른 chunk 선택
- 문서에 존재하는 수치만 유지
6. 전체 실험 결과 요약
Detection
- Hidden-state ≈ Lookback
- Sliding window에서 Lookback 우위
- Cross-task generalization 강함
Mitigation
- XSum +9.6%
- NQ +3%
- MT-Bench hallucination 감소
Transfer
- Cross-model 가능
- Head space mapping으로 해결
Ablation
- Head subset만으로 불충분
- Layer 전체 활용 필요
- Chunk size 안정적
연구적으로 중요한 메시지
- Attention map은 실제로 grounding signal을 담고 있음
- Hidden representation 없이도 hallucination detection 가능
- Attention structure는 model-agnostic feature가 될 수 있음
- Grounding과 self-consistency head의 균형이 중요
이 논문에서 Hallucination Detection 성능을 어떻게 정의하고 측정했는지, 그리고 NLI 기반 방법은 어떤 방식으로 비교했는지를 정리합니다 .
1. Hallucination Detection 평가 설정
목표
주어진 생성된 span이
- 문맥에 근거한 factual span인지 (label=1)
- contextual hallucination인지 (label=0)
를 이진 분류.
2. Ground Truth Label 생성 방식
데이터 생성 과정
- LLaMA-2-7B-Chat이 greedy decoding으로 생성
- GPT-4o가 다음 작업 수행:
- 문맥 기반으로 truthfulness 판별
- span-level hallucinated segment 식별
- 일부 데이터는 human 검증
- Summarization: 97% 일치
- QA: 94% 일치
즉,
Detection은 GPT-4o가 생성한 span-level hallucination annotation을 gold label로 사용
3. Span 정의 방식
논문은 두 가지 평가 설정을 사용합니다.
(A) Predefined Span Setting
- GPT-4o가 표시한 hallucinated span 그대로 사용
- Clean binary classification
평가:
이 경우, 각 span은 완전히 hallucinated 또는 non-hallucinated
(B) Sliding Window Setting (현실적)
- 고정 chunk size = 8
- sliding window로 전체 생성문을 분할
- window가 hallucinated span과 겹치면 label=0
→ 실제 decoding 상황과 유사
이 설정이 더 어려움.
4. 평가 지표
모든 detection 실험은:
- classifier가 출력한 factual probability를 threshold 없이 평가
- imbalance에 robust
- span-level binary classification 문제
5. NLI 기반 Hallucination Detection은 어떻게 측정했는가?
방식
NLI 모델은 다음 구조로 사용됨:
입력
- Premise: 입력 문맥(document)
- Hypothesis: 생성된 span
출력
- Entailment / Non-entailment
Entailment이면 factual
Non-entailment이면 hallucination
NLI 모델 종류
- SoTA NLI (Vectara model)
- DeBERTa-v3 기반
- 약 731k 데이터로 학습
- Authors’ implementation
- DeBERTa-v3-base
- 동일 CNN/DM + NQ 데이터로 fine-tuning
평가 방식
- 각 span에 대해 entailment score 출력
- 해당 score를 기반으로
- AUROC 계산
즉,
Lookback Lens와 동일한 방식으로 평가.
6. 실험 결과 비교 (Detection)
Predefined Span
| Method | QA→Sum Transfer |
|---|---|
| SoTA NLI | 76.6 |
| Hidden state (28th) | 83.6 |
| Lookback Lens | 85.3 |
Sliding Window (현실적)
| Method | QA→Sum Transfer |
|---|---|
| SoTA NLI | 57.1 |
| Hidden state | 57.7 |
| Lookback Lens | 66.1 |
왜 NLI는 Sliding Window에서 약한가?
이유는 구조적 차이 때문입니다.
NLI는:
- 텍스트 의미 기반 판단
- span이 짧거나 불완전하면 판단 어려움
- distribution shift에 취약
Lookback Lens는:
- attention grounding 패턴 직접 사용
- generation 과정 정보 포함
- token 단위 구조적 신호 활용
즉,
NLI는 “텍스트 결과”만 보고 판단
Lookback은 “모델 내부 attention 구조”를 본다
8. Detection 평가 전체 요약
| 항목 | 방식 |
|---|---|
| Label 생성 | GPT-4o span annotation |
| Span 단위 | Predefined / Sliding Window |
| 지표 | AUROC |
| NLI 입력 | (Document, Generated span) |
| NLI 출력 | entailment probability |
| 비교 방식 | 동일 span-level AUROC |
연구적으로 중요한 포인트
- Detection은 generation 이후 post-hoc binary classification
- AUROC로 threshold-independent 비교
- NLI는 purely semantic evaluation
- Lookback은 mechanistic attention-based signal
- Sliding window에서 attention 기반 방법이 robust
답글 남기기