





이 논문은 기존 LLMLingua 계열의 한계를 개선한 task-agnostic prompt compression 논문입니다.
핵심 아이디어는 다음과 같습니다.
“정보 엔트로피(perplexity) 기반으로 토큰을 제거하지 말고,
LLM(GPT-4)로부터 압축 지식을 distillation하여
‘이 토큰을 유지할지 버릴지’를 분류하도록 학습하자.”
즉:
- 기존:
- causal LM의 entropy 기반 heuristic compression
- 제안:
- GPT-4가 만든 “좋은 압축 예시”를 학습한
- bidirectional encoder 기반 token classifier
입니다.
1. 문제 배경
LLM prompt는 점점 길어짐:
- CoT
- RAG
- ICL
- multi-document QA
→ 수천~수만 token.
문제:
- inference latency 증가
- API cost 증가
- long-context degradation
- “Lost in the Middle” 현상
따라서:
를 수행하고 싶음.
2. 기존 방법의 한계
논문은 기존 task-agnostic compression의 핵심 문제를 지적합니다.
대표 baseline:
- Selective-Context
- LLMLingua
이들은:
즉 entropy/perplexity 기반으로 중요도를 계산.
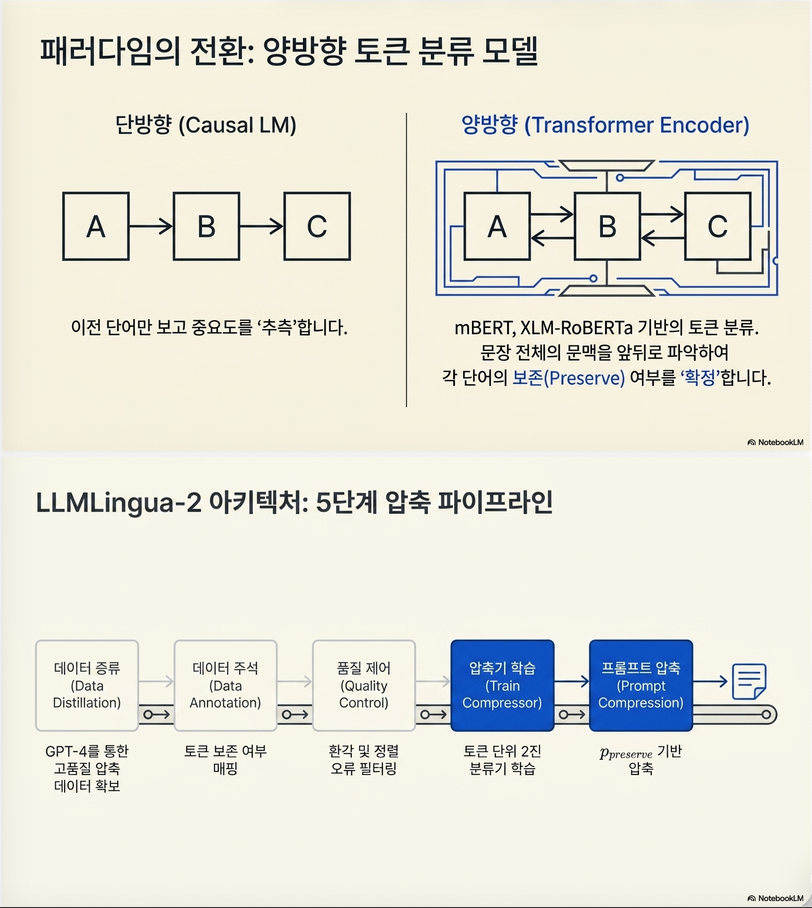
문제점 1: causal context만 사용
기존 방식은 causal LM 사용:
즉 미래 context를 못 봄.
예:
The capital of France is Paris.“Paris” 중요성은 뒤 context까지 봐야 정확히 판단 가능.
하지만 causal entropy는 local surprisal 기반이라
semantic importance와 다름.
문제점 2: compression objective와 불일치
entropy가 낮다고 불필요한 것은 아님.
예:
notentropy 낮아도 의미상 매우 중요.
즉:
3. 핵심 아이디어
논문의 핵심 구조는 page 3 Figure 1에 잘 나와 있습니다.

전체 pipeline:
- GPT-4로 압축 데이터 생성
- token-level label 생성
- 품질 filtering
- token classifier 학습
- classifier로 압축 수행
4. Data Distillation
논문의 가장 중요한 부분입니다.
4.1 GPT-4로 “압축 정답” 생성
GPT-4에게:
“원문 단어를 유지하면서 불필요한 단어만 제거하라”
라고 instruction.
Figure 2 prompt:
핵심 제약:
- remove only
- reorder 금지
- word 변경 금지
- abbreviation 금지
- new word 추가 금지
즉:
extractive compression만 허용.
왜 extractive인가?
abstractive summarization 기반 압축은:
- hallucination 발생
- detail loss 발생
RAG/QA에 치명적.
따라서:
을 위해 extractive 방식 채택.
5. Chunk-wise Compression
긴 문서 전체를 GPT-4로 압축하면:
- 과도 압축 발생
- 정보 손실 증가
그래서:
로 분할 후 chunk별 압축.
이 부분이 성능에 매우 중요합니다.
논문 ablation에서도:
chunk-wise compression 제거 시 성능 크게 하락.
6. Token Classification Formulation
이 논문의 핵심 methodological contribution.
기존 방식
기존:
heuristic ranking.
제안 방식
압축을 binary classification으로 변환:
모델 구조
Transformer encoder 사용:
즉:
- BERT
- XLM-R
- mBERT
같은 bidirectional encoder 사용.
장점
(1) bidirectional context 활용
에 가까운 semantic importance 학습 가능.
(2) compression objective 직접 최적화
entropy heuristic 아님.
직접:
를 supervision.
(3) 매우 빠름
decoder LM inference 불필요.
encoder forward 한 번이면 끝.
7. Compression Strategy
목표 compression ratio:
이면 유지 token 수:
각 token preserve probability:
계산 후:
- token 유지
- original order 유지
즉:
sort by preserve probability방식.
8. Quality Control
매우 실용적인 부분입니다.
8.1 Variation Rate (VR)
GPT-4가 hallucination한 비율.
VR 높은 샘플 제거.
8.2 Alignment Gap (AG)
annotation 품질 측정.
핵심 아이디어:
compressed token과 original token alignment 품질 평가.
AG = HR – MR
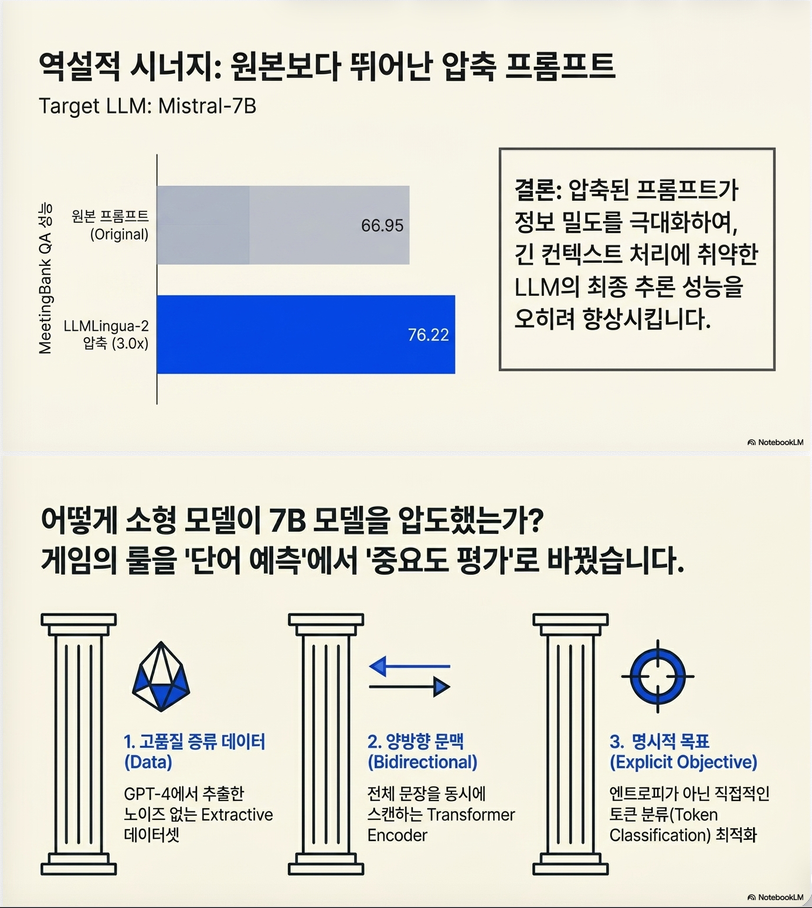
9. 실험 결과
9.1 In-domain (MeetingBank)
Table 1.
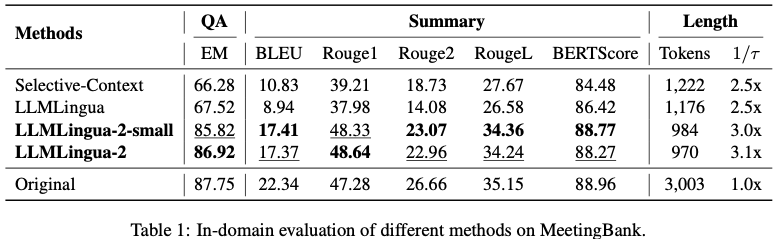
LLMLingua-2:
- QA 성능 거의 original 유지
- summary 성능 향상
- token 수 대폭 감소
특히:
- LLMLingua baseline보다 훨씬 우수
- 더 작은 모델인데도 성능 superior
9.2 Out-of-domain
LongBench / ZeroSCROLLS / GSM8K / BBH.
Table 2, 3.
결과:
- strong generalization
- task-agnostic인데도 robust
특히:
- reasoning
- ICL
- long-context QA
에서 꽤 잘 유지됨.
9.3 Latency
Table 5.
압축 자체 latency:
- LLMLingua: 1.5~2.9 sec
- LLMLingua-2: 0.4~0.5 sec
즉:
빠름.
end-to-end도:
speedup.
10. 왜 중요한 논문인가?
이 논문은 prompt compression 패러다임을 바꿈.
기존:
heuristic entropy pruning↓
LLMLingua-2:
learned semantic compression11. 논문의 핵심 통찰
핵심 insight:
“compression은 LM perplexity 문제가 아니라
supervised token selection 문제다.”
즉:
12. 한계
논문 limitation도 중요합니다.
(1) training data domain 편향
MeetingBank 기반 학습.
즉:
- conversational redundancy
- meeting transcript style
에 bias.
(2) semantic abstraction 부족
extractive only라서:
- paraphrasing
- semantic abstraction
못함.
따라서 extreme compression 한계.
(3) token-level independence
top-k token selection이라:
- phrase-level structure
- syntactic dependency
깨질 수 있음.
13. 이후 연구 흐름에 미친 영향
이 논문 이후:
- learned compressor
- semantic compressor
- latent compression
- soft prompt compression
- autoencoder compression
계열 연구가 급증.
특히 최근:
- Dynamic Compressing Prompts
- In-Context Autoencoder
- 500xCompressor
- Information Preservation
등의 흐름과 직접 연결됩니다.
14. 개인적으로 가장 중요한 포인트
이 논문의 가장 중요한 contribution은 사실:
“compression dataset distillation”
입니다.
즉:
로 사용했다는 점.
이게 이후:
- context autoencoder
- latent compressor
- retrieval compressor
- learned KV pruning
계열로 이어집니다.
15. 한 줄 요약
LLMLingua-2는:
GPT-4로 생성한 extractive compression 데이터를 이용해
bidirectional token classifier를 학습함으로써
기존 entropy 기반 prompt compression보다
더 정확하고 빠른 task-agnostic prompt compression을 달성한 논문이다.
답글 남기기