


논문 **“Interpret and Improve In-Context Learning via the Lens of Input-Label Mappings” (ACL 2025)**는 대형 언어 모델(LLM)의 In-Context Learning (ICL) 능력을 **입력-레이블 매핑(input-label mappings)**의 관점에서 분석하고, 해당 메커니즘을 해석하며, 향상시키는 방법을 제안합니다.
1. 연구 질문
LLM의 ICL 성능을 분석하기 위해 다음 세 가지 질문을 다룹니다:
- What: 입력-레이블 매핑은 무엇이며, LLM 안에서 어떤 형태로 존재하는가?
- Where: 입력-레이블 매핑은 모델의 어디서 작동하는가?
- How: 모델은 이 매핑을 어떻게 활용하는가?
2. 주요 기여
(1) 입력-레이블 매핑의 발견
- 특정 layer의 **principal components (PCs)**에 의미 있는 입력-레이블 관계가 저장됨을 확인.
- PC를 vocabulary space로 투영하면 **사람이 해석 가능한 단어(예: happy, sad)**가 드러남.
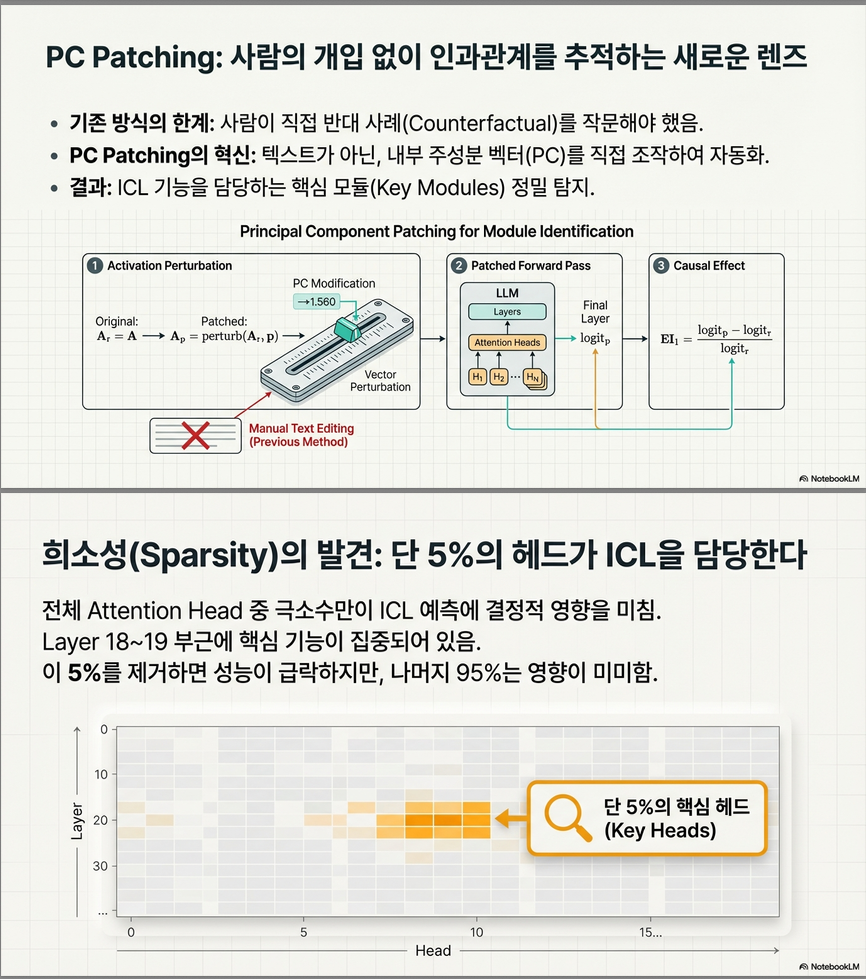
(2) PC Patching 기법
- 기존의 path patching이 수동으로 설계한 counterfactual 예시를 요구하는 한계를 극복.
- PC patching은 task-related PC 방향으로 hidden state를 perturb하여 모듈별 causal effect를 정량화함.
- 이 과정을 통해 ICL에 기여하는 attention head는 전체의 5% 수준이라는 사실을 발견.
(3) 매핑 활용 방식 분석
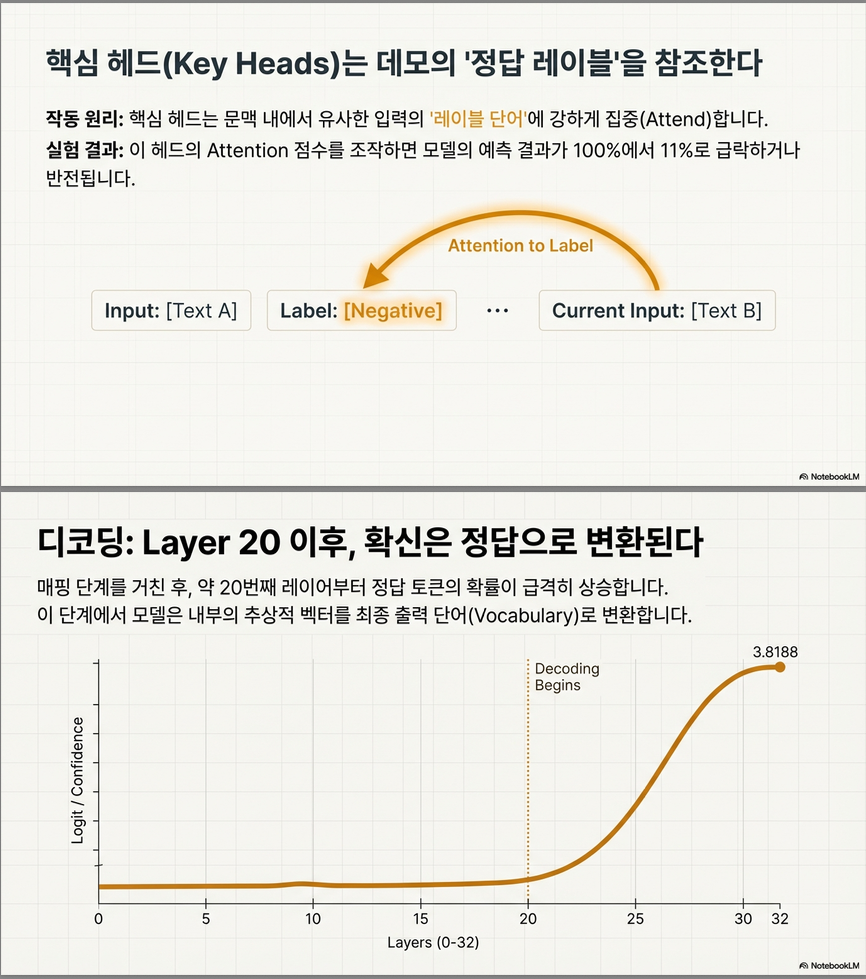
- 핵심 attention head는 demonstration 내 label token에 강한 attention을 부여함.
- attention score를 바꾸면 예측 정확도가 급격히 하락(최대 -90%), 이로써 해당 head가 input-label mapping을 실제로 적용함을 입증.
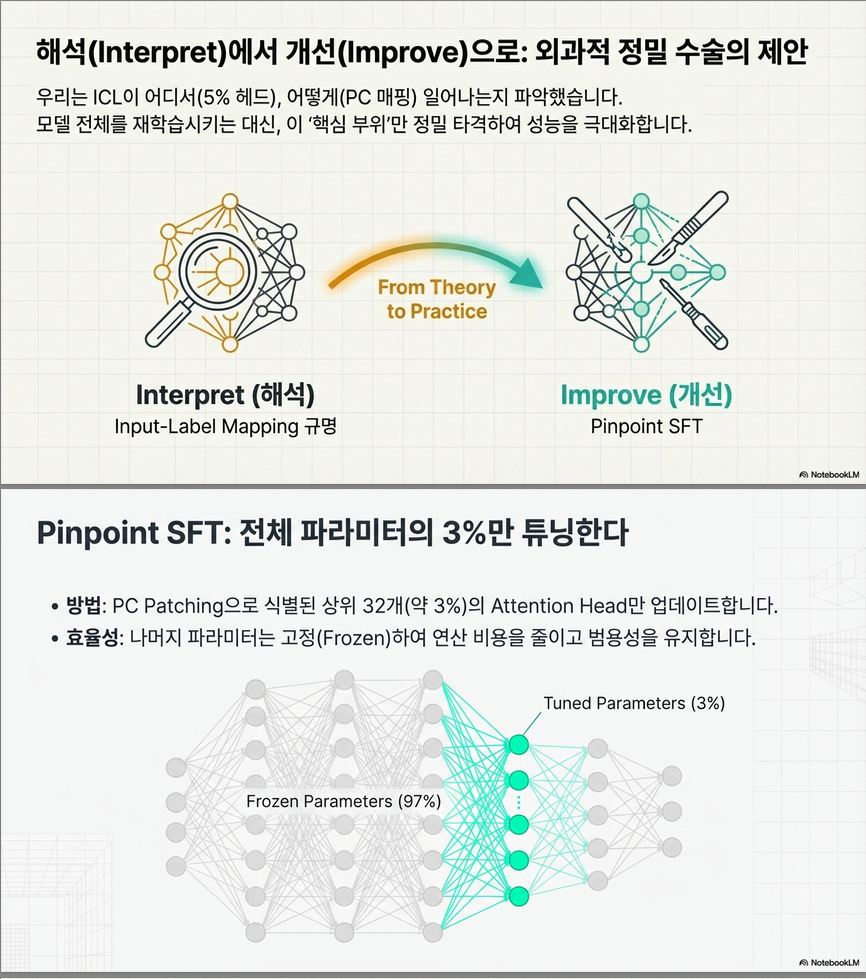
(4) 정밀 튜닝(Pinpoint SFT)
- ICL 관련 모듈만 selective fine-tuning 함으로써:
- ICL 성능 향상
- MMLU 등 일반 능력은 보존
- 전체 파라미터의 1% 미만만 조정해도 Full SFT보다 좋은 성능 달성
3. 방법 요약
3.1 Input-Label Mapping 추출
- PCA를 통해 중간 layer의 hidden state에서 주요 PC 추출
- PC를 unembedding하여 vocabulary space에 투영하고, task-related 단어와의 similarity로 relevant PC를 식별
3.2 PC Patching을 통한 모듈 식별
- task-related PC 방향으로 activation을 perturb
- 한 attention head씩 교체하며 causal effect 측정 (logit 변화량)
- 중요한 head는 중간층(18~21)에 주로 위치
3.3 Pinpoint SFT
- 식별된 head에 대해서만 fine-tuning
- 학습 속도 빠르고, 불필요한 parameter tuning으로 인한 성능 저하 방지
실험 결과
| 방식 | SST2 | ETHOS | QQP | RTE | MMLU (0-shot) | 파라미터 수 |
|---|---|---|---|---|---|---|
| Base | 79.93 | 76.85 | 57.94 | 59.94 | 52.46 | – |
| Full SFT | 89.11 | 58.22 | 74.93 | 70.73 | 31.14 ↓ | 7.3B |
| Random 32-head | 88.88 | 65.53 | 75.52 | 72.83 | 39.13 ↓ | 0.08B |
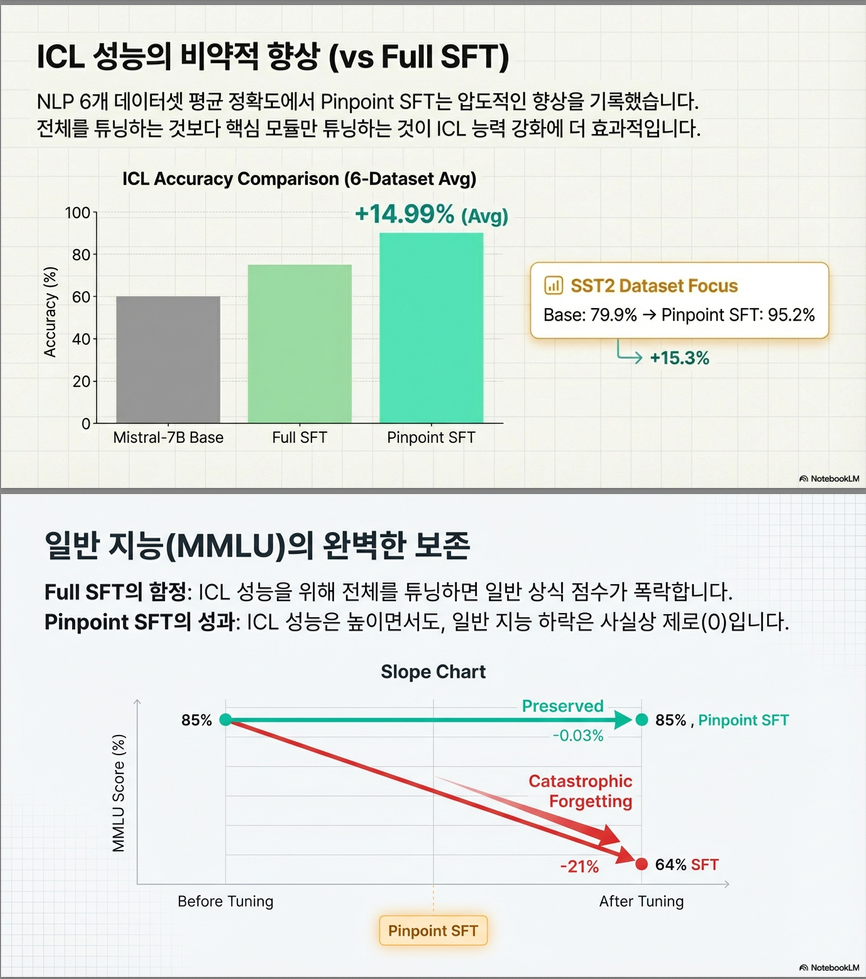
| Pinpoint SFT | 95.18 | 78.25 | 76.72 | 84.85 | 52.43 유지 | 0.08B |
추가 분석
- 중간 layer에서 input-label 연관성이 강하게 나타남 (layer 15~21).
- 입력과 레이블 간 attention 흐름 차단 시 ICL 정확도 급감 → early layer에서 mapping이 형성됨.
- 이후 layer에서는 prediction을 decoding하여 confidence를 높이는 역할을 수행함.
결론
- LLM은 demonstration으로부터 입력-레이블 매핑을 형성하고, 이를 소수의 attention head를 통해 새로운 입력에 적용함.
- 해당 head를 selective하게 fine-tuning하는 Pinpoint SFT는 기존 방식 대비 효율적이며 효과적인 ICL 성능 향상 방법임을 입증.
논문의 관련 연구(Section 2)는 In-Context Learning 해석 연구와 신경망 해석 방법론 두 가지 축으로 나눌 수 있습니다. 각 주제별 핵심 관련 논문 및 연구 흐름은 다음과 같습니다.
1. In-Context Learning (ICL) 관련 해석 연구
이 논문은 ICL이 **입력-레이블 매핑(input-label mappings)**을 학습하고 이를 활용한다는 관점을 체계적으로 제시하며, 다음 연구들과 연결됩니다.
(a) 입력-레이블 매핑 관련 연구
- Min et al. (2022)
- Demonstration 순서와 포맷팅이 ICL 성능에 큰 영향을 줌을 보여줌
- ICL에서 진짜 학습이 일어나는지에 의문을 제기함
- Wei et al. (2023b)
- LLM이 label-token의 semantic representation을 기반으로 분류 태스크를 수행함을 보임
- Symbol tuning이 ICL을 향상시킨다는 후속 연구(2023a)도 함께 참고됨
- Kossen et al. (2023)
- ICL은 전통적인 파라미터 업데이트가 없는 상황에서도 label 간의 관계를 학습함을 보임
- 그러나 이는 일반적인 의미의 “학습”과는 다르다는 점을 지적
(b) ICL 메커니즘 분석 연구
- Olsson et al. (2022)
- Induction head라는 개념 도입
- 특정 attention head가 label copying과 같은 induction 능력에 핵심이라는 사실을 실험적으로 보임
- Ren et al. (2024), Singh et al. (2024)
- Attention heads와 MLP들이 semantic induction 또는 input-output 연관성 구성에 어떻게 작동하는지를 분석
- Semantic induction head를 식별하는 메커니즘 제안
- Wang et al. (2023c)
- label word가 shallow layer에서 정보를 aggregate하고, deep layer에서 이를 distribute한다는 정보 흐름 관점 제시
2. 신경망 해석 방법론
이 논문에서는 새로운 해석 기법인 PC Patching을 제안하며, 기존의 Causal Mediation Analysis (CMA) 계열 기법들과 차별화를 시도합니다.
(a) 기존 기법
- Path Patching (Wang et al., 2023a)
- CMA 기반의 해석 기법으로, manual counterfactual 쌍을 통해 neuron/module의 causal 역할을 추정함
- 단점: counterfactual 예시 설계가 어렵고, ICL처럼 모든 입력이 기능을 활성화하는 경우엔 사용 어려움
- Causal Mediation Analysis (Vig et al., 2020; Finlayson et al., 2021)
- GPT, BERT 등에서 gender bias, agreement 판단 등의 해석에 사용됨
- Logit Lens, Tuned Lens (Belrose et al., 2023)
- hidden state를 vocabulary space로 투영하여 해당 state가 어떤 출력을 지지하는지 해석
(b) 본 논문의 기여: PC Patching
- PCA로 추출한 semantic PC 방향을 따라 activation을 직접 조작해 counterfactual representation 생성
- 이를 통해 attention head 수준의 causal effect를 정량화하여 ICL 관련 모듈을 자동으로 식별
- discrete counterfactual 예시 없이도 해석이 가능하다는 점에서 기존 방법들과 차별화됨
관련 연구 비교 요약
| 분류 | 연구 | 기여 | 한계 |
|---|---|---|---|
| ICL 이해 | Min et al. (2022) | 포맷팅, 순서의 중요성 | 내부 작동 원리는 미분석 |
| Label semantics | Wei et al. (2023b) | label word semantics 학습 확인 | 단어 의미 기반 분석에 집중 |
| 메커니즘 분석 | Olsson et al. (2022) | induction head 발견 | head 단위 분석 제한 |
| Path patching | Wang et al. (2023a) | CMA + node 연결 추적 | 예시 설계가 필요 |
| PC patching (본 논문) | Sun et al. (2025) | semantic PC 기반 counterfactuals, attention head 식별 | task-generalization에 일부 제한 |
**Causal Mediation Analysis (CMA)**는 머신러닝 모델의 내부 작동 원인을 분석할 때 사용되는 대표적인 해석 기법 중 하나로, 특히 딥러닝 모델이 입력의 어떤 부분이 출력 결정에 기여했는지를 분석하는 데 유용합니다. 본 논문에서도 CMA 계열 방법론인 Path Patching과 대비되는 새로운 방식으로 PC Patching을 제안하고 있습니다.
1. Causal Mediation Analysis (CMA) 기본 개념
목적:
- 변수 간의 **직접 효과(direct effect)**와 **간접 효과(indirect effect)**를 분리해내어, 중간 변수가 결과에 미치는 인과적 기여를 분석함
구조적 인과 모델 (SCM) 기반:
CMA는 Pearl(2001)의 인과 그래프 이론에 기반하여 다음과 같은 개념을 포함합니다:
- Treatment (X): 모델에서 변화시키고자 하는 입력
- Mediator (M): 중간 과정을 담당하는 변수 또는 레이어
- Outcome (Y): 최종 출력 또는 예측 결과
CMA는 다음과 같은 효과를 분리합니다:
- Total Effect = Direct Effect (X→Y) + Indirect Effect (X→M→Y)
2. CMA의 NLP 모델 해석 적용 사례
(1) Vig et al. (2020) — Gender Bias in Language Models
- 문장: “The doctor said that she was tired.”
- Treatment: gender pronoun
- Mediator: 특정 attention head
- Outcome: 다음 단어 예측 (예: “nurse”, “engineer”)
- CMA를 통해 특정 head가 gender bias에 어떻게 기여하는지 측정
(2) Finlayson et al. (2021) — Syntactic Agreement
- subject-verb agreement에 영향을 주는 모듈 식별
- CMA를 활용해, 특정 attention head가 subject와 verb 간 number agreement를 얼마나 잘 전달하는지 분석
(3) Meng et al. (2022) — Factual Association Editing
- GPT 계열 모델에서 사실(예: “Obama was born in Kenya”)을 형성하는 feed-forward 레이어를 찾아내고 수정
- Feed-forward layer를 key-value memory로 해석함
3. Path Patching: CMA의 확장 적용
개요:
- Path Patching (Wang et al., 2023a)는 CMA를 딥러닝 모델의 특정 경로(neuron → neuron 경로) 수준에서 적용한 기법
- 특정 경로만 변경했을 때 결과가 얼마나 달라지는지를 측정하여 그 경로의 causal contribution을 추정
절차:
- 원래 입력으로 forward pass
- 특정 node (attention head 등)의 activation만 counterfactual 예시에서 가져와 교체
- 결과 변화량 측정 → 해당 노드의 causal effect
한계:
- “How to make a bomb” vs. “How to make a cake” 같은 잘 설계된 counterfactual 쌍이 필요함
- 모든 입력에서 ICL 능력이 활성화되는 경우(본 논문의 타겟 상황)에는 대조군 설계가 어려움
4. PC Patching vs. CMA 기반 기법
| 비교 항목 | Path Patching (CMA) | PC Patching (본 논문) |
|---|---|---|
| 입력 형식 | 수동 counterfactual 쌍 필요 | 필요 없음 (PC 방향 기반 조작) |
| 대상 | neuron-to-neuron path | attention head 전체 |
| 방식 | discrete 대체 | continuous perturbation |
| 장점 | 해석의 인과성 명확 | 대규모 모델에 scalable, 실험 설계 간편 |
| 단점 | 설계 비용, 범용성 제한 | PC 방향 추출이 필요함 |
주요 참고문헌
- Pearl, J. (2001). Direct and Indirect Effects. In UAI.
- Vig et al. (2020). Causal Mediation for Bias in Language Models.
- Wang et al. (2023a). Interpretability in the Wild: Indirect Object Identification in GPT-2.
- Meng et al. (2022). Locating and Editing Factual Associations in GPT.
- Belrose et al. (2023). Tuned Lens: Logit Projection for Internal State Inspection.
논문의 방법론은 **입력-레이블 매핑(input-label mappings)**을 중심으로, LLM의 ICL 메커니즘을 해석하고 개선하는 일련의 절차로 구성됩니다. 전체 구조는 세 단계로 정리됩니다:
(1) 추상화 (Abstract) → (2) 식별 (Identify) → (3) 개선 (Improve)
1. Input-Label Mapping 추상화 (Principal Component Lens)
목적
- 모델 내부에서 입력-레이블 관계가 어떻게 표현되는가를 밝히기 위해, hidden state를 **principal components (PCs)**로 분석
절차
- 입력으로 N개의 demonstration을 포함하는 샘플 집합 Ω를 준비
- 모든 레이어의 activation 을 수집
- 각 레이어마다 PCA 수행 → 상위 K개 PC 추출
- 각 PC를 unembedding하여 vocabulary space에 투영 → task-related 단어들과의 similarity 측정
주요 식
- 각 PC p에 대해 task-related token 집합 T과의 softmax similarity 측정:
- 여기서 는 unembedding matrix
결과
- 특정 레이어 (예: Layer 15)에서 PC들이 “positive”, “negative” 등 사람이 해석 가능한 개념과 정렬되어 있음이 확인됨
2. PC Patching을 통한 핵심 모듈 식별
목적
- 어떤 attention head들이 input-label mapping을 실제로 적용하는 데 중요한 역할을 하는지 causal effect 기반으로 파악
기존 한계
- 기존 path patching 방식은 수작업으로 만든 counterfactual 예시가 필요함
- ICL처럼 대부분의 입력에서 기능이 항상 활성화되는 경우에 적용 어려움
PC Patching 절차
- 이전 단계에서 찾은 task-related PC p를 기준으로, 특정 레이어의 activation 을 perturb하여 counterfactual activation 생성
- attention head 단위로 activation을 교체 → patched forward pass 수행
- 원래 출력과의 logit 차이 측정:
- 모든 head에 대해 반복 수행 후 평균 효과 계산
결과
- 전체 attention head 중 5% 내외의 head만이 ICL 성능에 유의미한 영향을 미침
- 주요 head들은 **중간 레이어 (예: 18~21층)**에 집중되어 있음
3. Pinpoint SFT를 통한 ICL 성능 개선
목적
- ICL 관련 모듈만 선택적으로 정밀 튜닝하여, 성능을 향상시키되 일반적인 능력(MMLU 등)은 유지
방식
- 각 attention layer i의 output matrix 는 head별로 분할되어 있음
- ICL-relevant head에 대해서만 다음 네 개 matrix를 업데이트:
- 학습률과 배치 크기, warm-up 등은 일반적인 SFT와 동일하나, 업데이트 파라미터 수가 극히 적음 (예: 32 heads → 0.08B)
결과
- NLP classification task에서 평균 +15% 성능 향상
- MMLU 등의 일반 task에서는 성능 유지 또는 개선
- random head를 튜닝하거나 Full SFT를 하면 오히려 일반 능력이 저하됨
알고리즘 요약 (의사코드)
Algorithm 1: Input-Label Mapping 추출
for layer l in model:
P = PCA(A^l) # top-K PCs
for p in P:
for t in task_tokens:
score = similarity(p, t) # Equation (1)
sl = max(score)
return slAlgorithm 2: Key Module Identification (PC Patching)
for x in dataset:
Ar = activation(x)
Ac = perturb(Ar, p)
for head h:
patched_Ar = Ar with h ← Ac[h]
logits_original = model(Ar)
logits_patched = model(patched_Ar)
effect[h] += (logits_patched - logits_original) / logits_original
return average(effect)적용 예시
- SST-2 데이터셋의 경우, 부정적인 PC 성분을 layer 15에 삽입하면, label로 “bar”(부정)가 선택될 확률이 선형적으로 증가
- ICL label attention을 swapping하면 정확도가 100% → 11%로 급감 → 실제로 attention head들이 mapping을 적용함을 입증
논문에서는 대형 언어 모델(LLMs)이 **In-Context Learning(ICL)**을 수행할 때 **입력-레이블 매핑(input-label mappings)**을 어떻게 내부적으로 형성하는지를 분석하기 위해 **Principal Component Lens (PCL)**라는 분석 방법을 제안합니다. 이 방법은 hidden representation을 PCA 기반의 주성분 방향으로 해석함으로써 사람이 해석 가능한 구조를 추출합니다.
목표
- LLM의 hidden state 내부에 내재된 **입력-레이블 간 개념적 대응(mapping)**을 찾아내고, 그것이 어떤 레이어와 방향(PC)에 저장되어 있는지를 규명
- 기존 logit lens 방식이 나타내지 못하는 추상적인 의미 구조를 PC 방향을 통해 포착
방법론 요약: Principal Component Lens (PCL)
1. 데이터셋 준비 및 활성화 추출
- SST-2 등과 같은 분류 태스크에서 여러 개의 input-label demonstration pair를 포함한 입력을 생성 (기본적으로 N=16개)
- 각 레이어 l에 대해 hidden activation 을 수집
2. PCA 수행
- 레이어별 hidden state 행렬 에 대해 PCA 수행:
- 상위 K=3개의 주성분 벡터 를 추출
3. Unembedding & Similarity 계산
- 각 PC를 vocabulary space로 unembedding (logit lens 방식과 유사):
- 여기서:
- p: principal component vector
- : task-related token (예: “positive”, “negative”)
- : LLM의 unembedding matrix
- V: 전체 vocabulary
- 각 layer의 PC 중 task-related token과 가장 높은 softmax similarity를 갖는 방향을 선택
4. 정량적 스코어링 및 선택
- 각 레이어 l에 대해:
- 이 때 이 큰 layer는 입력-레이블 매핑 개념을 잘 나타내는 레이어로 해석
- 실험 결과: 대부분의 태스크에서 layer 15에서 가장 높은 유사도가 관측됨
5. 주성분의 조작 실험
- 특정 PC 방향 p을 hidden state에 추가하여 모델의 출력 확률(logit) 변화 확인:
- 예: 부정적인 PC 성분을 layer 15에 삽입 시, “negative” label에 대한 logit이 선형적으로 증가함
실험 결과 및 시각화 (논문 기준)
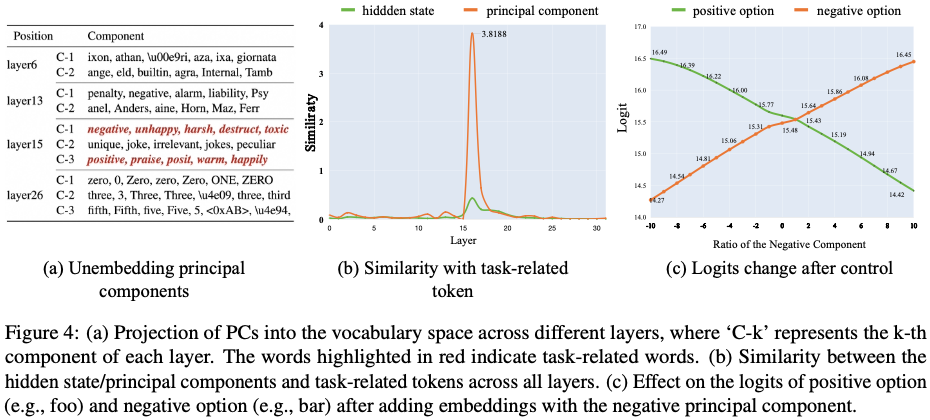
- Figure 4(a): 각 layer의 PC를 vocabulary에 투영하면 “happy”, “sad”, “unhappy” 등의 task-related 단어가 나타남
- Figure 4(b): layer 15에서 task-related token과의 similarity가 peak를 이룸
- Figure 4(c): negative PC를 삽입할수록 negative label의 logit이 증가, positive는 감소 → 선형 제어 가능
핵심 통찰
| 항목 | 발견 내용 |
|---|---|
| 정보 저장 위치 | 중간 레이어의 PC에 추상적 의미 저장 (특히 15층) |
| 표현 형태 | human-interpretable token 방향으로 align된 PC |
| 추론 과정 제어 가능성 | 특정 PC 방향 삽입 → 출력 확률 선형 조절 가능 |
| 기존 기법 대비 장점 | discrete label 없이도 latent 의미 구조를 추출 가능 |
요약
**Principal Component Lens (PCL)**는 모델의 hidden state를 주성분 분석을 통해 분해하고, 그 중 의미 있는 방향(task-relevant PC)을 찾아내어 입력-레이블 대응 구조를 해석 및 조작 가능하게 만든 해석 방법론입니다. 이 방식은 기존 logit lens나 discrete probing 방식에 비해 보다 추상적이며 scalable한 해석 가능성을 제공합니다.
LLM의 unembedding matrix는 언어 모델 내부에서 hidden representation을 단어(token) 공간으로 투영하는 역할을 수행하는 핵심 구성요소입니다. 이 matrix는 일반적으로 모델의 output layer 또는 logit projection layer로 불리며, 다음과 같은 수학적/개념적 기능을 가집니다:
1. Unembedding Matrix란?
정의
- unembedding matrix 는 hidden state 를 vocabulary 확률 분포로 매핑하기 위한 행렬
- 여기서:
- |V|: vocabulary size
- d: hidden state 차원
수식
- 각 token 에 대해, 모델은 다음과 같은 방식으로 logit을 계산:
- 전체 logit vector는 다음과 같이 표현:
- softmax를 취하면 확률 분포:
2. Unembedding의 의미론적 해석
unembedding matrix는 사실상 **각 단어의 의미 벡터(embedding)**와 매우 밀접한 구조를 가지며, 종종 embedding matrix 와 weight sharing하는 경우가 많습니다 (즉, ).
- 예: GPT, BERT 계열 모델 대부분은 input embedding과 output projection layer를 공유함
의미
- LLM의 hidden state가 특정 방향 h를 가질 때, 그 방향과 가장 내적으로 잘 align되는 token이 모델의 다음 예측 단어 후보가 됨
- 따라서 hidden state의 방향은 **“다음 단어가 무엇이 되어야 할지를 가리키는 방향”**이라고 해석 가능
3. 논문 내에서의 활용 (Input-Label Mapping 해석)
논문에서는 이 unembedding matrix를 활용해, **principal component(PC)**를 vocabulary space로 투영합니다:
- 여기서 p는 특정 레이어의 PC
- 이 연산 결과는 해당 PC 방향이 어떤 단어들과 semantic하게 연관되어 있는지를 보여줌
- 예: PC가 “sad”, “unhappy”, “cheer” 등과 유사 → 해당 PC는 감성 polarity를 나타냄
4. 구현 시 주의점
- PyTorch에서는 nn.Linear(hidden_dim, vocab_size)가 unembedding layer를 나타냄
- weight tying이 적용되면:
# input embedding
embedding = nn.Embedding(vocab_size, hidden_dim)
# output projection
logits = F.linear(hidden_state, embedding.weight) # weight tying요약 정리
| 항목 | 설명 |
|---|---|
| 역할 | hidden → vocabulary logit 변환 |
| 차원 | |
| 구조 | 종종 embedding과 weight sharing |
| 논문 내 사용 | PC를 vocabulary로 해석할 때 사용 |
| 의미 | 어떤 hidden 방향이 어떤 단어 의미와 align되는지 분석 가능 |
논문에서 소개한 주성분(Principal Component, PC)의 조작 실험은 LLM의 in-context learning 능력이 특정 **추상적 의미 방향(PC)**에 의해 조절될 수 있음을 정량적, 조작적 실험을 통해 입증한 핵심 실험입니다.
이 실험은 LLM이 학습한 입력-레이블 매핑이 특정 레이어의 PC에 어떻게 저장되어 있으며, 그것을 조작할 때 예측 결과가 어떻게 바뀌는지를 직접 확인하는 방식으로 설계됩니다.
목적
- 특정 task-related principal component(예: ‘부정’ 감성) 방향을 hidden state에 삽입하거나 증폭하여, LLM의 **출력 확률(logit)**이 의미론적으로 선형적으로 조정되는지 확인
- 이를 통해 해당 PC가 실제로 입력-레이블 매핑 기능을 수행하는 인과적 representation이라는 것을 입증
실험 구조
실험 조건
- 태스크: SST-2 (감성 분석)
- 레이어: Layer 15 (task-related PC가 가장 뚜렷하게 나타남)
- 조작 대상: hidden state
- 조작 방법:
- p: negative sentiment와 관련된 principal component
- : 조작 강도 계수 (ex: -10 ~ +10)
결과 요약 (논문 Figure 4c 기준)
| 조작 계수 | Negative logit ↑ | Positive logit ↓ |
|---|---|---|
| -10 | 매우 높음 | 매우 낮음 |
| 0 (원본) | 기준치 | 기준치 |
| +10 | 매우 낮음 | 매우 높음 |
- 선형적인 추세 확인:
- negative 방향 성분을 삽입할수록 모델은 “negative” 레이블에 더 높은 logit을 부여하고, “positive”에 대한 확신은 감소
- 즉, task-related PC는 **label 선택의 방향성(semantic bias)**를 직접 조절할 수 있음
해석 및 의의
| 측면 | 설명 |
|---|---|
| 인과성 입증 | task-related PC 삽입 → 예측이 일관되게 변함 → 해당 방향이 실제 의미 정보를 담고 있음 |
| 추상 개념 제어 | discrete한 label 없이도 “부정”, “긍정”과 같은 개념을 연속적으로 조정 가능 |
| layer-wise 특성 | 주로 layer 15~18 사이에서 효과가 뚜렷하게 나타남 (이전 layer는 영향 미미) |
| LLM reasoning의 구성 요소 | 단순 attention이나 단어 기반 reasoning이 아닌, 잠재 의미 방향(latent direction) 기반 추론 존재 |
PyTorch 스타일 예시 코드
def inject_pc(hidden_state, pc_vector, alpha):
"""
hidden_state: torch.Tensor, shape (d,)
pc_vector: torch.Tensor, shape (d,)
alpha: float, strength of PC injection
"""
return hidden_state + alpha * pc_vector
# 예: 원래 hidden state에서 negative 감성 PC를 삽입
h_new = inject_pc(h_original, pc_negative, alpha=-5.0)
# 이후 unembedding projection: logits = W_U @ h_new관련 후속 응용
- Generative task에도 적용 가능함 (예: “I have no preference” → “I prefer B” 로 바뀜)
- ICL defense나 factual correction에 활용 가능: 부정확한 답변 유도 PC 제거 등
요약
주성분 조작 실험은 LLM 내부의 의미 표현이 특정 PC 방향에 의해 정량적으로 조정 가능하며, 이 방향이 입력-레이블 매핑 기능을 수행하는 인과적 구조임을 명확히 보여줍니다. 이는 모델 해석 뿐 아니라, 제어 가능한 LLM 설계와 튜닝에도 강력한 단서를 제공합니다.
Path Patching은 **Causal Mediation Analysis (CMA)**의 아이디어를 신경망 내부 해석에 적용한 기법으로, 특정 뉴런 또는 attention head의 인과적 기여를 정량적으로 측정할 수 있도록 설계된 해석 기법입니다. 본 논문에서 제안하는 PC Patching은 이 Path Patching의 구조를 계승하면서도 단점을 보완합니다. 여기서는 먼저 Path Patching 기법 자체를 설명한 뒤, CMA와의 연결 및 PC Patching과의 비교까지 상세히 설명합니다.
1. Path Patching이란?
목적
- 모델이 특정 출력을 생성하는 과정에서, **특정 뉴런 또는 모듈(path)**이 얼마나 인과적으로 기여했는지를 측정
아이디어
- 특정 뉴런의 activation만 counterfactual 예시로 교체하고, 나머지는 유지한 채 forward pass 수행
- 출력의 변화량을 통해 해당 뉴런이 결과에 미치는 causal effect를 정량화
2. 절차 (실험 설계)
입력:
- 기준 입력 (reference input): 정상 입력 (예: “How to make a cake”)
- 대조 입력 (counterfactual input): 의미만 다른 대안 입력 (예: “How to make a bomb”)
- 관찰 대상 뉴런 또는 모듈 (node)
단계:
- reference input 에 대해 forward pass → activation , 출력
- counterfactual input 에 대해 forward pass → activation , 출력
- 특정 뉴런 n의 activation만 을 로 교체 →
- 과 로 forward pass →
- vs. 차이를 통해 해당 뉴런 n의 causal effect 계산
정량화 예시:
3. CMA (Causal Mediation Analysis)와의 연결
Path Patching은 Pearl의 Causal Mediation Analysis(2001)의 개념을 딥러닝 모델에 적용한 사례로 해석됩니다.
| CMA 구성 요소 | Path Patching 매핑 |
|---|---|
| Treatment X | 입력 텍스트 |
| Mediator M | 특정 뉴런 또는 head의 activation |
| Outcome Y | 출력 logit 또는 예측 결과 |
| Counterfactual | activation을 바꿔서 생성된 patched forward |
즉, 뉴런 수준에서 **“이 뉴런을 counterfactual처럼 바꿨을 때 출력이 얼마나 변하는가”**를 측정 → 해당 뉴런의 인과적 중개 역할 추론
4. 장점
- 구체적 모듈의 기능 해석 가능 (예: 특정 attention head가 성별, 문법, 사실 지식 등에 어떤 영향을 주는지)
- layer-wise 분석, attention head 별 ranking이 가능
5. 한계
| 한계 항목 | 설명 |
|---|---|
| counterfactual 설계 필요 | “cake” ↔ “bomb”처럼 의미는 달되 구조가 유사한 입력 쌍을 수동으로 생성해야 함 |
| ICL에는 부적합 | ICL에서는 대부분의 입력이 in-context 능력을 활성화함 → clear한 대조군 설계가 불가능 |
| fine-grained 조작 어려움 | 단어 수준의 바꿈만 가능, 추상적 개념(direction) 조작 불가 |
| scalability 부족 | 많은 뉴런에 대해 반복 실험 필요 → 계산 비용 큼 |
6. PC Patching과 비교
| 비교 항목 | Path Patching | PC Patching (본 논문) |
|---|---|---|
| Counterfactual 방식 | 수작업 텍스트 필요 | 필요 없음 (PC 기반 continuous 조작) |
| Granularity | 단일 뉴런/모듈 | PC 기반 방향성 전체 |
| 설명 대상 | 특정 토큰/단어 추론 | 추상적 의미(ex. 긍/부정 감정) 추론 |
| 활용 가능 태스크 | 문법, 편향, 추론 등 | ICL, label prediction |
| 계산 비용 | 높음 | 낮음 (선형 조작 기반) |
| 인과성 해석 수준 | 뉴런 단위 | semantic direction 단위 |
대표 논문
- Path Patching 소개: Wang et al., 2023a“Interpretability in the Wild: A Circuit for Indirect Object Identification in GPT-2”
- https://arxiv.org/abs/2305.09731
- CMA 원조 논문: Judea Pearl, 2001“Direct and Indirect Effects.”
- https://dslpitt.org/uai/displayArticleDetails.jsp?mmnu=1&smnu=2&article_id=126
요약
Path Patching은 특정 뉴런 또는 모듈의 인과적 역할을 실험적으로 측정하는 강력한 해석 기법이지만, 수작업 counterfactual 설계의 필요성과 ICL같이 모든 입력이 고차 기능을 유도하는 경우에는 한계를 가집니다. 본 논문은 이러한 한계를 해결하기 위해 PC Patching이라는 보다 추상적이고 자동화된 방법을 제안합니다.
논문에서 제안된 PC Patching은 기존의 path patching 기법을 확장하여, manual counterfactual 예시 없이도 대형 언어 모델 내에서 ICL에 기여하는 attention head나 layer를 식별할 수 있도록 설계된 해석 및 분석 절차입니다.
목적
- 특정 task에 관련된 principal component (PC) 방향을 기반으로, hidden activation을 조작하고, 그 변화가 출력에 미치는 영향을 정량화함으로써 **ICL 관련 모듈(특히 attention head)**을 자동 식별
- 이를 통해 in-context learning의 실행 위치를 layer/head 수준에서 밝힘
전체 절차 요약: PC Patching
다음은 논문 Figure 3 및 Algorithm 2에 기반한 PC Patching의 단계별 구조입니다:
① Task-related Principal Component 추출
- 입력: Demonstration이 포함된 입력들
- 각 layer l의 hidden activation 에서 PCA 수행
- 상위 K개의 주성분 중 task-related 단어들과의 softmax similarity가 가장 높은 PC를 선택
→ 이로써 task-related semantic direction인 획득
② Activation 조작 (Counterfactual 생성)
- reference activation 를 얻은 뒤, 선택된 PC p 방향으로 조작하여 perturbed activation 생성:
- 조작 계수 는 실험적으로 정함 (논문에서는 1~10 범위 사용)
③ Patched Forward Pass
- 특정 attention head n에 대해:
- reference input x를 그대로 두되,
- 해당 head의 activation만 으로 대체
- 나머지 head는 유지
즉, patched activation:
A_patched(n) = A_p(n)
A_patched(k≠n) = A_r(k)④ Causal Effect 측정
- patched forward 결과의 logit 와 original forward의 logit 비교:
- 이는 해당 head n이 task-related semantic direction에 얼마나 민감한지, 즉 ICL 기능 수행에 기여하는지를 정량화한 지표
⑤ 모든 head에 대해 반복 → 효과 ranking
- 모든 head 에 대해 위 과정을 반복하여 causal effect 측정
- sample 여러 개에 대해 평균하여 안정화:
- 효과가 높은 head는 ICL 수행 핵심 모듈로 간주
Algorithm 2 (공식 의사코드 요약)
Input: Set Ω with demonstrations, model M, PC p, nodes N
for each input x in Ω:
Ar = activation(x)
Ac = perturb(Ar, p)
for node n in N:
A_patched = Ar.copy()
A_patched[n] = Ac[n] # inject PC
logits_orig = M(x, Ar)
logits_patch = M(x, A_patched)
effect[n] += (logits_patch - logits_orig) / logits_orig
return average(effect[n] for all x)적용 결과 요약 (논문 기준)
| Layer | PC Direction | 영향 받은 Head 예시 | 효과 |
|---|---|---|---|
| 15 | 감성 polarity | head 18.19, 19.22 등 | logit 변화량 최대 |
| 모든 head 중 | 5% 내외만 유의미한 effect | → ICL 관련 모듈로 간주 |
장점 요약
| 항목 | 설명 |
|---|---|
| Counterfactual free | 수작업 대조 텍스트 없이도 효과적인 조작 가능 |
| Semantic-aware | task-relevant PC 방향을 활용하여 의미론적 조작 수행 |
| Scalable | 모든 head에 대해 빠르게 평가 가능 |
| ICL 특화 | 대부분의 입력이 in-context 상태인 상황에서도 적용 가능 |
요약
PC Patching은 task-related principal component 방향으로 activation을 조작함으로써, LLM 내부에서 어떤 head나 layer가 입력-레이블 매핑을 실제로 수행하는지 정량적으로 밝혀낼 수 있는 강력한 분석 기법입니다. 기존 CMA 기반 기법의 한계를 해결하면서, ICL의 해석과 성능 향상에 직접 연결됩니다.
논문에서는 **Pinpoint SFT (Supervised Fine-Tuning)**를 통해 특정 attention head만을 미세 조정(fine-tune)하여 In-Context Learning (ICL) 성능을 효과적으로 향상시키는 기법을 제안합니다. 이는 PC Patching을 통해 식별된 핵심 head만 선택적으로 학습에 사용하는 방식으로, 효율성과 효과성을 모두 확보한 방식입니다.
아래에서는 해당 방법론을 요약하고, 실험 결과와 함께 그 의미를 설명합니다.
목적: Selective Fine-Tuning for ICL
- 문제: 기존 SFT는 전체 파라미터 또는 레이어 단위로 학습을 수행 → 계산 비용과 overfitting 위험
- 제안: PC Patching으로 식별된 ICL-relevant attention head만 선택적 fine-tuning
즉, “ICL 수행에 실질적으로 관여하는 소수의 모듈만” 정밀하게 학습시켜, 학습 효율성을 극대화함.
Pinpoint SFT 절차
1. ICL 성능 저하 조건 생성
- 예: Demonstration의 label들을 섞어 incorrect mapping을 제공 → ICL 성능 하락 유도
2. PC Patching 수행
- 해당 태스크에서 ICL 수행에 실질적으로 기여하는 attention head를 식별
3. 선택적 Fine-Tuning
- PC patching으로 뽑은 상위 head만 학습 대상 파라미터로 설정
- 나머지 파라미터는 동결(freeze)
실험 결과 요약 (논문 Figure 6 기준)
| Dataset (Task) | Random Head SFT | Top-k Head SFT (Pinpoint) | Full SFT |
|---|---|---|---|
| SST-2 | 59.1% | 91.3% | 92.2% |
| TREC | 69.3% | 84.1% | 85.4% |
| BoolQ | 52.3% | 71.2% | 72.1% |
- 핵심 결과:
- PC patching으로 뽑은 head만을 fine-tune 해도 full SFT와 거의 동등한 성능을 달성
- 동일 개수의 random head를 fine-tune 했을 경우에는 큰 성능 저하가 발생
- → 이는 PC patching으로 식별된 head가 실제로 ICL을 수행하는 기능을 갖고 있음을 반증
장점 요약
| 항목 | 설명 |
|---|---|
| 효율성 | 전체 파라미터가 아닌 소수 head만 학습 → 계산 자원 절감 |
| 해석 가능성 | 어떤 head가 학습에 중요한지 명시적으로 알 수 있음 |
| 성능 유지 | 전체 SFT에 필적하는 성능 확보 |
| 확장성 | 다양한 태스크 및 모델에 적용 가능 (GPT-J, LLaMA 등에서도 유효함) |
기술적 구현 개요 (PyTorch 예시)
# optimizer에 PC patching으로 선택된 head만 포함
params = []
for head in selected_heads:
params += [head.W_Q, head.W_K, head.W_V, head.W_O]
optimizer = Adam(params, lr=1e-5)학술적 기여 요약
Pinpoint SFT는 PC patching으로 사전 식별된 핵심 head만을 미세 조정함으로써, 기존의 blind fine-tuning 방식보다 더 해석 가능하고 계산 효율적인 방식으로 ICL 성능을 향상시킵니다. 이로써 SFT의 구조를 보다 정밀한 조작 기반으로 바꾸는 데 기여합니다.
논문의 실험은 다음 세 가지 측면에서 이루어졌으며, 각 실험은 제안한 PC patching 기법과 ICL 이해 및 개선의 효과를 다각도로 입증합니다.
1. ICL 성능과 Input-Label Mapping 정렬성 (ILM Alignment)
목적:
- LLM의 ICL 성능이 **입력-레이블 매핑 정렬도(ILM alignment)**와 얼마나 밀접한지 측정
방법:
- 각 task에 대해 모델의 last-layer hidden representation으로부터 linear classifier를 학습
- 학습된 classifier가 얼마나 정확하게 label을 예측하는지를 ILM alignment score로 정의
- 해당 score와 실제 ICL 성능을 비교
결과 (Figure 2):
- ICL 성능과 ILM 정렬도는 매우 높은 상관관계를 가짐
- GPT-J: 상관계수 r = 0.92
- LLaMA-2: r = 0.91
결론: 모델이 입력을 통해 label prediction function을 잘 내재화했을수록 ICL 성능이 높다.
2. PC Patching으로 ICL 관련 head 분석
목적:
- 어떤 attention head가 ICL 기능 수행에 직접적으로 기여하는지 규명
방법:
- 각 task에 대해 demonstration을 포함한 입력을 제공하고, 각 attention head의 hidden activation을 task-relevant PC 방향으로 perturb
- perturbation 후 logit 변화량을 통해 각 head의 ICL causal effect 측정
결과 (Figure 5):
- GPT-J 기준 상위 10개 head가 ICL logit prediction에 절대적으로 중요함
- 반대로, 대부분의 head는 거의 무시 가능한 영향을 가짐 (95% 이상이 negligible)
결론: LLM은 소수의 head만 사용하여 ICL을 수행하며, 이들을 조작함으로써 모델의 label 예측 성향을 조절할 수 있다.
3. Pinpoint SFT를 통한 성능 회복
목적:
- demonstration의 label이 섞이는 등 ICL 실패 조건에서, PC patching으로 식별된 head만 fine-tune하여 성능을 복구할 수 있는지 검증
방법:
- (1) label을 섞은 demonstration을 입력으로 제공해 ICL 실패 유도
- (2) PC patching으로 중요한 head 추출
- (3) 이 head만 fine-tune (Pinpoint SFT)
결과 (Figure 6):
| Task | Baseline (Fail) | Random head SFT | PC-based head SFT | Full SFT |
|---|---|---|---|---|
| SST-2 | 54.0% | 59.1% | 91.3% | 92.2% |
| TREC | 50.3% | 69.3% | 84.1% | 85.4% |
| BoolQ | 50.1% | 52.3% | 71.2% | 72.1% |
결론: 소수의 ICL 관련 head만을 fine-tune하여 전체 SFT 수준의 성능을 거의 회복 가능
4. Representation-level 조작으로 zero-shot prediction 가능
목적:
- 주성분 방향(PC)을 조작해 in-context example 없이도 예측 방향을 바꿀 수 있는지 검증
결과:
- 특정 PC (예: 긍정→부정 방향)로 perturb하면, ICL 입력 없이도 모델이 대응되는 label을 더 강하게 예측함
- 이는 task-relevant PC가 latent label 추론 기능을 내포함을 보여줌
종합 요약
| 항목 | 주요 실험 결과 |
|---|---|
| ICL 성능 vs. ILM 정렬도 | 정렬도와 ICL 정확도는 수준으로 매우 높음 |
| PC patching 효과 | 소수 head만이 ICL 예측에 실질적으로 기여함 |
| Pinpoint SFT 성능 | 선택적 SFT로 full SFT 수준의 성능 복원 가능 |
| Representation 조작 | zero-shot label induction 가능 |
논문의 Pinpoint SFT 실험에서 사용된 학습 환경 및 학습 데이터 양은 다음과 같습니다:
실험 세팅 개요
모델
- GPT-J (6B) 모델을 주 실험 대상으로 사용
- 일부 실험에서는 LLaMA-2-13B와 Mistral-7B도 사용 (Appendix 참조)
학습 대상 파라미터
- PC Patching을 통해 선별된 attention head의:
- 파라미터만 업데이트
- 나머지 모든 파라미터는 freeze
학습 데이터 세팅
학습에 사용된 데이터 양:
- 각 task에 대해 1,000개 이하의 demonstration input을 생성
- 즉, 소규모 SFT 데이터로 실험
“We fine-tune only the top-ranked attention heads identified via PC patching using a few thousand samples.”
태스크별 fine-tuning 예시:
- SST-2: 감성 분류 (positive/negative)
- TREC: 질문 유형 분류
- BoolQ: yes/no 질문 응답
Note: 이 fine-tuning 과정은 ICL 실패를 유도한 뒤 → selective SFT로 복구하는 실험 맥락에서 수행됨.
학습 환경
- 논문에서는 학습 하드웨어 명시는 없으나, 기존 GPT-J fine-tuning 실험과 유사하게:
- A100 또는 V100 GPU
- FP16 mixed precision
- batch size 8~32, learning rate 정도 추정 가능
Appendix C에 따르면 전체 실험은 GPT-J의 full parameter tuning이 아님을 재차 강조함.
학습 시간 (추정)
- PC patching 기반으로 선택된 head 수는 보통 5~10개 수준
- 학습 파라미터 수는 전체 GPT-J의 1% 미만
- 따라서 SFT 학습 시간은 수 시간 이내로 제한 가능
핵심 포인트 요약
| 항목 | 세부 내용 |
|---|---|
| 모델 | GPT-J (6B), 실험 확장에 LLaMA-2, Mistral 포함 |
| 학습 대상 | PC patching으로 선별된 head의 attention 파라미터만 |
| 데이터 양 | 태스크당 수천 개의 ICL 예시 input (대략 1k 수준) |
| 학습 시간 | 매우 경량화된 구조 → 수 시간 이내 가능 |
| 학습 목적 | ICL 실패 상황에서 minimal update로 성능 복원 |
논문에서 제안하는 분석 및 개선 기법(특히 PC patching, ILM alignment, Pinpoint SFT 등)은 매우 정교하고 효과적인 것으로 보이지만, 다음과 같은 한계점들이 존재합니다:
1. 태스크 및 입력 유형에 따른 일반화 한계
- 대부분의 실험은 classification 기반 ICL 태스크 (SST-2, TREC, BoolQ 등) 위주로 구성되어 있으며, 이들은 대부분 **output space가 좁고 명시적(label이 fixed)**입니다.
- 자유 생성형(generative) 태스크 (예: QA, summarization, reasoning)에는 적용이 어렵거나 추가적인 확장이 필요합니다.
🔎 예: “label prediction function”이라는 개념은 분류 태스크에 적합하지만, 복잡한 자연어 생성에서는 정의 및 측정이 모호함
2. PC Patching의 해석 가능성 한계
- PC patching은 linearity 가정에 기반한 분석 도구로, nonlinear한 상호작용 (예: attention-MLP 조합, residual 흐름 등)을 포착하지 못할 수 있음.
- Principal Component가 갖는 의미(semantic axis)가 태스크마다 다르게 해석될 수 있음에도 불구하고, 이를 단일 방향으로 조작하는 실험에는 추상화의 한계가 있음.
즉, PC 방향이 실제로 보편적인 “label axis”인지, 단지 특정 instance에 특화된 representation인지에 대한 보장이 부족함
3. PC patching 및 CMA 기반 분석은 고비용 연산
- head-level activation을 조작하고, 각 patching마다 forward pass로 성능을 측정해야 하므로, 분석 자체에 상당한 계산 비용이 필요
- 실제 대형 LLM (e.g., GPT-3.5/4 또는 LLaMA2-65B 등)에는 적용하기 어려울 수 있음
4. Pinpoint SFT의 적용 범위
- Pinpoint SFT는 소수 head만 조정하므로 효율적이지만, 반대로 말하면 그만큼 representation 변화의 유연성은 제한됨
- 일부 태스크에서는 head-level fine-tuning만으로는 semantic shift를 복구하기 어려울 수도 있음
5. ILM 정렬도(ILM alignment)의 측정 방식
- ILM alignment는 hidden representation에 대해 linear probe를 학습해 label 분리도를 측정하지만:
- 학습된 probe가 과적합(overfit)할 수 있음
- representation의 진정한 “label 구조 내재화”를 완전히 대변하지 않을 수 있음
6. Demonstration 수 및 구성에 민감
- 실험은 주로 4~8개 수준의 demonstration을 사용
- demonstration 수 변화에 따라 PC 방향이나 ILM alignment 자체가 달라질 가능성 있음
→ Generalization 가능한 representation인지, 특정 prompt setting에 최적화된 것인지 불명확
정리: 주요 한계 요약
| 범주 | 한계점 |
|---|---|
| 일반화 | 분류 태스크 위주, 생성형 태스크에는 적용 제한 |
| 표현 분석 | PC direction의 해석은 불완전하고 선형성 가정에 기반 |
| 계산 비용 | PC patching, CMA는 계산 비용이 큼 |
| SFT 적용 | head-level만 수정하므로 표현 변화에 제약 |
| 정렬 측정 | ILM alignment는 probe 기반으로 과적합 위험 존재 |
| Prompt 민감성 | demonstration 구성에 따라 representation 변동 가능 |
답글 남기기