






논문 “Improving Contextual Faithfulness of Large Language Models via Retrieval Heads-Induced Optimization” (ACL 2025 Long Paper) 은 RAG 기반 LLM의 신뢰도 문제, 특히 문맥적 정합성(contextual faithfulness) 을 향상시키는 새로운 방법을 제안한 연구입니다 .
1. 연구 배경
- 문제의식 Long-Form QA(LFQA)와 같은 retrieval-augmented generation 환경에서 LLM은 hallucination(출처에 없는 정보 생성)을 자주 일으킴. → 특히, faithfulness hallucination: 모델 출력이 주어진 문서 근거와 일치하지 않는 경우.
- 핵심 통찰 최근 연구(Wu et al., 2024)에 따르면 retrieval head라 불리는 특정 attention head가 문맥 정보 복사(copy-paste) 역할을 수행함. 저자들은 이 head의 작동이 faithfulness의 주요 요인임을 발견하고, 이를 조작하여 학습 신호로 활용함.
2. 주요 아이디어: RHIO 프레임워크
RHIO = Retrieval Heads-Induced Optimization
“retrieval head를 마스킹하여 비충실(unfaithful)한 샘플을 인위적으로 만들고, 이를 이용해 모델이 충실성과 비충실성을 구분하도록 학습한다.”
(1) Unfaithful Data Augmentation
- retrieval head 탐지 알고리즘(Wu et al., 2024)으로 상위 N개 head 선택.
- attention matrix A ∈ 에서 retrieval head h ∈ R 이면 으로 masking.
- → 이렇게 masking된 모델 출력은 실제 hallucination 패턴(불완전·허위 · 모순형 오류)을 잘 모사함 (Fig. 2 참조).

(2) Faithfulness-Aware Tuning (FAT)
- 두 개의 control token 사용: [POS], [NEG]
- [POS]: faithful 출력 유도
- [NEG]: unfaithful 출력 유도
- 각각의 pair (y⁺, y⁻)에 대해 다음 loss로 학습:
→ 모델이 두 타입의 출력을 명시적으로 구분하도록 훈련.
(3) Self-Induced Decoding (SID)
- 추론 단계에서 두 control 코드를 동시에 활용하여 대조적 출력을 유도.
- faithful/unfaithful 로짓을 결합:
- α = 0.2 (contrast 강도)
- → faithful 출력 확률을 증폭, unfaithful 출력 확률은 감쇄시켜 정합성 향상.
3. GroundBench 벤치마크
faithfulness 평가를 위한 새 벤치마크 GroundBench 제안.
5개 LFQA 데이터셋을 통합:
| Dataset | 특성 |
|---|---|
| ELI5-WebGPT | 사람이 수집한 근거 문서 포함 설명형 QA |
| ExpertQA | 전문가 작성 질문과 검증된 근거 |
| HAGRID | 정보탐색 시나리오 LLM 응답 + 인간 평가 |
| CLAPNQ | Natural Questions 기반 웹 검색 질문 |
| QuoteSum | 여러 출처 문서 요약형 LFQA |
faithfulness 측정에는 MiniCheck 모델 사용 .
4. 실험 결과
| 모델 | 평균 FaithScore | 비고 |
|---|---|---|
| GPT-4o | 82.33 | 상용 모델 최고 성능 |
| Llama-2-7B + SFT | 72.98 | 기본 fine-tuning |
| Llama-2-7B + RHIO | 82.35 | + 9.4 p 향상, GPT-4o 초과 |
| Llama-2-13B + RHIO | 83.77 | + 9.4 p 향상 |
- SID 제거 → faithfulness −2~4 p 감소
- FAT 제거 → faithfulness −9~10 p 감소
- α = 0.2 일 때 최적 성능 (Fig. 4 (a))
- retrieval-head masking 기반 negative sample 이 다른 증강법(entity/relation corruption 등)보다 우수(Fig. 5).
5. 추가 분석
- Retrieval head masking 은 entity/relation perturbation 보다 현실적인 비충실 패턴 생성 → 모델 정합성 감지 능력 향상.
- DPO (Direct Preference Optimization) 와 결합 시 추가 성능 향상 가능(Table 4).
- Human Evaluation: RHIO-13B 의 faithfulness 87.5%, GPT-4o 보다 약간 우세 (Table 5).
6. 기여 요약
- Retrieval Head 분석 → faithfulness 기제 규명.
- RHIO 프레임워크 제안:
- retrieval-head masking으로 unfaithful 데이터 생성
- Faithfulness-Aware Tuning (FAT)
- Self-Induced Decoding (SID)
- GroundBench 벤치마크 구축.
- GPT-4o 보다 높은 faithfulness 달성.
7. 한계 및 미래 과제
- 실험은 주로 Llama-2 시리즈 모델에 한정.
- GroundBench는 retrieval failure 시나리오를 포함하지 않음.
- Retrieval head 별 오류 유형 제어 미비 → 향후 세분화된 오류 유형 생성 탐구 필요.
요약하자면, RHIO는 “retrieval head 마스킹 → 비충실 샘플 생성 → 충실성 인식 학습 → 대조 디코딩 강화” 의 단계로 LLM의 문맥적 신뢰도를 내재적으로 향상시키는 새로운 접근입니다.
GPT-4o 수준을 능가하는 faithfulness 개선을 보여 retrieval 기반 LLM 신뢰성 연구의 중요한 전환점으로 평가됩니다.
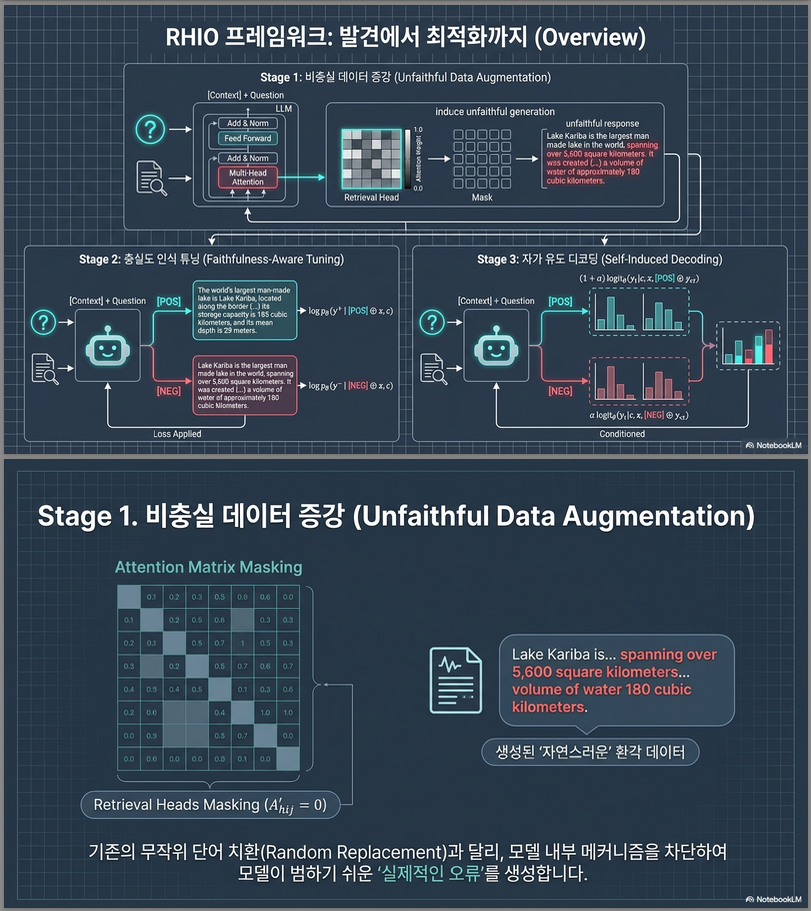
논문의 (1) Unfaithful Data Augmentation 파트는 RHIO 프레임워크의 핵심 시작 단계로, “retrieval head를 마스킹(masking)하여 LLM 내부에서 실제처럼 비충실(unfaithful)한 응답을 생성” 하는 과정을 다룹니다 .
1. 문제의식
- 목표: LLM이 “충실한 응답(faithful output)”과 “비충실한 응답(unfaithful output)”을 스스로 구별해 학습하도록 만들기 위해서는 → 현실적인 negative(비충실) 데이터가 필요함.
- 문제: 기존 방법들은
- 엔티티 치환(entity permutation),
- 관계 변조(relation corruption) 등 표면적 교란만 일으켜 실제 모델의 오류 양상과는 다름. → coherence가 낮고 error coverage가 협소함.
2. 핵심 아이디어
“LLM이 실제로 비충실한 출력을 내는 내부 원인은 retrieval head의 비활성화와 유사하다.”
- 저자들은 retrieval head masking 실험을 통해, 특정 attention head(정보 복사/참조 담당)를 꺼버리면 모델이 실제와 유사한 hallucination 패턴을 보임을 발견함 (Section 2.2 Pilot Study 결과).
- 따라서, retrieval head를 인위적으로 마스킹하여 비충실 샘플을 합성(augment) 하는 접근을 제안.
3. 수학적 정의
(1) Attention Matrix 정의
- 한 layer의 self-attention matrix:
- H : attention head 수
- L : sequence 길이
(2) Retrieval Head 탐지
- Wu et al. (2024)의 retrieval head 검출 알고리즘을 이용해 top-N retrieval heads 집합 R = {h₁,…,h_N} 을 선정.
(3) Masking 연산
- 상위 retrieval head의 attention 가중치를 0으로 만듦:
- 결과적으로 A′은 retrieval 정보 흐름이 차단된 attention matrix.
- 논문에서는 N = 100 (head 단위 마스킹)으로 설정함.
4. 효과
- 이렇게 생성된 응답은 모델이 실제로 저지르는 unfaithfulness 패턴과 거의 동일 (Fabricated 40%, Incomplete 48%, Inconsistency 12%) .
- 즉, retrieval head masking → 모델 내재적 hallucination 패턴을 재현.
- 이 샘플들을 negative data로 활용하여 후속 단계 (Faithfulness-Aware Tuning)에서 모델이 충실성과 비충실성을 명시적으로 구분하도록 훈련할 수 있음.
5. 핵심 포인트 요약
| 구분 | 내용 |
|---|---|
| 입력 | Question + Context |
| 조작 대상 | Retrieval head attention matrix |
| 조작 방식 | Top-N retrieval head attention 값 0으로 mask |
| 결과 | Faithful → Unfaithful 출력 자동 유도 |
| 장점 | 모델 내부 기제에 근거한 realistic error 생성 |
| 용도 | FAT 단계에서 negative 샘플로 사용 |
요컨대,
Unfaithful Data Augmentation은 RHIO 프레임워크의 첫 단계로,
retrieval head 마스킹을 통해 LLM 자체의 “hallucination 유발 기전”을 학습적으로 이용하여 보다 현실적인 비충실 데이터를 생성하는 기술입니다.
이는 후속 Faithfulness-Aware Tuning 단계에서 충실성 인식 능력을 강화하는 핵심 발판이 됩니다.
Retrieval Head Mechanistically Explains Long‑Context Factuality (Wu et al., 2024) 논문에서 제안된 retrieval head 검출 알고리즘을 단계별로 정리하면 다음과 같습니다.
1. 배경 & 정의
- 논문에서는 transformer 기반 대형 언어모델이 긴 문맥(예: 수십 ~ 수백 k 토큰) 내에서 입력 내부의 특정 위치에서 정보를 꺼내(“retrieve”) 출력에 사용하는 메커니즘이 존재한다고 가정합니다.
- 여기에서 “retrieval head”란 attention 모듈 내 특정 head가 다음 두 조건을 만족할 때 가정된 기능입니다:
- 출력하는 토큰 w가 입력(context) 내 어떤 토큰과 정확히 같거나 매우 유사한 토큰이다.
- 해당 head가 출력 시점에 가장 많은 attention weight 를 입력의 그 동일 토큰(혹은 복사 대상)에게 집중하고 있다.
- 즉, “copy-paste” 혹은 “입력 내부 토큰을 직접 참조해 출력으로 옮기는” 양상을 보이는 head가 “retrieval head”로 판정됩니다.
2. 알고리즘 개요 – “Needle‐in‐a‐Haystack” 방식
Wu et al. 은 detection 알고리즘을 아래와 같이 구성하였습니다.
(i) 준비: “needle” 삽입
- 문맥 x (“haystack”) 를 준비하고, 여기에 질문 q 와 함께 답변 문장 k (“needle”) 을 임의 위치에 삽입합니다. k는 모델이 내장 지식만으로 쉽게 답할 수 없는, 문맥 내 삽입되지 않으면 답변이 불가능한 유일한 문장입니다.
- 예컨대 “Once upon a time … the best thing to do in San Francisco is to eat a sandwich in Dolores Park …” 식으로 input context 뒤에 needle을 숨겨 넣습니다.
(ii) 출력 생성 및 attention 기록
- 모델에게 q 를 던져 답변을 생성하도록 하고, auto-regressive decoding 중 각 출력 토큰 w 에 대하여 각 attention head h 의 attention distribution (크기: |x|) 를 기록합니다.
- 특히, 어떤 head h 가 출력 w 에 대해 입력 에서 최대 주의를 기울였다면
(iii) 복사-판단 및 retrieval score 정의
- 만약 출력 토큰 w ∈ k (즉, 삽입된 needle 문장 내부의 토큰) 이고, 또한 그 head h 가 w 와 동일한 입력 토큰 에 가장 집중했다면, 우리는 이 head가 이 w 를 “복사해냈다(copy/paste)”고 판단합니다.
- 각 head h 별로 = {복사했다고 판단된 토큰 집합} 을 구성하고, retrieval score 를 로 정의합니다. 즉 → “needle 전체 토큰 중 이 head 가 출력 시점에 복사해낸 비율”.
(iv) 반복 실험 및 final ranking
- 위 과정을 다양한 문맥 길이 (예: 1k–50k 토큰)와 다양한 삽입 위치(depth)에서 반복하여 각 head h 에 대해 평균 retrieval score 를 계산합니다. 각 모델당 약 600개의 인스턴스를 사용한 실험입니다.
- 일정 기준(threshold) 이상 score 를 가진 head 들을 “retrieval head”로 분류합니다. 예컨대 논문에서는 score > 0.1 (즉 10% 이상 복사 행동) 을 기준으로 한 경우가 있습니다.
3. 알고리즘 상세 흐름 (의사코드 형태)
for each model:
for each (q, k, x) sample in Needle-in-a-Haystack set:
# x: context (“haystack”)
# insert k into x at random position
output = model.generate(q, context=x)
for each output token w at step t:
for each attention head h:
a = attention_head_scores(h, at step t) # vector over |x|
j = argmax(a)
if w ∈ k and x[j] == w:
record that head h copied token w
for each head h:
retrieval_score[h] = (# tokens copied by h across all instances) / (total # tokens in all k's)
retrieval_heads = { h | retrieval_score[h] ≥ threshold }4. 유의사항 & 한계
- “복사했다” 판단 조건이 출력 토큰 == 입력 토큰 및 해당 head가 가장 큰 attention weight 을 줬다는 두 조건을 만족해야 합니다. 이로 인해 재구성(paraphrase) 되는 retrieval 행동은 잘 잡아내지 못할 수 있습니다. Wu et al. 본문에서도 “copy-paste or paraphrase” 가능성은 언급하지만, 검출은 주로 copy-paste 행동에 기반합니다.
- 문맥 길이, 질문 유형, 삽입 위치 등이 다양해야 안정적인 retrieval head 판별이 가능합니다 — 논문에서는 다양한 길이/깊이(depth)를 사용했습니다.
- threshold 설정은 임의성이 존재하며, “score ≥ 0.1” 은 논문의 한 설정일 뿐이며 모델/실험마다 다를 수 있습니다.
- 이 검출 방식은 출력에 직접 입력 토큰이 복사된 경우에 강점을 보이지만, 입력을 “이용했다” 하더라도 완전히 바꿔 표현한 경우에는 검출이 어려울 수 있습니다.
5. 왜 이 알고리즘이 유의미한가
- 이 방법을 통해 “어떤 head들이 실제로 문맥 내 정보 참조/재사용(retrieve) 역할을 하고 있는가” 라는 메커니즘적 해석이 가능해졌습니다.
- 논문 실험에서 retrieval head들을 마스킹(masking)했을 때 모델의 “needle” 회수 성능이 급감했고, 반대로 임의의 non-retrieval head 마스킹은 성능 저하가 거의 없었다는 점이 이 head들의 causal 역할을 보여줍니다.
6. 논문에서 제시된 주요 수치 및 관찰
- 대부분 모델에서 retrieval head는 전체 attention head 대비 매우 적은 비율(≈ 3%-6%) 입니다.
- 어떤 head들은 거의 항상 활성화(activation frequency ≈ 1) 되는 반면, 일부는 특정 토큰/문맥에서만 활성화되는 특징이 발견되었습니다 (“dynamic activation”)
- retrieval head 마스킹 시 모델의 성능(“needle” 회수율)이 급격히 저하된 반면, non-retrieval head 마스킹은 영향이 적었다는 causal 증거가 보고됨.
아래는 논문의 방법론(Methodology) 을 구성요소–목표–수식–추론 단계까지 일관된 관점에서 정리한 설명입니다.
0. 전체 개요
이 논문의 핵심 방법론은 RHIO로 요약됩니다.
RHIO = Retrieval Heads-Induced Optimization
retrieval head를 조작해 현실적인 비충실(unfaithful) 샘플을 만들고, 모델이 충실/비충실을 명시적으로 구분하도록 학습한 뒤, 대조적 디코딩으로 충실성을 증폭한다.
구성은 3단계입니다.
- Unfaithful Data Augmentation (retrieval head masking)
- Faithfulness-Aware Tuning (FAT) (control token 기반 이중 감독)
- Self-Induced Decoding (SID) (contrastive decoding)
1. Unfaithful Data Augmentation
목표
- 현실적인 negative(비충실) 샘플을 자동 생성
- 엔티티 치환 등 표면적 교란이 아닌, 모델 내부 기제에 근거한 오류 유도
핵심 아이디어
- Wu et al. (2024)이 정의한 retrieval head는 입력 문맥에서 정보를 복사/참조하는 attention head
- 이 head를 비활성화하면 실제 LFQA에서 관찰되는 hallucination 패턴(fabricated / incomplete / inconsistent)이 재현됨
구현
- 한 레이어의 attention:
- retrieval head 집합 R (상위 N개, 논문에서는 N=100)
- 마스킹:
결과
- 동일한 입력(question+context)에 대해
- 정상 모델 → 상대적으로 faithful 출력
- retrieval-masked 모델 → model-intrinsic unfaithful 출력
- 이 출력이 negative sample 로 사용됨
2. Faithfulness-Aware Tuning (FAT)
목표
- 모델이 “충실한 답변”과 “비충실한 답변”을 개념적으로 구분하도록 학습
- 단순 SFT(positive imitation) 한계 극복
Control Tokens
- [POS] : faithful generation 지시
- [NEG] : unfaithful generation 지시
학습 데이터 구성
- 동일 입력 (x, c) 에 대해
- : 원래 모델(혹은 gold)에서 생성한 faithful 응답
- : retrieval head masking으로 생성한 unfaithful 응답
학습 목적함수
의미
- [POS] 조건 하에서 근거 충실성 강화
- [NEG] 조건 하에서 비충실 패턴 인식 능력 강화
- 결과적으로 faithfulness에 대한 표현 분리(representation disentanglement) 발생
3. Self-Induced Decoding (SID)
목표
- 학습된 control token을 추론 단계에서도 활용
- faithful/unfaithful 분포 차이를 디코딩 레벨에서 증폭
아이디어
- 동일 prefix에 대해 [POS], [NEG] 두 조건의 logit을 동시에 계산
- faithful logit은 강화, unfaithful logit은 억제
디코딩 수식
- : [POS] 조건 logit
- : [NEG] 조건 logit
- : 대조 강도 (논문 기본값 0.2)
- : temperature
직관
- “이 토큰이 비충실할 때 잘 나오는지”를 직접 감점
- 기존 CAD(Context-Aware Decoding)보다
- 모델-내재 오류 분포를 활용한다는 점에서 더 강력
4. 방법론의 핵심적 특징
| 측면 | 기존 접근 | RHIO |
|---|---|---|
| Negative 데이터 | 규칙 기반 변조 | retrieval head 기반 model-intrinsic 오류 |
| 학습 신호 | Positive only | Positive + Negative 이중 감독 |
| Faithfulness 인식 | 암묵적 | 명시적 (control token) |
| 디코딩 | 단일 분포 | 자기 유도 대조 분포(SID) |
| 개입 위치 | 데이터 / 프롬프트 | Attention head + decoding |
5. 연구적 의미 (해석 관점)
- Mechanistic Interpretability → Training Signal 로의 직접 연결
- retrieval head를
- 분석 대상이 아니라
- *학습 가능한 오류 생성기(error generator)*로 사용
- “faithfulness”를
- 평가 지표가 아니라
- 모델 내부에서 분리·조작 가능한 개념으로 취급
한 줄 요약
RHIO의 방법론은 retrieval head라는 메커니즘적 단서를 이용해,
LLM이 스스로 ‘충실함 vs 비충실함’을 인식·대조·증폭하도록 만드는 구조적 학습 프레임워크이다.
아래는 **본 논문(RHIO)**의 실험 결과(Experimental Results) 를 정량 성능 → 소거(Ablation) → 추가 분석 → 인간 평가 순서로 핵심만 압축 정리한 것입니다.
1. 메인 정량 결과 (GroundBench)
설정
- 백본: Llama-2-7B / 13B
- 벤치마크: GroundBench (ELI5-WebGPT, ExpertQA, HAGRID, CLAPNQ, QuoteSum)
- Faithfulness 지표: MiniCheck 기반 FaithScore
핵심 수치 (평균 FaithScore)
| 모델 | Avg. Faith |
|---|---|
| GPT-4o (프롬프트) | 82.33 |
| Llama-2-7B + SFT | 72.98 |
| Llama-2-7B + RHIO | 82.35 |
| Llama-2-13B + SFT | 74.40 |
| Llama-2-13B + RHIO | 83.77 |
해석
- RHIO는 7B/13B 모두에서 +12~13p의 대폭 향상.
- 7B RHIO가 GPT-4o를 근소하게 상회, 13B RHIO는 GPT-4o보다 +1.4p 내외.
- 단순 SFT, RECOMP, Self-RAG 대비 일관되게 최고 faithfulness.
2. Ablation Study (구성요소 기여)
(A) FAT 제거 (w/o Faithfulness-Aware Tuning)
- 7B: 82.35 → 72.98 (−9.37p)
- 13B: 83.77 → 74.40 (−9.37p)
결론: Negative(비충실) 샘플을 포함한 이중 감독이 성능의 핵심.
(B) SID 제거 (w/o Self-Induced Decoding)
- 7B: 82.35 → 80.03 (−2.32p)
- 13B: 83.77 → 80.42 (−3.35p)
결론: 디코딩 단계의 대조 증폭이 추가 이득을 제공.
(C) α(대조 강도) 민감도
- 최적 α ≈ 0.2
- 과도한 α는 유창성/안정성 저하로 성능 하락.
3. Negative 샘플 생성 방식 비교
| 증강 방식 | Faith 개선 |
|---|---|
| Entity replacement | 낮음 |
| Relation corruption | 낮음 |
| Prompt-induced hallucination | 중간 |
| Retrieval-head masking | 최고 |
해석: retrieval-head masking은 모델-내재 오류 분포를 재현 → 학습 효율이 가장 큼.
4. Preference Learning과의 결합 (DPO)
- SFT → SFT+DPO: 전 데이터셋에서 faithfulness 추가 향상
- retrieval-head masking으로 만든 (chosen, rejected) 쌍이 고품질 preference 데이터로 작동
의미: RHIO의 negative 생성은 **정렬 학습(DPO)**에도 직접 활용 가능.
5. Self-Induced vs 외부-유도 Negative
- Self-induced (동일 모델에서 masking) > 외부 모델 생성 negative
- 이유: 모델-특이적 오류를 정확히 학습 가능
6. Human Evaluation
| 모델 | Fully Faithful | Partially | Not Faithful |
|---|---|---|---|
| GPT-4o | 86.5% | 8.1% | 5.4% |
| SFT-13B | 76.8% | 13.8% | 9.4% |
| RHIO-13B | 87.5% | 7.6% | 4.9% |
- RHIO-13B가 GPT-4o와 동급 또는 소폭 상회
- Completeness도 동반 개선 (과도한 보수/누락 감소)
7. 요약 인사이트
- 대규모 성능 격차: RHIO는 모델 크기와 무관하게 큰 폭의 faithfulness 개선.
- 핵심 원천: retrieval-head 기반 현실적 negative 생성 + 이중 감독(FAT).
- 추론 이득: SID로 디코딩 단계에서 추가 증폭.
- 범용성: DPO 등 정렬 학습과 상호보완적.
- 실전 의미: 작은 오픈소스 모델도 상용 SOTA 수준의 faithfulness 달성 가능.
답글 남기기