


논문: Function Vectors in Large Language Models, ICLR 2024. 핵심은 ICL prompt가 유도한 “작업 함수”가 LLM 내부의 특정 attention head 출력들의 합으로 벡터화되어 있으며, 이 벡터를 다른 문맥에 삽입하면 모델이 해당 작업을 수행한다는 주장입니다.
1. 핵심 아이디어
논문은 LLM이 few-shot ICL을 할 때 단순히 예시를 복사하거나 표면 패턴을 따르는 것이 아니라, 예시들로부터 “입력→출력 함수” 자체를 내부 hidden state에 압축해 표현한다고 봅니다.
예를 들어:
awake: asleep
future: past
joy: sorrow
simple:이런 antonym 예시를 보면 모델 내부에는 “반의어 생성 함수”를 나타내는 벡터가 형성됩니다. 논문은 이를 Function Vector, FV라고 부릅니다.
이 FV를 zero-shot 문맥에 넣으면:
simple:만 있어도 모델이 complex 같은 반의어를 생성하도록 유도할 수 있습니다.
2. 문제 설정
Autoregressive Transformer LM을 f라고 하고, prompt p에 대해 다음 토큰 분포를 출력합니다.
각 layer 의 마지막 토큰 hidden state는 다음처럼 분해됩니다.
여기서:
- : MLP output
- : layer , head j의 attention head output
- 분석 대상은 마지막 토큰 위치의 activation
ICL prompt는 다음과 같이 정의됩니다.
즉, task t에 대한 N-shot 예시와 query input으로 구성됩니다.
3. 방법론 1: 평균 hidden state로 task vector 가능성 확인
먼저 저자들은 매우 단순한 실험을 합니다.
절차
- 특정 task t에 대한 여러 ICL prompt를 준비합니다.
- 각 prompt의 마지막 토큰에서 layer 의 hidden state 를 수집합니다.
- 평균 activation을 계산합니다.
- 이 평균 벡터를 zero-shot prompt의 hidden state에 더합니다.
예:
simple:에 을 더함.
관찰
중간 layer, 특히 GPT-J에서는 layer 12 근처에 이 평균 벡터를 더하면 모델이 antonym task를 수행합니다. 즉, hidden state 안에 task 정보가 들어 있다는 초기 증거입니다.
하지만 이 평균 hidden state는 여러 정보가 섞여 있으므로, 논문은 더 정교하게 attention head 단위의 causal mediator를 찾습니다.
4. 방법론 2: Causal Mediation Analysis로 핵심 attention head 찾기
논문의 핵심 방법입니다.
목표는 다음입니다.
ICL 중 task 정보를 실제로 전달하는 attention head는 무엇인가?
이를 위해 clean prompt와 corrupted prompt를 만듭니다.
4.1 Clean ICL prompt
정상적인 예시입니다.
awake: asleep
future: past
joy: sorrow
simple:4.2 Corrupted / shuffled-label prompt
입력과 출력의 대응을 섞습니다.
awake: sorrow
future: asleep
joy: past
simple:이 경우 prompt 안에 일관된 함수가 없으므로 모델은 query의 정답을 맞히기 어렵습니다.
5. Attention head별 평균 task activation 계산
각 task t에 대해, attention head 의 평균 출력을 계산합니다.
이 값은 “정상 ICL prompt에서 해당 head가 task t 수행 중 평균적으로 내는 출력”입니다.
6. Causal Indirect Effect, CIE
이제 corrupted prompt를 모델에 넣고, 특정 attention head의 출력을 clean prompt에서 얻은 평균 출력으로 바꿔치기합니다.
의미는 다음입니다.
corrupted prompt에서 특정 head만 정상 task activation으로 바꿨을 때, 정답 토큰 확률이 얼마나 증가하는가?
즉, CIE가 크면 그 head는 task 수행에 causal하게 중요합니다.
7. Average Indirect Effect, AIE
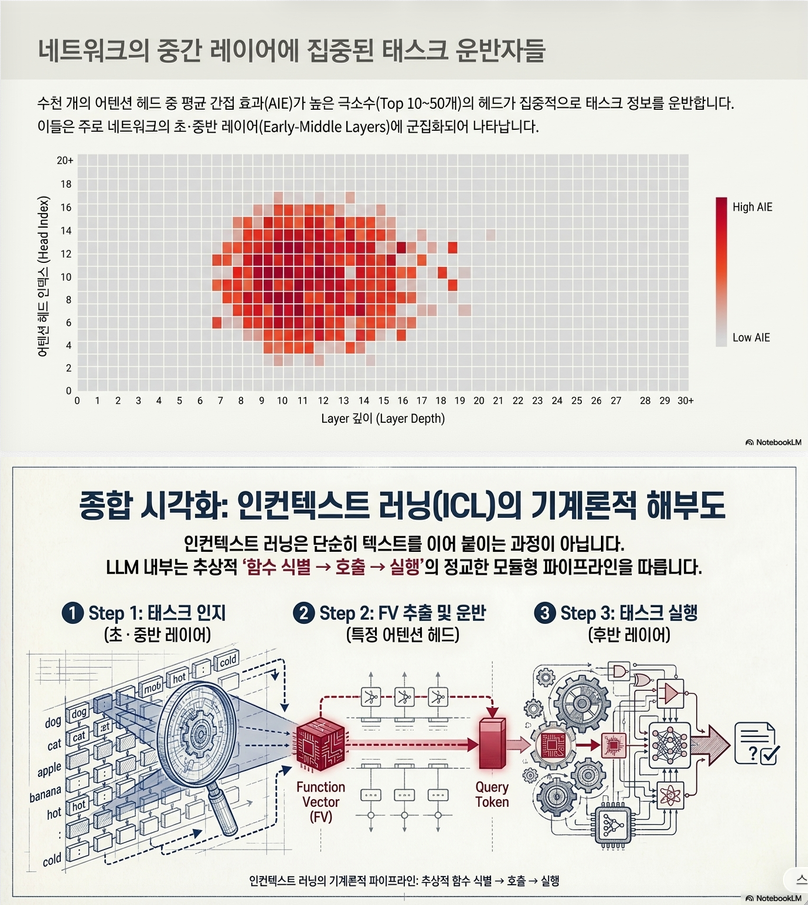
CIE를 task와 prompt 전체에 대해 평균냅니다.
AIE가 큰 head들은 여러 ICL task에서 공통적으로 task 정보를 전달하는 head로 간주됩니다.
논문에서는 GPT-J의 경우 상위 10개 attention head를 선택합니다. Llama 2 70B 같은 큰 모델에서는 더 많은 head를 선택합니다.
8. Function Vector 구성
선택된 attention head 집합을 A라고 하면, task t의 Function Vector는 다음과 같이 정의됩니다.
즉, FV는:
causal mediation으로 찾은 중요 attention head들의 평균 task-specific output을 합한 벡터입니다.
중요한 점은 FV가 학습된 별도 파라미터가 아니라, 모델 내부 activation에서 추출된 벡터라는 것입니다.
9. FV 삽입 방식
추출한 FV 를 새로운 prompt의 특정 layer hidden state에 더합니다.
예:
simple:이라는 zero-shot prompt가 있을 때, 중간 layer의 마지막 토큰 hidden state에:
를 적용합니다.
그러면 모델이 task t를 수행하도록 유도됩니다.
10. 실험 task
대표 task는 다음 6개입니다.
| Task | 설명 |
|---|---|
| Antonym | 단어의 반의어 생성 |
| Capitalize | 첫 글자 대문자화 |
| Country-Capital | 국가 → 수도 |
| English-French | 영어 → 프랑스어 번역 |
| Present-Past | 현재형 동사 → 과거형 |
| Singular-Plural | 단수 명사 → 복수형 |
전체적으로는 40개 이상의 ICL task를 사용합니다.
사용 모델은 GPT-J, GPT-NeoX, Llama 2 7B/13B/70B입니다.
11. 주요 결과
11.1 FV는 zero-shot에서도 task를 유도함
FV를 넣지 않은 zero-shot에서는 정확도가 매우 낮습니다.
하지만 FV를 넣으면 다음처럼 성능이 크게 증가합니다.
예를 들어 6개 task 평균:
| 모델 | Zero-shot baseline | + FV |
|---|---|---|
| GPT-J | 5.5% | 57.5% |
| GPT-NeoX | 6.7% | 57.1% |
| Llama 2 70B | 8.2% | 83.8% |
즉, FV만으로도 모델이 해당 task를 상당히 수행합니다.
12. Layer별 효과
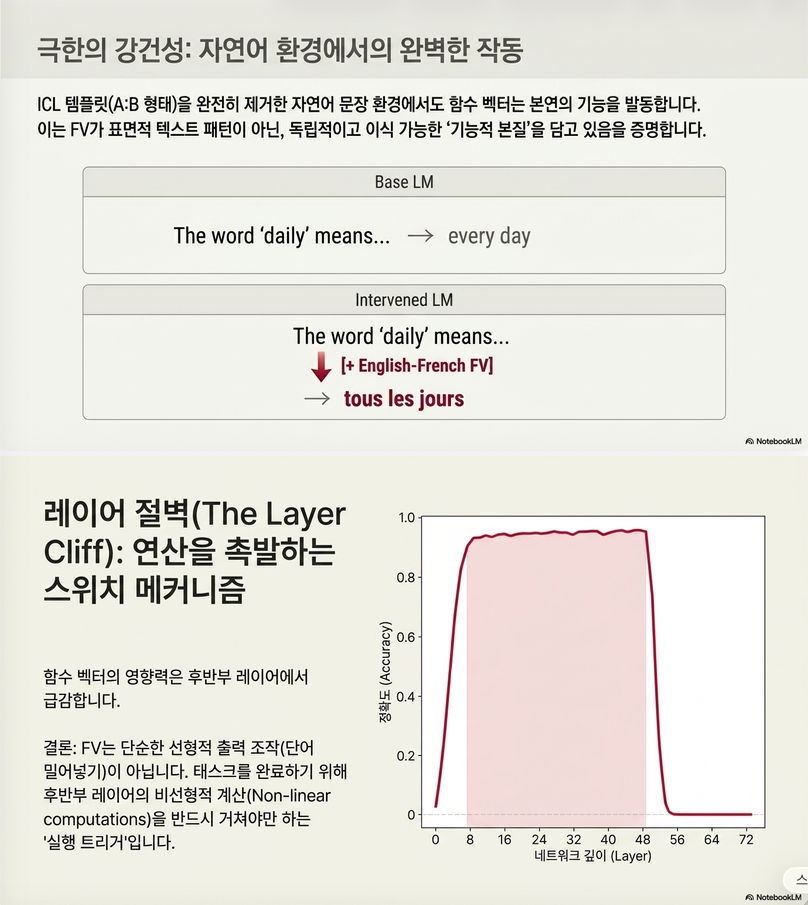
FV는 모든 layer에서 잘 작동하지 않습니다.
가장 효과적인 위치는 대체로 early-middle 또는 middle layer입니다.
후반 layer에서는 효과가 급격히 줄어듭니다.
이는 FV가 단순히 마지막 logit 방향으로 직접 작용하는 것이 아니라, 중간 layer에서 모델 내부의 후속 계산을 “트리거”한다는 해석을 가능하게 합니다.
즉:
FV는 답을 직접 쓰는 벡터라기보다, 모델 내부의 task execution procedure를 호출하는 벡터에 가깝다.
13. Portability 실험
논문은 FV가 원래 ICL prompt 형식에만 의존하는지 확인합니다.
13.1 다른 ICL template
입출력 구분자, prefix, formatting을 바꿔도 FV는 여전히 작동합니다.
즉, FV는 특정 prompt format에 overfit된 것이 아닙니다.
13.2 Natural text prompt
예를 들어 antonym FV를 다음 문장에 삽입합니다.
The word "x" means또는
When I think of the word "x", it usually meansFV를 넣으면 자연어 문맥에서도 반의어를 생성하는 비율이 크게 증가합니다.
이는 FV가 ICL 형식뿐 아니라 일반 자연어 생성 문맥에서도 task behavior를 유도할 수 있음을 보여줍니다.
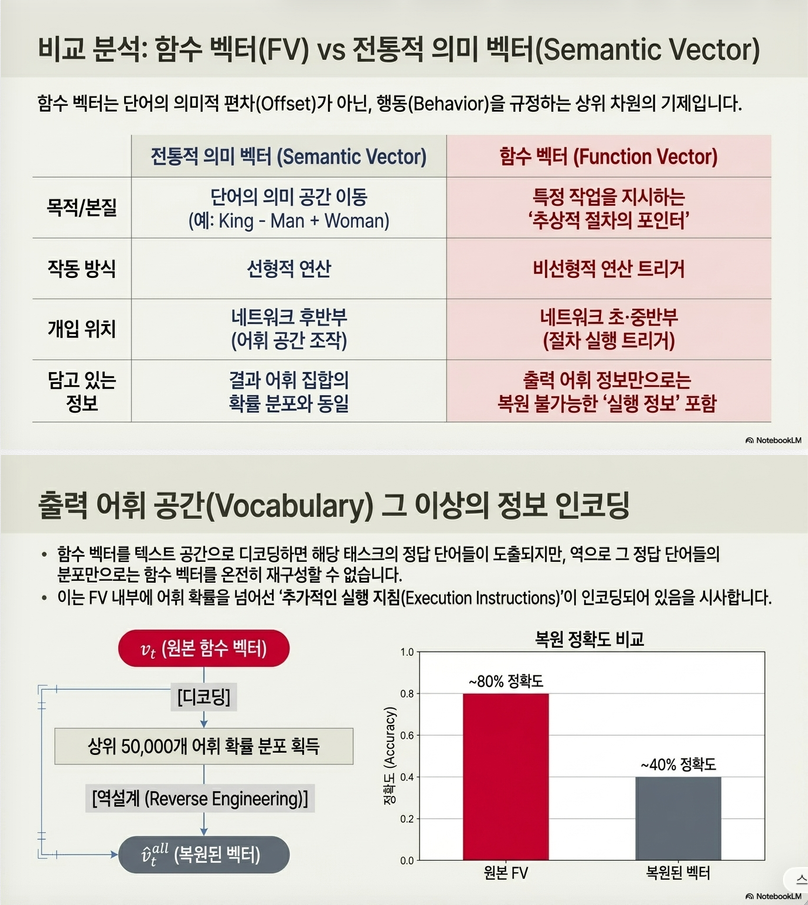
14. FV는 단순 vocabulary vector인가?
저자들은 FV를 decoder에 직접 넣어 어떤 token 분포가 나오는지 봅니다.
예:
| Task | FV decoding 결과 |
|---|---|
| Country-Capital | Moscow, Bangkok, Paris, London |
| Present-Past | received, changed, killed |
| Singular-Plural | cards, stocks, helmets |
많은 경우 FV는 해당 task의 출력 공간과 관련된 token을 decode합니다.
하지만 이것만으로 FV를 설명할 수는 없습니다.
저자들은 top-k token 분포만 맞추도록 벡터를 재구성해 보았지만, 원래 FV만큼 task를 잘 수행하지 못했습니다.
결론:
FV에는 output vocabulary 정보도 있지만, 그것만으로는 부족하며, task procedure를 호출하는 추가 정보가 들어 있다.
15. FV vector algebra
논문은 FV들이 word embedding처럼 조합 가능한지도 실험합니다.
예를 들어:
- First-Copy: 리스트의 첫 단어 복사
- Last-Copy: 리스트의 마지막 단어 복사
- First-Capital: 첫 단어의 수도 출력
이 세 FV를 조합해서:
즉:
를 만들 수 있는지 봅니다.
일부 task에서는 조합된 FV가 실제로 새로운 복합 task를 수행합니다. 다만 모든 task에서 성공하지는 않습니다.
이는 FV 공간에 어느 정도 function-level vector algebra가 존재할 가능성을 보여줍니다.
16. 논문의 의의
이 논문의 가장 중요한 기여는 다음입니다.
- ICL task 정보가 LLM 내부에서 compact vector로 표현됨을 보임
- 그 벡터가 attention head output의 합으로 추출 가능함
- FV가 zero-shot, shuffled-label, natural text 등 다양한 문맥에서 task를 유도함
- FV는 단순 output vocabulary vector가 아니라 task execution을 trigger하는 causal representation임
- 일부 FV는 벡터 연산으로 composition 가능함
17. 한계
중요한 한계도 있습니다.
- FV가 ICL 전체 메커니즘을 완전히 설명하지는 않습니다.
- 주로 비교적 단순한 lexical/function task 중심입니다.
- FV composition은 일부 task에서만 성공합니다.
- instruction-following 모델보다는 base autoregressive LM 중심 분석입니다.
- FV가 구체적으로 어떤 내부 알고리즘을 호출하는지는 아직 불명확합니다.
요약
이 논문은 LLM의 ICL 과정에서 task 자체가 Function Vector라는 내부 activation vector로 표현된다고 주장합니다. 방법론적으로는 causal mediation analysis를 사용해 task 수행에 중요한 attention head를 찾고, 그 head들의 평균 출력을 합쳐 FV를 만듭니다. 이 FV를 다른 prompt의 중간 layer에 삽입하면, 모델은 예시 없이도 해당 task를 수행합니다. 따라서 FV는 단순한 단어 의미 벡터가 아니라, LLM 내부의 함수 호출형 task representation으로 해석할 수 있습니다.
답글 남기기