


논문 **“TTRL: Test-Time Reinforcement Learning” (NeurIPS 2025)**는
라벨이 없는 test 데이터에서 RL을 수행하여 LLM을 test-time에 self-evolve 시키는 방법을 제안합니다 .
아래에서 핵심 아이디어, 수식, 실험 결과, 그리고 왜 작동하는지까지 체계적으로 정리하겠습니다.
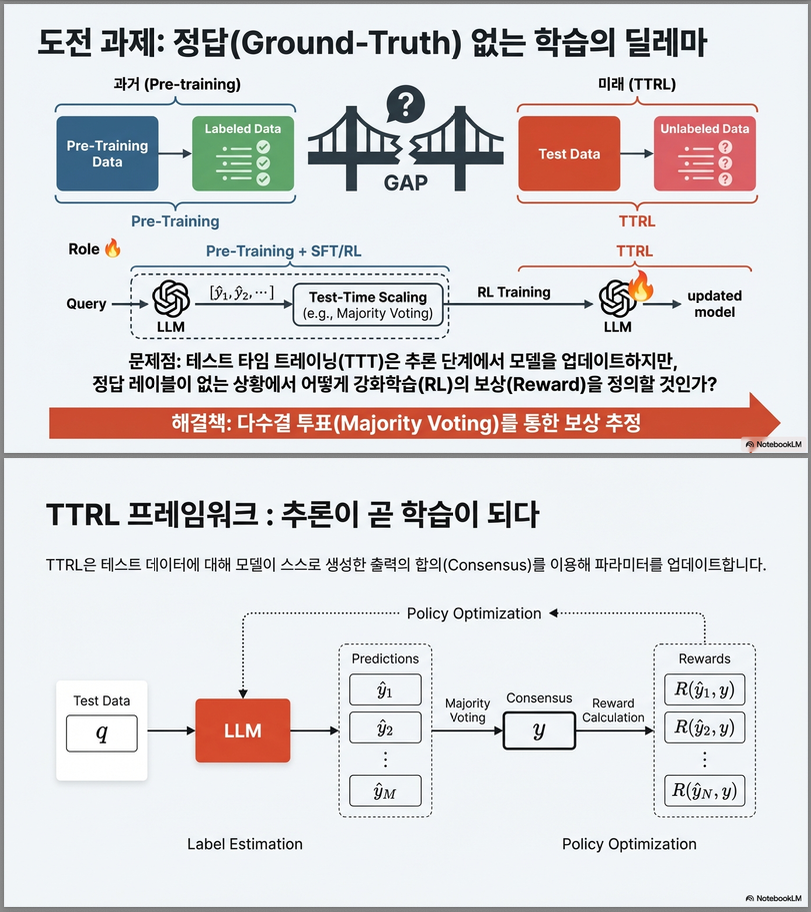
1. 문제 설정: Test-Time RL
기존 RL 기반 reasoning 모델 (예: GRPO, PPO 기반 수학 RL)은 ground-truth label이 있는 데이터를 사용합니다.
그러나 TTRL은 다음과 같은 설정을 다룹니다:
Test-time에, ground-truth 없이 RL로 모델을 학습한다.
즉,
- 주어진 것은 입력 x (문제)
- 정답 y^* 없음
- 그럼에도 RL을 수행해야 함
이것이 TTRL의 핵심 도전입니다.
2. 핵심 아이디어: Majority Voting을 Reward로 사용
TTRL은 **Test-Time Scaling (TTS)**의 대표 기법인 majority voting을
reward estimator로 재해석합니다 .
(1) 기본 절차
Step 1. 여러 개 샘플 생성
Step 2. Majority Voting으로 pseudo-label 생성
즉, 가장 많이 등장한 답을 “정답”처럼 사용.
Step 3. Reward 정의
3. RL Objective
기본 RL objective는 다음과 같습니다:
Gradient update:
핵심은:
reward는 ground-truth가 아니라 모델의 consensus로부터 온다.
4. 왜 이게 작동하는가? (핵심 분석)
논문 4.2절은 매우 중요합니다.
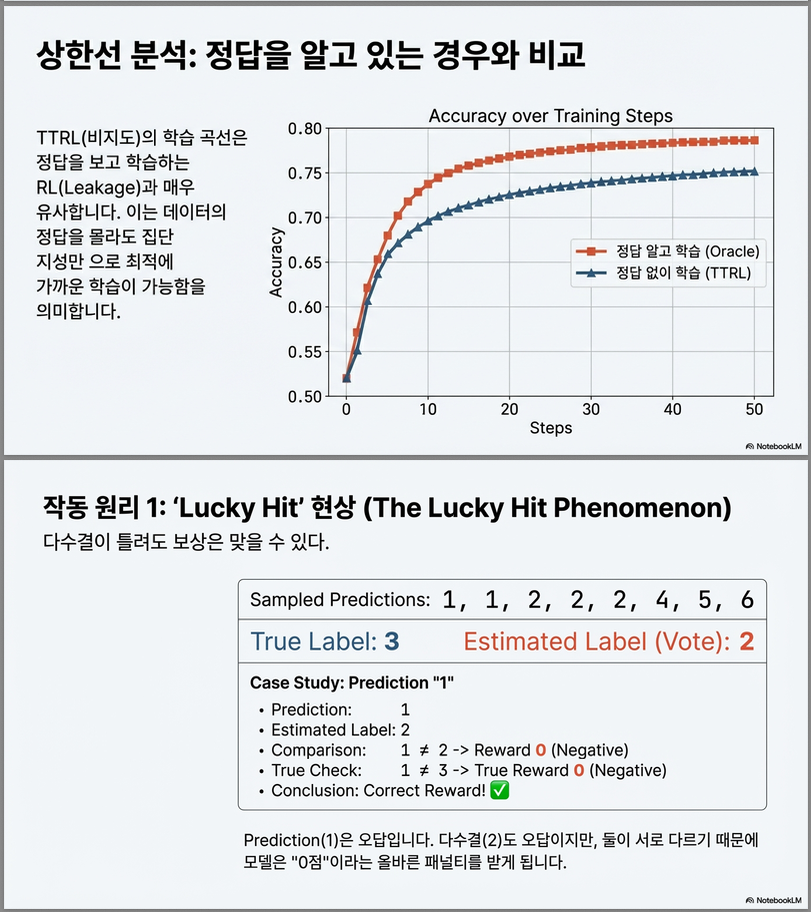
(1) Lucky Hit 현상
pseudo-label이 틀렸어도 reward는 상당히 정확할 수 있음 .
예:
- True label = 3
- Majority vote = 2 (틀림)
- 샘플 예측들: 1,1,2,2,2,4,5,6
이 경우:
- 예측이 2인 경우 → reward=1
- 예측이 1,4,5,6 → reward=0
놀랍게도:
- 틀린 label을 썼는데도
- 많은 경우 negative reward는 정확히 계산됨
이를 논문에서는 “Lucky Hit”이라 부름.
(2) Reward Accuracy > Label Accuracy
AIME 2024 실험에서:
- Label accuracy ≈ 37%
- Reward accuracy ≈ 92%
(figure 10)
즉,
pseudo-label이 틀려도 reward signal은 매우 신뢰할 수 있음.
(3) RL은 reward noise에 robust
논문은 다음 두 점을 강조합니다 :
- RL은 reward noise를 허용
- RL은 SFT보다 일반화가 강함
따라서 pseudo reward로도 안정적인 학습 가능.
5. 가장 인상적인 결과
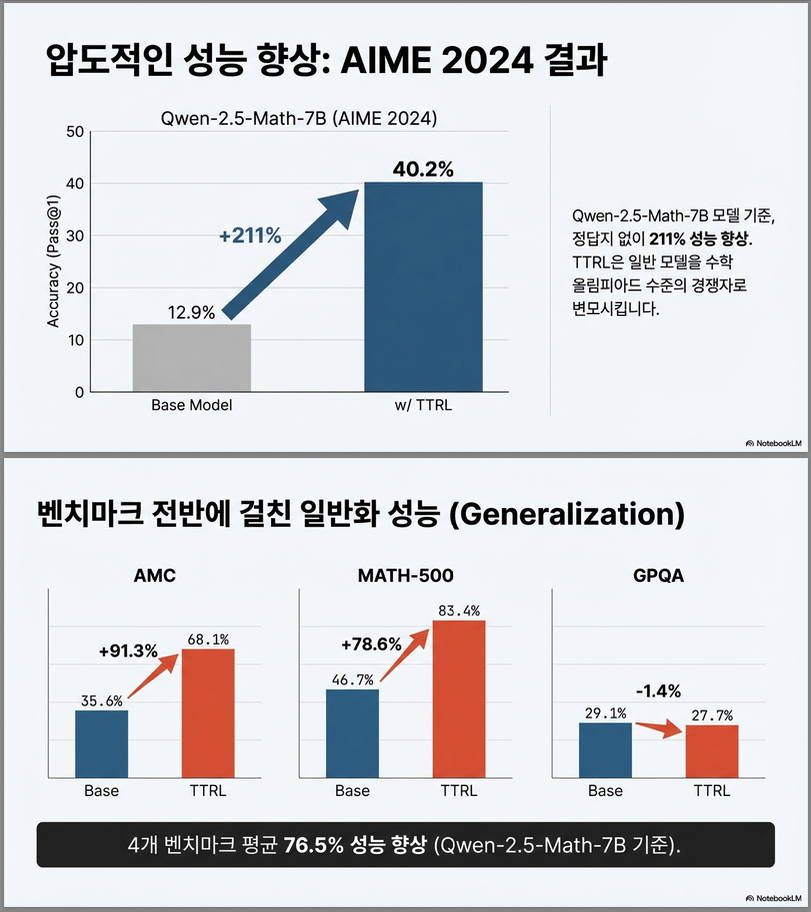
(1) 211% 성능 향상
Qwen2.5-Math-7B:
- AIME 2024: 12.9 → 40.2
- +211% 향상
이는 라벨 없이 test data만으로 얻은 결과.
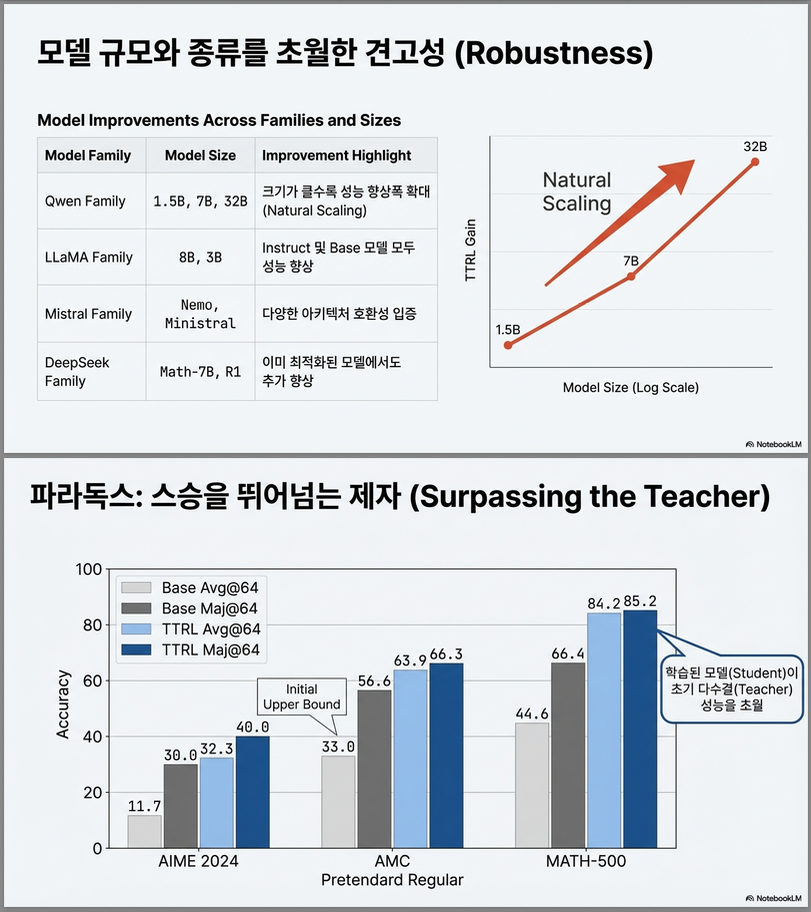
(2) Self-training upper bound를 넘는다
일반 self-training의 upper bound는 initial model의 maj@n.
그런데 TTRL은:
즉, 자기 bootstrap을 넘어선다 .
(3) Direct RL (label leakage)에 근접
라벨을 직접 사용하여 RL한 것과 거의 유사한 성능 도달 .
이건 굉장히 중요한 실험입니다.
6. 핵심 개념 정리
| 개념 | 기존 방법 | TTRL |
|---|---|---|
| Reward source | ground-truth | majority vote |
| 학습 시점 | train time | test time |
| Label 필요 | 필요 | 불필요 |
| 방식 | offline RL | online RL |
7. TTRL의 본질
TTRL은 다음을 통합한 방법입니다:
- Test-Time Scaling (majority voting)
- Test-Time Training (parameter update)
- Online RL
- Self-labeled reward
즉,
“Inference-time self-evolution via RL”
8. 연구적 의미
이 논문의 중요성은 단순 성능 향상이 아니라:
- Unsupervised RL for reasoning
- Label 없이 continual learning 가능성
- Self-bootstrapping beyond majority ceiling
- RL as dynamic pseudo-label refinement
9. 해석적 관점
이 방법은 다음과 연결됩니다:
- Self-consistency (Wang et al., 2022)
- GRPO-style rule-based RL
- Self-improving LMs (Huang et al.)
- Online test-time adaptation
그리고 매우 중요한 철학:
Label estimation → reward estimation → policy improvement → better label estimation (Self-reinforcing loop)
10. 한계
논문은 다음과 같은 implicit limitation을 가짐:
- 수학/검증 가능 task에 최적화
- verifier 기반 reward 필요
- compute heavy (64 rollout)
요약 한 문장
TTRL은 majority voting을 reward로 변환하여, ground-truth 없이 test-time에 RL을 수행함으로써 LLM을 self-evolve시키는 프레임워크이다.
TTRL 방법론 (Methodology)
TTRL(Test-Time Reinforcement Learning)은
ground-truth label 없이 test-time에서 RL을 수행하는 프레임워크입니다 .
핵심은:
majority voting을 reward estimator로 사용하여 online RL을 수행한다
아래에서 수식, 알고리즘 흐름, 학습 구조를 체계적으로 정리합니다.
1. 문제 설정
입력:
정답 는 존재하지만 접근 불가
정책:
목표:
하지만 r(y)를 직접 계산할 수 없음.
2. Majority Voting 기반 Reward 추정
2.1 Rollout
하나의 입력 x에 대해:
(논문 구현: N=64 샘플링 후 일부 downsample)
2.2 Label Estimation
답 추출기(answer extractor)로 최종 답만 추출:
Majority voting:
이것이 pseudo-label.
2.3 Reward Function
중요:
- reward는 정답과 비교하지 않음
- 모델 자신의 consensus와 비교
3. RL Objective
목표 함수:
Gradient update:
실제 구현은 GRPO 기반.
4. 학습 루프 구조
TTRL은 Online RL입니다.
반복 구조:
for each test batch:
1. sample N responses
2. compute majority vote
3. assign rewards
4. update policy중요 특징:
모델이 업데이트될수록 majority vote 품질도 개선됨 → reward quality 향상 → further policy improvement
논문에서는 이를 “self-reinforcing loop”로 설명
5. Vote-then-Sample 전략
논문 구현 세부:
- 64개 샘플 생성
- voting 수행
- 32개만 training에 사용
이 전략은 compute 절감 + 성능 유지
6. 왜 단순 Self-Training이 아닌가?
Self-training:
- majority 선택
- SFT로 학습
TTRL:
- majority → reward
- policy gradient 수행
차이:
| Self-Training | TTRL |
|---|---|
| offline | online |
| SFT | RL |
| upper bound = maj@n | surpass 가능 |
논문은 TTRL이 initial maj@n을 초과한다고 보고
7. Reward Noise 내성
pseudo-label이 틀려도 reward는 상당히 정확:
- Label accuracy ≈ 37%
- Reward accuracy ≈ 92%
이유:
- reward는 “comparison 기반”
- Lucky Hit 현상
8. 알고리즘 정리 (수식 기반)
Step 1. Sampling
Step 2. Consensus
Step 3. Reward
Step 4. Policy Gradient
(실제는 GRPO 형태의 normalized group objective)
9. TTRL의 구조적 특징
(1) Test-Time Scaling + Test-Time Training 통합
- TTS → majority voting
- TTT → parameter update
- RL → bridge 역할
(2) Self-evolution
논문 표현:
model “lifts itself up by its own bootstraps”
즉, initial consensus를 supervision으로 사용
→ policy 개선
→ consensus 개선
→ 반복
10. 핵심 정리
TTRL 방법론은 다음 세 요소로 구성됩니다:
- Label Estimation – majority voting
- Reward Calculation – rule-based 0/1 reward
- Online RL Optimization – GRPO 기반
한 줄 요약
TTRL은 majority voting을 reward signal로 변환하여, test-time에서 ground-truth 없이 online RL을 수행하는 self-bootstrapping 프레임워크이다.
TTRL에서 실제 policy optimization에 사용된 **GRPO (Group Relative Policy Optimization)**의 수식을 구조적으로 설명하겠습니다.
TTRL은 majority voting으로 reward를 계산하고, 그 reward를 GRPO objective에 넣어 policy를 업데이트합니다 .
1. GRPO의 배경
GRPO는 DeepSeekMath에서 제안된 outcome-level rule-based RL 방식입니다 .
핵심 아이디어:
하나의 prompt에서 생성된 여러 샘플을 group으로 보고, 그 안에서의 상대적 성과(relative performance)를 이용해 업데이트한다.
즉, PPO처럼 value model을 두지 않고, group 내부 평균을 baseline으로 사용합니다.
2. 기본 설정
입력 x
정책:
하나의 prompt에 대해 K개 샘플:
각 샘플 reward:
3. Group 평균 보상
GRPO는 group 내부 평균을 baseline으로 사용합니다:
Advantage 정의:
중요:
- 별도 value network 없음
- variance 감소 효과
- 상대적 우수성만 반영
4. GRPO Objective
정책 비율:
GRPO의 clipped objective:
구조는 PPO와 유사하지만:
- value loss 없음
- KL penalty optional
- advantage는 group-relative
5. TTRL에서의 특수성
TTRL에서는 reward가 다음과 같이 정의됩니다 :
즉 0/1 reward.
그러므로:
해석:
- majority에 속한 샘플 → positive advantage
- minority → negative advantage
즉, policy는 consensus 확률을 키우는 방향으로 업데이트됨.
6. Token-Level Gradient
각 샘플은 token sequence:
로그확률:
Gradient:
즉 sequence-level reward를 token-level로 credit assignment.
7. 왜 GRPO가 적합한가?
TTRL에서 GRPO가 특히 적합한 이유:
(1) Label-free setting
value network 학습 불필요 → pseudo reward만으로 학습 가능
(2) Majority reward 구조와 잘 맞음
reward는 group 내부 상대적 정보이므로 group-relative baseline과 자연스럽게 결합됨.
(3) Noise robustness
reward가 noisy해도:
이 baseline subtraction이 noise를 완화.
8. 수식적으로 보는 Self-Bootstrapping
TTRL + GRPO의 dynamics:
초기에는:
- majority 정확도 낮음
- reward noisy
하지만:
정책이 majority 쪽 확률을 증가시키면:
→ positive feedback loop
논문에서 이것을 “lifts itself up by its own bootstraps”라고 설명
9. GRPO vs PPO vs PRIME
논문 실험에서는 PPO와 PRIME과도 비교 .
결론:
- 세 방법 모두 잘 작동
- GRPO는 value-free라 구현 단순
- TTRL은 RL 알고리즘에 agnostic
10. 핵심 직관 정리
GRPO in TTRL은:
“한 prompt 내에서 상대적으로 consensus에 가까운 trajectory를 강화하는 방식”
수학적으로는:
- Reward = consensus indicator
- Advantage = relative consensus deviation
- Update = clipped policy gradient
한 줄 요약
TTRL에서 GRPO는 majority-based 0/1 reward를 group-relative advantage로 변환하여, value-free clipped policy gradient로 업데이트하는 방식이다.
논문의 실험 결과를 구조적으로 정리하겠습니다.
1. 메인 결과 (Table 1)
논문은 4개 benchmark에서 TTRL을 적용합니다:
- AIME 2024
- AMC
- MATH-500
- GPQA
결과는 **Table 1 (p.4)**에 정리되어 있습니다 .
1.1 Qwen2.5-Math-7B (가장 인상적 결과)
| Benchmark | Before | After TTRL | Δ | Relative Gain |
|---|---|---|---|---|
| AIME 2024 | 12.9 | 40.2 | +27.3 | +211% |
| AMC | 35.6 | 68.1 | +32.5 | +91% |
| MATH-500 | 46.7 | 83.4 | +36.7 | +78% |
핵심 포인트:
라벨 없이 test 데이터만으로 AIME에서 211% 향상
1.2 작은 모델도 강하게 향상
Qwen2.5-Math-1.5B
| Benchmark | Before | After | Δ |
|---|---|---|---|
| AIME | 7.7 | 15.8 | +105% |
| MATH-500 | 32.7 | 73.0 | +123% |
특히 MATH-500에서 40점 이상 상승.
→ 작은 모델도 self-evolution 가능.
2. 다양한 모델 패밀리 실험 (Table 2)
논문은 Qwen 외에도:
- LLaMA
- Mistral
- DeepSeek
- Skywork
- Qwen3-8B (thinking mode)
에 적용 .
결과:
거의 모든 모델에서 일관된 향상.
예:
DeepSeek-R1-LLaMA-8B
51.7 → 69.2 (AIME)
이미 RL로 heavily post-trained된 모델에서도 추가 상승.
3. Large Reasoning Model(LRM) 결과
Figure 3 (p.5)
Skywork-OR1-Math-7B:
- 66.7 → 75.0
Qwen3-8B:
- 72.5 → 82.5
핵심:
이미 고성능 RL 모델에서도 추가 10점 상승
4. Scaling Behavior (p.6)
논문은 model size 증가 시 TTRL 효과도 증가한다고 보고 .
1.5B → 7B → 32B
- majority voting 정확도 ↑
- reward quality ↑
- self-improvement ↑
즉:
5. Out-of-Distribution Generalization
Figure 4 (p.6)
TTRL을 AIME에서 수행 후,
AMC/MATH에서 평가해도 성능 상승.
즉:
단순 overfitting 아님
Generalizable reasoning improvement
6. RL Algorithm Compatibility
Figure 5 (p.6)
GRPO vs PPO vs PRIME 비교.
결과:
- 세 방법 모두 유사한 상승 곡선
- TTRL은 RL 알고리즘에 독립적
7. Majority Upper Bound 초과 (핵심 결과)
Section 4.1
놀라운 발견:
즉:
- majority voting을 supervision으로 썼는데
- majority ceiling을 넘어섬
이는 기존 self-training과 결정적 차이.
8. Direct RL (Label Leakage)와 비교
Figure 8 (p.8)
TTRL vs RL(ground-truth 사용)
결과:
TTRL 성능이 거의 leakage RL에 근접
이는 매우 강한 실험 증거.
9. Reward Accuracy vs Label Accuracy
Figure 10 (p.9)
AIME 2024에서:
- Label accuracy ≈ 37%
- Reward accuracy ≈ 92%
즉:
pseudo-label은 부정확해도 reward는 매우 정확
Lucky Hit 효과 때문.
10. 종합 요약
정량적 결론
- 평균적으로 약 70% 이상 상대 향상
- 최대 211% 향상
- 다양한 모델에서 일관성
- LRM에서도 유효
- OOD generalization 가능
- majority upper bound 초과
실험이 말하는 것
- Majority reward는 실제로 usable하다.
- RL은 noisy reward에서도 잘 작동한다.
- Online self-evolution이 가능하다.
- 작은 모델도 크게 성장한다.
연구적으로 가장 중요한 실험 결과
(1) Upper bound 초과
→ self-training 이론적 ceiling 붕괴
(2) Leakage RL 근접
→ pseudo reward의 강력함 입증
(3) Reward accuracy ≫ Label accuracy
→ TTRL 성공의 핵심 메커니즘
답글 남기기