



이 논문은 RAG(Retrieval-Augmented Generation)에서 문서를 매우 강하게 압축하면서도 QA 성능 손실을 거의 없애는 soft compression 방법을 제안한 논문입니다.
핵심 메시지는 다음과 같습니다.
기존 soft compression은 압축률은 높지만 QA 정확도가 크게 떨어졌고, 대규모 pretraining + labeled QA 데이터가 필요했다.
PISCO는 pretraining 없이, 단순한 sequence-level distillation만으로
x16 압축에서도 원본 LLM과 거의 동일한 QA 성능을 달성한다.
1. 문제 배경
RAG에서는 query마다 여러 document를 붙여 LLM에 입력합니다.
즉:
하지만 transformer attention cost는:
O(n^2)
이라서 document 수가 늘어나면 inference cost가 급격히 증가합니다.
또한:
- context window 제한
- latency 증가
- memory 사용량 증가
문제가 생깁니다.
2. 기존 접근의 한계
논문은 compression을 두 가지로 구분합니다.
(1) Hard Compression
예:
- summarization
- token pruning
- sentence filtering
장점:
- 해석 가능
- 아무 LLM에나 사용 가능
단점:
- 압축률이 낮음 (보통 2~5x)
(2) Soft Compression
문서를 latent embedding으로 압축.
즉:
여기서 는 compressed vector representation.
장점:
- 매우 높은 압축률
단점:
- QA 성능 하락
- 긴 pretraining 필요
- annotated QA labels 필요
특히 기존 방법들은:
- xRAG
- COCOM
- ICAE
- AutoCompressor
등인데, x16 수준 compression에서 QA accuracy가 크게 감소했습니다.
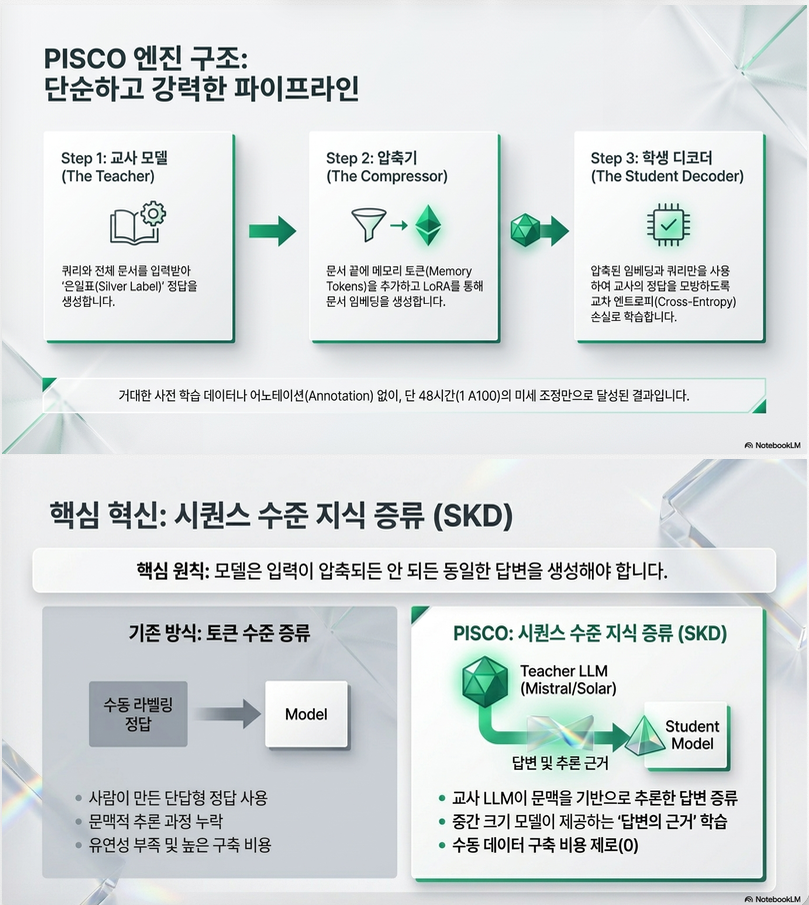
3. PISCO 핵심 아이디어
PISCO는 구조 자체는 기존 soft compression과 유사합니다.
하지만 training objective가 완전히 다릅니다.
핵심 아이디어:
“압축된 문서를 사용해도 원본 문서를 넣었을 때와 동일한 답을 생성해야 한다.”
이를 위해:
Sequence-Level Knowledge Distillation (SKD)
사용합니다.
4. PISCO 구조
논문 Figure 2의 전체 pipeline은 다음입니다.

Step 1. 문서 압축
각 document 뒤에 memory token 추가:
LLM encoder를 통과시키고:
마지막 hidden state만 추출:
즉 문서를:
- l개의 embedding vector
로 압축합니다.
Compression Rate
memory token 개수 l이 compression rate를 결정합니다.
예:
- 원문: 128 tokens
- memory token: 8
이면:
128/8 = 16x
압축입니다.
5. 핵심 차별점: Decoder도 Fine-tuning
기존 연구는 보통 decoder를 freeze했습니다.
즉:
- compressor만 학습
- decoder는 원래 LLM 그대로 사용
하지만 PISCO는:
- compressor LoRA
- decoder LoRA
둘 다 학습합니다.
논문 주장:
compressed embedding은 원래 token embedding 분포 밖에 존재하므로,
decoder adaptation이 필수.
실제로 frozen decoder는 성능이 크게 떨어졌습니다.
6. 가장 중요한 부분: Sequence-level Distillation
기존 연구:
- token-level KD
- GT answer 필요
- teacher logits matching
PISCO:
teacher가 생성한 entire answer sequence를 label로 사용.
즉:
teacher:
생성.
student는 compressed doc만 보고:
최대화.
Loss는:
7. 왜 SKD가 중요한가?
논문의 핵심 insight입니다.
기존 방식:
- raw label 사용
- token-level distillation
→ 압축 representation에서 semantic retrieval/localization 학습이 어려움.
PISCO는:
- teacher reasoning
- contextual answer generation
자체를 imitation하게 만듦.
논문 Needle-in-a-Haystack 결과:
- raw label fine-tuning → retrieval 능력 감소
- distillation → retrieval 능력 향상
즉:
compression에서는 “답만 맞추는 supervision”보다
“teacher reasoning trajectory imitation”이 훨씬 중요.
이게 논문의 가장 중요한 contribution 중 하나입니다.
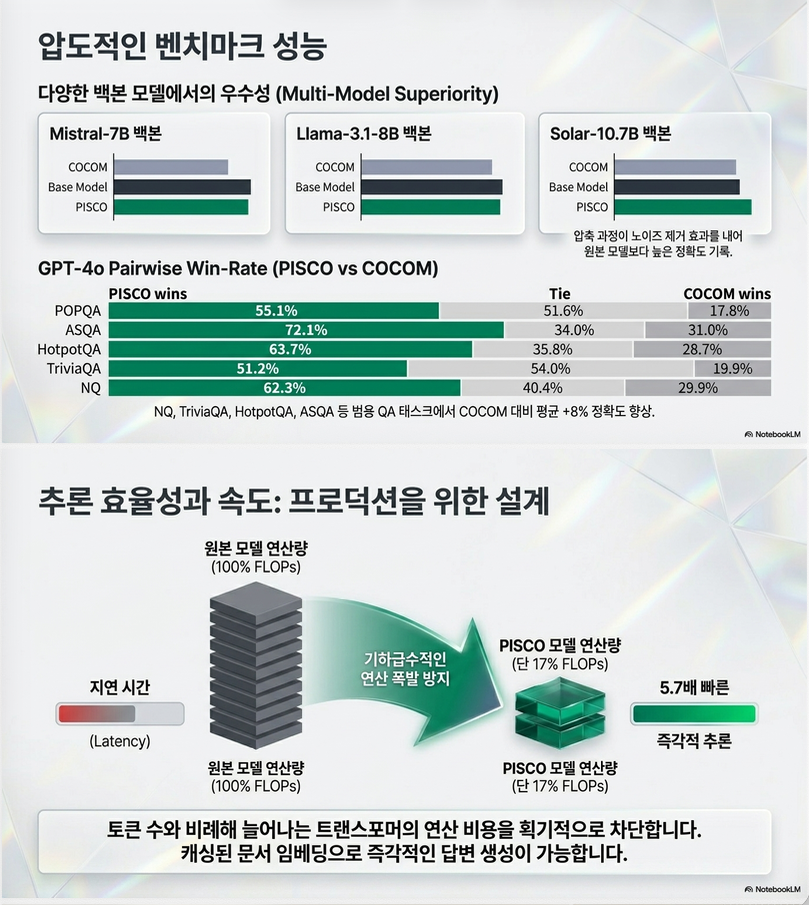
8. 실험 결과
Main QA 결과
Table 2 핵심.
PISCO-Mistral x16
| Model | Avg QA Acc |
|---|---|
| Mistral-7B 원본 | 0.71 |
| COCOM | 0.61 |
| PISCO | 0.68 |
즉:
- x16 compression
- accuracy drop 3% 정도
밖에 안 남.
PISCO-Solar
더 흥미로운 결과:
| Model | Avg |
|---|---|
| Solar 원본 | 0.73 |
| PISCO-Solar | 0.74 |
압축 후 오히려 상승.
논문 해석:
irrelevant information 제거 → denoising 효과
9. 왜 잘 되는가?
논문의 중요한 분석 결과.
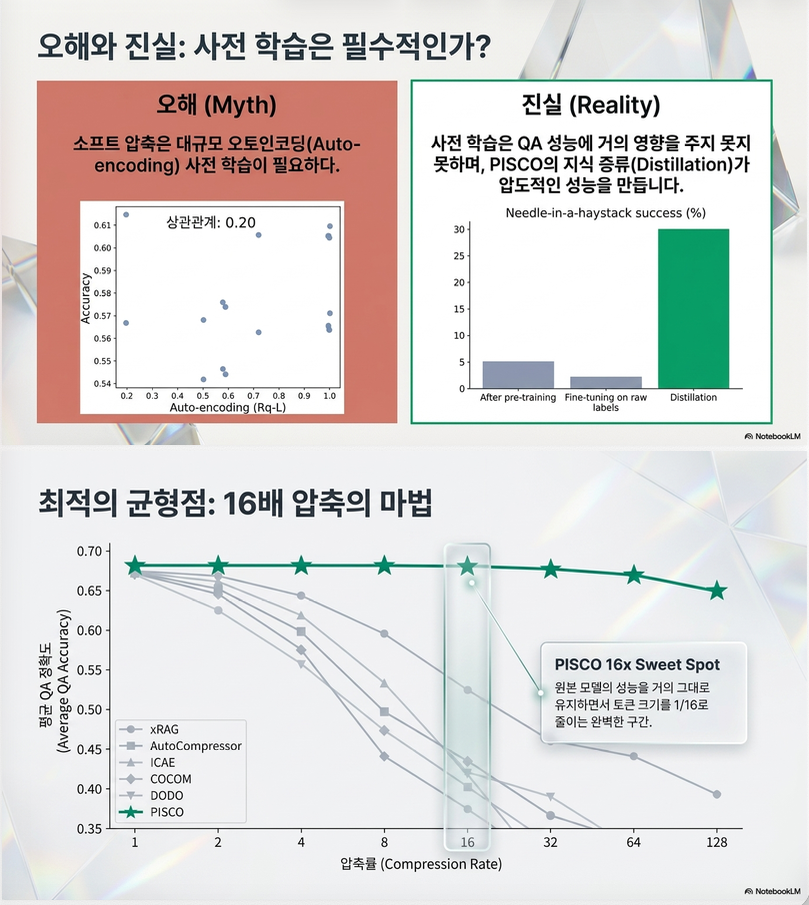
(1) Pretraining 거의 의미 없음
기존 soft compression 연구들은:
- autoencoding pretraining
- LM pretraining
엄청 강조.
하지만 PISCO 분석:
- pretraining metric ↔ QA 성능 correlation 거의 없음
즉:
compression에서 중요한 건 reconstruction이 아니라
downstream QA alignment.
(2) Teacher Quality 중요
흥미롭게도:
- 가장 큰 teacher
- 가장 강한 teacher
가 꼭 좋은 건 아님.
오히려:
- reasoning 포함
- context-grounded answer
를 잘 생성하는 teacher가 좋음.
이건 최근:
- reasoning teacher
- explanation distillation
계열과 연결됩니다.
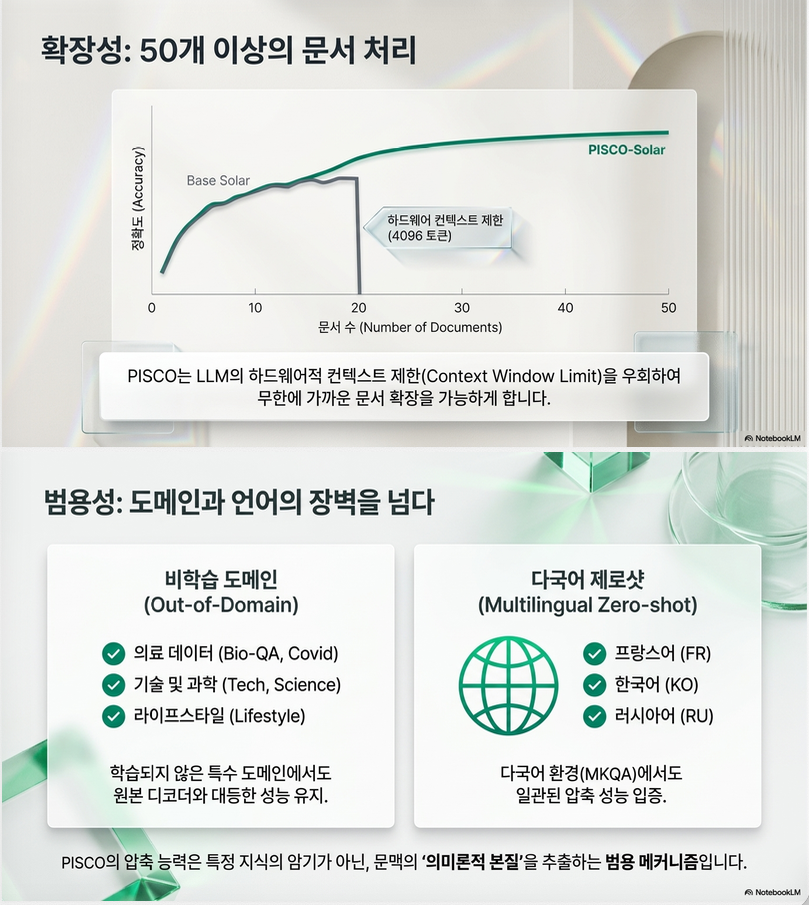
10. Embedding 분석
논문에서 꽤 재미있는 부분.
Compressed embedding이:
- text 전체를 균등 저장하지 않음
- spatial specialization 발생
즉 embedding마다 담당 영역이 생김.
예:
- embedding 1 → 초반부
- embedding 2 → 중간부
- embedding 3 → 후반부
같은 역할 분담.
또한 logit lens 분석 결과:
compressed embedding 내부에 실제 token semantic 정보가 남아있음.
이 부분은:
- latent retrieval
- neural memory
- continuous prompt
관점에서 매우 흥미롭습니다.
11. 연구적으로 중요한 의미
이 논문은 단순 compression paper가 아닙니다.
사실상 다음 메시지를 줍니다:
핵심 주장
“RAG compression의 본질은 reconstruction이 아니라
reasoning-preserving latent representation learning이다.”
즉:
기존:
PISCO:
이 관점은:
- retrieval compression
- latent memory
- neural database
- continuous RAG
쪽으로 확장 가능성이 큽니다.
PISCO 방법론 상세 설명
PISCO의 핵심은:
“문서를 latent memory embedding으로 압축한 뒤,
decoder가 그 compressed representation만 보고도
원본 문서를 본 것처럼 답하도록 학습”
하는 것입니다.
논문 방법론은 크게 다음 5단계로 구성됩니다.
전체 구조
입력:
- q: 질문
- : retrieval된 문서
출력:
r
PISCO는 각 문서를:
로 압축합니다.
여기서:
- l: memory token 개수
- h: hidden dimension
즉:
문서를 소수의 latent vectors로 변환.
1. Compression Module
기본 아이디어
문서 뒤에 memory token 추가.
즉 입력:
여기서:
- : learnable memory token
Encoding 과정
LLM F에 통과:
그리고 마지막 layer에서:
memory token 위치 hidden state만 추출.
즉:
Compression Rate
논문 설정:
- document 길이: 128 tokens
- memory token: 8
이면:
128 / 8 = 16x
compression.
LoRA 기반 Compression
PISCO는 full finetuning 안 함.
대신:
- compressor LoRA
- decoder LoRA
만 학습.
즉:
만 update.
2. Decoder Module
압축된 embedding을 decoder 입력으로 사용.
즉 generation:
여기서 중요한 점:
compressed embedding은 일반 token embedding과 distribution이 다름.
논문은 t-SNE 분석에서:
- compressed embedding이
- token manifold 밖에 존재
한다고 분석.
따라서:
decoder adaptation 필수
즉 decoder freeze하면 성능 크게 감소.
3. 핵심: Sequence-Level Knowledge Distillation (SKD)
이 부분이 PISCO의 가장 중요한 기여.
기존 방법의 문제
기존 soft compression:
Token-level distillation
예:
또는:
teacher forcing 기반 CE loss.
문제:
- token local matching만 학습
- reasoning preservation 부족
- labeled QA data 필요
PISCO 방식
teacher가 answer sequence 전체 생성.
즉:
teacher:
Student Objective
student는:
compressed docs만 보고
teacher answer sequence를 모방.
Loss:
즉:
- teacher reasoning trajectory
- answer generation style
- evidence usage
까지 imitation.
왜 Sequence-level KD가 중요한가?
논문의 핵심 insight.
Compression에서는:
“정답 자체”
보다:
“문서에서 답을 찾는 방식”
보존이 중요.
논문 Needle-in-a-Haystack 결과:
- raw label fine-tuning → retrieval capability 감소
- SKD → retrieval capability 유지/향상
즉 latent representation 안에:
- localization 정보
- evidence access pattern
이 유지됨.
4. Training Pipeline
전체 학습 pipeline:
Step 1. Retrieval
retriever:
- SPLADE-v3
- DeBERTa-v3 reranker
사용.
top-k document 선택.
논문 기본:
k=5
Step 2. Teacher Generation
teacher LLM이:
보고 answer 생성.
teacher output 저장.
Step 3. Compression
각 문서:
compressed embedding 생성.
Step 4. Student Decoding
student decoder:
만 입력받아 teacher answer 생성하도록 학습.
5. Prompt 구조
논문 prompt:
System:
You are a helpful assistant...
User:
Background:
<DOC><SEP><DOC>...
Question:
<QUESTION>여기서:
<DOC> 위치에 실제 text 대신 compressed embedding 들어감.
즉 decoder 입장에서는:
continuous latent prompt를 받는 셈.
6. Pretraining 없이 되는 이유
논문의 매우 중요한 주장.
기존:
- autoencoding pretraining
- LM pretraining
필수라고 생각.
하지만 논문 실험:
- reconstruction 성능 ↔ QA 성능 correlation 매우 낮음.
즉:
compression의 핵심은:
reconstruction
이 아니라
task-relevant latent reasoning preservation
이라는 주장.
7. Embedding 분석
논문에서 상당히 흥미로운 부분.
(1) Spatial Specialization
memory embedding별로 담당 위치가 생김.
예:
- embedding 1 → 문서 앞부분
- embedding 4 → 중간
- embedding 8 → 후반
즉 latent slot specialization 발생.
(2) Logit Lens 분석
compressed embedding에 대해:
decoder head projection 수행.
그러면 특정 embedding이:
- 특정 단어들
- 특정 semantic cluster
와 강하게 연결됨.
즉 compressed vector가 실제 semantic content를 encoding.
8. 계산 효율
PISCO-Mistral x16:
- FLOPs 17%
만 사용.
즉:
달성.
9. 핵심 방법론적 의미
PISCO는 사실상:
“RAG용 latent memory learning”
논문입니다.
즉:
기존 RAG:
PISCO:
로 이동.
인코더와 디코더를 따로 학습하나?
네. PISCO는 사실상:
- compressor(encoder 역할)
- decoder(generator 역할)
를 분리된 LoRA adapter로 동시에(end-to-end) 학습합니다.
다만 backbone LLM 자체는 동일 모델을 공유합니다.
즉 구조적으로는:
두 개의 모드를 가진 형태입니다.
1. 구조적으로 어떻게 되어 있나?
논문은 하나의 pretrained LLM F 위에:
- compression용 LoRA
- decoding용 LoRA
를 각각 따로 붙입니다.
즉:
| 역할 | Adapter |
|---|---|
| Compression | |
| Decoding |
2. Compression 단계
문서 입력:
을:
에 넣음.
즉:
- compressor LoRA 활성화
- decoder LoRA는 사용 안 함
그리고 memory token hidden state 추출:
3. Decoding 단계
이제:
를:
에 입력.
즉:
- decoder LoRA 활성화
- compressor LoRA는 사용 안 함
그리고 answer 생성.
4. 중요한 점: Backbone은 공유
완전히 encoder-decoder architecture(BART/T5)처럼:
- encoder network
- decoder network
가 따로 있는 건 아닙니다.
실제로는:
하나의 decoder-only LLM
(Mistral/Llama/Solar)
을 공유하고:
- compression 시에는
- generation 시에는
다른 adapter를 사용.
즉 개념적으로는:
Shared LLM Backbone
├── Compression LoRA (θc)
└── Decoding LoRA (θd)형태.
5. 왜 adapter를 분리했나?
이게 상당히 중요한 포인트입니다.
Compression과 decoding은 요구 기능이 완전히 다릅니다.
Compression 역할
필요한 능력:
- document semantic aggregation
- information packing
- latent storage
즉:
Decoder 역할
필요한 능력:
- latent memory retrieval
- query-conditioned reasoning
- answer generation
즉:
따라서 동일 adapter 공유보다:
- compression-specific adaptation
- decoding-specific adaptation
을 따로 하는 게 유리.
6. 학습은 어떻게 되나?
Loss는 하나입니다.
여기서:
즉 gradient가:
- decoder LoRA
- compressor LoRA
둘 다로 전파됨.
따라서:
jointly end-to-end 학습
입니다.
7. 왜 decoder training이 중요한가?
논문에서 매우 강조한 부분.
기존 연구들:
- decoder freeze
- compressor만 학습
시도.
하지만 PISCO는:
decoder adaptation 없이는 compressed embedding 활용이 어렵다
고 주장.
논문 분석 결과
t-SNE 결과:
compressed embedding이:
- 일반 token embedding manifold 밖에 존재.
즉 decoder 입장에서는:
"이상한 새로운 latent token"처럼 보임.
따라서 decoder도:
- latent interpretation 방식
- attention pattern
을 새로 학습해야 함.
8. Frozen Decoder 결과
논문 Table 8:
| Setting | Avg 성능 |
|---|---|
| Decoder trained | 높음 |
| Decoder frozen | 크게 하락 |
특히:
- PopQA
- HotpotQA
같은 retrieval-heavy task에서 하락 큼.
9. 관점적으로 보면
PISCO는 사실상:
“Neural Codec”
구조입니다.
Compressor
문서를 latent code로 인코딩:
Decoder
latent code를 reasoning 가능한 memory로 사용:
즉 NLP판:
- VQ-VAE
- latent diffusion autoencoder
- neural codec
와 매우 유사한 철학.
핵심 요약
PISCO는:
- encoder/decoder backbone은 공유하지만
- compression용 LoRA와 generation용 LoRA를 분리해
- end-to-end jointly 학습하는 구조
입니다.
답글 남기기