

이 논문은 LLM의 긴 context를 매우 짧은 “memory slot”으로 압축하는 방법인 ICAE (In-context Autoencoder) 를 제안한다. 핵심 아이디어는:
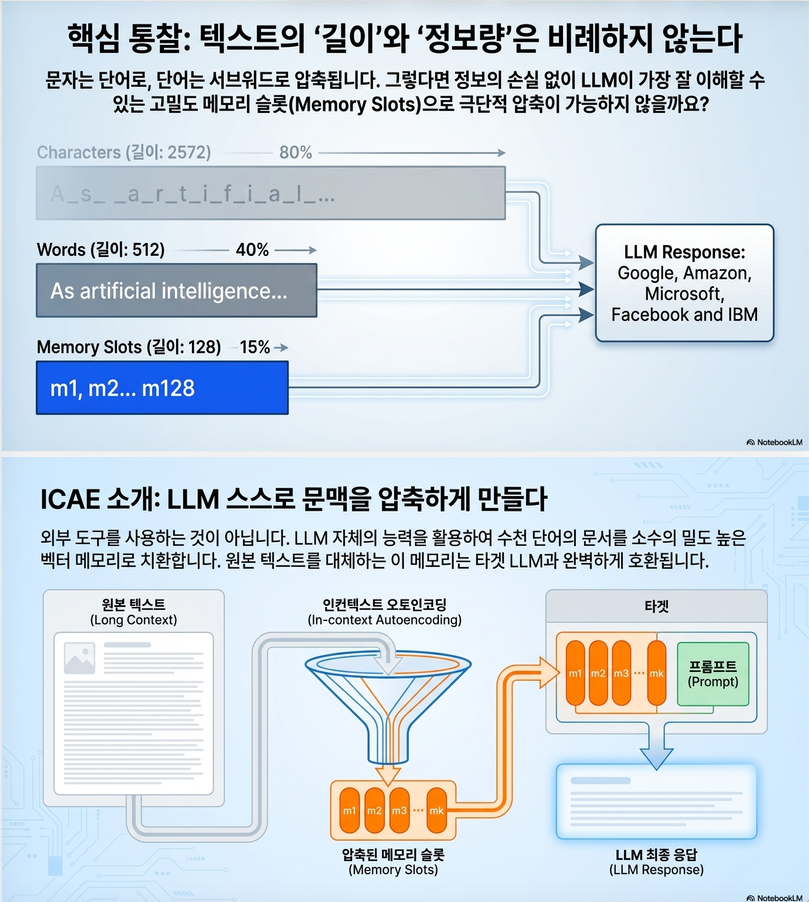
“원래 512-token context를, 예를 들어 128개의 latent memory slot으로 압축한 뒤, LLM이 이 compressed representation만 보고도 원래 context를 거의 복원하거나 질문에 답할 수 있게 하자.”
즉, 기존 long-context transformer처럼 attention 구조를 바꾸는 대신:
- context 자체를 압축
- 압축된 memory representation을 prompt처럼 사용
- inference latency와 KV cache 비용 감소
를 목표로 한다.
1. 핵심 문제의식
Transformer 기반 LLM은 self-attention 때문에 context length가 길어질수록:
- 계산량: O(n^2)
- KV cache 메모리 증가
- latency 증가
문제가 발생한다.
기존 연구는:
- Longformer
- Performer
- Compressive Transformer
- LongNet
등 attention 구조 자체를 수정했다.
반면 ICAE는 완전히 다른 접근:
“긴 텍스트를 compact latent memory로 바꾸자.”
2. 핵심 아이디어
논문의 가장 중요한 개념은 다음 그림이다.
- 원래 context:
- 512 tokens
- 압축 후:
- 128 memory slots
- 이후:
- LLM은 memory slots만 보고 QA/요약/추론 수행
즉:
이다.
논문은 이를 인간 working memory와 비슷한 관점으로 해석한다.
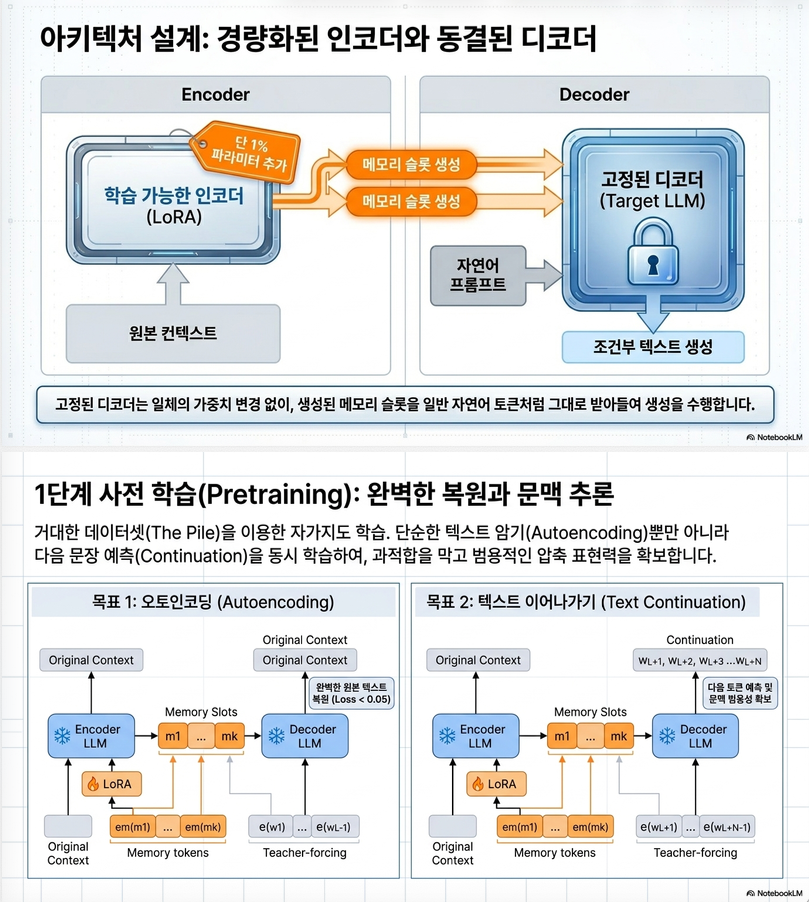
3. ICAE 구조
전체 구조
ICAE는 두 부분으로 구성된다.
| 구성 | 역할 |
|---|---|
| Encoder | 긴 context를 memory slot으로 압축 |
| Decoder | memory slot 기반으로 text 생성 |
특징은:
- Encoder:
- LoRA-adapted LLM
- Decoder:
- 원래 untouched LLM
이라는 점이다.
4. Encoder 동작 방식
입력 context:
뒤에 learnable memory token:
를 append한다.
즉 입력은:
이 된다.
이후 마지막 memory token hidden state를:
memory slot으로 사용한다.
5. 왜 LoRA encoder인가?
논문에서 매우 중요한 설계.
Encoder 전체를 새로 학습하지 않고:
- 기존 LLM 복사
- query/value projection에만 LoRA 적용
한다.
장점:
- parameter-efficient
- 약 1% 추가 parameter만 필요
- decoder LLM과 latent space alignment 쉬움
실제로:
- memory embedding
- LoRA adapter
만 추가한다.
6. Decoder 구조
Decoder는 원래 LLM 그대로 사용.
즉:
- compressed memory slot을 prefix처럼 conditioning
- 추가 prompt와 함께 사용
예:
[memory slots] + "What companies founded Partnership on AI?"→ 답 생성
7. 학습 목표 (가장 중요)
논문은 두 가지 pretraining objective를 사용한다.
7-1. Autoencoding Objective
핵심 목표:
memory slot만으로 원래 context를 reconstruct
즉:
loss:
이다.
7-2. Text Continuation Objective
논문은 단순 reconstruction만 하면 overfit될 수 있다고 본다.
그래서:
context -> memory -> next token prediction도 함께 학습한다.
즉:
여기서:
- o:
continuation text
이다.
7-3. 최종 pretraining loss
논문은 두 loss를 결합:
를 사용한다.
실험적으로:
이 가장 좋았다고 보고한다.
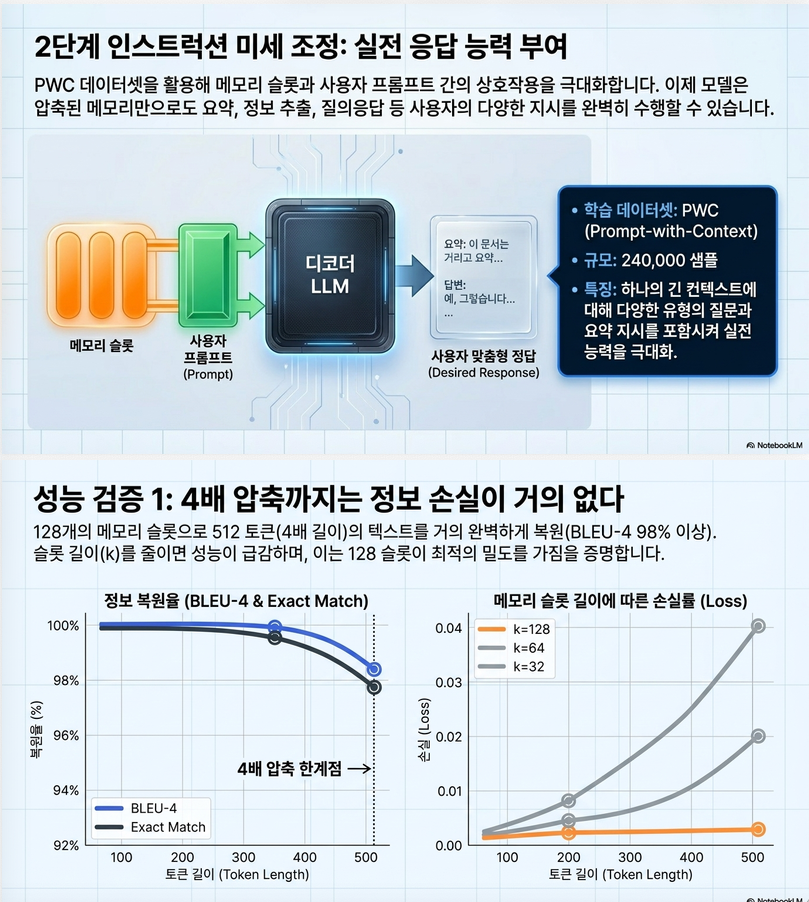
8. Instruction Fine-tuning
Pretraining 후에는:
- QA
- 요약
- rephrase
- continuation
같은 실제 task를 수행하도록 fine-tuning한다.
학습 형태:
[memory slots] + prompt -> responseloss:
이다.
9. PWC Dataset
논문은 자체적으로:
Prompt-With-Context (PWC)
dataset을 구축했다.
구성:
- context
- prompt
- answer
triplet.
생성 방식:
- Pile text sampling
- GPT-4로 다양한 prompt/answer 생성
규모:
- train 240k
- test 18k
이다.
10. 핵심 실험 결과
10-1. Autoencoding 성능
512-token context를:
- 128 memory slot
으로 압축 (4× compression).
결과:
- BLEU ≈ 99%
- 매우 낮은 reconstruction loss
를 달성했다.
즉:
latent memory가 거의 모든 정보를 유지한다는 의미.
10-2. Compression ratio 영향
memory slot 수 감소:
| k | 결과 |
|---|---|
| 128 | 매우 우수 |
| 64 | 성능 하락 |
| 32 | 큰 성능 저하 |
즉:
- 너무 aggressive compression은 어려움
을 보여준다.
10-3. 인간과 유사한 memorization
매우 흥미로운 결과.
복원 시:
large pretrained language model→
large pretrained model처럼 semantic paraphrase가 발생.
논문은:
인간도 기억할 때 의미 중심으로 compression한다
고 해석한다.
10-4. Random text 실험
정상 text는 잘 압축되지만:
- random token sequence
- meaningless text
는 거의 압축 불가능.
결과:
| Content | BLEU |
|---|---|
| Normal text | 99.3 |
| Pattern random | 3.5 |
| Completely random | 0.2 |
즉:
LLM prior knowledge가 compression에 매우 중요함을 의미.
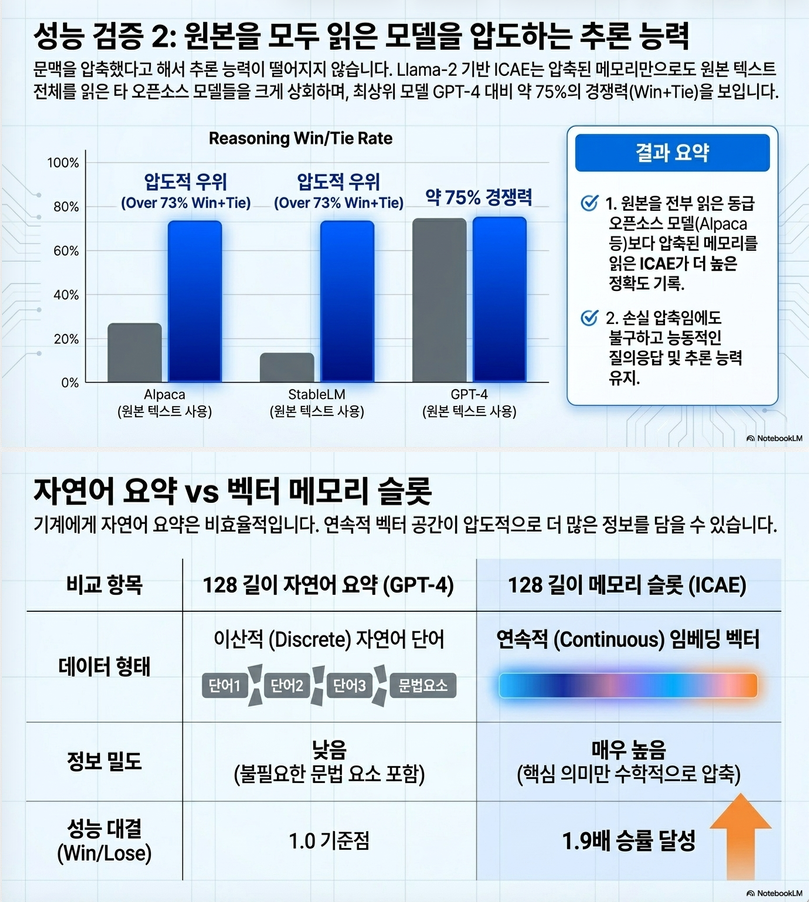
10-5. QA 성능
압축 memory 기반 QA를 GPT-4 evaluator로 비교.
Llama2-7B-chat 기반 ICAE:
- 512 tokens → 128 memory slots
- 약 4× compression
에서도:
- GPT-4 대비 tie 포함 74% 수준
달성.
10-6. Summary보다 우수
논문은:
- 128-token GPT-4 summary
vs - 128 memory slot
비교도 수행.
결과:
memory slot이 summary보다 훨씬 informative였다.
중요한 의미:
- natural language summary는 information bottleneck
- latent vector는 더 dense representation 가능
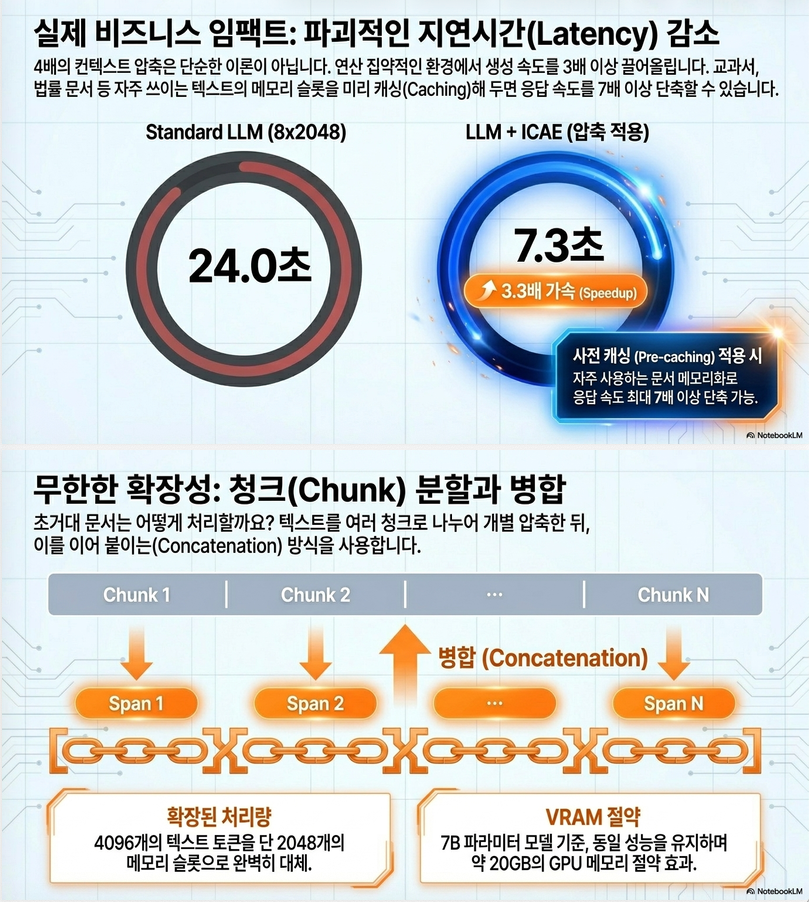
10-7. Latency 개선
가장 practical한 결과.
2048-token 입력 기준:
| 방식 | 시간 |
|---|---|
| 원래 LLM | 24.0 |
| ICAE | 7.3 |
즉:
- 약 3.3× speedup
달성.
11. Multiple Memory Span
긴 문서를:
chunk1 -> memory1
chunk2 -> memory2
...로 각각 압축 후 concatenate 가능.
즉:
[memory_1 ; memory_2 ; …]
형태로 매우 긴 context도 표현 가능.
12. 기존 연구와 차이
논문은:
- GIST
- AutoCompressor
와 비교한다.
핵심 차이:
| 방법 | 특징 |
|---|---|
| GIST | short prompt compression |
| AutoCompressor | recursive summary vector |
| ICAE | general long-context latent compression |
특히 ICAE는:
- LoRA 기반
- 매우 lightweight
- decoder untouched
- scalable
이라는 점을 강조한다.
13. 논문의 핵심 의미
이 논문은 단순 compression 논문이 아니다.
실제로는:
(1) Context = latent memory
라는 관점을 제안.
(2) LLM internal representation을 외부 memory로 사용
즉:
- token sequence 대신
- hidden latent representation
자체를 context로 활용.
(3) Long-context 문제를 architecture 대신 representation 관점으로 해결
Transformer 수정 없이:
- context 자체를 압축.
14. 한계
논문 한계도 명확하다.
(1) Lossless compression 아님
compression ratio 증가 시 성능 저하.
특히:
- 8× 이상은 어려움.
(2) Decoder compatibility 문제
memory slot은:
- 해당 decoder LLM에 특화됨.
cross-model transfer 어려움.
(3) Chunk interaction 부족
여러 chunk 압축 시:
- inter-chunk dependency 약함.
(4) Information locality 부족
어떤 memory slot이 어떤 정보 담당하는지 interpretability 낮음.
ICAE 방법론 상세 설명
논문의 핵심은 다음 문제를 푸는 것이다:
“긴 context를 아주 짧은 latent memory representation으로 압축하고, LLM이 그 memory만 보고도 원래 context 기반 작업을 수행하게 만들 수 있는가?”
ICAE는 이를 위해:
- Encoder
- 긴 context → compressed memory slot
- Decoder
- memory slot 기반 generation
구조를 사용한다.
1. 전체 구조
논문의 전체 파이프라인은 다음과 같다.
Long Context
↓
LoRA Encoder
↓
Memory Slots
↓
Frozen Decoder LLM
↓
Response / Reconstruction중요한 점:
- encoder와 decoder 모두 LLM 기반
- decoder는 원래 LLM 그대로 유지
- encoder만 lightweight adaptation
이다.
2. 입력 구성
원래 context:
여기에 learnable memory token:
를 뒤에 append한다.
즉 encoder 입력은:
이다.
3. Memory Slot 생성
Transformer를 통과한 후:
memory token의 hidden state만 추출한다.
즉:
최종 memory representation:
이다.
4. 왜 뒤에 memory token을 붙이는가?
핵심 이유:
Transformer self-attention 특성상:
- memory token이
- 전체 context를 attention으로 읽고
- compressed representation을 형성
할 수 있기 때문이다.
즉:
memory token = learned summary query처럼 동작한다.
이는 사실상:
- Perceiver latent
- Set Transformer inducing point
- prefix latent bottleneck
과 유사한 구조이다.
5. Encoder 구조
논문은 encoder 전체를 새로 학습하지 않는다.
대신:
- pretrained LLM 복사
- LoRA adapter만 추가
한다.
구체적으로:
- attention Q projection
- attention V projection
에만 LoRA 적용.
6. LoRA 수식
기존 weight:
W
LoRA 적용:
W’ = W + BA
여기서:
이다.
즉 low-rank update만 학습.
7. 왜 LoRA를 쓰는가?
논문 관점에서 매우 중요.
이유 1: Parameter efficiency
추가 parameter 약 1%.
이유 2: Decoder compatibility
decoder는 frozen original LLM.
encoder가 decoder latent space를 크게 바꾸면 안 됨.
LoRA는:
- 원래 representation 유지
- 최소 수정만 수행
하므로 latent alignment 유지에 유리.
8. Decoder 구조
decoder는 원래 LLM 그대로 사용.
입력:
[memory slots] + prompt예시:
[m1][m2]...[mk]
What are the future AI risks?decoder는:
- memory slot을 context처럼 해석
- response 생성
한다.
9. 핵심 학습 목표 1: Autoencoding
가장 중요한 objective.
목적
compressed memory만으로:
복원 가능하게 학습.
Decoder 입력
[memory slots] + [AE]여기서 [AE]는:
- autoencoding task indicator token
이다.
Loss
논문 식:
실제로는 token-level cross entropy.
즉:
decoder가 원문을 teacher forcing으로 복원.
10. 왜 Autoencoding이 중요한가?
핵심은:
memory slot이 원문 정보를 최대한 보존하도록 강제
하는 것이다.
즉 latent bottleneck learning.
11. 핵심 학습 목표 2: Text Continuation
논문은 AE만 사용하면:
- rote memorization
- overfitting
발생한다고 본다.
그래서 추가 objective 사용.
12. LM Objective
입력 context:
다음 continuation:
memory slot으로 continuation 예측:
13. 왜 LM objective가 필요한가?
AE만 하면:
lossless storage만 학습 가능.
LM objective는:
- semantic abstraction
- predictive representation
- generalized latent encoding
을 유도.
즉:
“다음 토큰을 잘 예측하는 representation”
학습.
14. 최종 Pretraining Loss
두 objective 결합:
실험적으로:
근처가 가장 좋았다.
15. Instruction Fine-tuning
Pretraining 후에는 실제 task 학습.
입력
[memory slots] + prompt출력
responseLoss
16. PWC Dataset 생성
논문은:
Prompt-With-Context Dataset
를 새로 만든다.
생성 과정:
- Pile에서 text sampling
- GPT-4로:
- 질문
- 요약
- title generation
- continuation
- keyword extraction
등 생성.
즉:
context -> many prompts -> responses형태.
17. Multiple Memory Span
긴 문서는 chunk 단위 압축.
즉:
Chunk1 -> Memory1
Chunk2 -> Memory2
...후 concatenate:
[M1][M2][M3]...한다.
18. 왜 Concatenation이 가능한가?
논문 핵심 insight:
memory slot은 token처럼 decoder에 들어감.
즉:
- 여러 memory span을 이어붙여도
- decoder가 sequence로 해석 가능.
다만 초기에는 성능이 안 나왔고:
- training 중 multiple-span pattern 추가
후 해결.
19. ICAE의 본질적 의미
이 방법론의 본질은:
기존 Prompt
natural language tokensICAE Prompt
continuous latent memory 이다.즉:
“context를 자연어 대신 latent representation으로 사용”
한다는 점이 핵심.
20. 기존 Prompt Compression과 차이
기존:
- token pruning
- summarization
- extractive compression
은 모두 natural language 유지.
ICAE는:
- latent vector 자체 사용
- non-linguistic representation
- information density 극대화
를 수행.
21. 방법론의 가장 중요한 장점
(1) 기존 LLM 수정 최소화
- decoder frozen
- LoRA만 추가
(2) 매우 높은 compression ratio
512 → 128 가능.
(3) KV cache 절감
실제 inference acceleration 가능.
(4) Semantic compression
단순 token 삭제가 아니라:
- 의미 기반 latent abstraction 수행.
22. 방법론적 한계
(1) Decoder 종속성
memory slot은 특정 decoder latent space에 맞춰짐.
(2) Compression upper bound 존재
8× 이상은 급격히 어려워짐.
(3) 정보 locality 부족
어떤 memory slot이 어떤 의미 담당하는지 불명확.
답글 남기기